作者 hey-hoho,来自神州数码钛合金战队。神州数码钛合金战队是一支致力于为企业提供分布式数据库 TiDB 整体解决方案的专业技术团队。团队成员拥有丰富的数据库从业背景,全部拥有 TiDB 高级资格证书,并活跃于 TiDB 开源社区,是官方认证合作伙伴。目前已为 10+客户提供了专业的 TiDB 交付服务,涵盖金融、证券、物流、电力、政府、零售等重点行业。
导读
TiDB Serverless 上的向量化功能终于开始邀约体验啦!本文是来自 TiDB 社区用户对 TiDB Vector 功能初体验的详细分享,hey-hoho 介绍了他从申请体验到实际操作的全过程,包括创建 TiDB Vector 实例、进行向量检索的初体验,以及实现以图搜图和自然语言搜图的基础应用。如果你对 TiDB Serverless 感兴趣,欢迎了解 TiDB Vector,一起开启 TiDB Serverless 数据库之旅吧!
最早知道 TiDB 要支持向量化的消息应该是在 23 年 10 月份左右,到第一次见到 TiDB Vector 的样子是在今年 1 月初,当时 dongxu 在朋友圈发了一张图:
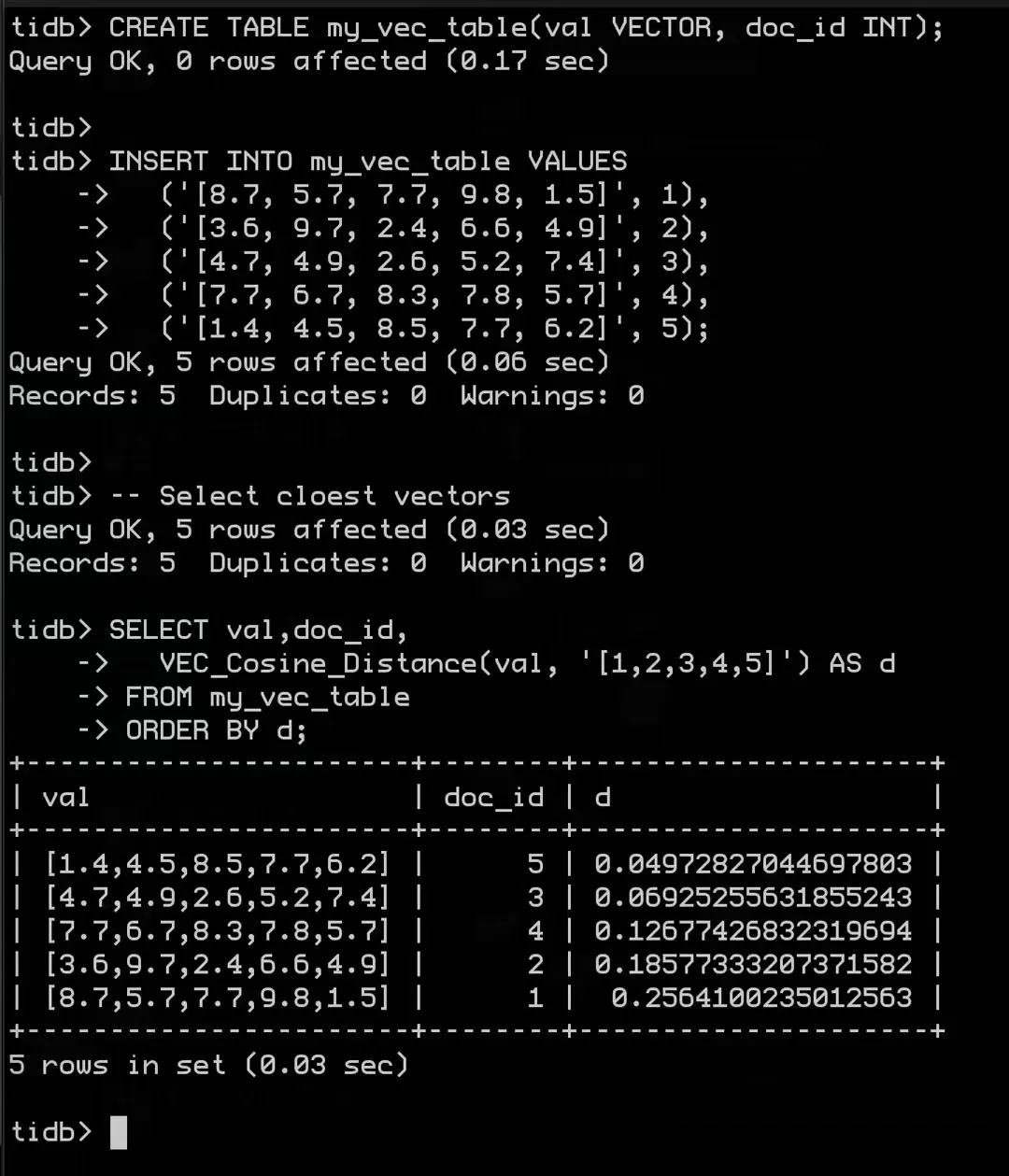
去年我研究了一段时间的向量数据库,一直对 TiDB 向量特性非常期待,看到这张图真的就激动万分,于是第一时间提交了 waitlist 等待体验 private beta。
苦等几个月,它终于来了(目前只对 TiDB Serverless 开放)。迫不及待做个小应用尝尝鲜。
waitlist 申请入口:https://tidb.cloud/ai
体验入口:https://tidbcloud.com/
创建 TiDB Vector 实例
在收到体验邀请邮件后,恭喜你可以开始 TiDB Vector 之旅了。
TiDB Serverless 提供了免费试用额度,对于测试用途绰绰有余,只需要注册一个 TiDB Cloud 账号即可。
创建 TiDB Vector 实例和普通的 TiDB 实例并没有太大区别,在创建集群页面可以看到加入了如下开关:
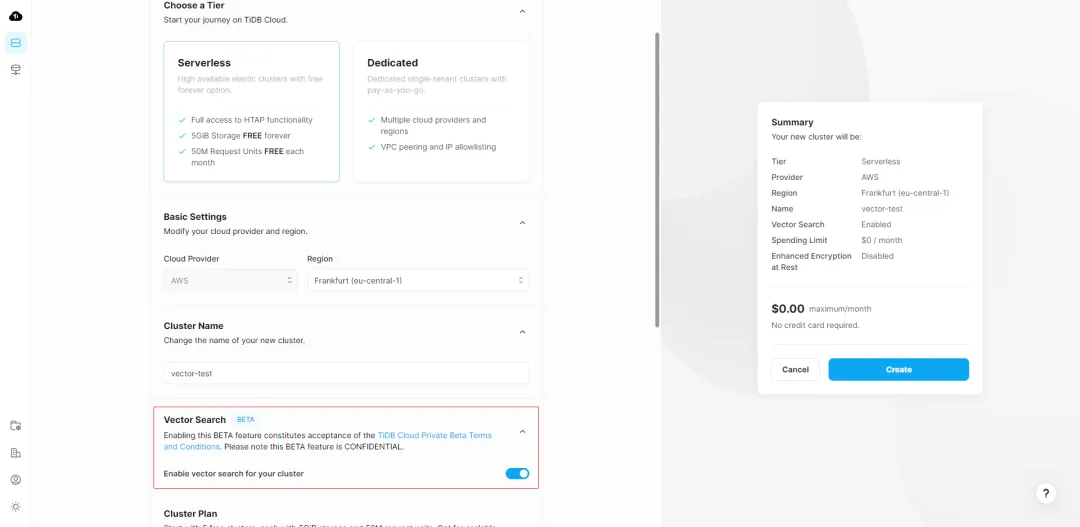
不过要注意的是目前 TiDB Vector 只在部分区域开放,大家可以根据实际情况选择。
这里只需要填一个集群名称就可以开始创建,创建成功后的样子如下所示:
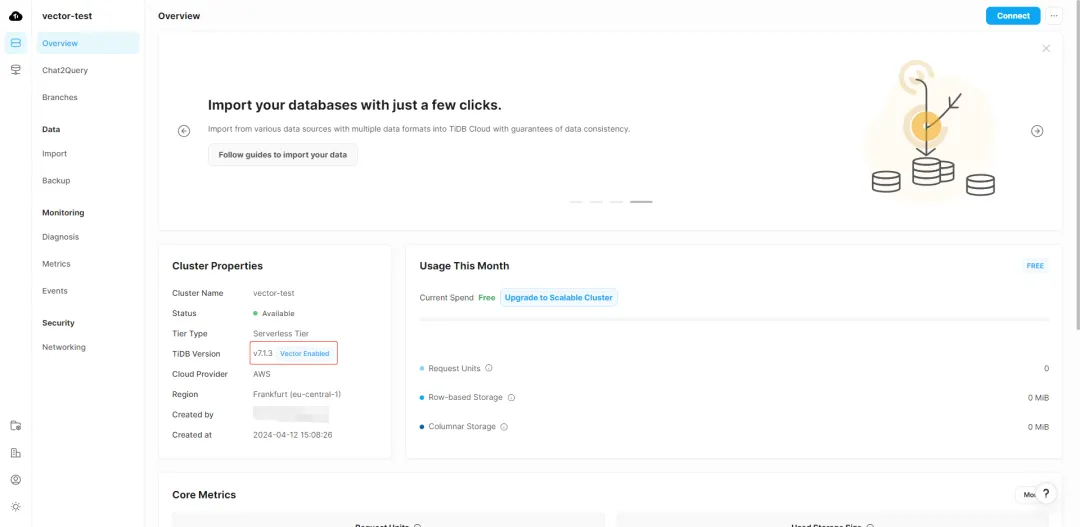
下面开始进入正题。
关于向量的那些事
一些基础概念
-
