

黄东旭解析 TiDB 的核心优势
2913
2023-10-23
为什么云原生数据库中需要存算分离?
Massive Parallel Processing(MPP)架构为OLAP类数据库最普遍采用的技术架构。在MPP架构下,计算存储共享一个节点,每个节点有自己独立的CPU、内存、磁盘资源,互相不共享。数据经过一定的分区规则打散到不同的节点上,处理查询时每个节点并行处理各自的数据,互相之间没有资源争抢,具备比较好的并行执行能力。
但是这种将存储资源、计算资源紧密耦合的架构,不太容易满足云时代不同场景下的不同workload需求。例如复杂查询类任务往往对CPU的资源消耗非常大,而数据导入类的任务对CPU资源消耗不大,但是往往需要消耗比较大的IO和网络带宽。因此面对这两种不同的workload,在选择资源规格时,需要结合不同的workload分别做不同的类型选择,也很难用一种资源规格同时满足这两种类型。因为业务不停在发展,workload也不停在变化,比较难提前做好规划。
当我们需要扩容集群扩充CPU资源时,往往会引发数据的reshuffle,这会消耗比较大的网络带宽和CPU资源。即便是基于云平台构建的数据仓库,在查询低峰期时,也无法通过释放部分计算资源降低使用成本,因为这同样会引发数据的reshuffle。耦合的架构严重限制了数据仓库的弹性能力。
而通过分离存储资源、计算资源,可以独立规划存储、计算的资源规格和容量。这样计算资源的扩容、缩容、释放,均可以比较快完成,并且不会带来额外的数据搬迁的代价。存储、计算也可以更好的结合各自的特征,选择更适合自己的资源规格和设计。
云原生数据库的幕后英雄—浅谈分布式数据库的计算和存储分离
分布式数据库替代传统商业数据库是近年最热门和最具争议的话题。理论上没有什么数据库不能被替代,现实却往往是代价大到难以承受。怎样才能更好的降低替代带来的代价呢?“存储和计算分离”作为近年数据库改造流行趋势之首,其作用就是降低数据库替代的代价。本文将通过分析当前主流厂商的数据库计算和存储分离(简称存算分离)对数据库替代中一些棘手问题进行解析,供分布式云原生数据库开发和使用者参考。
