

黄东旭解析 TiDB 的核心优势
862
2023-04-14
本文为云盛海宏数据库架构师徐婷的分享实录。云海零售系统是支撑着全渠道、全品类运动鞋服的零售服务平台。本文介绍了云盛海宏云海零售系统所使用的数据库架构从集中式到分布式的演进历程,并根据使用的经验和体验,阐述了为什么选择 TiDB 数据库来支撑其业务,详细讲述了 TiDB 如何在实际使用中助力精细化运营。
大家好,我是徐婷,云盛海宏的数据库架构师,也是 TiDB 的深度用户,很高兴和大家分享 TiDB 在云盛海宏“云海零售系统”中的应用。云盛海宏是一家零售行业的科技公司,以科技的力量为门店和线上客户打造 360 度的优秀体验,目前服务全国近万家的线下门店和千万级别的线上会员。
云海零售系统是支撑着全渠道、全品类运动鞋服的零售服务平台。在过去的十年间我们的业务系统和架构经历过多次的升级和改造,整体来看就是一个从集中式演进到分布式的过程。在 2016 年之前,各个大区自建设信息化系统,每天向总部上传业务数据,属于烟囱式的数据架构。随着移动互联网和数字经济的发展,该架构也暴露出一些问题,比如说没有办法很及时地去查看地区的汇总数据,也无法跨大区去查看全国的实时库存等。
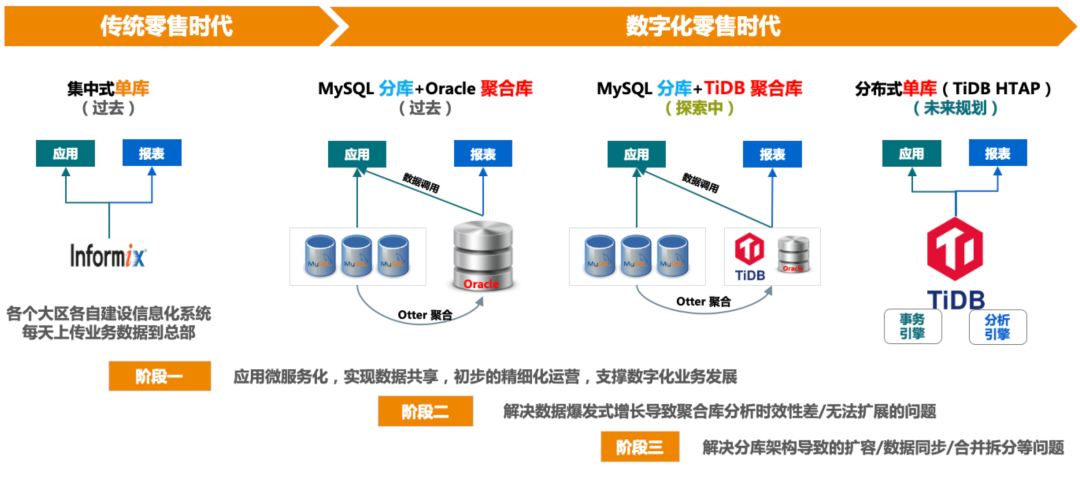
为了解决这些问题,我们在 2016 年的时候就上线了全新的架构——云海零售系统。新架构是采用的微服务 + MySQL 的分库分表架构,并通过 Otter 将数据的实时汇聚到 ***,用于支撑复杂的报表查询。随着数字化零售时代的开启,汇聚库 *** 也遇到了一些瓶颈,例如存储无法扩展、分析时效差等问题,所以我们就引入了 TiDB 和 *** 一起支撑业务需求。对于未来的规划,我们希望能借助 TiDB 混合负载特性,支撑我们整个零售系统。
