
vivo 为用户提供了在手机上备份联系人、短信、便签、书签等数据的能力,底层存储采用 MySQL 数据库进行数据存储。随着 vivo 业务发展,用户量增长迅速,存储在云端的数据量越来越大,海量数据给后端存储和数据库带来了巨大的挑战。云服务业务最大的痛点,就是如何解决用户海量数据的存储问题。
vivo 数据库与存储体系

在整个 vivo 云服务体系中,数据库与存储处于核心位置,从体系上可以分为两层,最上面一层是工具产品层,包含数据库存储统一管控平台、数据传输服务(支持数据同步、数据订阅、数据迁移等)、运维白屏化工具等。下面一层是数据库产品层,这一层又分为三个部分:一部分是 MySQL、 TiDB 等关系型数据库;一部分是 Redis、ElasticSearch、MongoDB、磁盘 KV 等非关系型数据库;还有一部分是对象存储、文件存储、块存储等存储服务。
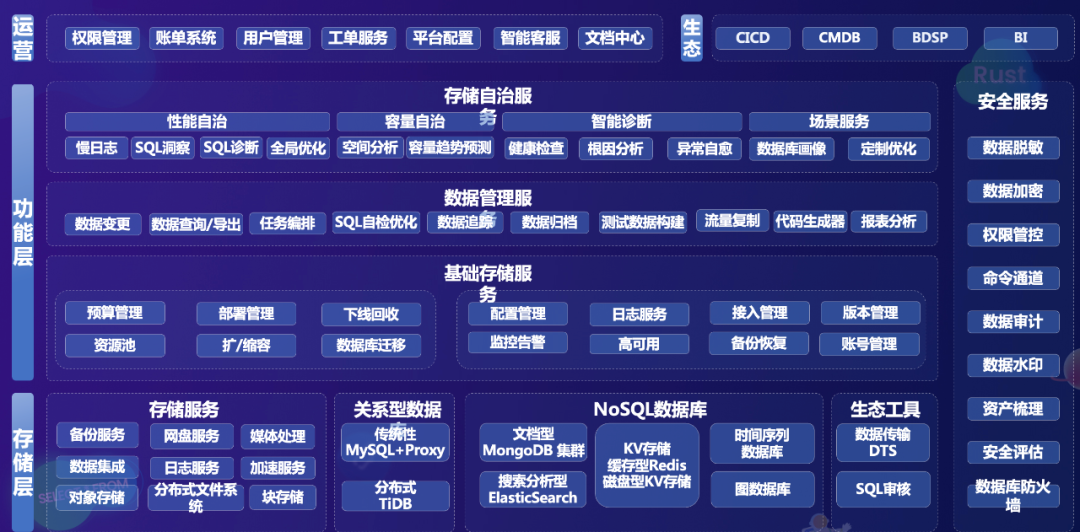
为了管理这些众多的数据库与存储产品,vivo 打造了一个数据库与存储运营管理平台,主要分为三层架构:
- 最底层是支撑、管理所有数据库的工具产品,包含数据存储服务、关系型数据库、NoSQL 数据库,以及生态工具;
- 中间是功能层,包括基础存储服务、数据管理服务,以及存储自治服务;
- 最上面是运营层,包括权限账单、用户管理、工单服务等基础服务。同时还有一些安全相关服务,如数据脱敏、数据加密、权限管控、命令通道、数据审计等一系列功能。
TiDB 在 vivo 的落地实践
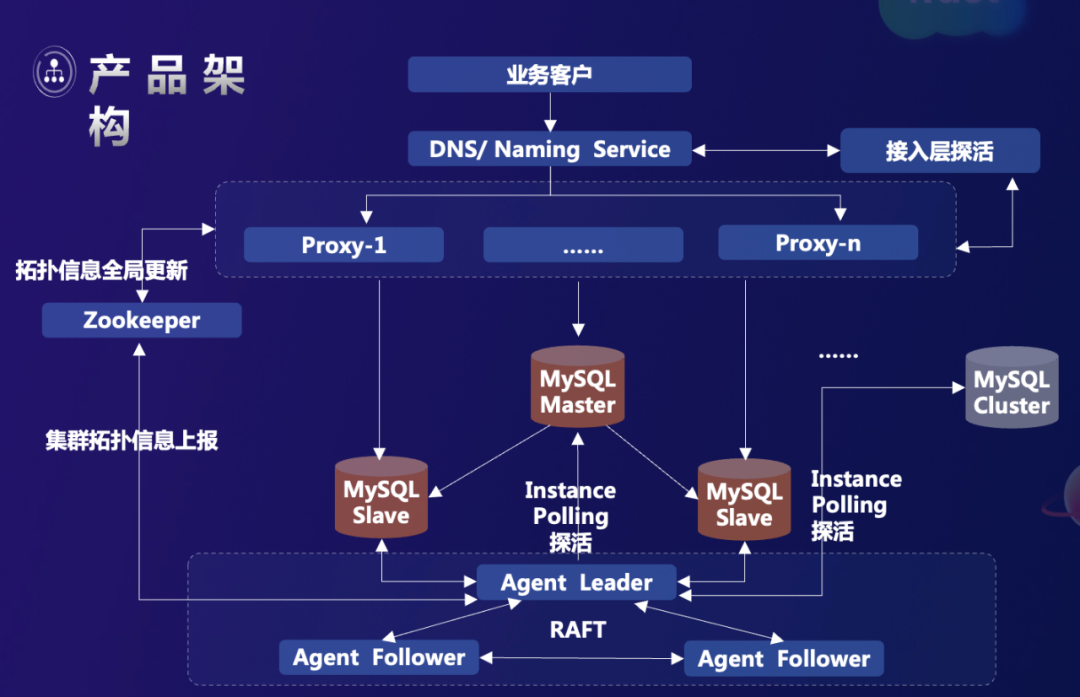
