

黄东旭解析 TiDB 的核心优势
754
2018-10-11
内容来源:http://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247486872&idx=1&sn=1f8d7e88cd92878142a444c2aea8e764&chksm=eb162af2dc61a3e4a6675f86f91e8bd97886b6fd8006662df2f8e58f5190514a192a259beb25#rd
上篇文章中,我们介绍了与 TiKV 处理读写请求相关的基础知识,下面将开始详细的介绍 TiKV 的读写流程。Enjoy~
RawKV
TiKV 提供两套 API,一套叫做 RawKV,另一套叫做 TxnKV。TxnKV 对应的就是上篇文章中提到的 Percolator,而 RawKV 则不会对事务做任何保证,而且比 TxnKV 简单很多,这里我们先讨论 RawKV。
Write
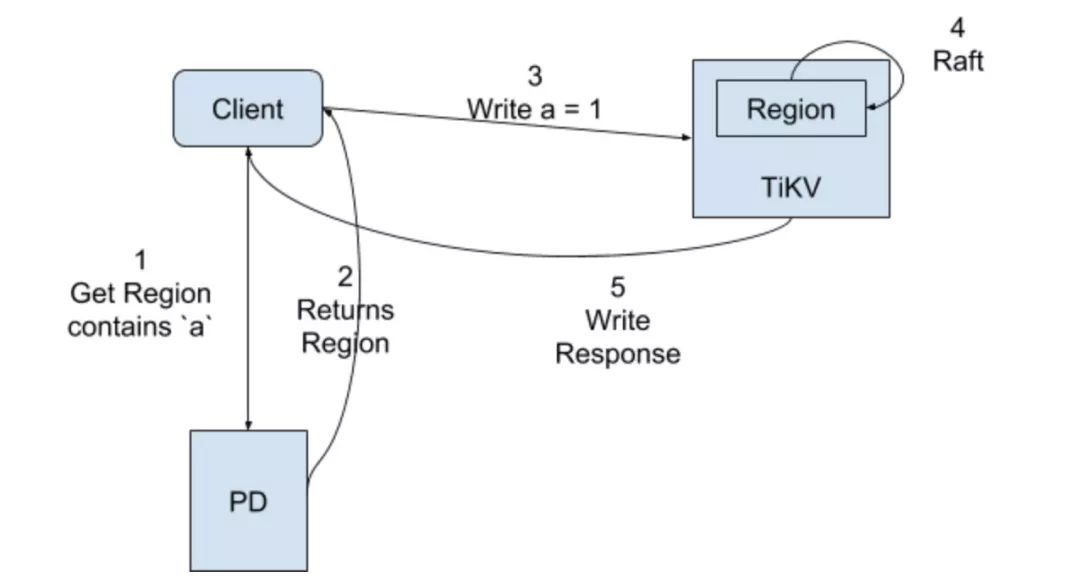
当进行写入,譬如 Write a = 1,会进行如下步骤:
1. Client 找 PD 问 a 所在的 Region
2. PD 告诉 Region 相关信息,主要是 Leader 所在的 TiKV
3. Client 将命令发送给 Leader 所在的 TiKV
4. Leader 接受请求之后执行 Raft 流程
5. Leader 将 a = 1 Apply 到 KV RocksDB 然后给 Client 返回写入成功
Read
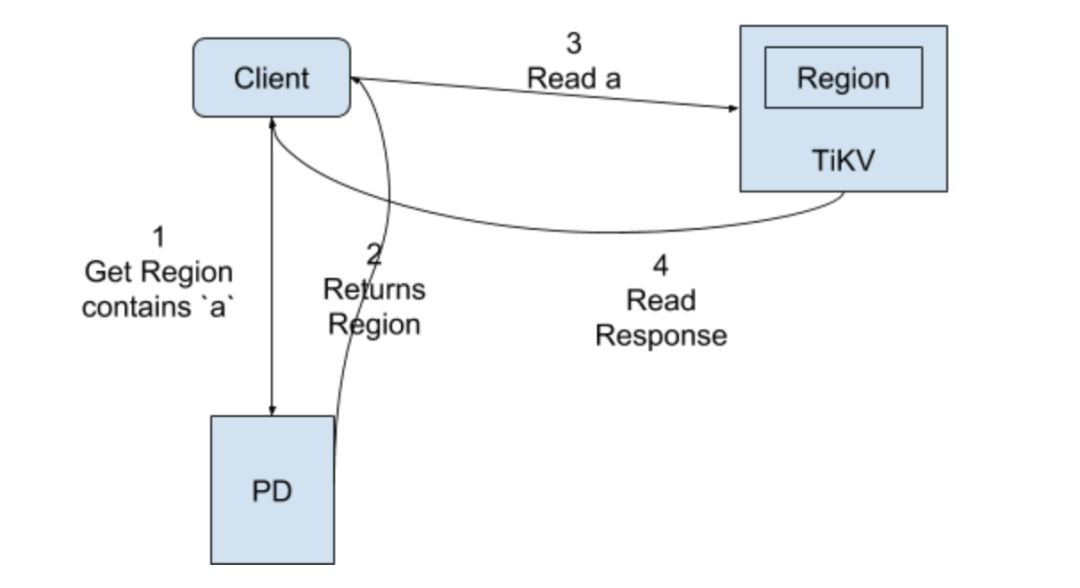
对于 Read 来说,也是一样的操作,唯一不同在于 Leader 可以直接提供 Read,不需要走 Raft。
TxnKV
Write
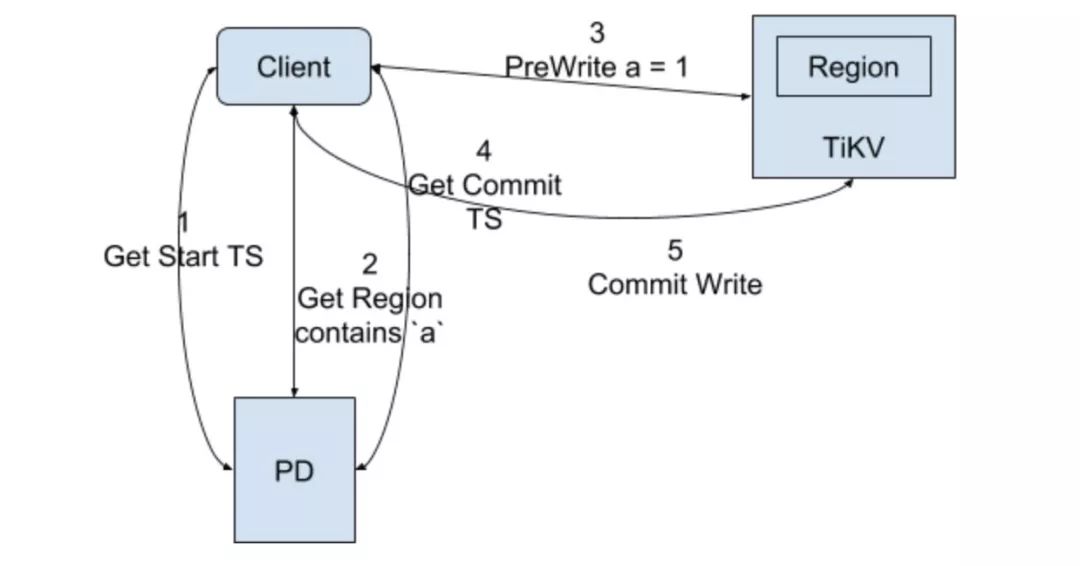
对于 TxnKV 来说,情况就要复杂的多,不过大部分流程已经在 Percolator 章节进行说明了。这里需要注意的是,因为我们要快速的 seek 到最新的 commit,所以在 RocksDB 里面,我们会先将 TS 使用 bigendian 生成 8 字节的 bytes,然后将这个 bytes 逐位取反,在跟原始的 key 组合存储到 RocksDB 里面,这样就能保证最新的提交存放到前面,seek 的时候就能直接定位了,当然 seek 的时候,也同样会将对应的 TS 按照相同的方式编码处理。
