

黄东旭解析 TiDB 的核心优势
696
2023-04-15
在 2023 伊始,我们很高兴向大家宣布,TiDB 6.5 LTS 版本已经发布了。这是 TiDB V6 的第二个长期支持版(上一个是 TiDB 6.1 ),除了携带了诸多备受期待的新特性,同时也将得到 TiDB 开发社区的长期维护,是推荐企业级用户采用的最新版本。

在这个版本中,TiDB 专注于如下几个主题:
产品易用性进一步提升 内核不断打磨,更加成熟 多样化的灾备能力 应用开发者生态构建相信长期关注我们的朋友已经发现,这些主题似曾相识。的确如此,TiDB 近年的发展几乎都围绕着它们开展。我们期望 TiDB 成为更易用,对开发者更友好,且更成熟的企业级数据库,而这个追求也并没有尽头。
大家也许不止一次听说过,易用性之于 TiDB 是非常关键的理念。毕竟,TiDB 伊始是为了解决分库分表带来的麻烦,这也使得易用性在 TiDB 研发过程中贯穿始终。在新版本中,我们提供了更多的让用户解放心智的能力。
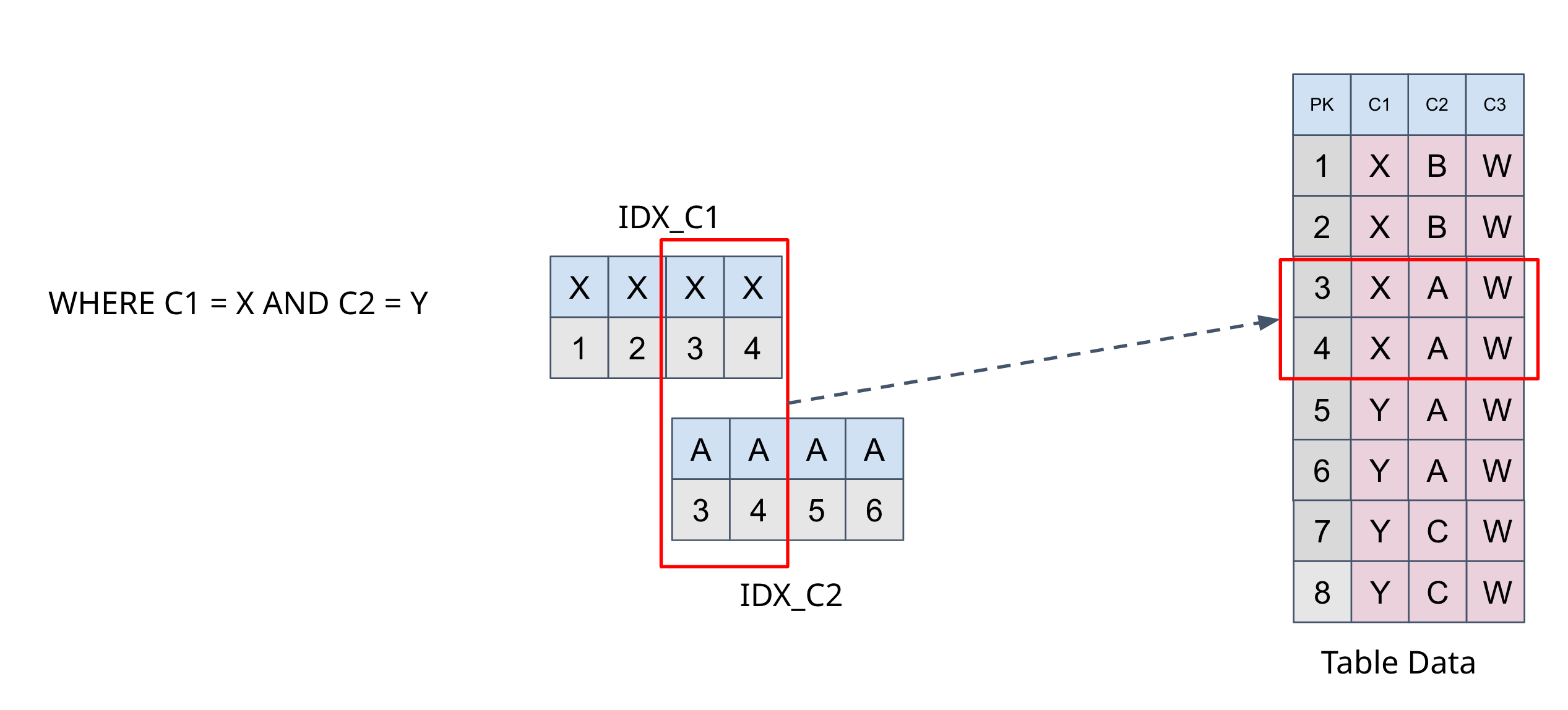
对于数据服务和洞察场景,用户往往会基于诸多查询条件的组合进行数据筛选。例如在物流场景中,用户可能会根据下单日,仓库 ID,转运人,送达日,目标地址等等不同维度进行筛选再分析。而这些条件单独来看,并不一定具备很好的选择性,只有组合起来才能将数据限定在一个小范围。如果条件的组合不多,我们尚可使用特定的组合索引覆盖,但很可能在这类场景中,组合以数十记,完全无法为每个组合都创建特定索引。在新版本中,TiDB 支持根据 AND 条件组合同时选中多组索引,并计算它们的交集再读取实际表数据。这种能力,使得用户可以仅仅为单列创建少量索引,以达到更好的选择性以及更优的性能。
有时候,用户会希望整个集群快速恢复到之前的某个时间点。例如,由于游戏服务器新版本数据设定问题,将一把绝世好剑设定为 1 元,造成新版发布后一小时内人手一把。若仅仅如此也就算了,开发者可以很容易回收或这个道具,但这种事故还有次生灾害,例如稀有 Boss 被滥杀,稀有掉落随之泛滥,整个游戏内容崩坏。这时候作为游戏设计师,你可能会希望时间能回到犯错之前的那一刻,让你修正那个令人追悔莫及的错误。在新版本中,TiDB 就提供了这个能力,它支持用简单一条命令向 GC 时间内的任意时间点进行全集群闪回,就像下面这样。