向量:向量就是一组浮点数,在编程语言中通常体现为 float 数组,数组的长度叫做维度(dim),维度越大精度越高,向量的数学表示是多维坐标系中的一个点。例如 RGB 颜色表示法就是一个简单的向量示例。
-
embedding:中文翻译叫嵌入,感觉不好理解,实质上就是把非结构化数据(文本、语音、图片、视频等)通过一系列算法加工变成向量的过程,这里面的算法叫做模型(model)。
-
向量检索:计算两个向量之间的相似度。
向量检索初体验
连接到 TiDB Serverless 后,就可以体验文章开头图片中的向量操作。
创建一张带有向量字段的表,长度是 3 维。
CREATE TABLE vector_table (
id int PRIMARY KEY,
doc TEXT,
embedding vector < float > (3)
);往表中插入向量数据:
INSERT INTO vector_table VALUES (1, 'apple', '[1,1,1]'), (2, 'banana', '[1,1,2]'), (3, 'dog', '[2,2,2]');根据指定的向量做搜索:
SELECT *, vec_cosine_distance(embedding, '[1,1,3]') as distance FROM vector_table ORDER BY distance LIMIT 3;
+-----------------------+-----------------------+---------------------+
| id | doc | embedding | distance |
+-----------------------+-----------------------+---------------------+
| 2 | banana | [1,1,2] | 0.015268072165338209|
| 3 | dog | [2,2,2] | 0.1296117202215108 |
| 1 | apple | [1,1,1] | 0.1296117202215108 |
+---------+-------------+-----------------------+---------------------+这里的 distance 就是两个向量之间的相似度,这个相似度是用 vec_cosine_distance 函数计算出来的,意味着两个向量之间的夹角越小相似性越高,夹角大小用余弦值来衡量。
