

黄东旭解析 TiDB 的核心优势
777
2023-04-14
本文是 TiCDC 源码解读系列的第七篇,聚焦 TiCDC 的 Sorter 模块,主要回答以下几个问题:
为什么在 TiCDC 中 Puller 和 Sink 中间,需要有 Sorter? Sorter 的默认排序引擎是什么,以及为什么做出此选择? 针对 LSM 树的读、写放大,Sorter 中做了哪些优化?Sorter 的上游是 Puller。回顾前面几期的内容,用户创建的一个 Changefeed 中可能捕获了多个表,这些表会被调度到若干个 TiCDC 实例上,每个 TiCDC 实例承载该 Changefeed 中的几个表。在每个表上都会有一个 Puller 实例,后者创建 KV-Client 从 TiKV 获取每个 Region 的行变更,经过一系列处理后交给下游的 Sink。
显然,Sink 的吞吐上限可能是低于 KV-Client 的输出的,特别是在需要同步大存量数据到下游的情况下。因此,Sorter 的第一重意义就是作为磁盘缓冲,暂存来不及写到下游的事件。
Sorter 的第二重意义是排序。由于 KV-Client 以 Region 为单位从上游获取行变更事件,多个 Region 之间的事件显然是乱序的。即使在一个 Region 内部,事件也不一定完全是有序的,这是因为 KV-Client 在订阅一个 Region 时,实际上建立了两条数据流:一条通过 Observer 监听这个订阅建立之后的所有变更,另一条则扫描 TiKV 的上该 Region 的行记录,被称为“增量扫”。增量扫的必要性在于,KV-Client 发送给 TiKV 的 ChangeDataRequest 请求中携带了 CheckpointTs 作为订阅的起点,但是 TiKV 上 CheckpointTs 之后的一些变更可能已经通过 Observer 了,便无法从 Observer 中取得了,只能去行记录中扫描。增量扫的数据流和 Observer 的数据流相互独立,因此同一行的多次变更,最终发送到 TiCDC 上其顺序也可能是乱的。因此,Sorter 需要担负起这个排序的任务。
在 Sorter 的上游,行变更是以行为单位进行收集的;在 Sorter 的下游,即 Sink 模块中,行变更是以事务为单位输出的。Sorter 的第三重意义就是将行变更组装成事务。在上游 TiDB 系统中,事务的实现基于 Percolator 算法;在这个算法中,事务有 CommitTs 和 StartTs,前者决定了事务的可见性,后者唯一标识一个事务。Sorter 将行变更组装回事务,在实现上是基于排序的,即将一个表内部的所有行变更,按照 CommitTs 和 StartTs 作为前缀排序,这样属于同一个事务的所有行变更就被聚合在一起了,这样就还原了上游事务的本来面貌。
至此,关于 Sorter 的必要性,可以简单地总结如下:
KV-Client 以 Region 为单位从 TiKV 获取行变更,并将他们按表分别存储在特定的位置; 存储时,同一个表内的行变更以 CommitTs 和 StartTs 为前缀排序; 排序通常应在内存中实现,必要时,需要将事件缓冲到磁盘上;基于前述对 Sorter 的需求描述,假设我们需要自研该组件,它大概应该是这样子的:
从 KV-Client 接收行变更事件,按表划分,先在内存中排序、攒批,然后在需要的时候刷到磁盘上; 排序时,以 CommitTs、StartTs 作为联合前缀,以便将相同事务的变更放到临近位置,不过需要考虑如下问题:
a. 同一个事务的多条行变更,可能被分隔到多个不同文件中了;
b. 多个文件的 CommitTs、StartTs 可能并不是单调递增的,在头部、尾部可能存在交叠; 为解决上面描述的问题,Sorter 提供给 Sink 的数据访问迭代器,在必要时应当归并排序这些磁盘文件; 如果要在单个 TiCDC 实例上支撑几十万个表,直接在物理上隔离它们可能会造成内存、磁盘管理的压力,似乎可以考虑在表之间共享内存缓冲和磁盘文件,那么
a. 迭代器需要具备查找(Seek)某个文件内部某个表的起始位置的能力;
b. 当磁盘上具备成千上万个文件时,如果对每个表发起的每次读取都需要到每个文件内部进行 Seek,会有巨大的开销,造成巨大的性能回退。因此,在磁盘文件过多时,需要考虑一次性读取出来,归并排序后重新写入磁盘,这样,不同表的内容在物理上就被分开了, 读取特定表的数据时就不需要 Seek 大量的文件了。我们很容易发现,Log-structured merge-tree(即 LSM 树)几乎与上述能力要求完美契合,它是 RocksDB 和 Pebble 等 KV 存储引擎的核心数据结构。我们以 RocksDB 的术语简单描述它的核心内容:
内存缓冲区称为 MemTable,前台的写入首先在 MemTable 中排序,在达到缓冲区大小上限时刷出到磁盘上,称为 SSTable(Sorted String Table)。所有 MemTable 和 SSTable 被划分到多个 Level 中,其中所有 MemTable 和直接从 MemTable 刷出到磁盘上的 SSTable 所在的层称为 Level-0,它们的特点是所有文件之间可能存在交叉,当迭代器需要顺序访问时,就需要在每个 Level-0 之间归并排序。
