
黄东旭解析 TiDB 的核心优势
1027
2023-04-15
A brief introduction of TiCDC write throughput enlarged by 7x when syncing a single large table
TiCDC 是 TiDB 生态圈的一员,为 TiDB 提供数据同步服务,它订阅上游集群中的 TiKV 节点事务执行过程中产生的数据变更事件,输出到下游目标数据系统(如 TiDB / Kafka / MySQL)。目前被广泛用于异地容灾、异构逃生、数据归档、数据集成等场景。
TiCDC 以表为单位同步数据,为每张表创建一个 Table Pipeline,它由两部分构成:1)KV-Client 和 Puller 模块负责从从 TiKV 拉取数据,写入到 Sorter;2)Mounter 和 Sink 从 Sorter 读取数据,写入到下游目标数据系统。
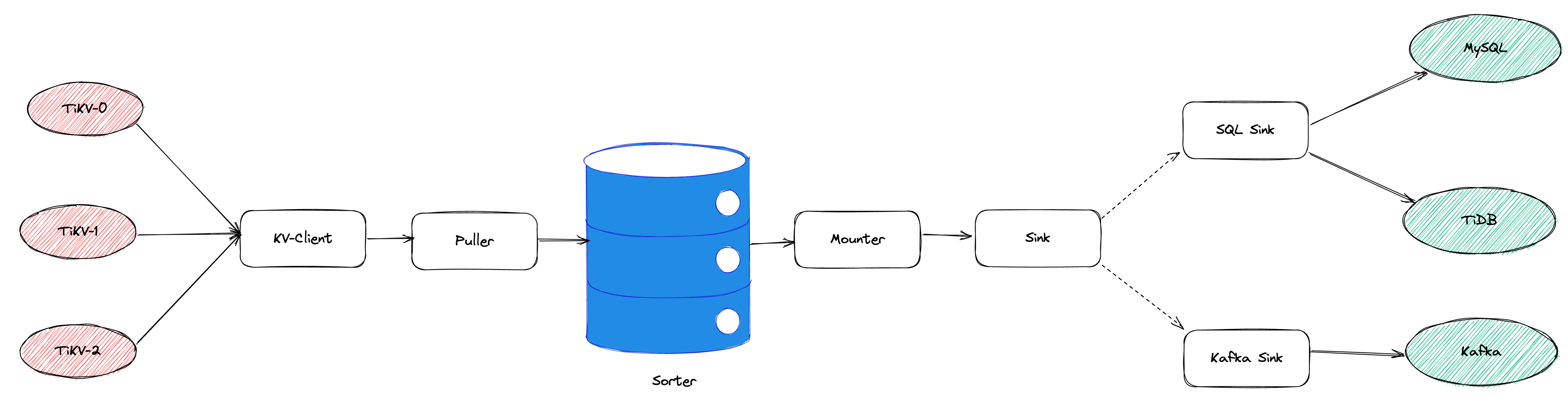
我们收到了一些用户需求反馈,他们希望 TiCDC 能够进一步提升吞吐性能,从而更好地支撑数据归档、大数据集成等场景。我们分析了这些场景的特点,发现它们的工作负载集中在少量的大单表上,具有如下特点:
单表数据规模超过 10T,由超过 200k 的 Region 组成。 数据列数量超过 100,平均行宽约 2k,写入 QPS 达到 10k / s。虽然 TiCDC 具备水平扩展能力,可以通过增加节点的方式来提升处理多张表时的性能,但在当前阶段,一张表只能被一个 CDC 节点处理,因此提升单一节点处理大单表的性能就非常有必要了。
为了定位上述场景下系统的性能瓶颈,我们做了一系列的压力测试和性能分析。我们根据上文所述的大单表的特点构建了相应规模的工作负载,使用 16C,32G 的虚拟机分别部署了一台 TiCDC 节点和 Kafka 节点作为测试环境。
