
导读
随着人工智能技术的蓬勃发展,AI Agent 不再只是科技巨头的专属。如今,每个人都可以成为 AI 的创造者和使用者。
Dify,一个开源的 LLM 应用开发平台,以其简洁的界面和强大的功能,让模型管理、RAG 搭建和 Agent 开发变得简单直观,而 TiDB Vector 的向量搜索功能可以为 AI Agent 提供灵活的数据处理能力。
本文将介绍如何通过 Dify 和 TiDB Vector 这两个工具,快速搭建起一个功能完备的 AI Agent。
*本文外链较多,可结合文末“参考资料”辅助阅读。
关于 Dify:Dify 是一个易用的 LLMOps 平台,旨在让更多人可以创建可持续运营的原生 AI 应用,提供多种类型应用的可视化编排,应用可开箱即用,也能以后端即服务的 API 提供服务。
引言
目前 TiDB Vector 的功能已经推出,开源了 tidb-vector-python [1],并在两个 AI Agent 引擎中支持了它,具体可以看 LangChain [2]和 LlamaIndex [3]的文档。
但其实这两个开源框架对于非开发者还是略有难度和学习成本,本文介绍了通过 Dify 快速使用 TiDB Vector 搭建 AI Agent。
前期准备
创建 TiDB Vector
目前如果想使用 TiDB Vector 功能暂时还需要申请,预计会很快公测。申请地址是 https://tidb.cloud/ai [4]
申请通过后会收到体验邀请的邮件,收到邮件后就可以登录 TiDB Cloud 来体验了。
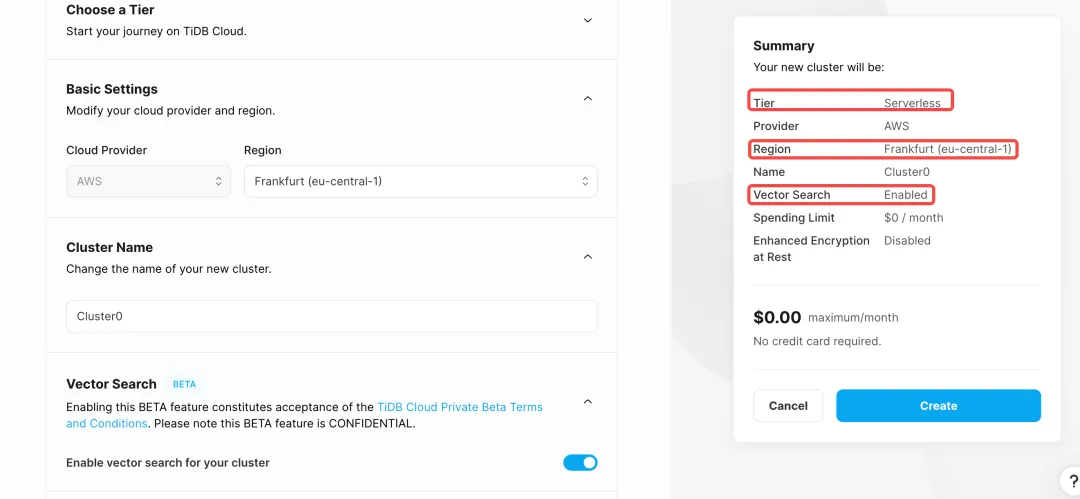
首先让我们创建一个 TiDB Vector 实例:
- 登录 TiDB Cloud 并创建 cluster
- 选择
Serverless并设置 Region 为Frankfurt (eu-central-1) - 开启
Vector Search并设置集群名 - 创建集群
创建好集群后还需要创建一个 shema,执行如下语句
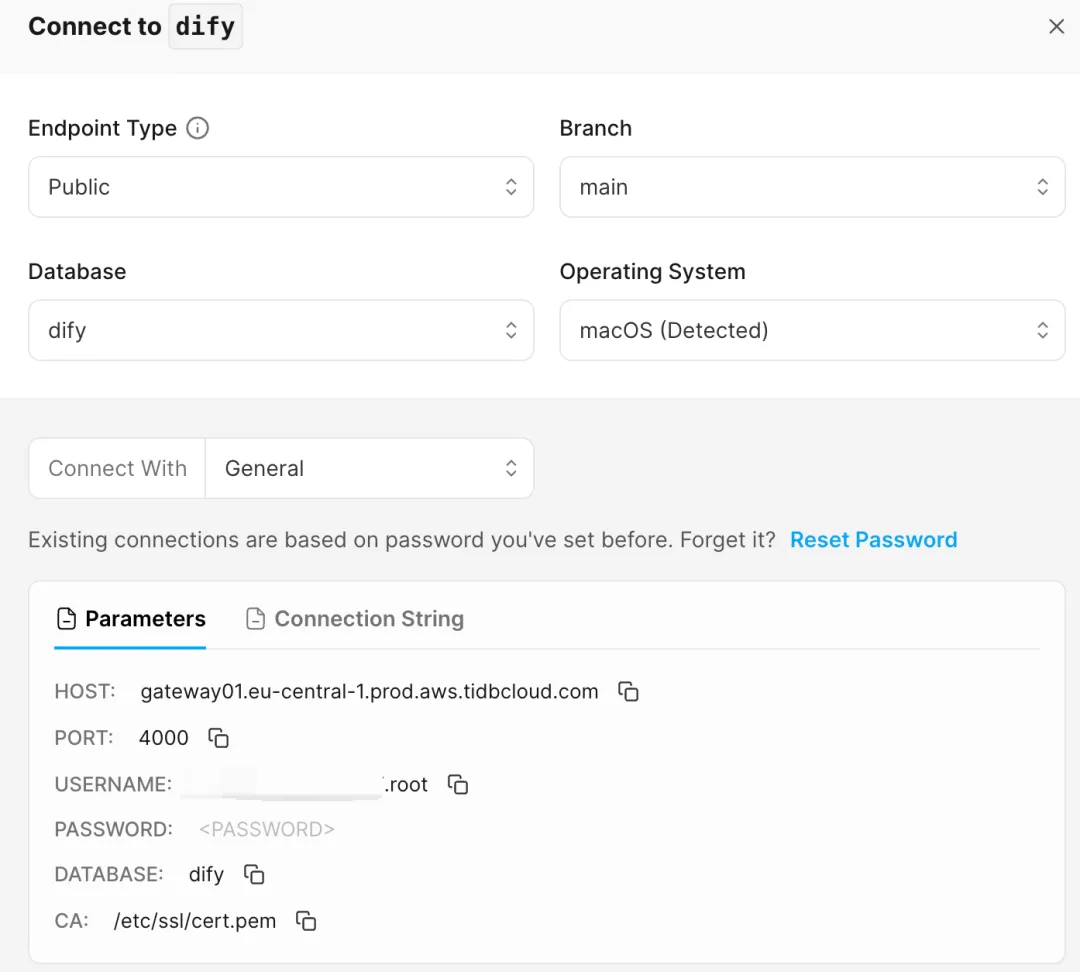
create schema dify;至此,我们已经可以拿到对应数据库的连接配置,请保存下来
部署 Dify
先说说 Dify 是什么?Dify 是一个开源的 LLM 应用开发平台,通过简洁的界面用户可以进行模型管理、搭建 RAG 和 Agent 等,除此之外 Dify 也提供了可观测功能,具体可以看官方文档[5]。