2016 年为了支撑数字化业务,我们进行了业务流程的变革,并升级了我们的 IT 架构,上线了云海零售系统,这是当时的系统架构图。基于 MyCAT 进行分库分表和读写分离,拆分的规则复杂一点,基于每个业务系统还有大区都做了一定的拆分,这个架构的好处是将当时比较分散的数据汇聚到了一起。但这套架构也增加了实时分析的难度,做到了数据的共享,但因为数据做了拆分,如果要做一些复杂的需求,比如一些报表,比较复杂的 SQL,还有一些其他业务的时候就会增加相应的难度,一方面由于 MyCAT 对复杂 SQL 的支持有限、另外 MySQL 大表复杂查询效率也有限,所以我们通过 Otter 将数据实时汇聚到 *** 中,在 *** 上进行复杂的 SQL 查询。
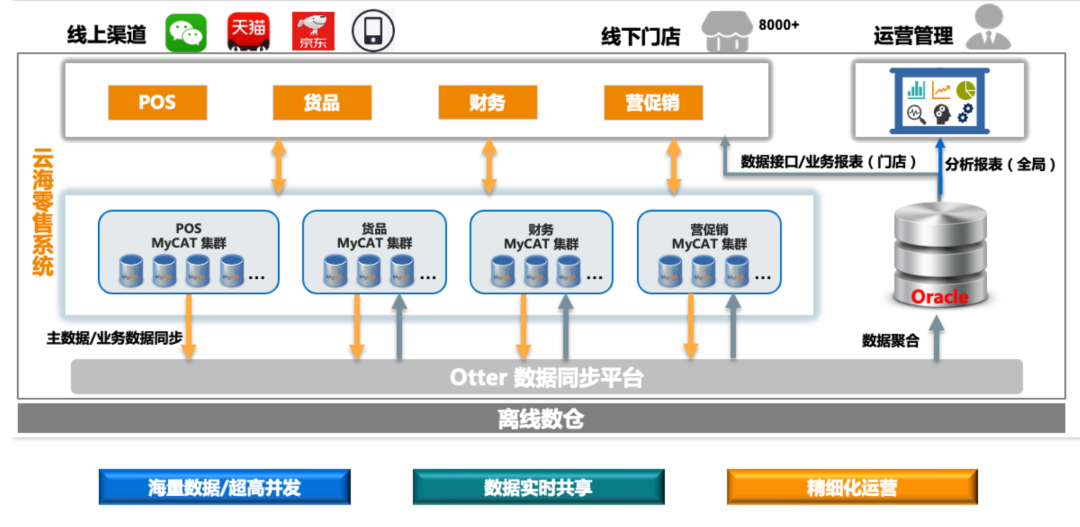
这套架构支撑了我们业务高速发展的五年,实现了很多小目标,比如实现了全国各地区、各大区的海量数据的存储,实现了数据的实时共享,也达到了业务可视化的目标。但是随着业务的扩展和需求难度的增加,慢慢地面临了一些新的挑战。由于 MyCAT 分库分表规则基于静态的策略,在日常的使用中需要大量的人工维护,如新的业务或者组织机构合并,需要新建表或者调整数据时,需要调整策略以及手动导数据。