计算和存储分离是行业巨头共同的选择
回顾存算分离的发展历程,今天倡导分离的,恰巧就是当年提出计算和存储一体架构的互联网和云计算巨头们。到底存算分离有什么独特的魅力,我们看看业界的巨头大V怎么说?
阿里副总裁,数据库产品事业部总裁李飞飞在《云原生分布式数据库与数据仓库系统点亮数据上云之路》中说:“传统的冯诺依曼架构下计算和存储是紧密耦合的,可将多个服务器通过分布式协议和处理的方式连成一个系统,但是服务器和服务器之间、节点和节点之间,分布式事务的协调、分布式查询的优化,尤其要保证强一致性、强ACID的特性保证的时候,具有非常多的挑战……云原生的架构,本质上底下是分布式共享存储,上面是分布式共享计算池,中间来做计算存储解耦,这样可以非常好地提供弹性高可用的能力,做到分布式技术集中式部署,对应用透明。”
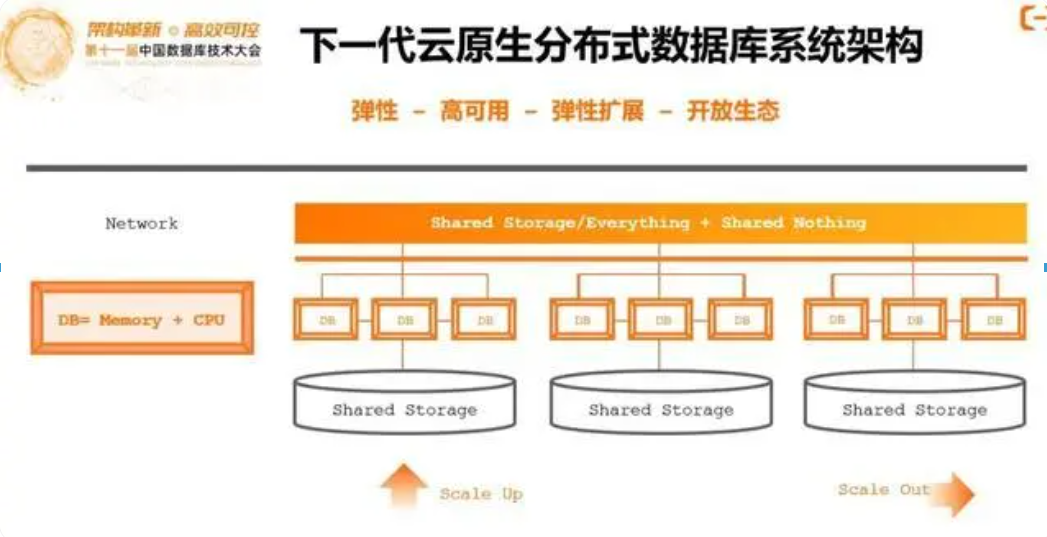
阿里的云原生数据库重新回到提升数据库Scale Up扩展能力的路上,来解决分布式事务,弹性扩展的问题。在必要时可以结合分布式分库分表模式进行Scale Out扩展。
***数据库专家也表示“高可用、易用易维、高扩展、高性能、与大数据相辅相成的云数据库,尤其是基于云场景架构设计的云原生分布式数据库,计算与存储分离、能充分发挥最新硬件性能、利用 AI 和 ML(深度学习) 等功能成发展趋势。”
上面几家是上(数据库)下(存储)内(自有业务)外(公有云)通吃的,而Facebook这种自己玩的互联网厂商完全从自己的业务需要出发,研发了一套温数据存储,以存算分离的架构来支撑亿的用户量产生的大数据。而Snowflake走了一条采用通用对象存储构建公有云数据仓库服务的道路,并实现了数据仓库的计算无状态化。
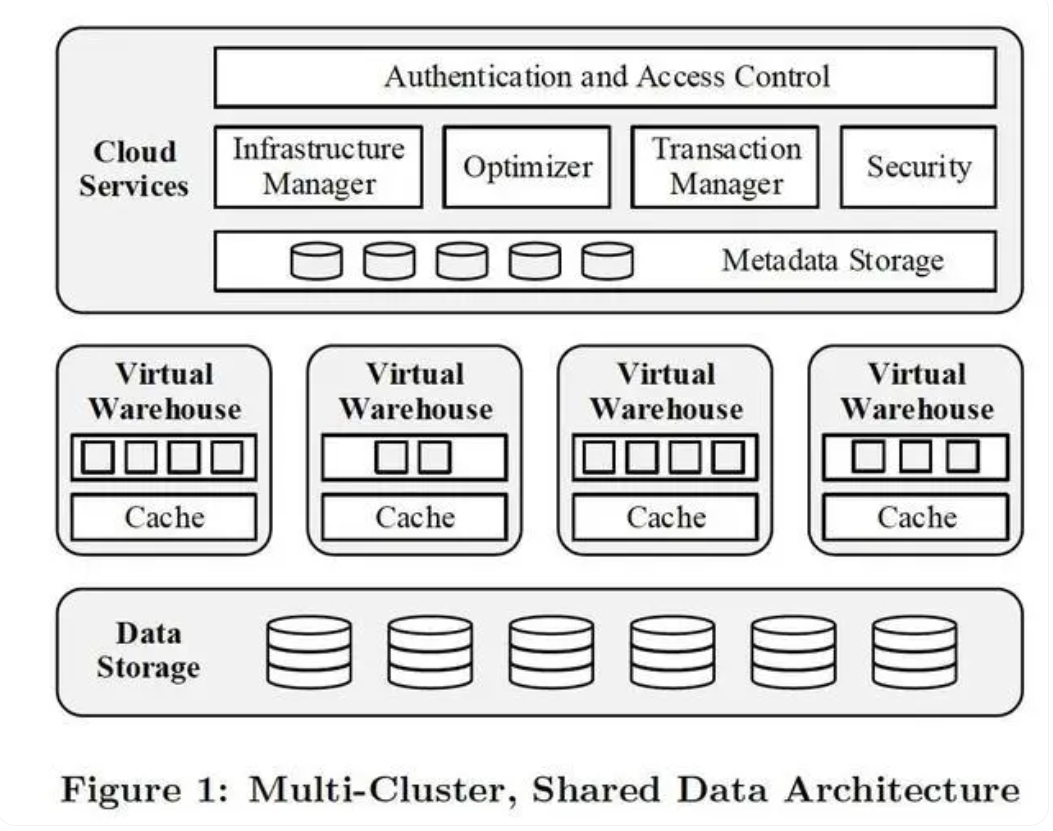
云原生中无处不在的存算分离