作为个人如果想使用 Dify 有两种方式:云服务和自托管社区版。
Dify 云服务中默认使用的向量数据库是 weaviate [6],所以如果想要将向量库切换成 TiDB Vector,需要使用社区开源版进行自托管。
当前 Dify v6.0.11 已经正式支持 TiDB Vector,可以关注 GIthub Release [7]
这里推荐用 Docker Compose 来部署 Dify,官方文档可以看这里[8]。
Docker Compose 的 yaml 文件可以在开源代码库[9]找到。
为了使用 TiDB Vector,我们需要修改 Docker Compose 中 api 和 worker 的环境变量:
# 将 VECTOR_STORE 修改为 tidb_vector,文件中的默认值是 weaviate
VECTOR_STORE: tidb_vector
# 将以下配置改为保存好的连接 TiDB 配置
TIDB_VECTOR_HOST: xxx.eu-central-1.prod.aws.tidbcloud.com
TIDB_VECTOR_PORT: 4000
TIDB_VECTOR_USER: xxx.root
TIDB_VECTOR_PASSWORD: xxxxxx
TIDB_VECTOR_DATABASE: dify修改完毕后,执行启动命令:
docker compose up -d部署成功后,在浏览器中输入 http://localhost 即可访问 Dify。
基于 Dify 创建 Agent
我们先复习一下用向量库增强大模型 (RAG) 的流程:
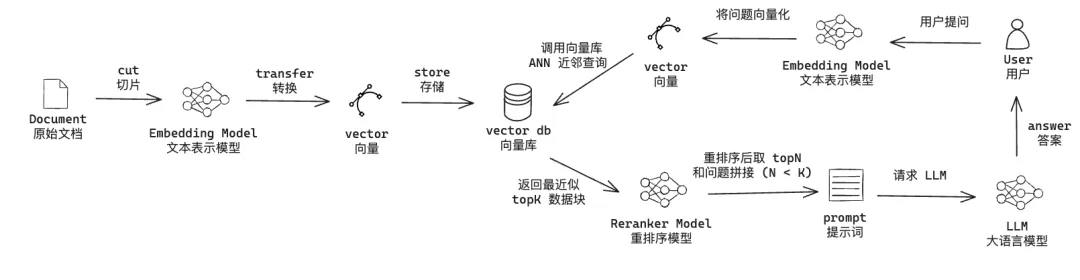
上面这张图主要分为左右两部分:
左半部分是用户上传文档到向量库右半部分是用户使用向量库的数据增加大模型能力用户提出问题将用户的问题通过 Embedding 模型向量化以问题向量化作为查询节点,对向量库进行 ANN 查询,返回 TopK 个近邻节点将 用户问题和 TopK 节点的数据传递给 Reranker 模型进行重排序,并选择重排后的 TopN (N < K)将问题和 TopN 节点的内容拼接成 prompt 作为大模型的上下文调用大模型。
Reranker 模型是非必要的,主要是用于增强 RAG。即使没有也不影响使用,直接将向量库 ANN 查询后的 TopK 拼接到 prompt 上下文即可。
知识库
在上面的准备工作中,我们已经配置好了 TiDB Vector,那么如何在 Dify 配置 Embedding 和 Reranker 模型?