FLASHBACK CLUSTER TO TIMESTAMP 2022-09-28 17:24:16;我们当然希望这不会是一个常见的状况,但这并不表示需要闪回的时机千年难遇:闪回能力也可用于日常操作,例如将测试环境恢复到测试开始前的状态,以供反复使用。
在前序版本中,我们支持了针对删除的大事务自动拆分支持。而在新版本中,TiDB 完整支持了针对插入和修改的大事务拆分。在以往版本中,TiDB 用户经常要面对的一个问题就是,一些大规模的数据变更维护操作,例如过期数据删除,大范围数据修订,或者根据查询结果回写数据等操作,会遇到超过 TiDB 单条事务上限的问题,这是由于 TiDB 单一事务需要由单一 TiDB Server 作为提交方而带来的限制,这时候用户往往不得不手动想办法拆小事务以绕过该限制。但在实际使用中,上述类型的数据变更未必真的需要作为单一事务确保原子性,例如数据淘汰和数据修订,只要最终执行完成,哪怕事务被拆开多次执行也并不会影响使用。在 TiDB 6.5 中,我们提供了将大事务自动拆分的能力,例如按照 t1.id 以 10000 条为大小分批数据更新,可以简单使用如下语句完成:
BATCH ON t1.id LIMIT 10000 update t1 join t2 on t1.a=t2.a set t1.a=t1.a*1000;更详细的说明请 参考文档 。
TiFlash 在过往版本中有一个很大的缺憾是无法在读写事务中使用:经常用户希望将 TiFlash 的计算结果进行回写以供高并发读取(类似物化效果)。从 v6.5.0 起,TiFlash 支持通过 INSERT SELECT 语句回写结果进行物化,节省系统资源并提高响应速度。