如前所述,当 Level-0 的文件个数较多时,迭代器在每个文件内部去 Seek 会造成可观的开销,因此 RocksDB 会周期性地将 Level-0 的文件归并排序并重新输出。生成的新文件之间便没有任何交叉了,迭代器可以很自然地顺序访问它们。这些新文件便也不再位于 Level-0;除了 Level-0 之外的所有其他 Level,其内部的文件都是有序且不交叉的。下图展示了这一过程。
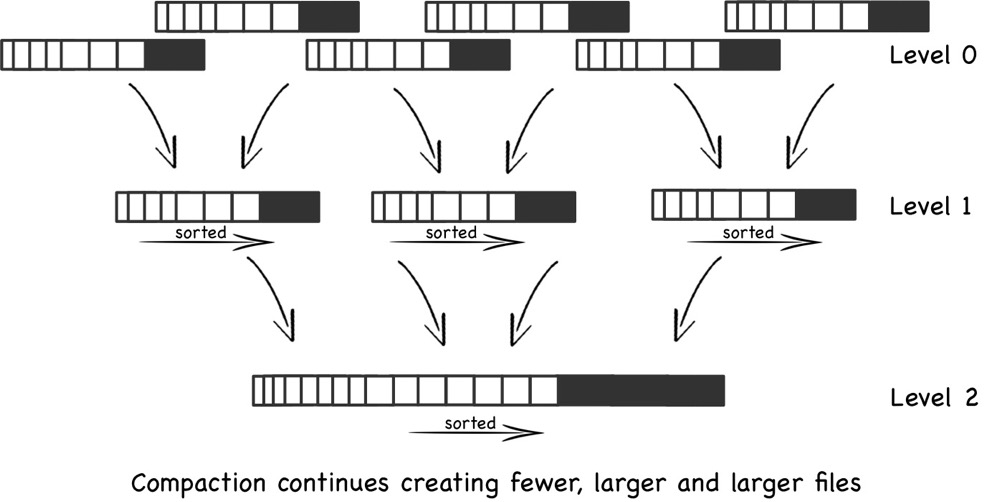
LSM 树有开源的 golang 实现 Pebble,因此我们最终选择了 Pebble 作为默认的排序引擎。
Sorter 的实现细节中,SortEngine 位于核心的位置,它提供了 Add 方法用于接受 Puller 收到的事件,提供 FetchByTable 方法用于 Sink 拉取事件。OnResolve 方法是 Puller 和 Sink 之间的桥梁,当事件在 Sorter 内部就绪之后,会借此来告知 Sink 当前可获得的事件的上界。
// You can search "type SortEngine" in the code tree to find it. type SortEngine interface { // AddTable adds the table into the engine. AddTable(tableID model.TableID) // RemoveTable removes the table from the engine. RemoveTable(tableID model.TableID) // Add adds the given events into the sort engine. // // NOTE: its an asynchronous interface. To get the notification of when // events are available for fetching, OnResolve is what you want. Add(tableID model.TableID, events ...*model.PolymorphicEvent) // OnResolve pushes action into SortEngines hook list, which // will be called after any events are resolved. OnResolve(action func(model.TableID, model.Ts)) // FetchByTable creates an iterator to fetch events from the given table. // lowerBound is inclusive and only resolved events can be retrieved. // // NOTE: FetchByTable is always available even if IsTableBased returns false. FetchByTable(tableID model.TableID, lowerBound, upperBound Position) EventIterator }接下来,将分别从 SortEngine 的写入端和读取端来进一步考察。

上图展示了 TiDB 如何编码一个行记录,以及 TiCDC 中是如何把一行上的变更编码写入 Sorter 的。在 TiDB 中,表 ID 和行记录 ID 会编码为 Key 的前缀,所有的列会编码到一个大的 Value,于是关系数据库表的数据便可以此形式存储到 Key-Value 存储引擎中。TiCDC 会以等价的形式从 TiKV 中接收行变更事件,之后按照前述 Sorter 的需求对包含了 TableID 和 RecordID 的 Key 再次编码,使得事件以 CommitTs、StartTs 为前缀来聚集组织。
编码之后,便可以调用 API 将事件写入 Pebble 实例中;其中包含了一些非常简单、直观的攒批优化,这里就不作赘述了。
Sorter 的读取端入口是 SinkManager,代码中截取了与本期内容密切相关的字段:
// You can search "type SortEngine" in the code tree to find it. // SinkManager is the implementation of SinkManager. type SinkManager struct { // sinkProgressHeap is the heap of the table progress for sink. sinkProgressHeap *tableProgresses // tableSinks is a map from tableID to tableSink. tableSinks sync.Map // lastBarrierTs is the last barrier ts. lastBarrierTs atomic.Uint64 sinkWorkers []*sinkWorker sinkTaskChan chan *sinkTask sinkMemQuota *memquota.MemQuota }SinkManager 维护了 Changefeed 中每个表的进度信息,以及该 Changefeed 的一些信息。上述字段的大致意义:
sinkProgressHeap 是一个最小堆,记录了所有表当前同步到下游的进度。因此在派发任务时,SinkManager 总是可以选择进度最落后的那些表优先进行处理; tableSinks 是一个以表 ID 为 Key 的映射,其 Value 中记录了每个表当前可以向下游同步的上界;记为每个表的 ResolvedTs。这个上界即是 SortEngine 中 OnResolve 钩子来设置的; lastBarrierTs 是该 Changefeed 中所有表能够向下游同步的上界。在对每个表生成 Sink 任务时,实际的上界即为 lastBarrierTs 和表的 ResolvedTs 取最小值得到; sinkWorkers 是 Sink 任务的执行者,sinkTaskChan 用于向它们发送 Sink 任务。任务执行完毕之后,会重新进进入 sinkProgressHeap 等待下一次调度; sinkMemQuota 是一个内存配额管理器,用于控制该 Changefeed 下所有 Sink 任务执行过程中占用的总内存。生成 Sink 任务的代码在 SinkManager 的 generateSinkTasks 方法中,细节的部分这里就不作展开了,请读者自行观察领会。
任务的执行Sink 任务在 cdc/processor/sinkmanager/table_sink_worker.go 中的 sinkWorker.handleTask 函数中执行,这个函数比较长,处理的逻辑也比较繁琐,我们仅重点留意这两个细节:
配合 MemQuota,在内存不足时主动放弃任务并记录进度; 针对大事务拆分功能是否开启的不同情况,将攒批的事件组装后发送到下游;至于下游 Sink 的具体实现,比如对 MySQL 或者消息队列的不同处理,则由后续的源码阅读章节来深入阐述了。
if usedMem >= availableMem { if txnFinished { // It means this transaction is complete. if w.sinkMemQuota.TryAcquire(requestMemSize) { availableMem += requestMemSize } } else { if !w.splitTxn { w.sinkMemQuota.ForceAcquire(requestMemSize) availableMem += requestMemSize } else { // NOTE: if splitTxn is true its not required to force acquire memory. if err := w.sinkMemQuota.BlockAcquire(requestMemSize); err != nil { return errors.Trace(err) } availableMem += requestMemSize } } }这段代码展示了在获取并处理完一个事件事件之后,如果遇到了申请的内存配额耗尽的情况,应该如何抉择。如果当前事务已经组装完整了,则可以调用 MemQuota.TryAcquire 来尝试分配更多内存来继续任务。如果分配失败,则会在这个地方中断当前任务,并将这个表的最新进度写回 sinkProgressHeap 中。如果当前事务没有组装完成,则视是否开启了大事务拆分功能又有不同分支。如果未开启大事务拆分功能,则必须调用 MemQuota.ForceAcquire 来申请内存,因为事务组装完毕前无法发送到下游,从而已经申请过的内存配额便不能释放,如果调用 MemQuota.BlockAcquire,则会有潜在的死锁问题。
doEmitAndAdvance := func() (err error) { if len(events) > 0 { task.tableSink.appendRowChangedEvents(events...) events = events[:0] } if currTxnCommitTs == lastPos.CommitTs { // It means the current transaction is completed. if lastPos.IsCommitFence() { // All transactions before currTxnCommitTs are resolved. err = w.advanceTableSink(task, currTxnCommitTs, committedTxnSize+pendingTxnSize) } else { // This means all events of the currenet transaction have been fetched, but we cant // ensure whether there are more transaction with the same CommitTs or not. err = w.advanceTableSinkWithBatchID(task, currTxnCommitTs, committedTxnSize+pendingTxnSize, batchID) } committedTxnSize = 0 pendingTxnSize = 0 } else if w.splitTxn && currTxnCommitTs > 0 { // This branch will advance some complete transactions before currTxnCommitTs, // and one partail transaction with `batchID`. err = w.advanceTableSinkWithBatchID(task, currTxnCommitTs, committedTxnSize+pendingTxnSize, batchID) } else if !w.splitTxn && lastTxnCommitTs > 0 { err = w.advanceTableSink(task, lastTxnCommitTs, committedTxnSize) committedTxnSize = 0 } return }这段代码展示了攒批并将事务发送到下游的核心逻辑。