在调查问题的过程中,我们主要通过持续 Profiling 的方式来发现性能瓶颈点,同时结合监控面板,查看 CPU / Memory 等相关计算资源指标,有如下发现:

KV-Client 模块在处理 Resolved Ts 事件时有明显 CPU 开销,近一半的 CPU 时间被 Golang Runtime 占用。

Puller 模块中的 Frontier 组件在处理大量 Resolved Ts 事件时也有显著的 CPU 开销。
我们再来看一下数据从 Sorter 流出之后的处理过程。Mounter 会对从 Sorter 读取到的数据进行解码,生成一个新的内部数据结构,然后就交给 Sink 模块,后者将事件发送到目标数据系统。
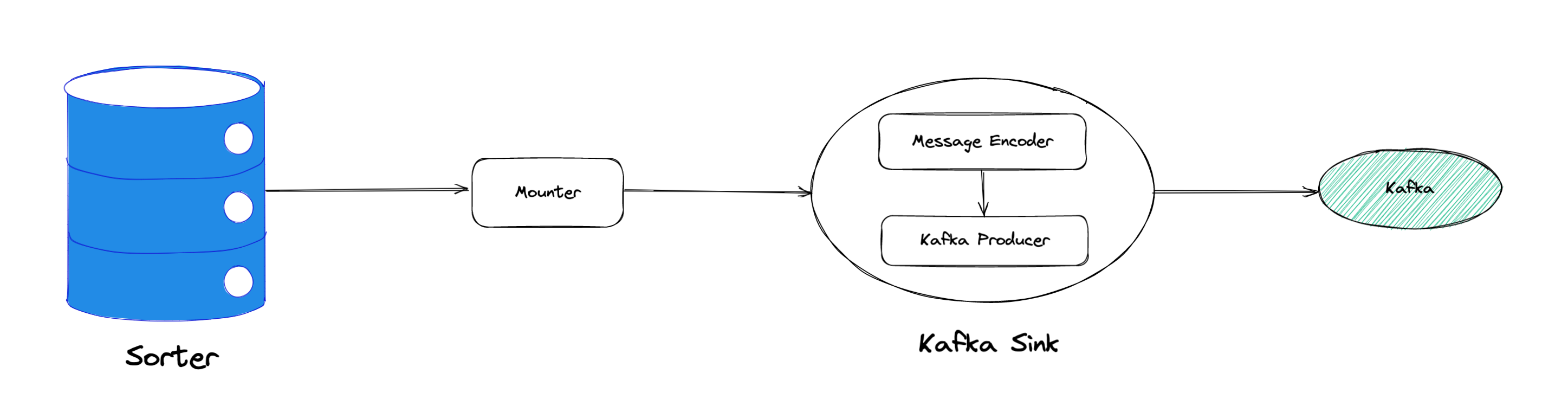
从上图中我们可以看到,Mounter 和 Sink 是一个顺序关系。如果 Mounter 模块的吞吐量不足,势必会影响 Sink 模块的吞吐量。我们对 Mounter 模块的吞吐量做了 Benchmark 定量分析。我们使用了一种特殊的 Sink,它会将从 Mounter 接收到的数据直接丢弃,这种情况下我们认为 Sink 的吞吐量不是性能瓶颈。在测试中发现,这种情况下 Sink 的吞吐量只有 5k/s 左右,这说明数据流入 Sink 的速率不足,也就说明了 Mounter 模块的吞吐量不足,是必须优先解决的性能瓶颈。
在 Kafka Sink 内部,首先会由 Encoder 模块将数据编码成特定的格式,然后交给 Kafka Producer 发送到目标 Kafka 集群。我们使用了和测试 Mounter 吞吐量类似的策略,来测试 Encoder 的性能,发现 Encoder 模块也存在吞吐量不足的问题。

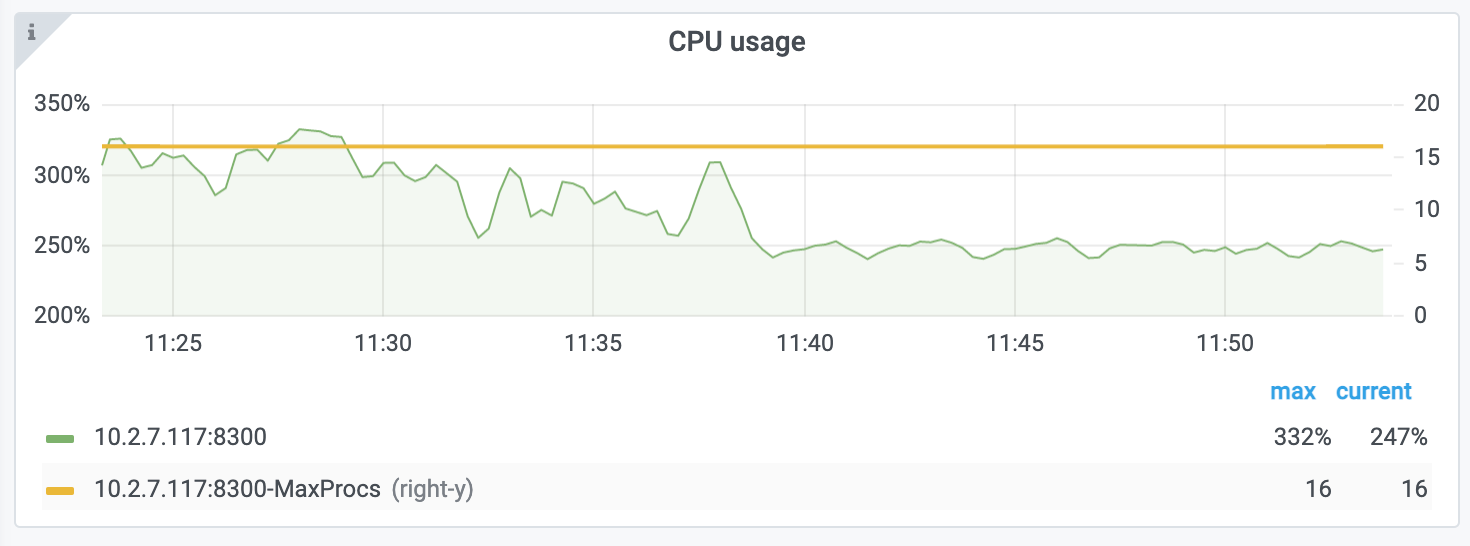