INSERT INTO top_payments SELECT MAX(amount) FROM payments;在执行上述 INSERT INTO SELECT 语句时,TiDB 可以将 SELECT 子查询下推到 TiFlash 以提供高速分析计算,并将返回结果通过 INSERT INTO 可以保存到指定的 TiDB 表中。值得一提的是,该功能结合前述大事务拆分可以实现大量结果集物化。
TiDB 作为一款分布式数据库,以往在使用 AUTO INCREMENT 列创建主键时,仅保证在每个 TiDB 实例中序列递增,而跨 TiDB 实例则无法保证。但实际使用中,用户仍然经常会遇到需要严格单调递增主键的时候,例如以主键隐式代表时间维度,确定事件发生顺序。在 6.4 版本中,我们加入了高性能的全局单调递增主键的支持,以兼容 MySQL 的行为。该模式下,TiDB 将采取中心化的主键分配以确保单调递增,即使跨 TiDB 实例访问,ID 也不会出现回退,且针对其的写入也可轻松达到数万的 TPS。
维护数据的生命周期在 TB 以上规模下并不是很容易的事情:由于数据规模大,寻找并清理过期的数据往往需要消耗相当的算力,有时用户为了更快清理数据甚至被迫使用分区表,以删除分区的方式来进行快速清理。更麻烦的是,用户需要维护特定的任务以不断定期淘汰数据。在新版本中,TiDB 提供了 Time to Live (TTL) 能力,使得用户可以设定行级别的生命周期控制策略。通过为表设置 TTL 属性,TiDB 可以周期性地自动检查并清理表中的过期数据。当开启时,TTL 会以表为单位,并发地分发不同的任务到不同的 TiDB 实例节点上,进行并行删除处理,且不影响集群性能。更详细的说明请 参考文档 。
TiDB 包含繁多的特性集合,但其中有些仍需不断打磨,例如 JSON 虽然已获支持许久,但实际能力却尚需完善。在新版本中,我们针对重要特性集合用力打磨,以期提供给用户更「丝滑」的体验,让 TiDB 的重大特性以更完善的方式呈现在用户面前,也让 TiDB 演进方式更稳重更有质量。
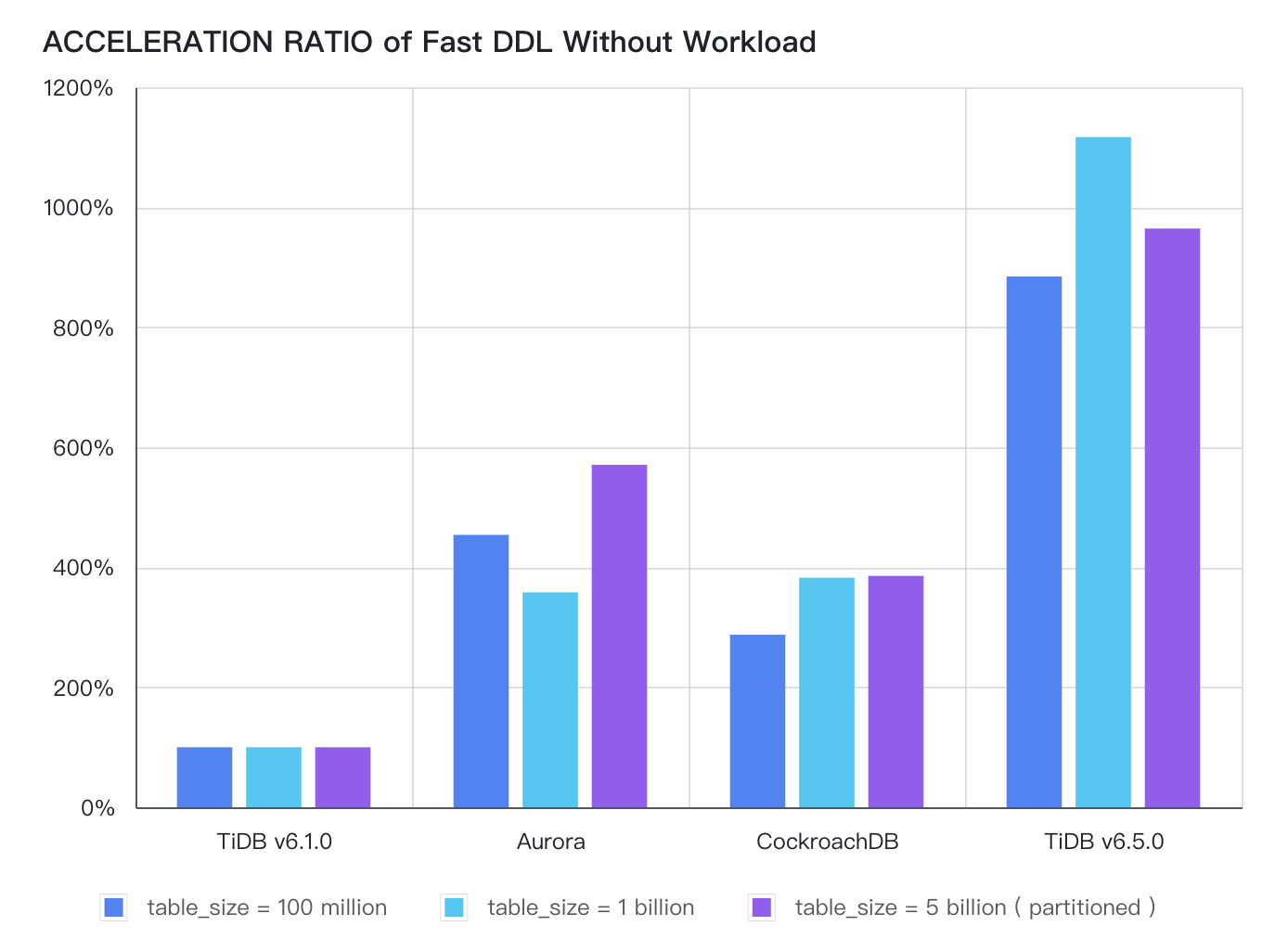