云原生一直在努力实现无状态化,而实现的手段就是把数据层剥离出去!只不过在应用层,数据可以剥离给缓存、数据库、文件存储和消息队列,而数据库、消息队列等要云原生时就只能自己做存算分离了。像最近大火的消息队列Apache Pulsar 给自己的定义是这样的:“Apache 软件基金会顶级项目,下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。”
而对于Pulsar的云原生特性则是这么描述的:“Pulsar使用计算与存储分离的云原生架构,数据从Broker搬离,存在共享存储内部。上层是无状态Broker,复制消息分发和服务;下层是持久化的存储层Bookie集群。Pulsar存储是分片的,这种架构可以避免扩容时受限制,实现数据的独立扩展和快速恢复”。
可见实现云原生存算分离已是无处不在,只不过不会直接感知到它罢了。
何为计算、存储、分离
计算:提供计算能力的不可变基础设施
存算分离中计算的变化比较小,也更容易理解,不管是一开始的虚拟机,还是现在最常用的容器,计算部分都是为数据库提供算力,其最基本的资源是CPU和内存。一些“计算”还会用服务器本地盘作为缓存,但并不包括持久化数据。这也使“计算”不断接近云原生中对不可变基础设施的要求。、
存储:能力不断增强的数据持久化资源池相对计算,存储的能力,形态则变化较大。但不管是对象存储,HDFS存储,KV存储,文件存储,还是像AWS那样提供了部分数据库存储引擎功能的“计算存储”,不管是自研的还是购买第三方存储,是云服务还是线下存储,存算分离中的存储始终承担着数据持久化的工作。这一点是理解存算分离的关键,也是存算分离的主要价值之一。
分离:下刀的位置因时而变
分离容易理解,但怎么切是有讲究的,它反映了需求,能力,甚至商业考量。如果想让存储多做点事,可以切得狠一点,像AWS Aurora把日志引擎都切给存储了,如果想通用一些,也可以像阿里***那样正常地切,以至于底层换个存储也能用。如果想封闭圈子自己玩,就切给自己家存储,并且切完了还会连着一点点(封闭接口),公有云基本就是这种做法,如果不想自己研发存储,就切给通用存储,如果想卖存储,就按通用接口来切,***,浪潮的大数据存储,***的HDFS存储都是这个套路,这些都来自商业的考量。