还有以一种常用的相似度计算方法是比较两个向量之间的直线距离,称为欧式距离。
这也意味着不管两个向量是否有关联性,总是能计算出一个相似度,distance 越小相似度越高。
向量检索原理
前面大概也提到了两种常用的向量检索方式:余弦相似度和欧式距离,不妨从从最简单的二维向量开始推导一下计算过程。
二维向量对应一个平面坐标系,一个向量就是坐标系中任意一点,要计算两点之间的直线距离用勾股定理很容易就能得出,两点夹角的余弦值也有公式能直接算出来。
拓展到三维坐标系,还是套用上一步的数学公式,只是多了一个坐标。
以此类推到 n 维也是一样的方法。

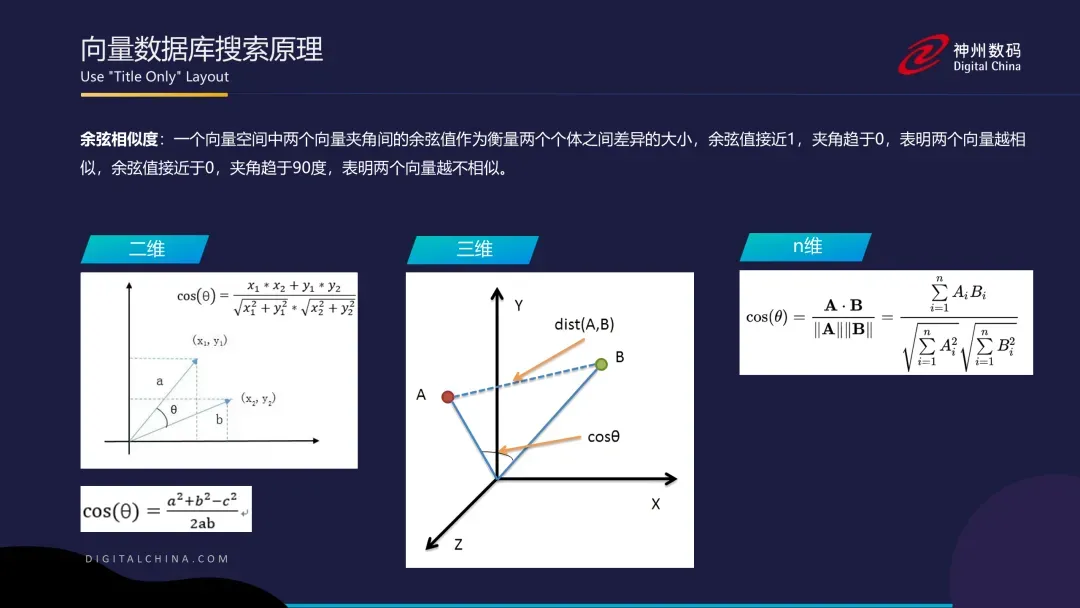
以上内容来自我去年讲的向量数据库公开课:https://www.bilibili.com/video/BV1YP411t7Do
可以发现维数越多,对算力的要求就越高,计算时间就越长。
第一个 TiDB AI 应用:以图搜图
基础实现
借助前面介绍的理论知识,一个以图搜图的流程应该是这样子:

下面我用最简洁直白的代码演示整个流程,方便大家理解。
首先肯定是先连接到 TiDB 实例,目前官方提供了 python SDK 包 tidb_vector ,对 SQLAlchemy、Peewee 这样的 ORM 框架也有支持,具体可参考 https://github.com/pingcap/tidb-vector-python
这里简单起见直接用 pymysql 手写 SQL 操作,以下连接参数都可以从 TiDB Cloud 控制台获取:
import pymysql
def GetConnection():
connection = pymysql.connect(
host = "xxx.xxx.prod.aws.tidbcloud.com",
port = 4000,
user = "xxx.root",
password = "xxx",
database = "test",
ssl_verify_cert = True,
ssl_verify_identity = True,
ssl_ca = "C:\\Users\\59131\\Downloads\\isrgrootx1.pem"
)
return connection再借助 Towhee 来简化 embedding 的处理,里面包含了常用的非结构化数据到向量数据的转换模型,用流水线(pipeline)的形式清晰构建整个处理过程。
from towhee import ops,pipe,AutoPipes,AutoConfig,DataCollection