首先是 DDL 加强。支持在线 DDL 是 TiDB 的核心优势之一,在过往一年中,我们加入了对并行 DDL 的支持,使得以往在 SaaS 等多租户场景因 DDL 串行执行互相阻塞导致的 DDL 语句间执行效率低的问题得以解决,通过引入 Metadata Lock 基本消除了 DDL 干扰 DML 的情况。在新的 6.5 版本中,TiDB 支持了类似 Lightning 注入 SST 的设计,针对需要追溯的历史数据直接使用 SST 构建的方式进行生成,大幅提高了 DDL 的构建速度,最快可达 10 倍提升。
如下图所示,以 TiDB 6.1 版本为基准值,新版除了取得了数量级的提速,且对比 CockroachDB v22.2 和当前版的 AWS Aurora 也快 2-3 倍。
其次是 JSON 的支持打磨。JSON 对于需要灵活数据结构的场景非常重要,因此在移动端,游戏开发等场景中广泛使用。从 6.2 版本以来,TiDB 陆续引入了完整的 MySQL 5.7 兼容函数,针对 JSON 的表达式索引支持,更多的生态工具兼容。新版本支持将 JSON 函数 "->"、"->>"、"JSON_EXTRACT()" 下推至 TiFlash,可以提高 JSON 类型数据的分析效率,拓展 TiDB 实时分析的应用场景。
再者是 TiDB 全局内存控制。自 v6.5.0 起,TiDB 全局内存控制已能够跟踪到 TiDB 中主要的内存消耗。当单个会话的内存消耗达到系统变量 tidb_mem_quota_query 所定义的阈值时,将会触发系统变量 tidb_mem_oom_action 所定义的行为 (默认为 CANCEL,即取消操作)。当全局内存消耗达到 tidb_server_memory_limit 所定义的预设值时,TiDB 会尝试 GC 或取消 SQL 操作等方法限制内存使用,保证 TiDB 的稳定性,对内存的使用效率也更加高效。
最后是降低累积的悲观锁对性能的影响。 在一部分交易系统,尤其是银行业务中,客户应用会在悲观事务中利用 select for update 先锁定一条记录,从而达到对数据一致性的保护,减少事务中后续操作失败的可能,比如