此前,vivo 已经用了很多年关系型数据库 MySQL。基于原生的 MySQL 数据库,vivo 结合集群高可用的管理与数据库代理的一体化架构,通过域名服务、名字服务进行接入,提供通用的关系型数据库服务。它主要具有三大核心能力:
- 第一,兼容 MySQL 协议与 SQL 语法;
- 第二,增强 MySQL 集群管控能力。vivo 引入 MySQL 的时间很早,在 MySQL 的一些集群管控能力上都有自研的能力;
- 第三,安全增强能力,包括密码管理、数据脱敏、数据加密等能力。
本质上 MySQL 架构还是一个主从架构,并没有分布式技术引入。针对数据量较大、流量较大的场景,或者分析场景,给业务带来了巨大挑战。基于以上原因,vivo 在对比了主流分布式数据后后考虑引入分布式关系型数据库 TiDB,作为关系型数据库产品矩阵的一环,补充整个关系型数据库的能力。
引入 TiDB 帮助 vivo 解决了一些在 MySQL 生态中无法解决的问题:
- TiDB 可以解决数据量过大、流量过大的问题,以及海量数据分析的场景;
- TiDB 兼容 MySQL 语法,业务迁移比较平滑;
- TiDB 支持水平扩展,相比传统的 MySQL 复杂的分库分表方式,TiDB 的扩展能力大大降低了运维压力;
- TiDB 具备数据强一致性、高可用性,可以提供金融级数据安全性。
vivo 研发团队具有较强的自研能力,他们将内部所有数据库统一实现了平台化管理,这是一种提供高度自助、高度智能化、高可用、低成本的数据存储使用与管理平台,包含从数据库服务的申请、部署、维护、变更、优化,以及数据恢复、服务下线等一系列数据库全生命周期的管理。