image_pipe = AutoPipes.pipeline('text_image_embedding')这里使用默认配置构建了一个 text_image_embedding 流水线,它专门用于对文本和图片做向量转换,从引用的源码中可以看到它使用的模型是 clip_vit_base_patch16,默认模态是 image。
@AutoConfig.register
class TextImageEmbeddingConfig(BaseModel):
model: Optional[str] = 'clip_vit_base_patch16'
modality: Optional[str] = 'image'
customize_embedding_op: Optional[Any] = None
normalize_vec: Optional[bool] = True
device: Optional[int] = -1clip_vit_base_patch16 是一个 512 维的模型,因此需要在 TiDB 中创建 512 维的向量字段。
create table if not exists img_list
(
id int PRIMARY KEY,
path varchar(200) not null,
embedding vector<float>(512)
);我准备了 3000 张各种各样的动物图片用于测试,把它们依次加载到 TiDB 中,完整代码为:
def LoadImage(connection):
cursor = connection.cursor()
cursor.execute("create table if not exists img_list (id int PRIMARY KEY, path varchar(200) not null, embedding vector<float>(512));")
img_dir='D:\\\\test\\\\'
files = os.listdir(img_dir)
for i in range(len(files)):
path=os.path.join(img_dir, files[i])
embedding = image_pipe(path).get()[0]
cursor.execute("INSERT INTO img_list VALUE ("+str(i)+",'"+path+"' , '"+np.array2string(embedding, separator=',')+"');")