访问 http://localhost ,选择知识库,上传文件并创建。然后进入知识库设置。
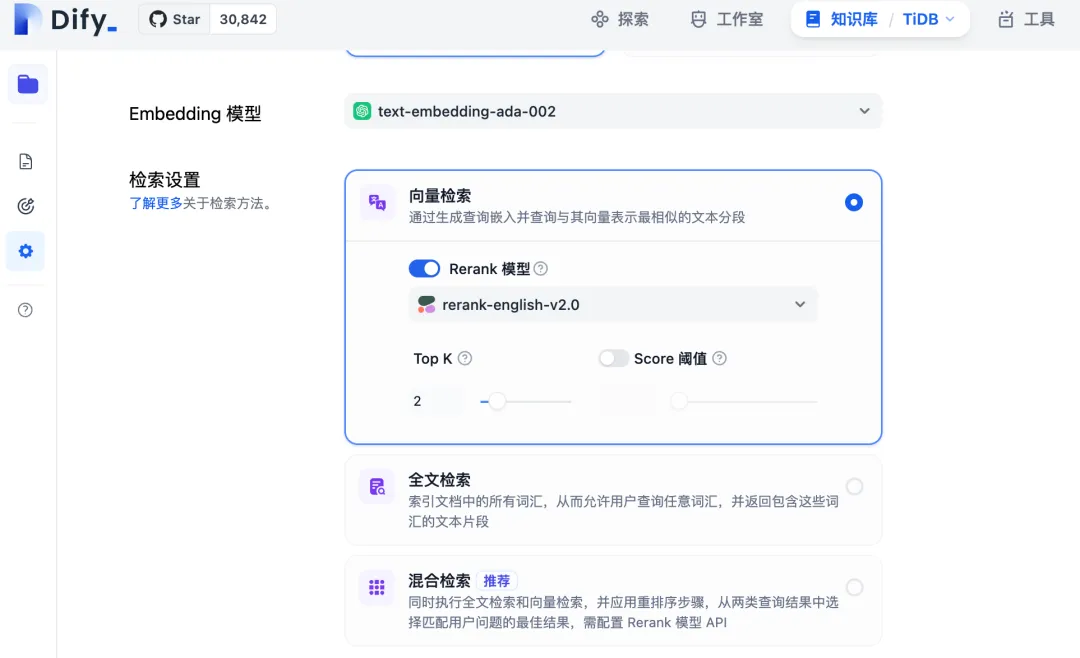
这里可以看到,Dify 针对向量库的检索主要分为 3 种模式:
- 向量检索:基于 ANN 查询的检索,Reranker 模型为可选
- 全文检索:基于 BM25 检索,Reranker 模型为可选(目前 TiDB Vector 类型未支持)
- 混合(向量+全文):ANN + BM25 检索,Reranker 模型为必选
在使用 Embedding 和 Reranker 的时候,需要通过 token 授权。Embedding 模型可以尝试通义千问[10]、MINIMAX[11]、JINA[12] 等等;Reranker 模型可以尝试 JINA[13]、Cohere[14] 等。
智能体 Agent
配置知识库设置并上传文件后,我们就可以创建 Agent 了。
在「工作室」中选择创建空白应用,选择 Agent 并设置图标、名称和描述信息。
进入 Agent 详情后,在上下文中添加我们刚刚创建的知识库。除了知识库之外,我们还可以设置大模型人设、工具等等。这部分操作这里就不在赘述,官方文档[15]写的很全。
完成上面这些操作后,我们已经基于 TiDB Vector 创建好了 Agent。
如果想要在别的平台或者网站使用,可以点击右上角的「发布」。目前 Dify 支持通过 script、iframe 或者 api 接口调用的方式使用 Agent。
源码分析:表结构和 SQL
上面主要讲了操作流程,下面主要介绍一下 Dify 接入 TiDB Vector 后的表结构和 SQL 脚本。增删改查这里不做具体的描述,主要看一下表结构和查询语句。
首先我们看看 Dify 创建的表结构:
CREATE TABLE IF NOT EXISTS ${collection_name} (
# id: 这里的id是在 Dify 中生成 uuid
id CHAR(36) PRIMARY KEY,
# text: 分片后的文本内容
text TEXT NOT NULL,
# meta: 元数据,记录数据集id、文档id、知识库id等,用于条件查询
meta JSON NOT NULL,
# vector: 分片向量,需要设置向量维度
vector VECTOR<FLOAT>(${dimension}) NOT NULL COMMENT "hnsw(distance=${distance_func})",
create_time DATETIME DEFAULT CURRENT_TIMESTAMP,
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);${dimension}表示向量的维度,这个取决于选择的 Embedding 模型。${distance_func}表示用户设置的距离度量方法,目前支持的值有cosine和l2,目前仅支持cosine。
用户输入问题后,查询 TiDB Vector 向量库的 SQL 如下:
SELECT meta, text FROM (
SELECT meta, text, ${tidb_func}(vector, "${query_vector}") as distance
FROM ${collection_name}
ORDER BY distance
LIMIT ${top_k}
) t WHERE distance < ${distance};${query_vector}表示查询向量,即用户问题向量化后的结果${tidb_func}表示 TiDB Vector 中支持的向量距离度量防范,目前支持的方法有Vec_Cosine_Distance和Vec_l2_Distance${top_k}表示结果 TopK 的具体个数${distance}表示向量库中的节点离查询节点的距离,Dify 知识库可以设置距离/分数阈值
拓展
- Vector Search Indexes in TiDB[16]
- Dify 中文文档[17]
- LangChain - TiDB Vector 文档[18]
- LlamaIndex - TiDB Vector Store 文档[19]
- tidb-vector-python 源码 [20]
- Dify 源码[21]
- langchain - tidb_vector 源码[22]
- llama-index-vector-stores-tidbvector 源码[23]
参考资料