同时,我们也查看了 CPU Profiling 。Mounter 模块和 Sink 内部的 Encoder 模块的 CPU 开销相对其他模块更为显著。同时查看监控发现,CPU 资源的整体使用率并不高,TiCDC 所在的机器有 16C,但 CPU 利用率不足 300%。Mounter 和 Encoder 的主要工作是对数据进行编解码,属于 CPU 密集型任务,所以在 Profiling 上看起来较为突出是正常的。整体 CPU 使用率低说明当前的数据消费链路对 CPU 使用效率低下,提升整体 CPU 使用率是解决问题的重要途径。
经过上述性能测试和剖析 (Profiling),确定了整条 Table Pipeline 链路上需要被优化的性能瓶颈点。KV-Client 和 Puller 模块对 Region 数量颇为敏感,海量 Region 带来的大量 Resolved Ts 事件给二者带来了不可忽视的压力,因此有必要提升二者在处理 Resolved Ts 事件时的效率。对于 Mounter 和 Sink 模块,消除 Mounter 模块和 Encoder 模块的吞吐量瓶颈,是提升 TiCDC 吞吐量性能的关键。
KV-Client 和 Puller 模块需要处理的 Resolved Ts 事件数量,和被监听的 Region 数量成正比,这是造成二者 CPU 开销高的主要因素。
当前的 KV-Client 模块逐个处理 Resolved Ts 事件,这显然不是一个高效的方案。我们对其做出了改进了,让它批量地处理 Resolved Ts 事件,从而减少相关函数调用引起的上下文切换,降低 CPU 开销。同时优化了实现细节,降低模块内多线程并发访问过程中占用锁带来的 CPU 开销。测试结果表明,200k Regions 的场景下,CPU 使用率下降了 50%。
Frontier 组件 采用最小堆来维护所有 Regions 的 Resolved Ts,输出最小值作为表级别的 Resolved Ts。每次处理 Resolved Ts 事件时需要检查最小堆中的所有元素,以应对 Region 发生分裂合并导致的 Region 变更情况,所以 CPU 开销明显。我们认为在一般场景下,绝大多数 Region 不会发生频繁的分裂合并。