connection.commit()如果用 ORM 框架的话这里对数据库和向量加工操作会简单些,不需要数组到字符串之间的手工转换。
加载完成后的数据:

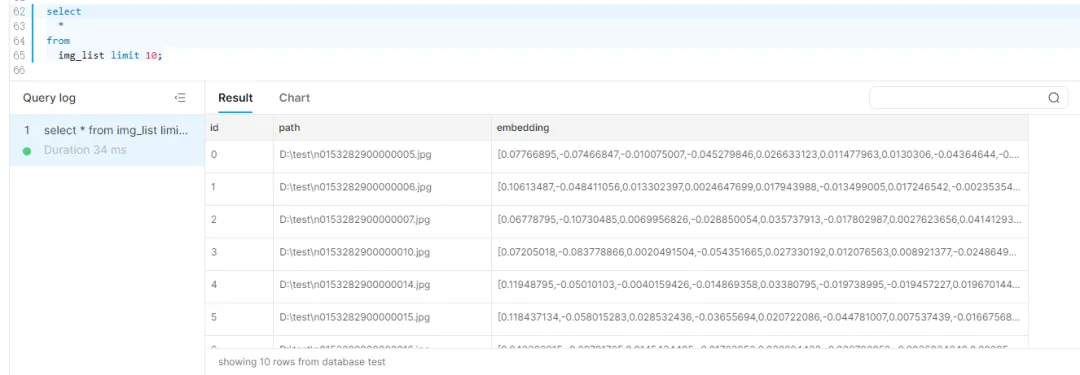
下一步定义出根据指定向量在 TiDB 中检索的函数:
def SearchInTiDB(connection,vector):
cursor = connection.cursor()
begin_time = datetime.datetime.now()
cursor.execute("select id,path,vec_cosine_distance(embedding, '"+np.array2string(vector, separator=',')+"') as distance from img_list order by distance limit 3;")
end_time=datetime.datetime.now()
print("Search time:",(end_time-begin_time).total_seconds())
df =pd.DataFrame(cursor.fetchall())
return df[1]这里根据余弦相似度取出结果最相近的 3 张图片,返回它们的文件路径用于预览显示。
下一步用相同的 image pipeline 给指定图片做 embedding 得到向量,把这个向量传到 TiDB 中去搜索,最后把搜索结果输出显示。
def read_images(img_paths):
imgs = []
op = ops.image_decode.cv2_rgb()
for p in img_paths:
imgs.append(op(p))
return imgs
def ImageSearch(connection,path):
emb = image_pipe(path).get()[0]
res = SearchInTiDB(connection,emb)
p = (
pipe.input('path','search_result')
.map('path', 'img', ops.image_decode.cv2('rgb'))
.map('search_result','prev',read_images)
.output('img','prev')
)