其次业务对于 Otter 也有很高的依赖度,同步通道 100 多个,维护成本也比较大。源端进行 DDL 操作、大表 DML 操作时,有可能导致同步中断或者同步延迟,人力成本较大。最紧迫的还是在聚合库这边遇到的问题,由于数据量一直增涨,*** 很快就面临了单机数据库的存储容量上限问题,并且随着数据增长部分 SQL 效率越来越差。
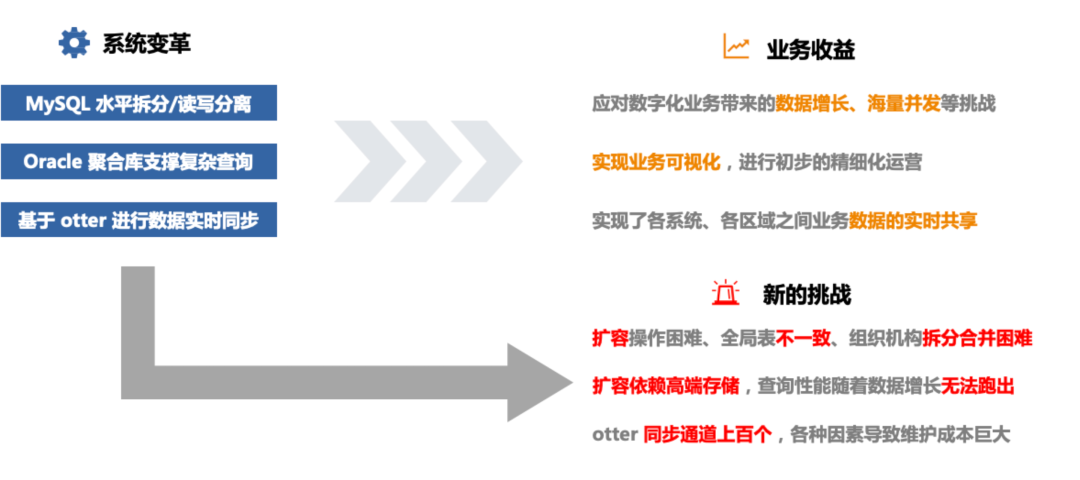
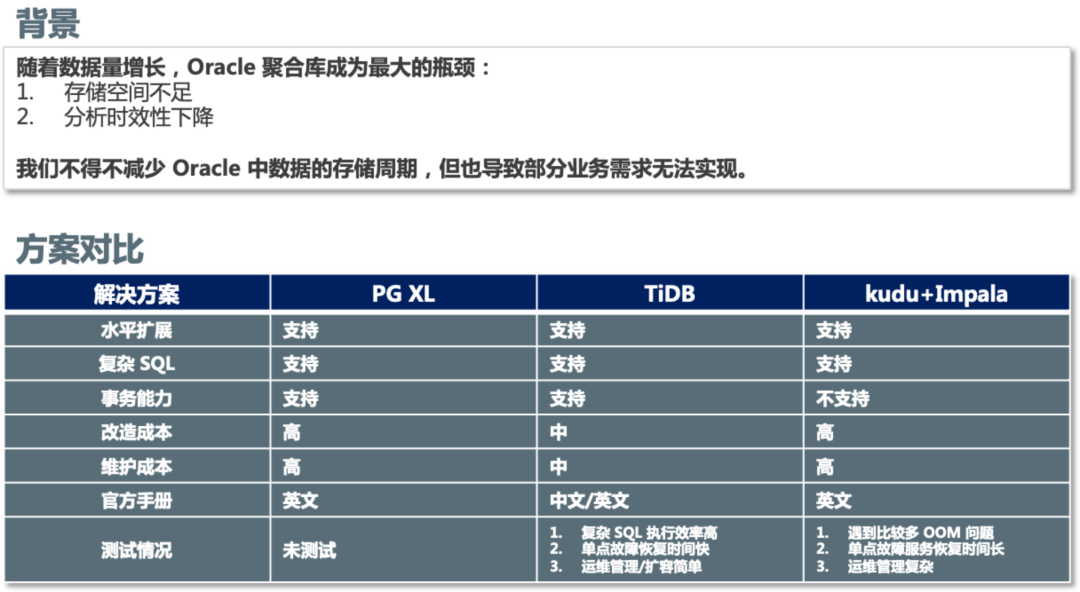
到 2020 年的时候,我们当时已经不得不减少 *** 这边数据存储周期,来保障大部分查询的时效性,但同时也导致了有一部分业务需求无法实现。于是我们开始探索其他解决方案,用于解决 *** 聚合库这边的问题。
我们当时调研了 PG XL、Impala、TiDB 这几个方案,综合来看:TiDB 作为一个分布式关系型数据库天然具备水平扩展能力,协议上与 MySQL 兼容,并且复杂 SQL 执行效率也比较高,在解决我们问题的时候成本是最低的。另外 TiDB 文档比较齐全、社区比较活跃,我们的学习成本也比较低。经过了详细测试和业务评估,我们正式引入了 TiDB。
下图是云海零售系统引入 TiDB 之后的新架构,使用 TiDB 去共同支撑聚合库这边的一些需求,并且将绝大部分功能迁移到 TiDB 上。TiDB 的实际使用效果超出我们的预期:TiDB 分布式架构可以灵活扩展,数据存储周期越来越长;绝大部分 SQL 从 *** 迁移过来时,效率都获得提升,当然也有小部分 SQL 效率退化(通过我们手动调整解决);之前由于数据存储周期和查询时效性导致的一系列难以实现的需求,目前也可以实现了。
