
业务挑战
知乎首页是解决流量分发的一个关键入口,知乎通过个性化首页推荐的方式在海量的信息中高效分发用户感兴趣的优质内容。为了避免给用户推荐曾经看过的重复内容,「已读服务」会将所有知乎站上用户深入阅读或快速掠过的内容记录下来长期保存,并将这些数据应用于首页推荐信息流和个性化推送的已读过滤。
当用户打开知乎进入推荐页时,系统会先向首页服务发起请求拉取“用户感兴趣的新内容”。首页根据用户画像,去多个召回队列召回新的候选内容,这些召回的新内容中可能有部分是用户曾经看过的,所以在分发给用户前,首页会先将这些内容发给已读服务过滤,然后做进一步加工并最终返回给客户端。
在整个过程中,已读服务业务具有以下主要特点:
- 系统可用性要求非常高。个性化首页和个性化推荐是知乎最重要的流量分发渠道;
- 数据写入量非常大。峰值每秒写入 40K+ 行记录,日新增记录近 30 亿条;
- 历史数据长期保存。知乎按照产品设计数据需要保存三年,产品迭代至今,已经保存了约 13000 亿条历史记录。按照每月近 1000 亿条记录的增长速度计算,预计两年后将膨胀到 30000 亿的数据规模;
- 查询吞吐高。用户在线上每次刷新首页,至少要查一次,并且因为有多个召回源和并发的存在,查询吞吐量可能还会放大。峰值时间首页每秒大约产生 30000 次独立的已读查询,每次查询平均要查 400 个文档,长尾部分大概 1000 个文档。也就是说,整个系统峰值平均每秒处理 1200 万份文档的已读查询;
- 响应时间敏感。在这样一个吞吐量级下,响应时间要求比较严格,要求整个查询响应时间(端到端超时)为 90ms,这也就意味着最慢的长尾查询都不能超过 90ms;
- 可以容忍 false positive。有些内容虽然被过滤掉了,但是系统仍然能为用户召回足够多可能感兴趣的内容,只要 false positive rate 被控制在可接受的范围就可以。
解决方案
由于知乎首页的重要性,在设计已读服务架构时,知乎重点考虑三个设计目标:高可用、高性能、易扩展。
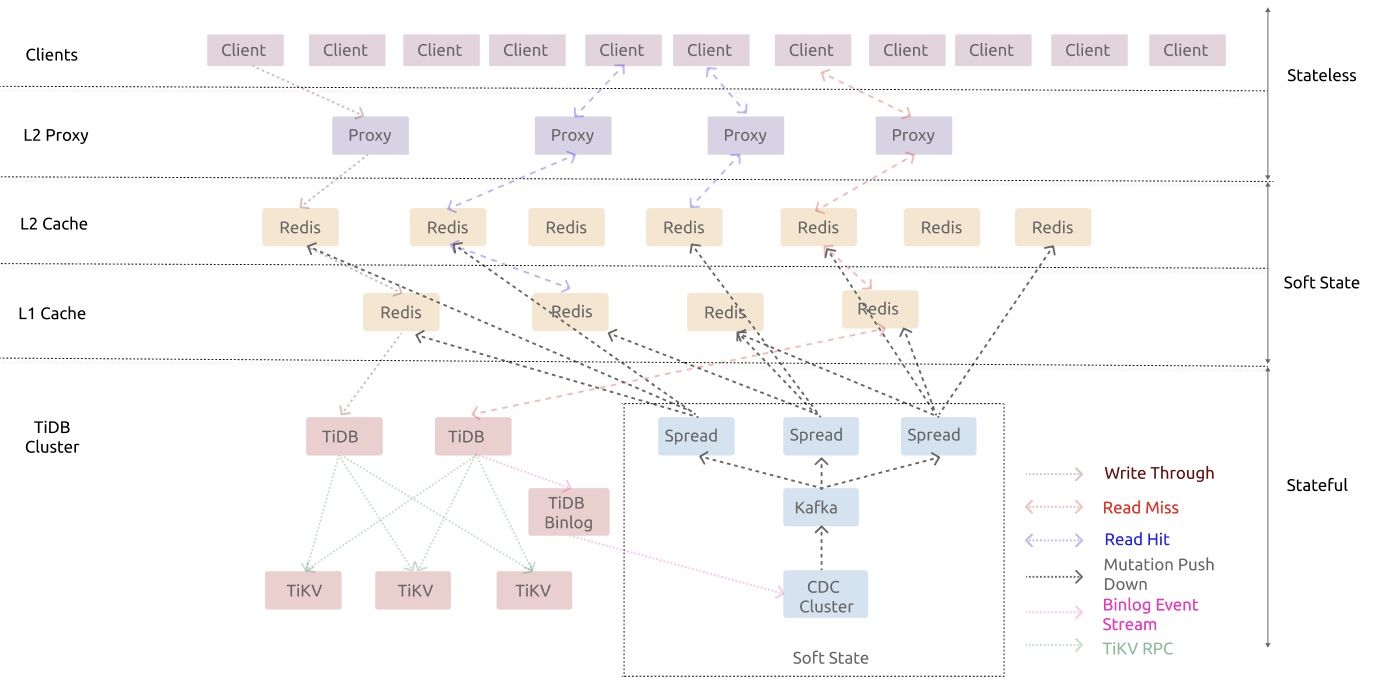
已读服务框架上层的客户端 API 和 Proxy 是完全无状态可随时扩展的组件。最底层为存储全部状态数据的 TiDB,中间组件都是弱状态的组件,主体是分层的 Redis 缓冲。除了 Redis 缓冲外,还有一些其他外部组件配合 Redis 来保证 Cache 的一致性。
存储层,知乎最初采用了 MySQL 数据库,但在面临知乎这个体量的数据时 MySQL 单机已经无法满足需求,尽管尝试了分库分表+ MHA 机制,当每月新增 1000 亿条数据的情况下也无法安心应对。寻找一款可持续发展、可维护、高可用的替代方案迫在眉睫,最终,知乎选择了对 MySQL 高度兼容的 TiDB 作为替代方案。在整个系统中,TiDB 层自身已经拥有高可用能力,可以实现自愈。系统中无状态的组件非常容易扩展,而有状态的组件中弱状态的部分也可以通过 TiDB 保存的数据恢复,出现故障时也可以自愈。
此外,系统中还有一些组件负责维护缓冲一致性,但它们自身是没有状态的。所以在系统所有组件拥有自愈能力和全局故障监测的前提下,知乎使用 Kubernetes 来管理整个系统,从而在机制上确保整个服务的高可用。
用户收益
- TiDB 高度兼容 MySQL,知乎原有业务只需进行少量修改即可平滑迁移,替换风险小;
- 基于分布式架构的 TiDB 可以进行水平弹性扩展,在遇到数据量大幅增长时只需简单地增加节点就可以实现容量和性能的线性提升;
- 大大提升知乎已读服务吞吐量,迁移至 TiDB 后,已读服务的流量已达 40000 行记录写入,30000 独立查询和 1200 万个文档判读,在这样的压力下已读服务响应时间的 P99 与 P999 仍然维持在 25ms 和 50ms。

客户简介
行业:生活服务
知乎于 2011 年 1 月正式上线,是中文互联网高质量的问答社区和创作者聚集的原创内容平台。截至 2020 年, 已有超过 4000 万名答主在知乎创作,全站问题总数超过 4400 万,回答总数超过 2.4 亿。