[1]tidb-vector-python: https://github.com/pingcap/tidb-vector-python
[2]LangChain: https://python.langchain.com/v0.1/docs/integrations/vectorstores/tidb_vector/
[3]LlamaIndex: https://docs.llamaindex.ai/en/stable/examples/vector_stores/TiDBVector/
[4]TiDB Cloud: https://www.notion.so/TiDB-Vector-Dify-AI-Agent-06b03cc8eaff434fa3064d3a320f3440?pvs=21
[5]官方文档: https://github.com/langgenius/dify/blob/main/README_CN.md
[6]weaviate: https://weaviate.io/
[7]GIthub Release: https://github.com/langgenius/dify/releases
[8]这里: https://docs.dify.ai/v/zh-hans/getting-started/install-self-hosted/docker-compose
[9]开源代码库:https://github.com/langgenius/dify/blob/main/docker/docker-compose.yaml
[10]通义千问: https://help.aliyun.com/zh/dashscope/developer-reference/generic-text-vector/?spm=a2c4g.11186623.0.0.2b31696bUwAwpF
[11]MINIMAX: https://platform.minimaxi.com/document/guides/Embeddings
[12]JINA: https://help.aliyun.com/zh/dashscope/developer-reference/generic-text-vector/?spm=a2c4g.11186623.0.0.2b31696bUwAwpF
[13]JINA: https://jina.ai/reranker
[14]Cohere: https://docs.cohere.com/docs/rerank-2
[15]官方文档: https://docs.dify.ai/v/zh-hans/guides/knowledge-base/integrate_knowledge_within_application
[16]文档: Vector Search Indexes in TiDB: https://docs.google.com/document/d/15eAO0xrvEd6_tTxW_zEko4CECwnnSwQg8GGrqK1Caiw/edit
[17]Dify 中文文档: https://docs.dify.ai/v/zh-hans
[18]LangChain - TiDB Vector 文档: https://python.langchain.com/v0.1/docs/integrations/vectorstores/tidb_vector/
[19]LlamaIndex - TiDB Vector Store 文档: https://docs.llamaindex.ai/en/stable/examples/vector_stores/TiDBVector/
[20]tidb-vector-python 源码: https://github.com/pingcap/tidb-vector-python
[21]Dify 源码: https://github.com/langgenius/dify
[22]langchain - tidb_vector 源码: https://github.com/langchain-ai/langchain/blob/master/libs/community/langchain_community/vectorstores/tidb_vector.py
[23]llama-index-vector-stores-tidbvector 源码: https://github.com/run-llama/llama_index/tree/main/llama-index-integrations/vector_stores/llama-index-vector-stores-tidbvector
目录