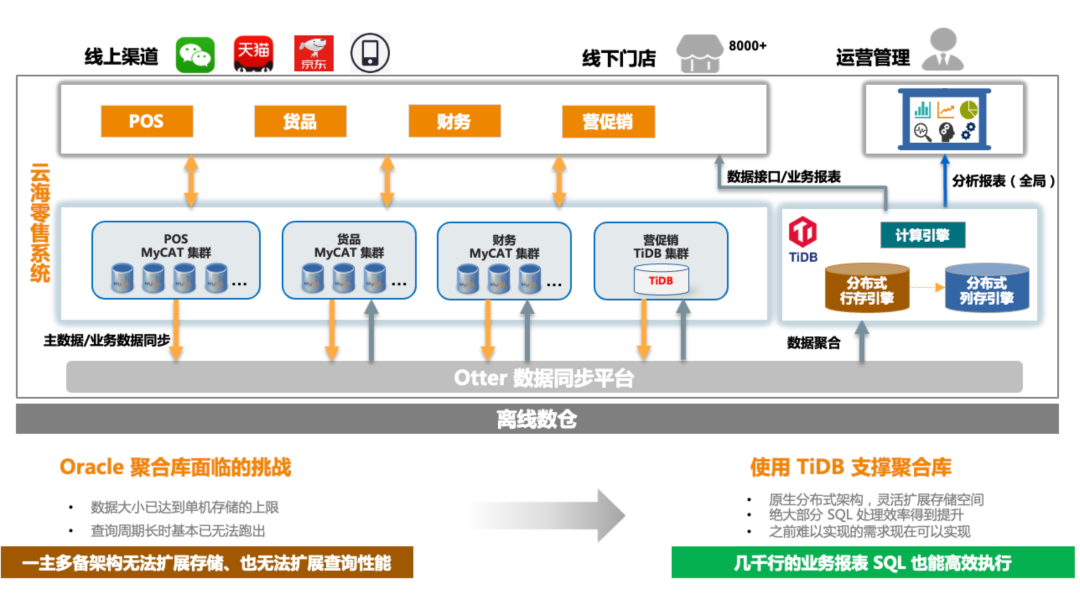
这个是目前 TiDB 的使用规模,基本上承载了整个系统的数据,总数据量将近 15 TB,最大的业务表单表达到了 600GB。在业务的高峰期,比如上午业务比较繁忙的时候,QPS 达到 20000 以上,地区的业务报表每天最大并发差不多在 300 以上。
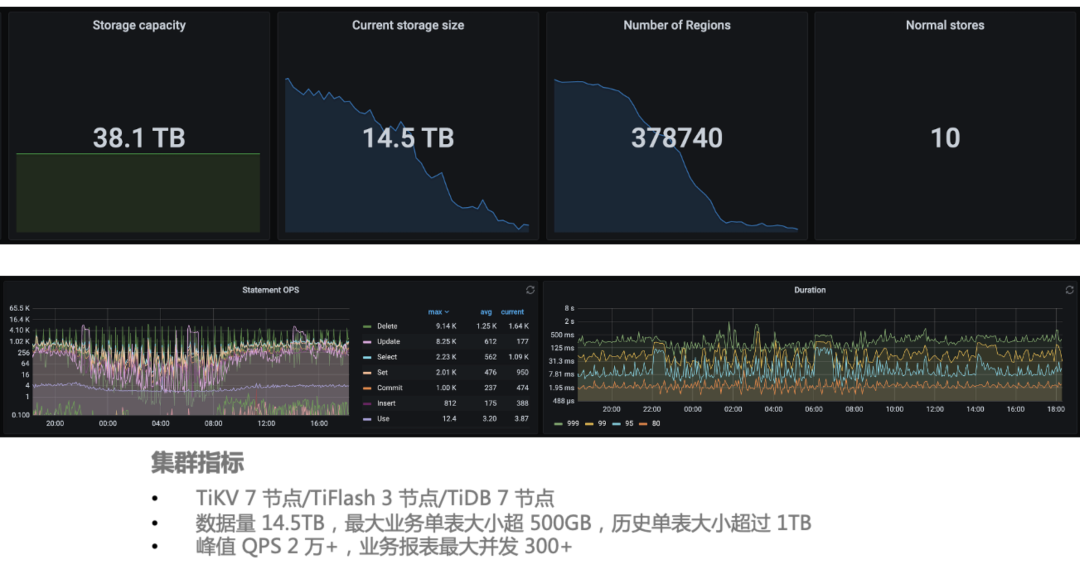
我们目前正计划迁移一个业务子系统,迁移的过程中也整理了一些经验分享,供大家参考。对于一个存量系统的迁移,可以认为它是简单的也可以认为是复杂的。简单的原因是因为 TiDB 兼容 MySQL 协议,业务基本上不需要太多改造就可以在 TiDB 上跑起来;而复杂的原因恰好因为不需要太多改造,导致测试的时候可能会遗漏一些边边角角的功能测试,导致上线的时候出现隐患。
所以目前该系统的迁移,除了有开发、测试同学的人力测试外,还有数据库级别的流量测试。即将源端各个分片的慢查询日志收集起来,根据分片规则作对日志中的库表名进行相应的调整转换,然后利用 perconca-playback 工具去目标端回放,实现流量回放的目的,发现执行异常、执行效率存在差异的 SQL,并进行分析和优化。如果上游是单库的话,只要制定源端慢查询日志和目标端的数据库地址、库名等信息,就可以直接进行流量回放。