基于这一假设改进了 Frontier 的计算逻辑,在检测到没有 Region 发生变化的情况下,通过快速路径计算得到表级别的 Resolved Ts,这一改进提升了处理 Resolved Ts 事件的效率,测试结果表明 CPU 使用效率再次下降了 50%。
上述两个优化工作完成之后,KV-Client 和 Puller 模块应对海量 Region 时的 CPU 开销有明显的下降,这也使得 TiCDC 能够更加高效地应对有大量 Region 的场景,在相同资源的情况下,支持比以前更大规模的数据量。
为了提升 Mounter 和 Encoder 的吞吐性能,对二者进行了多线程改造,提出了 Mounter Group 和 Encoder Group 模块。
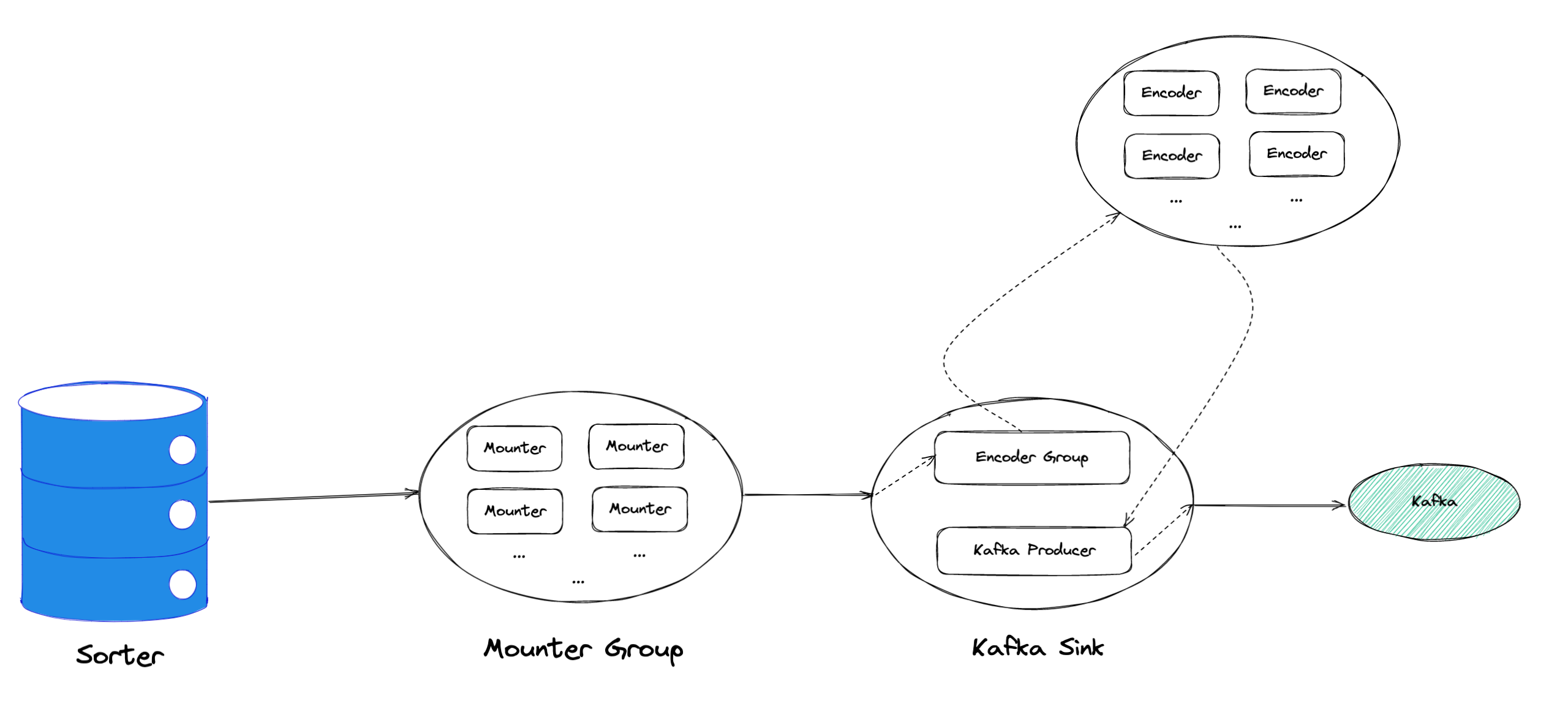
如上图所示,Mounter Group 内部维护了多个 Mounter 实例,批量地输入数据,并发地进行数据解码工作,提升整体解码效率。测试结果表明,Mounter Group 的吞吐量有 10 倍左右的提升。
Encoder Group 的实现和前者类似,并发地对执行数据编码工作,吞吐性能也得到了显著提升。我们分析了 Kafka Sink 内部的运行过程,可以分为 3 个步骤:接收数据,使用 Encoder 编码数据,然后经由 Kafka Producer 发送到目标 Kafka 集群。我们发现这三个步骤是串行执行的,于是我们对这三个步骤做了多线程改造,“接收数据,编码数据,发送数据” 3 个过程以流水线的方式运行,这进一步提升了 Kafka Sink 的运行效率。


Encoder 的编码效率也是一个影响吞吐量的重要因素。Canal-JSON 是我们推荐的一种编码协议,它使用 Golang 标准库的 JSON 库对数据进行编码工作。如上图-8 所示,CPU 开销显著,同时有明显的垃圾回收开销。图-9 是对应时段的内存分配对象 Profiling,可以看到在编码过程中分配了大量的对象,内存占用量明显。对此我们选择使用 easyjson 更为高效地生成 JSON 编码,这使得 Canal-JSON Encoder 的效率得到提升,不仅编码速度更快,而且减少了内存分配开销,降低了 GC 压力。