BEGIN; SELECT c FROM sbtest1 WHERE id = 100 FOR UPDATE; UPDATE sbtest1 SET k = k + 1 WHERE k = ?; COMMIT;而在 TiDB 中,对一行记录反复的 select for update,会造成这条记录的查询性能下降。 在 v6.5.0 中,我们对这部分机制进行了优化, 通过记录连续的锁标记,降低了累积的悲观锁对查询性能的影响,QPS 可大幅提升 10 倍以上。
在过往版本中,TiDB 主要依赖 BR 进行静态的备份恢复,而在 6.2 之后的新版中,TiDB 提供了 PITR 能力,使得数据库可以更灵活地恢复到任意时间点。
TiDB PITR(Point-in-Time Recovery)是结合了 BR 和变更捕获(Change Data Capture)两种能力的灾备特性。以往 BR 的静态灾备只能将数据恢复到备份的时间点,如果要更提供针对更新和更多时间点的恢复,则相应需要提高备份频率。这不但会加重备份对在线业务的负担,也需要更多存储成本。使用 PITR 则可以摆脱这个烦恼,用户无需不断进行全量备份,而是可经由一个全量备份结合增量共同完成针对任意时间点的数据恢复。
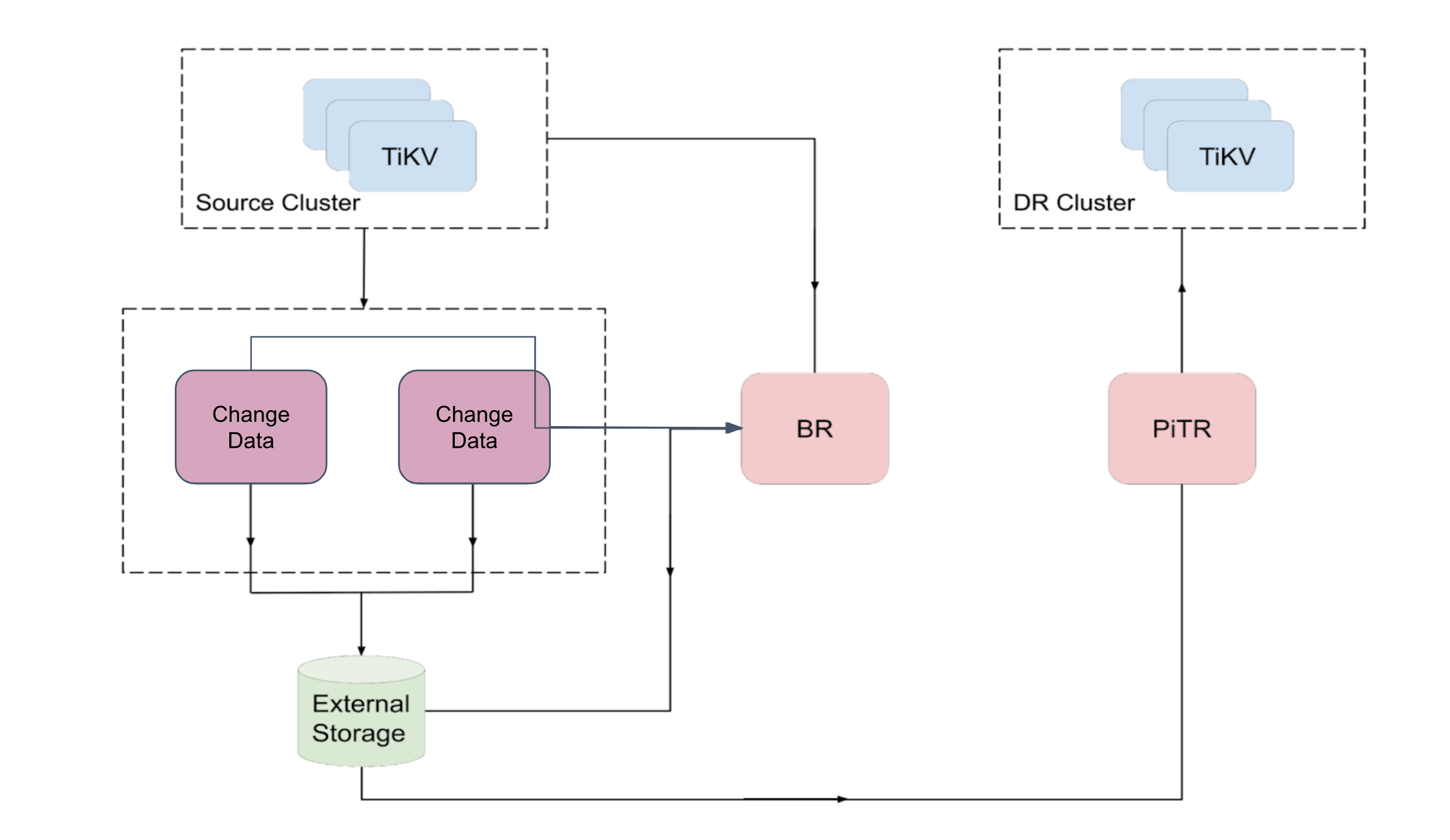
经过半年左右的持续改进,在新版本中,我们减少了 PITR 备份文件大小和数量,加强了稳定性,提升了性能。 例如:确保在绝大多数异常场景下 RPO < 5mins, 单个 TiKV 的备份速度达到100MB/s等。
与此同时,在 6.5 版本中,TiCDC 的吞吐获得了得了至数倍的提升。通过对 TiCDC 内部的设计和实现的不断优化,针对数据复制场景,当下游为 Kafka 集群时,针对大单表场景的吞吐量得到了极大的提升,单个 TiCDC 节点可以支持35k row/s QPS,吞吐量可以达到 50MB/s,并将延迟控制在 2 秒左右,而内存使用量只有之前版本的50%左右。 针对跨区域主备集群容灾场景,TiCDC 单个节点的吞吐量可以达到 30MB/s,并且其延迟也可以稳定在 2 秒左右,稳定性大幅度提高。
