
麒麟v10 上部署 TiDB v5.1.2 生产环境优化实践
5282
2023-06-13
本文讲述了hadoop三大组件,Hadoop、HDFS、Hive、Hbase之间的关系
1、HDFS
HDFS(Hadoop Distributed File System)是 Hadoop 项目的核心子项目,主要负责集群数据的存储与读取,HDFS 是一个主/从(Master/Slave) 体系结构的分布式文件系统。HDFS 支持传统的层次型文件组织结构,用户或者应用程序可以创建目录,然后将文件保存在这些目录中。文件系统名字空间的层次结构和大多数现有的文件系统类似,可以通过文件路径对文件执行创建、读取、更新和删除操作。但是由于分布式存储的性质,它又和传统的文件系统有明显的区别。
HDFS优点:
高容错性。HDFS上传的数据自动保存多个副本,可以通过增加副本的数据来增加它的容错性。如果某一个副本丢失,HDFS 会复制其他机器上的副本,而我们不必关注它的实现。
适合大数据的处理。HDFS 能够处理 GB、TB 甚至 PB 级别的数据,规模达百万,数量非常大。(1PB=1024TB、1TB=1014GB)
流式数据访问。HDFS 以流式数据访问模式来存储超大文件,一次写入,多次读取,即文件一旦写入,则不能修改,只能增加。这样可以保持数据的一致性。
2、MapReduce
MapReduce 是 Hadoop 核心计算框架,适用于大规模数据集(大于1TB)并行运算的编程模型,包括 Map(映射)和 Reduce(规约) 两部分。
当启动一个 MapReduce 任务时,Map 端会读取 HDFS 上的数据,将数据映射成所需要的键值对类型并传到 Reduce 端。Reduce 端接收 Map 端传过来的键值对类型的数据,根据不同键进行分组,对每一组键相同的数据进行处理,得到新的键值对并输出到 HDFS,这就是 MapReduce 的核心思想。
一个完整的 MapReduce 过程包含数据的输入与分片、Map 阶段数据处理、Reduce 阶段数据处理、数据输出等阶段:
读取输入数据。MapReduce 过程中的数据是从 HDFS 分布式文件系统中读取的。文件在上传到 HDFS 时,一般按照 128MB 分成了几个数据块,所以在运行 MapReduce 程序时,每个数据块都会生成一个 Map,但是也可以通过重新设置文件分片大小调整 Map 的个数,在运行 MapReduce 时会根据所设置的分片大小对文件重新分割(Split),一个分片大小的数据块就会对应一个Map。
Map 阶段。程序有一个或多个 Map,由默认存储或分片个数决定。针对 Map 阶段,数据以键值对的形式读入,键的值一般为每行首字符与文件最初始位置的偏移量,即中间所隔字符个数,值为这一行的数据记录。根据需求对键值对进行处理,映射成新的键值对,将新的键值对传到 Reduce 端。
Shuffle/Sort 阶段:此阶段是指从 Map 输出开始,传送 Map 输出到 Reduce 作为输入的过程。该过程会将同一个 Map 中输出的键相同的数据先进行一步整合,减少传输的数据量,并且在整合后将数据按照键排序。
Reduce 阶段:Reduce 任务也可以有多个,按照 Map 阶段设置的数据分区确定,一个分区数据被一个 Reduce 处理。针对每一个 Reduce 任务,Reduce 会接收到不同 Map 任务传来的数据,并且每个 Map 传来的数据都是有序的。一个 Reduce 任务中的每一次处理都是针对所有键相同的数据,对数据进行规约,以新的键值对输出到 HDFS。
3、Yarn
Hadoop 的 MapReduce 架构称为 YARN(Yet Another Resource Negotiator,另一种资源协调者),是效率更高的资源管理核心。
YARN 主要包含三大模块:Resource Manager(RM)、Node Manager(NM)、Application Master(AM):
Resource Manager 负责所有资源的监控、分配和管理;
Application Master 负责每一个具体应用程序的调度和协调;
Node Manager 负责每一个节点的维护。
Hadoop发展现状
Hadoop 设计之初的目标就定位于高可靠性、高可拓展性、高容错性和高效性,正是这些设计上与生俱来的优点,才使得Hadoop 一出现就受到众多大公司的青睐,同时也引起了研究界的普遍关注。Hadoop 技术在互联网领域已经得到了广泛的运用,例如,Yahoo 使用4 000 个节点的Hadoop集群来支持广告系统和Web 搜索的研究;Facebook 使用1 000 个节点的集群运行Hadoop,存储日志数据,支持其上的数据分析和机器学习;百度用Hadoop处理每周200TB 的数据,从而进行搜索日志分析和网页数据挖掘工作;中国移动研究院基于Hadoop 开发了“大云”(Big Cloud)系统,不但用于相关数据分析,还对外提供服务;淘宝的Hadoop 系统用于存储并处理电子商务交易的相关数据。国内的高校和科研院所基于Hadoop 在数据存储、资源管理、作业调度、性能优化、系统高可用性和安全性方面进行研究,相关研究成果多以开源形式贡献给Hadoop 社区。
Hadoop:是一个分布式计算的开源框架
HDFS:是Hadoop的三大核心组件之一
Hive:用户处理存储在HDFS中的数据,hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序。
Hbase:是一款基于HDFS的数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
Hive与***的区别与联系
区别:
Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能。
Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。hive需要用到hdfs存储文件,需要用到MapReduce计算框架。
hive可以认为是map-reduce的一个包装。hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序。
***:***是Hadoop的数据库,一个分布式、可扩展、大数据的存储。
hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作
hbase可以认为是hdfs的一个包装。他的本质是数据存储,是个NoSql数据库;hbase部署于hdfs之上,并且克服了hdfs在随机读写方面的缺点。
联系:
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
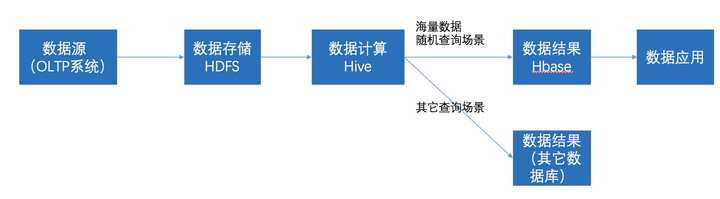
在大数据架构中,Hive和***是协作关系,数据流一般如下图:
通过ETL工具将数据源抽取到HDFS存储;
通过Hive清洗、处理和计算原始数据;
HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
数据应用从***查询数据;
上文就是小编为大家整理的hadoop三大组件,Hadoop、HDFS、Hive、Hbase之间的关系。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