技术发展使存算分离成为可能
存算分离能再次流行是因为之前受限于的技术障碍:传输性能与存储能力问题已得到解决。
技术拐点:分离正当时
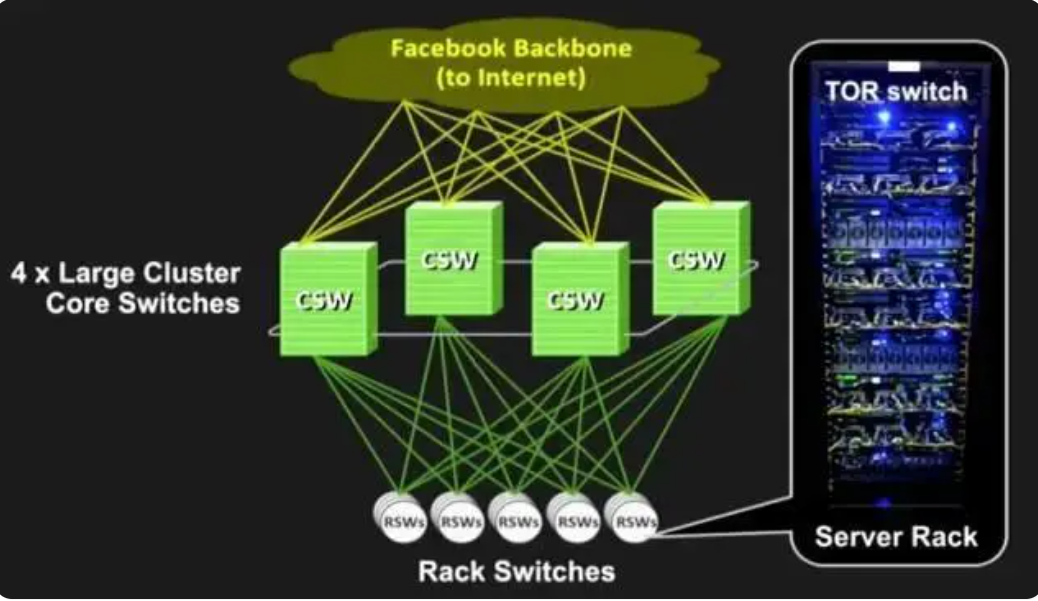
每一次网络技术的进步都会对我们系统架构产生重大影响,大量数据相互间同步,既要低延时又要高带宽,如果没有网络技术的进步无法实现,然而每个短板被填补以后都会带来IT架构的变革,FaceBook在其阐述温存储大数据研发的原因中提出了“技术拐点论”非常准确的说明了当下为什么可以实现存算分离的技术原因:传输协议和带宽能力已不再是IO瓶颈。
高速以太网:吞吐量大幅提升而成本和部署灵活性相比FC和IB有大幅度改善,足以应对从当年的千兆迈入10GE,25GE,甚至100GE时代。
无阻塞转发网络:比如FaceBook采用了CLOS网络拓扑,实现了分解式的网络,网络不会成为性能瓶颈,同时提供了灵活的组网能力。
RoCE(RDMA over Converged Ethernet )和NOF(NVMe over Fabric):带来网络访问高性能、低延迟和低协议负担的优势。阿里***和AWS最新的IO2 Express使用了RoCE。
无损网络:保证网络稳定性,使以太网可以用于高速关键业务。
而相对于传输能力和协议的发展,近年介质能力和协议的提升并不大,这就使当初使用本地盘方案要解决的问题不再存在了。
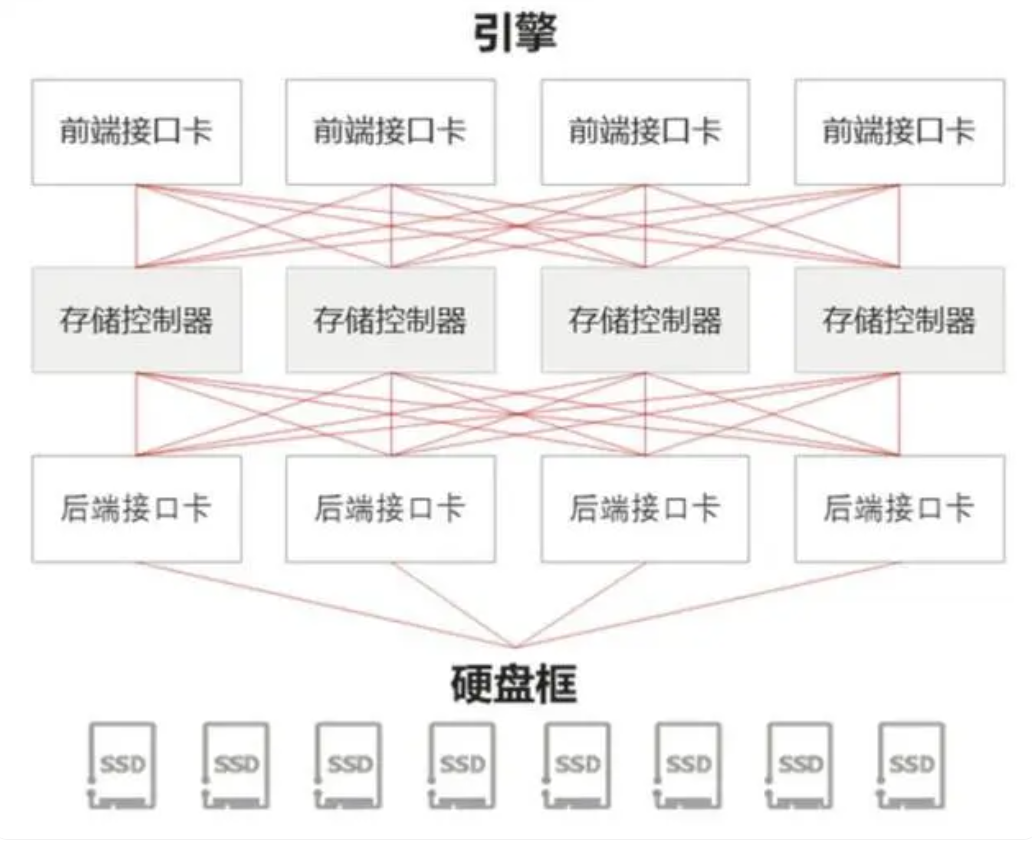
全栈方案厂商存储能力积累 新通用存储+数据库形成开放架构
这个“新”指通用存储具备的新特性,既能提供比本地盘更好的能力,也有别于传统存储。对于存算分离,比较关键的特性包括:
低成本:这主要针对如类似数据湖这种海量数据应用,而对交易类数据库,因为规模相对小并且关注点不同,则不一定是关注重点;
高性能:交易类的业务性能要求高,往往要求亚毫秒级时延和极高的性能密度(IOPS/GB),全闪存存储是比较合适的选择;