譬如,假设一个 key 现在有两次提交,commitTS 分别为 10 和 12,startTS 则是 9 和 11,那么在 RocksDB 里面,key 的存放顺序则是:
Write CF:
a_12 -> 11
a_10 -> 9
Data CF:
a_11 -> data_11
a_9 -> data_9另外,还需要注意的是,对于 value 比较小的情况,TiKV 会直接将 value 存放到 Write CF 里面,这样 Read 的时候只要走 Write CF 就行了。在写入的时候,流程如下:
PreWrite:
Lock CF: W a -> Lock + Data
Commit:
Lock CF: R a -> Lock + 10 + Data
Lock CF: D a
Write CF: W a_11 -> 10 + Data对于 TiKV 来说,在 Commit 阶段无论怎样都会读取 Lock 来判断事务冲突,所以我们可以从 Lock 拿到数据,然后再写入到 Write CF 里面。
Read
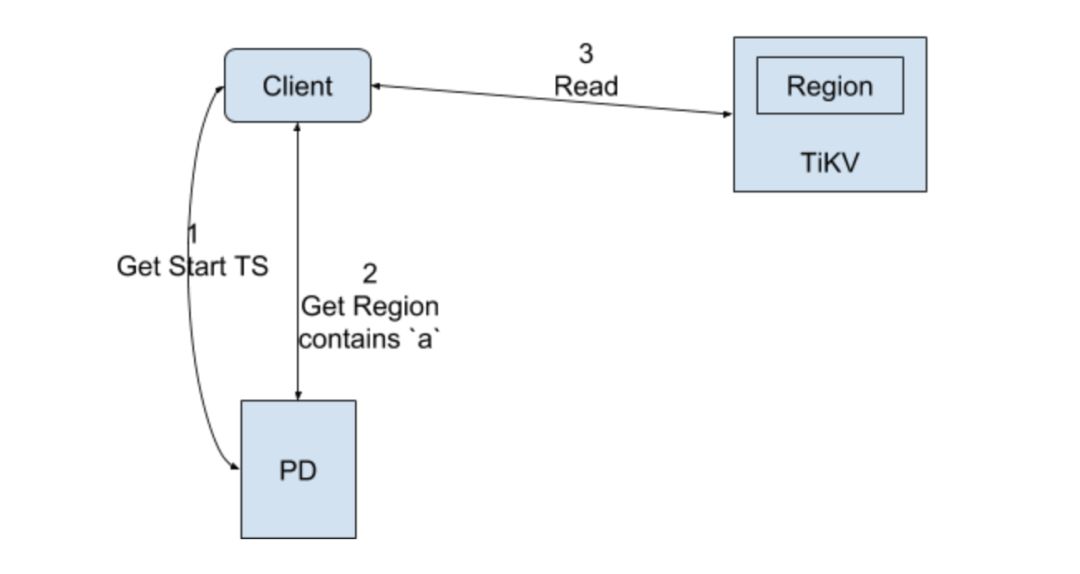
Read 的流程之前的 Percolator 已经有说明了,这里就不详细解释了。
SQL Key Mapping
我们在 TiKV 上面构建了一个分布式数据库 TiDB,它是一个关系型数据库,所以大家需要关注的是一个关系型的 table 是如何映射到 key-value 上面的。假设我们有如下的表结构:
CREATE TABLE t1 {
id BIGINT PRIMARY KEY,
name VARCHAR(1024),
age BIGINT,
content BLOB,
UNIQUE(name),
INDEX(age),
}上面我们创建了一张表 t1,里面有四个字段,id 是主键,name 是唯一索引,age 是一个索引。那么这个表里面的数据是如何对应到 TiKV 的呢?