首先调用 appendRowChangedEvents 方法将事件转移给下游 Sink,注意此时只是在下游暂存,尚无法发送。后续会通过 advanceTableSink 或 advanceTableSinkWithBatchID 函数告知下游你可以将暂存的事件中截止到某一位置的内容发出去了,此时事件才真正能流向下游外部存储,之后即可更新这个表的 Checkpoint。
advanceTableSink 和 advanceTableSinkWithBatchID 的区别是后者会携带一个 BatchID,意味着给定的 CommitTs 上,还可能存在更多的事务未发送到下游,因此不能将 Checkpoint 推进到这个 CommitTs 上。这个逻辑的必要性在于,在 TiDB 中多个事务是可能共享相同的 CommitTs 的。
回到代码,在 appendRowChangedEvents 之后首先会判断当前事务是否已经组装完成。如果是,则从该事务的 StartTs 和 CommitTs 的比较(即 IsCommitFence 方法)中可以判断后续是否仍然可能有相同 CommitTs 的事务进来,并分别调用上述两个函数中的一个。如果当前事务未组装完成,且没有开启大事务拆分的功能,则只能调用 advanceTableSink 函数将进度推到上一个组装完成的事务位置。易知,如果当前事务是一个非常大的事务,则只能在内存中一直保留直到组装完毕才能发送到下游了。
Sorter 的默认排序引擎是 Pebble,后者基于 LSM 树,因此先天具有读写放大的缺点。在 TiCDC 中,我们通过一些手段极大缓解了读写放大的情况。下面我们通过代码具体地观察。
type tableCRTsCollector struct { minTs uint64 maxTs uint64 } func (t *tableCRTsCollector) Add(key pebble.InternalKey, value []byte) error { crts := encoding.DecodeCRTs(key.UserKey) if crts > t.maxTs { t.maxTs = crts } if crts < t.minTs { t.minTs = crts } return nil } func (t *tableCRTsCollector) Finish(userProps map[string]string) error { userProps[minTableCRTsLabel] = fmt.Sprintf("%d", t.minTs) userProps[maxTableCRTsLabel] = fmt.Sprintf("%d", t.maxTs) return nil }在创建并打开 Pebble 实例时,tableCRTsCollector 会被放入 pebble.Options 的 TablePropertyCollectors 字段中。后者会在生成磁盘文件时根据该文件中的每个 Key 来产生一些 Property,并最终记录到该文件中。在创建迭代器时,就可以通过这些 Property 过滤掉一些不需要的磁盘文件,从而在存在大量磁盘文件(特别是 Level-0 文件)的情况下,显著地减少读放大。上面代码中,我们在 Property 中记录了该文件包含的所有事件的 CommitTs 范围,并以此来过滤不需要访问的磁盘文件。
cleanTable 函数展示了在一个表的 CheckpointTs 向前推进之后,残留在 Sorter 中的数据如何清理的细节,即最终会调用 Pebble 的 DeleteRange API。后者适用于以较低的代价删除一段区间,实际的数据会在 Pebble 内部进行 Compaction 的时候清理掉。这个调用不宜过于频繁,否则会极大地影响迭代器的性能,目前 TiCDC 中对于每个表会最低间隔 5s 调用一次。利用 DeleteRange 机制,可以极大地减小 TiCDC 在使用 Pebble 时潜在的写放大,在 TiCDC 整体延迟较小的情况下效果尤其优异。
这两段代码都在 cdc/processor/sourcemanager/engine/pebble 这个包下面,感兴趣的读者可以进一步深究。
以上就是 TiCDC 中 Sorter 模块的源码解析,限于篇幅未能覆盖全部细节,希望能为读者提供按图索骥的导览。关于 Sorter 模块目前仍有许多潜在的优化,欢迎社区的朋友参与研发与迭代,一同成长进步!
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