扩展性:现在的企业存储也开始采用分布式架构,提供Scale-out和Scale-up兼具的、更好的分层扩展能力,不再有扩展性问题;
量身打造的功能:比如专门用于大数据的HDFS存储,用于增强MySQL等开源数据库能力的可计算存储等。
需求决定是否要做存算分离
技术决定可行性,需求决定必要性。分布式云原生数据库采用存算分离架构的需求来自两方面:利用“云”的优势和提升数据库能力,也就是降低数据库替换中的代价。了解存算分离能解决哪些问题及解决方法,对是否需要以存算分离以及如何规划构建存算分离方案意义重大。
云的必然选择
由于新一代数据库,尤其是分布式数据库,普遍采用云计算部署方式,甚至一些新生代数据库就是为云而设计的。即使不考虑云的因素,分布式数据库改造造成的集群规模暴涨也需要考虑资源分配,弹性扩展,故障切换自动化等需求。对于分布式数据库来说采用存算分离可以归结为资源使用和云原生的需要。
云原生:不可变基础设施带来可靠性提升和弹性扩展能力
上文提到存储的主要功能是实现数据持久化,从而实现不可变基础设施。那么我们来看看存算分离以后,存储带来的价值。
首先是计算发生故障时,由于不需要重新在新服务器上恢复数据,因此实例可以快速恢复。如Aurora采用了共享存储架构的一写多读架构,只需要在计算实例间同步少量缓存信息,因此读实例可以快速恢复成主实例,理论上可以接近ORACLE RAC的切换速度。
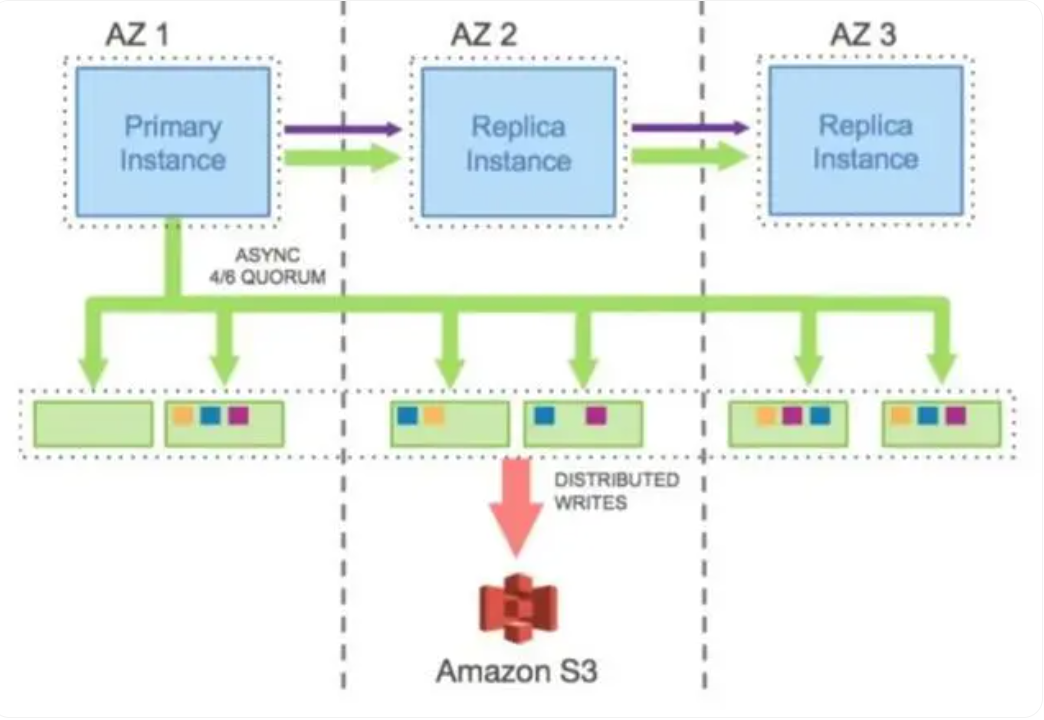
其次即使实例间没有使用同一份共享存储,在存算分离后,也不需要全量恢复数据了,这样数据库恢复到工作状态的时间就大幅度缩短了。京东就采用了这种方式,避免了数据恢复中日志恢复慢和高负载下可能追不上日志的问题。
另外存算分离后计算实例可以摆脱物理服务器的束缚,任意迁移且不需要进行数据同步,这使得弹性扩展变得极为容易。
把规划变简单,提升资源使用效率
对于数据库这类复杂的应用如果使用服务器本地盘,在资源规划时要考虑CPU、内存、存储容量/IOPS/ 带宽,网络IO/带宽,差不多7个维度。这会有多复杂呢?
