

黄东旭解析 TiDB 的核心优势
857
2023-06-25
本文关于(什么是TiDB Lightning?及其整体架构)。
TiDB Lightning 是用于从静态文件导入 TB 级数据到 TiDB 集群的工具,常用于 TiDB 集群的初始化数据导入。
TiDB Lightning 支持以下文件类型:
Dumpling 生成的文件
CSV 文件
Amazon Aurora 生成的 Apache Parquet 文件
TiDB Lightning 支持从以下位置读取:
本地
Amazon S3
Google GCS
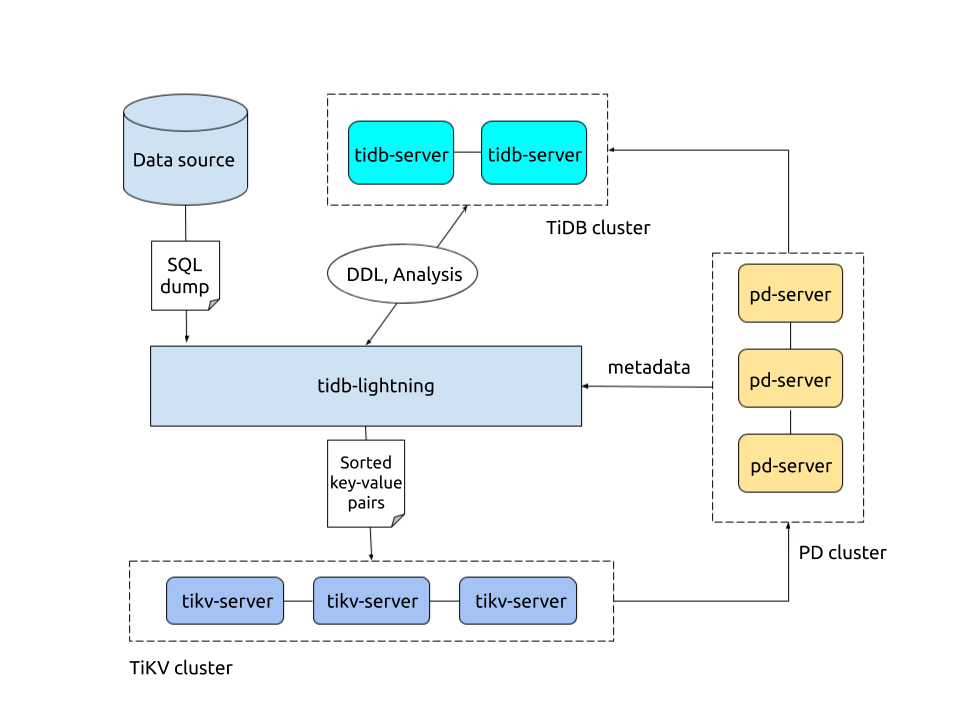
TiDB Lightning 目前支持两种导入方式,通过 backend 配置区分。不同的模式决定 TiDB Lightning 如何将数据导入到目标 TiDB 集群。
物理导入模式:TiDB Lightning 首先将数据编码成键值对并排序存储在本地临时目录,然后将这些键值对上传到各个 TiKV 节点,最后调用 TiKV Ingest 接口将数据插入到 TiKV 的 RocksDB 中。如果用于初始化导入,请优先考虑使用物理导入模式,其拥有较高的导入速度。物理导入模式对应的后端模式为 local。
逻辑导入模式:TiDB Lightning 先将数据编码成 SQL,然后直接运行这些 SQL 语句进行数据导入。如果需要导入的集群为生产环境线上集群,或需要导入的目标表中已包含有数据,则应使用逻辑导入模式。逻辑导入模式对应的后端模式为 tidb。
| 导入模式 | 物理导入模式 | 逻辑导入模式 |
后端 |
|
|
速度 | 快 (100 ~ 500 GiB/小时) | 慢 (10 ~ 50 GiB/小时) |
资源使用率 | 高 | 低 |
占用网络带宽 | 高 | 低 |
导入时是否满足 ACID | 否 | 是 |
目标表 | 必须为空 | 可以不为空 |
支持 TiDB 集群版本 | >= v4.0.0 | 全部 |
导入期间是否允许 TiDB 对外提供服务 | 受限制 | 是 |
注意
以上性能数据用于对比两种模式的导入性能差异,实际导入速度受硬件配置、表结构、索引数量等多方面因素影响。
上述就是小编为大家整理的(什么是TiDB Lightning?及其整体架构)
***
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