DataCollection(p(path,res)).show()看一下最终搜索效果如何。先看一张已经在图片库存在的图(左边是待搜索的图,右边是搜索结果,按相似度由高到低):
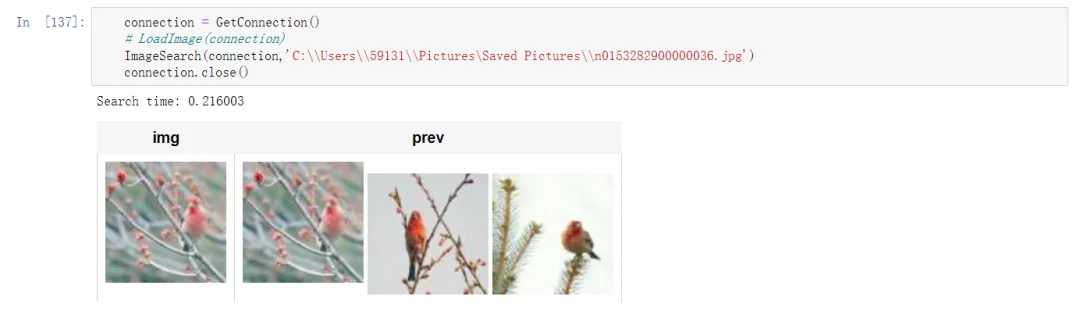
不能说非常相似,只能说是一模一样,准确度非常高!再看一下不在图片库的搜索效果:
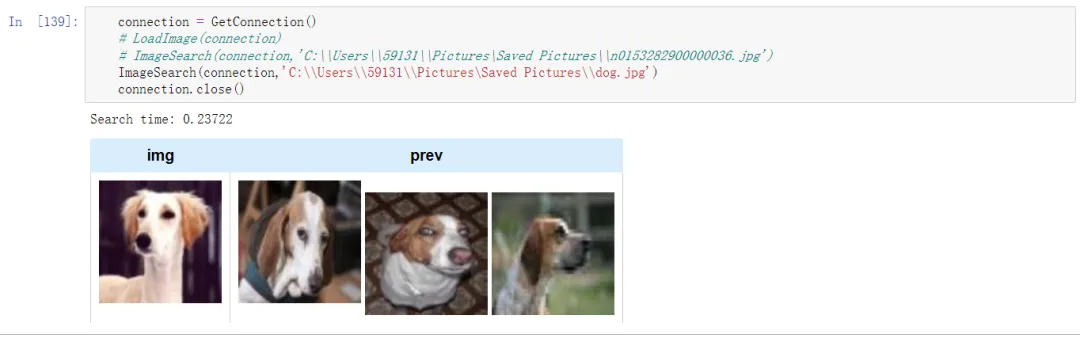
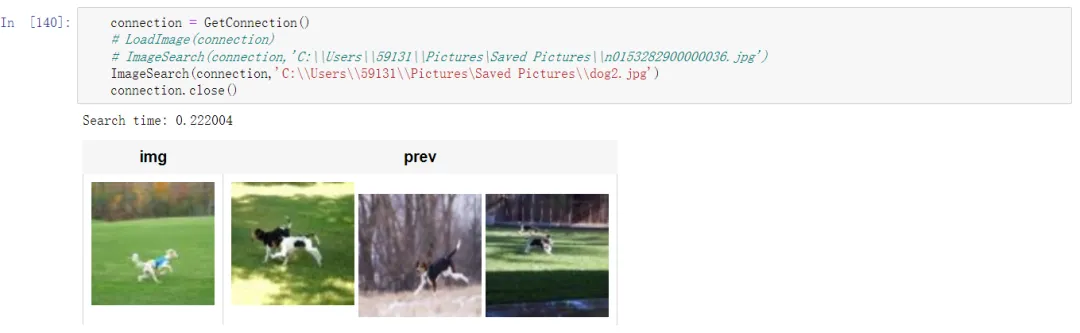
图片库里有几十种动物,能够准确搜索出需要的是狗,特别是第一张从图片色彩、画面角度、动作神态上来说都非常相似。
使用向量索引优化
没错,向量也能加索引,但这个索引和传统的 B+ Tree 索引有些区别。前面提到向量相似度计算是一个非常消耗 CPU 的过程,如果每次计算都采用全量暴力搜索的方式那么无疑效率非常低。上一节演示的案例就是用指定的向量与表里的 3000 个向量逐一计算,最简单粗暴的办法。
向量索引牺牲了一定的准确度来提升性能,通常采用 ANN(近似最近邻搜索) 算法,HNSW 是最知名的算法之一。TiDB Vector 目前对它已经有了支持:
create table if not exists img_list_hnsw
(
id int PRIMARY KEY,
path varchar(200) not null,
embedding vector<float>(512) COMMENT "hnsw(distance=cosine)"
);重新把 3000 张图片加载到新的 img_list_hnsw 表做搜索测试。
以下分别是不带索引和带索引的查询耗时,第二次明显要快很多,如果数据量越大这个差距会越明显,只是目前还无法通过执行计划或其他方式区分出索引使用情况。
E:\GitLocal\AITester>python tidb_vec.py
Search time: 0.320241
+------------------------------------+------------------------------------------------------------------------------------------------------+
| img | prev |
+====================================+======================================================================================================+