在使用 TiDB 的两年里面也遇到一些问题:最多的还是优化器生成的执行计划有时不准,像索引选择不准、Join 顺序选择不准、存储引擎选择不准等问题,目前我们基本都是通过在 SQL 中指定 hint 或者在计算节点上设置默认引擎来解决。统计信息也存在一些收集不及时的情况,导致优化器影响较大,目前我们也自己部署了定时收集统计信息的脚本,保障统计信息的健康度。其他的基本上就是一些排序规则和工具上使用上的小问题,影响不大。

从 2020 年的 4.0 版本开始使用 TiDB,到目前线上的 5.4.2 版本,每一次升级 TiDB 给我们带来了很多比较实用的特性和功能,像 MPP、中文字符排序、CTE、canal-json 等等,并且持续提升稳定性和性能,是一个非常有活力的产品。当前 TiDB 仍存在一些需要改善的地方:在执行计划正确的时候,TiDB 效率都比较高。但当前仍旧存在索引设计合理、统计信息准确时,执行计划还是不对的情况。而且遇到时,往往都是事后才发现并去手动处理,对业务已经产生一定影响。
此外,业务上有大量数据批处理操作,当前像 Insert Into ... Select(复杂查询)这样的 SQL 当前无法走 TiFlash,只能走 TiKV,而走 TiKV 一方面效率不佳,另外一方面走 TiKV 时消耗资源可能影响其他正常业务接口。业务上使用到的主数据,基本上都是读多写很少,一天才写 100 多条,写入基本都是从上游下发下来的,对实时性要求不那么高,反而对查询响应及吞吐性能要求很高,而当前 TiDB 缓存表无法缓存整张表数据,导致这个功能在我们这无法发挥出价值。