其次,在6.5 版本中,DM 正式发布了在数据迁移过程中的增量数据持续校验功能,该特性只对新增或变更的数据进行校验,而不是对整个数据集进行校验,在确保数据迁移过程的准确性和可靠性的同时,大大减少数据校验的时间和资源消耗。尤其是在迁移一些重要系统时,该特性可以让数据迁移过程更加安全。
除此以外,新版本支持了在下游集群使用水位线进行一致性读取的能力:在新版本中,TiCDC 可以在向下游写入时提供特殊的时间戳,而下游集群则可以自动使用该时间戳进行一致性读取而无需担心读到的事务不完整。这使得下游集群在需要严苛事务保证的场景下,也可以良好承担读流量分流的职责。
在以往版本中,TiDB 更强调 DBA 的使用体验。但在近期的更新中,你也许已经发现我们逐渐开始聚焦 DBA 以外的应用开发者体验。在新版中,我们强化了应用开发所需的生态环境构建,例如这半年来 TiDB 通过增加对 Savepoint,User Level Lock,Multiple Schema Change 等功能的支持,完善了针对常见应用框架 django,prisma 等的支持。与此同时,我们也引入了更多上下游生态厂商的战略合作:Vercel,Hashicorp,Retool 等。在 6.5 版本中,TiCDC 增加了针对向 Object Storage 写入的支持。对象存储是一种面向云的存储服务,具有高可扩展性、高可用性、低成本等优势。使用 TiCDC 将数据同步到对象存储,可以帮助用户实现数据的长期存储、数据的跨区域复制等目的。另外,这使得 TiDB 在云环境下能直接打通向数仓和数据湖环境的通路。更好的生态支持,将使得开发者在使用 TiDB 构建应用时,拥有更多选择,也更简便。
作为 TiDB 版本 6 的第二个长期支持版,TiDB 6.5 已经发布。我们希望借助这个版本为更多用户提供更易用且更成熟的企业级数据库。更详细的变更情况请参阅 Release Notes 。欢迎各位和我们一起开启新的 奇妙旅程 。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

