

黄东旭解析 TiDB 的核心优势
1618
2023-06-25
本文关于(什么是TiFlash?TiFlash的核心特性有哪些?)。
TiFlash 是 TiDB HTAP 形态的关键组件,它是 TiKV 的列存扩展,在提供了良好的隔离性的同时,也兼顾了强一致性。列存副本通过 Raft Learner 协议异步复制,但是在读取的时候通过 Raft 校对索引配合 MVCC 的方式获得 Snapshot Isolation 的一致性隔离级别。这个架构很好地解决了 HTAP 场景的隔离性以及列存同步的问题。
整体架构
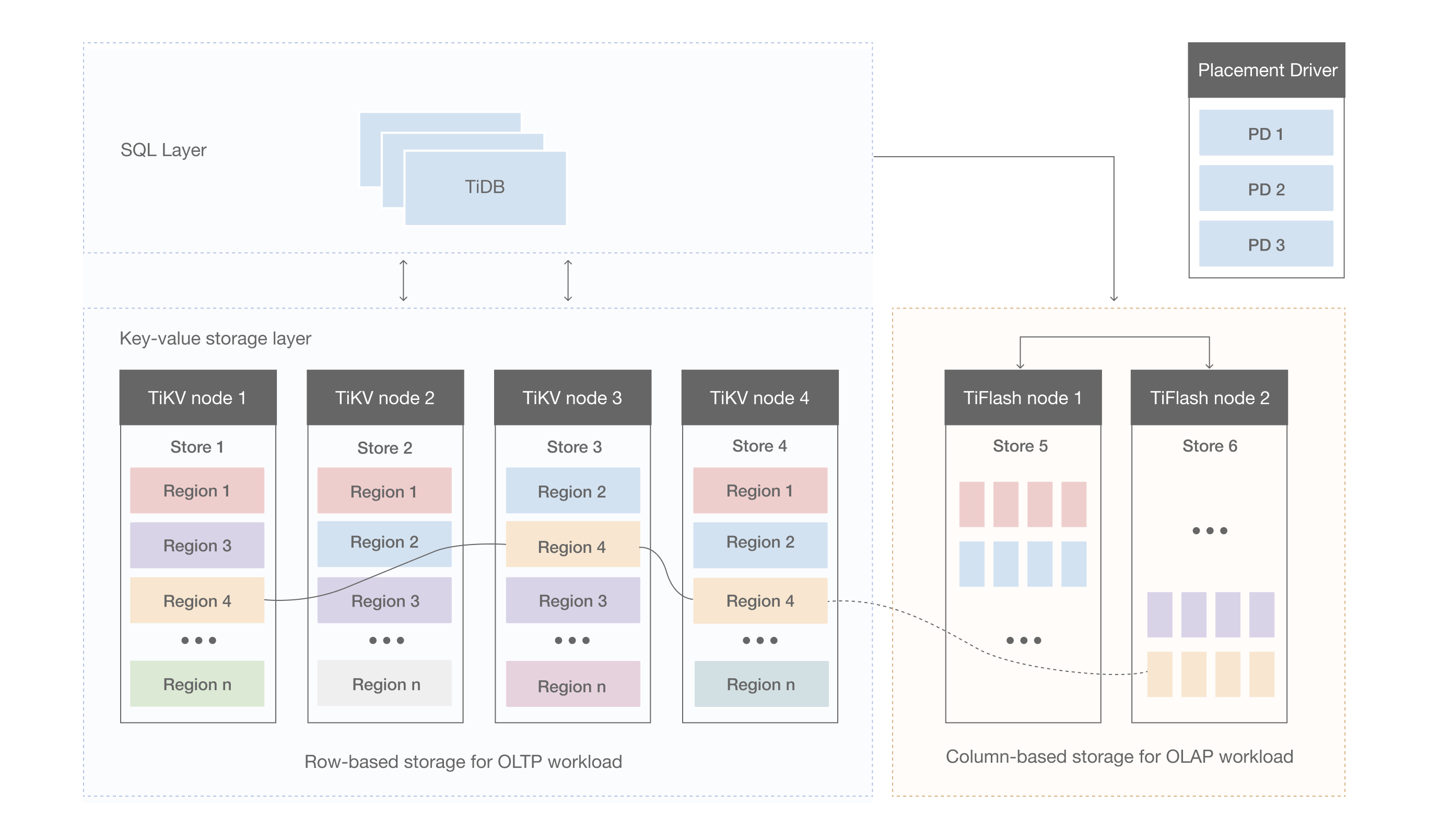
上图为 TiDB HTAP 形态架构,其中包含 TiFlash 节点。
TiFlash 提供列式存储,且拥有借助 *** 高效实现的协处理器层。除此以外,它与 TiKV 非常类似,依赖同样的 Multi-Raft 体系,以 Region 为单位进行数据复制和分散(详情见《说存储》一文)。
TiFlash 以低消耗不阻塞 TiKV 写入的方式,实时复制 TiKV 集群中的数据,并同时提供与 TiKV 一样的一致性读取,且可以保证读取到最新的数据。TiFlash 中的 Region 副本与 TiKV 中完全对应,且会跟随 TiKV 中的 Leader 副本同时进行分裂与合并。
在 Linux AMD64 架构的硬件平台部署 TiFlash 时,CPU 必须支持 AVX2 指令集。确保命令 cat /proc/cpuinfo | grep avx2 有输出。而在 Linux ARM64 架构的硬件平台部署 TiFlash 时,CPU 必须支持 ARMv8 架构。确保命令 cat /proc/cpuinfo | grep 'crc32' | grep 'asimd' 有输出。通过使用向量扩展指令集,TiFlash 的向量化引擎能提供更好的性能。
TiFlash 可以兼容 TiDB 与 TiSpark,用户可以选择使用不同的计算引擎。
TiFlash 推荐使用和 TiKV 不同的节点以做到 Workload 隔离,但在无业务隔离的前提下,也可以选择与 TiKV 同节点部署。
TiFlash 暂时无法直接接受数据写入,任何数据必须先写入 TiKV 再同步到 TiFlash。TiFlash 以 learner 角色接入 TiDB 集群,TiFlash 支持表粒度的数据同步,部署后默认情况下不会同步任何数据,需要按照按表构建 TiFlash 副本一节完成指定表的数据同步。
TiFlash 主要包含三个组件,除了主要的存储引擎组件,另外包含 tiflash proxy 和 pd buddy 组件,其中 tiflash proxy 主要用于处理 Multi-Raft 协议通信的相关工作,pd buddy 负责与 PD 协同工作,将 TiKV 数据按表同步到 TiFlash。