我也想和大家分享一些未来的规划,我们目前正计划升级 TiDB 6.1 LTS 版本,去解锁更多新特性:使用 Placement Rule in SQL,来实现冷热数据的分离以及资源的隔离;新版本 TiFlash 支持更高的并发能力以及更高的处理效率;TiKV 全新日志引擎及内存锁可以提升写入效率并降低资源消耗等等。
我们计划将 TiDB 应用到更有挑战的场景中,比如使用 TiDB 去升级分库分表的架构,支撑整个零售系统,使用 TiDB 去支撑有更多复杂需求的 *** 系统。
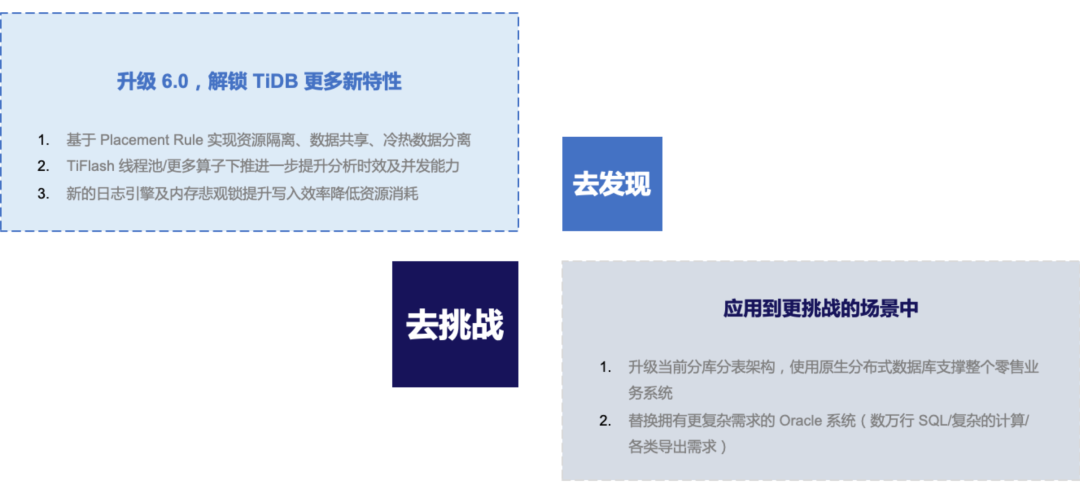
未来,我们计划将整个零售系统演进到单库的形态,基于 TiDB 混合负载能力,支撑整个零售系统,通过两套集群 + 两套存储引擎的方式,实现业务和资源的隔离,以下是我们未来初步规划的架构。
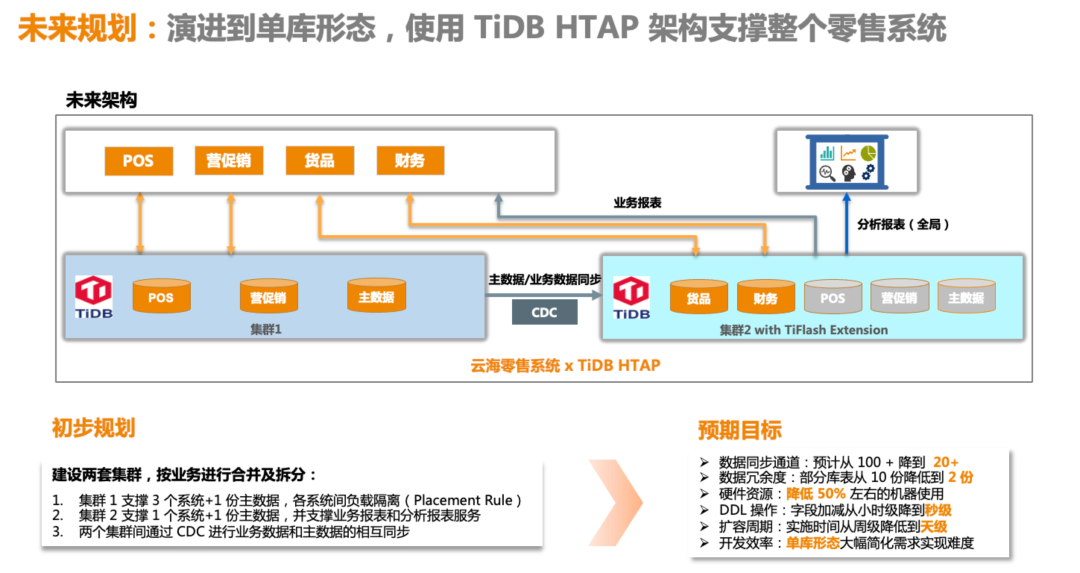
预估的收益体现在几个方面:
首先,新架构将大幅降低数据同步通道,预计可从 100 多个降低到 20 个左右; 其次,之前 MyCAT 上存在大量的数据冗余,部分库表冗余度从 10 份降低到 2 份; 由于数据冗余降低,再加上 TiDB 自带的压缩能力,我们预计硬件资源可降低约 50% 左右; 此外,在开发和运维层面,也能大幅提升我们的效率,加速业务需求的快速落地。整体来说,TiDB 是一款非常不错的产品,对我们来说是相见恨晚的,最后感谢 PingCAP 给我们带来一款这么好用的数据库产品。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