| Image shape=(900, 900, 3) mode=RGB | [Image shape=(84, 84, 3) mode=RGB,Image shape=(84, 84, 3) mode=RGB,Image shape=(84, 84, 3) mode=RGB] |
+------------------------------------+------------------------------------------------------------------------------------------------------+
E:\GitLocal\AITester>python tidb_vec.py
Search time: 0.239746
+------------------------------------+------------------------------------------------------------------------------------------------------+
| img | prev |
+====================================+======================================================================================================+
| Image shape=(900, 900, 3) mode=RGB | [Image shape=(84, 84, 3) mode=RGB,Image shape=(84, 84, 3) mode=RGB,Image shape=(84, 84, 3) mode=RGB] |
+------------------------------------+------------------------------------------------------------------------------------------------------+实际在本次测试中发现,使用 HNSW 索引对搜索结果准确度没有任何影响。
自然语言实现图片搜索
本来到这里测试目的已经达到了,突发奇想想试一下用自然语言也来实现图片搜索。于是对代码稍加改造:
def TextSearch(connection,text):
text_conf = AutoConfig.load_config('text_image_embedding')
text_conf.modality = 'text'
text_pipe = AutoPipes.pipeline('text_image_embedding', text_conf)
embedding = text_pipe(text).get()[0]
res=SearchInTiDB(connection,embedding)
p = (
pipe.input('text','search_result')
.map('search_result','prev',read_images)
.output('text','prev')
)
DataCollection(p(text,res)).show()还是用的 clip_vit_base_patch16 模型,只是使用模态改成了文本。通过对文本做 embedding 后得到向量数据送到 TiDB 中进行搜索,流程和前面基本一样。
看一下最终效果:
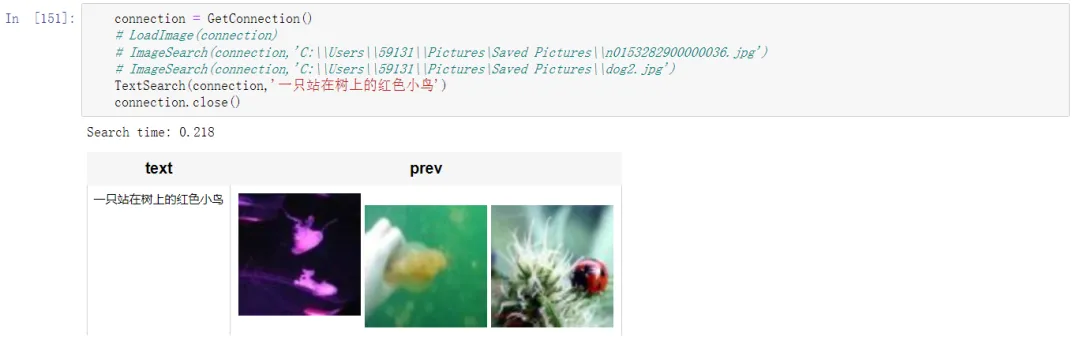
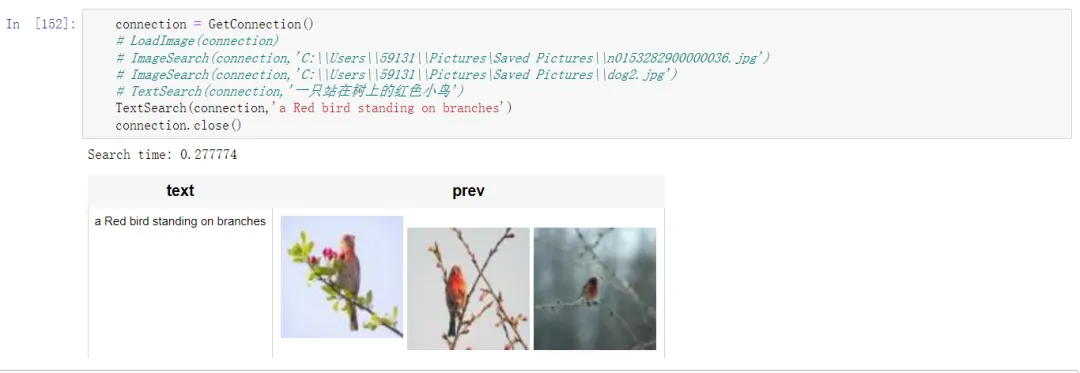
可以发现英文的搜索效果要很多,这个主要是因为模型对于中文理解能力比较差,英文语义下 TiDB 的向量搜索准确度依然非常高。
基于 TiDB Vector,前后不到 100 行代码就实现了以图搜图和自然语言搜图。
未来展望
反正第一时间体验完的感受就是:太香了,强烈推荐给大家!
在以往,想在关系型数据库中对非结构化数据实现搜索是一件不敢想象的事,哪怕是号称无所不能的 PostgreSQL 在向量插件的加持下也没有获得太多关注,这其中有场景、性能、生态等各方面的因素制约。而如今在 AI 大浪潮中,应用场景变得多样化,生态链变得更丰富,TiDB Vector 的诞生恰逢其时。
但是不可忽视的是,传统数据库集成向量化的能力已经是大势所趋,哪怕是 Redis 这样的产品也拥有了向量能力。前有专门的向量数据库阻击,后有各种传统数据库追赶,这注定是一个惨烈的赛道,希望 TiDB 能深度打磨产品,突围成功。
期待的功能:更多的索引类型、GPU 加速等。
当然了,最大的愿望必须是 TiDB On-Premises 中能尽快看到 Vector 的身影。
给 TiDB 点赞!
TiDB Vector waitlist 申请入口:https://tidb.cloud/ai
体验入口:https://tidbcloud.com/
目录