对于按表构建 TiFlash 副本的流程,TiDB 接收到相应的 DDL 命令后 pd buddy 组件会通过 TiDB 的 status 端口获取到需要同步的数据表信息,然后会将需要同步的数据信息发送到 PD,PD 根据该信息进行相关的数据调度。
TiFlash 主要有异步复制、一致性、智能选择、计算加速等几个核心特性。
异步复制
TiFlash 中的副本以特殊角色 (Raft Learner) 进行异步的数据复制。这表示当 TiFlash 节点宕机或者网络高延迟等状况发生时,TiKV 的业务仍然能确保正常进行。
这套复制机制也继承了 TiKV 体系的自动负载均衡和高可用:并不用依赖附加的复制管道,而是直接以多对多方式接收 TiKV 的数据传输;且只要 TiKV 中数据不丢失,就可以随时恢复 TiFlash 的副本。
一致性
TiFlash 提供与 TiKV 一样的快照隔离支持,且保证读取数据最新(确保之前写入的数据能被读取)。这个一致性是通过对数据进行复制进度校验做到的。
每次收到读取请求,TiFlash 中的 Region 副本会向 Leader 副本发起进度校对(一个非常轻的 RPC 请求),只有当进度确保至少所包含读取请求时间戳所覆盖的数据之后才响应读取。
智能选择
TiDB 可以自动选择使用 TiFlash 列存或者 TiKV 行存,甚至在同一查询内混合使用提供最佳查询速度。这个选择机制与 TiDB 选取不同索引提供查询类似:根据统计信息判断读取代价并作出合理选择。
计算加速
TiFlash 对 TiDB 的计算加速分为两部分:列存本身的读取效率提升以及为 TiDB 分担计算。其中分担计算的原理和 TiKV 的协处理器一致:TiDB 会将可以由存储层分担的计算下推。能否下推取决于 TiFlash 是否可以支持相关下推。具体介绍请参阅“TiFlash 支持的计算下推”一节。
TiFlash 部署完成后并不会自动同步数据,而需要手动指定需要同步的表。
你可以使用 TiDB 或者 TiSpark 读取 TiFlash,TiDB 适合用于中等规模的 OLAP 计算,而 TiSpark 适合大规模的 OLAP 计算,你可以根据自己的场景和使用习惯自行选择。具体参见:
构建 TiFlash 副本
使用 TiDB 读取 TiFlash
使用 TiSpark 读取 TiFlash
使用 MPP 模式
如果需要快速体验以 TPC-H 为例子,从导入到查询的完整流程,可以参考 HTAP 快速上手指南。
上述就是小编为大家整理的(什么是TiFlash?TiFlash的核心特性有哪些?)
***
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