我们平常接触的世界是三维的相对论把世界变成了4维,但也只解释了引力,另外三个要靠量子力学。而要统一相对论和量子力学,目前最有希望的理论弦理论认为世界是11维的!云计算解决这个问题的思路与物理学一样,一靠近似,就是忽略到一些维度,比如不管需求有多少,把服务器的配置统一成两三种。但这样一来,资源利用率不可能高。二是像拆分出相对论和量子力学两个看似矛盾的理论一样,把计算和存储解耦,这便是李飞飞“云原生的架构,本质上底下是分布式共享存储,上面是分布式共享计算池,中间来做计算存储解耦”的目的。
以较小代价提升数据库整体能力的需要
李飞飞在《云原生分布式数据库与数据仓库系统点亮数据上云之路》提到:“一旦做了分布式架构,数据只能按照一个逻辑进行Sharding和Partition,业务逻辑和分库逻辑不是完美一致,一定会产生跨库事务和跨Sharding处理,每当ACID要求较高的时候,分布式架构会带来较高的系统性能挑战,例如在高隔离级别下当distributed commit占比超过整个事务的5%或者更高以上的话,TPS会有明显的损耗。”
其实这只是架构导致的问题之一。如果对比一下企业数据库,Hadoop,和MySQL的主从同步方案就会发现:前两个都有专门的本地可靠性方案(一般是同机房),而MySQL的主从同步方案是在CAP中优先保证性能,牺牲一致性。加上MySQL的增强半同步很容易在大事务等情况下退化成异步复制,因此即使是同机房内,仍然有很大丢失数据风险。前面分析过,Hadoop因为有独立的HDFS存储层,它的可靠性是构建在HDFS存储层之上,而不是像MySQL构建在主从同步或MGR之上。相对来说,前者的效率要更高,可靠性更好。业界大佬们采用存算分离,就是因为架构变化能带来事半功倍甚至从0到1的改变,从而“让数据库替换的代价变小”。
纵观业界的数据库存算分离方案,除了之前提到的云原生之外,一般会从这几方面入手。
可靠性
存储本身就有非常好的本地和灾备可靠性能力,反倒是服务器的可靠性偏弱。存储可以实现本地盘很多无法实现或难以实现的可靠性功能:
本地可靠性冗余:基于本地盘实现冗余有丢数据风险,有些则很困难,如对 NVMe盘的RAID,或者效率上不如在存储上实现。不过必须指出同样由于像MySQL这样的数据库缺少专业的本地可靠性方案,本地可靠性切换接管需要专门的适配改造才能发挥出更大价值。
数据校验:这个功能在存储上是标配,但在服务器系统层则很少考虑, 如果数据库想做,那得自己开发这部分功能。
高可用:以MySQL为例,大事务或批处理业务都可能导致半同步退化。相对来说存储层实现容灾对数据库压力的敏感性要低。
备份:数据库备份恢复要依靠全量副本+增量日志,恢复时间会相当长。而存储一般都有快照复制能力,AWS和阿里更是把云备份的功能就建立在存储上了,在数据库实现存算分离后,直接将这部分功能用起来就可以了。
性能
解决可靠性问题时,一些性能消耗可以避免或降低,如增强半同步对性能的影响。
存储对性能的优化,如对***介质的优化催生了全闪存存储,采用端到端NVMe over Fabric降低IO路径和时延,专用的缓存算法等提升性能。
新技术的应用,如对SCM,FPGA的应用。
QoS实现对存储 IO的隔离在操作系统层面很困难
总结
云原生分布式数据库的高速发展,必然带来计算、存储的分离,“存算分离”是当前网络技术发展和社会经济进步的时代产物,是最适合当前时代发展需求的一种架构。数据库的存算分离是存储、云计算、数据库的技术的综合,对于数据库使用者和IT规划师,可以关注这一技术方向和其中的技术实现,来解决面临的问题。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