在 TiDB 里面,任何一张表都有一个唯一的 ID,譬如这里是 11,任何的索引也有唯一的 ID,上面 name 就是 12,age 就是 13。我们使用前缀 t 和 i 来区分表里面的 data 和 index。对于上面表 t1 来说,假设现在它有两行数据,分别是 (1, “a”, 10, “hello”) 和 (2, “b”, 12, “world”),在 TiKV 里面,每一行数据会有不同的 key-value 对应。如下:
PK
t_11_1 -> (1, “a”, 10, “hello”)
t_11_2 -> (2, “b”, 12, “world”)
Unique Name
i_12_a -> 1
i_12_b -> 2
Index Age
i_13_10_1 -> nil
i_13_12_2 -> nil因为 PK 具有唯一性,所以我们可以用 t + Table ID + PK 来唯一表示一行数据,value 就是这行数据。对于 Unique 来说,也是具有唯一性的,所以我们用 i + Index ID + name 来表示,而 value 则是对应的 PK。如果两个 name 相同,就会破坏唯一性约束。当我们使用 Unique 来查询的时候,会先找到对应的 PK,然后再通过 PK 找到对应的数据。
对于普通的 Index 来说,不需要唯一性约束,所以我们使用 i + Index ID + age + PK,而 value 为空。因为 PK 一定是唯一的,所以两行数据即使 age 一样,也不会冲突。当我们使用 Index 来查询的时候,会先 seek 到第一个大于等于 i + Index ID + age 这个 key 的数据,然后看前缀是否匹配,如果匹配,则解码出对应的 PK,再从 PK 拿到实际的数据。
TiDB 在操作 TiKV 的时候需要保证操作 keys 的一致性,所以需要使用 TxnKV 模式。
结语
上面简单的介绍了下 TiKV 读写数据的流程,还有很多东西并没有覆盖到,譬如错误处理,Percolator 的性能优化这些,如果你对这些感兴趣,可以参与到 TiKV 的开发,欢迎联系我 tl@pingcap.com。
延展阅读
三十分钟成为 Contributor | 为 TiKV 添加 built-in 函数
这可能是近期关于 TiKV 最深入的一次分享 | Meetup 回顾

版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