在完成了上述优化工作之后,我们使用 v6.3.0 版本的 TiCDC 作为参考对象,比较了优化前后吞吐性能之间的差异。我们使用的测试负载特点如下,单行数据有 60 个字段,单行数据长度约为 1.2k,我们认为这种规格的表具有代表性。在测试过程中,向上游 TiDB 集群写入 10,000,000 行数据,保证有足够的上游写入压力。测试环境和之前调查问题时使用的相同。
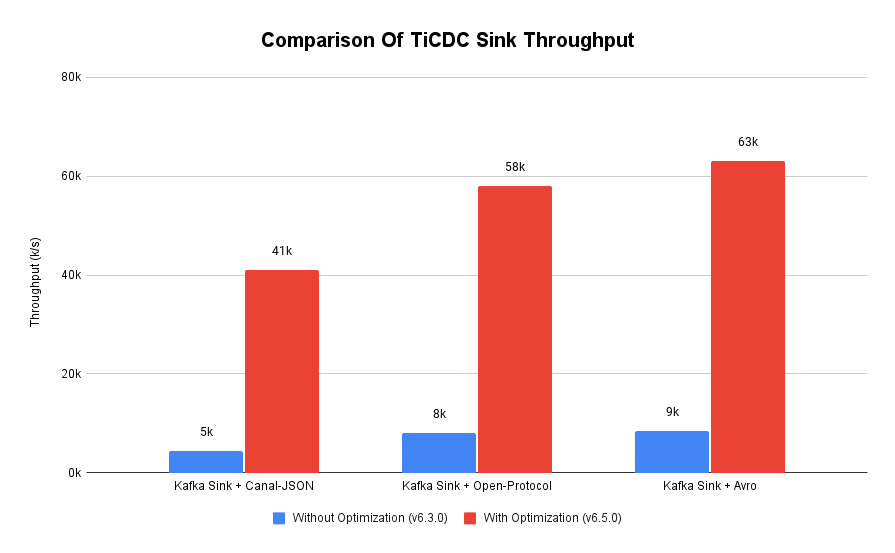
我们分别测试了 Canal-JSON , Avro , Open-protocol 3 种协议对 Kafka Sink 吞吐量的影响。从上图中我们可以看到,在使用不同编码协议时,Kafka Sink 吞吐量有明显差异。Avro 格式编码实现高效,测试中显示出最好的性能。而 Canal-JSON 格式较为复杂,针对每个数据列都携带有元数据,编码开销更大,所以性能有所下降。与前面两者不同的是,Open-Protocol 在编码时会将多行数据编码到一个消息中,均摊了编码开销,也取得了不错的吞吐性能。
本文讲述了针对大单表场景,我们做出的一系列性能分析和优化工作,在吞吐量指标上取得了显著的提升,Kafka Sink 的吞吐量提升了 7 倍有余。在未来我们依旧会针对该问题开展更多改进工作,比如我们发现 TiCDC 使用的第三方 Kafka 客户端实现存在性能瓶颈,是限制进一步提升 TiCDC Kafka Sink 吞吐量的主要因素,我们会在未来解决该问题。MySQL Sink 的性能目前还有待继续提升,我们会对它进行更多开发优化工作。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