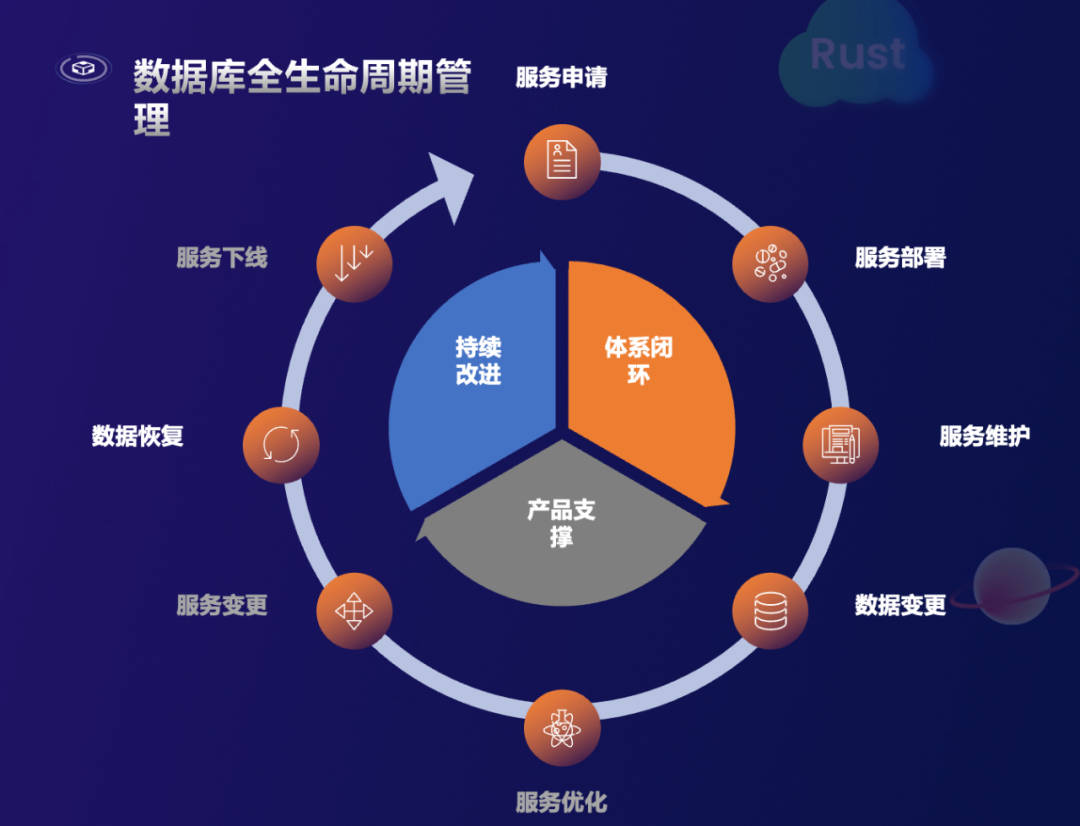
在应用 TiDB 后,vivo 研发团队同样也将 TiDB 集成到该平台中,实现诸如 TiDB 的自动化部署、服务维护、数据变更、数据恢复,包括一些还在持续建设中的能力,如服务优化、服务变更。这些能力与 vivo 的全球化业务场景息息相关。全球化业务场景要求更好满足于本地客户服务,以及符合本地数据安全相关的一些管理规范。所以 vivo 的服务都是本地化部署,平台化的管理方式可以帮助运维、研发更好地支撑业务研发或者业务变更的效率。
该平台一方面提升了 vivo 整个数据服务的安全性,如账号密码管控、敏感数据加密脱敏、集成的研发效能等。在业务开发团队需要一个 TiDB 服务的时候,几分钟内就能得到一款分布式数据库进行代码开发,降低了运维管理成本;运维(DBA)再也不需要登陆服务器执行各种涉钥命令;最后,平台也大大提升了数据的可用性。vivo 数据库团队将一些 TiDB 的备份恢复工具及数据库的可用性也集成在平台里。
应用场景
推送业务基于 TiDB 的海量数据实时 OLAP 方案
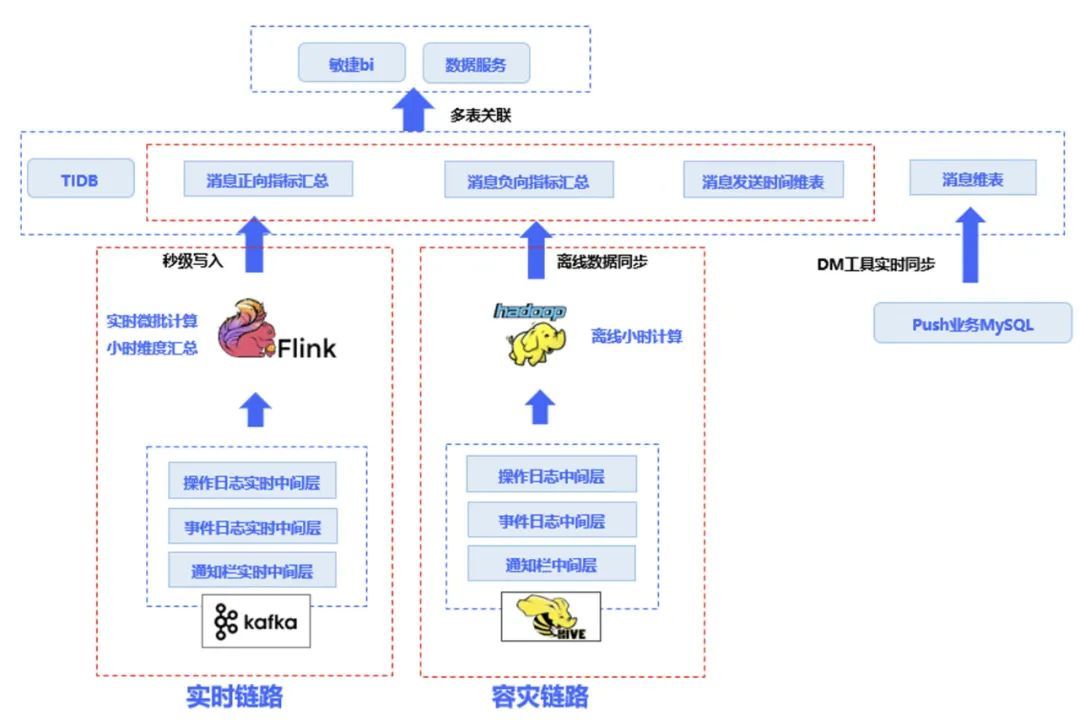
vivo 的推送业务基于 TiDB 实现了一套实时 OLAP 方案。该场景中具有千亿级别的数据指标,vivo 希望数据在数据指标写入时可以实现秒级入库。同时,该场景还要求以月度为范围秒级出报表。原方案中使用了其他 OLAP 数据库方案或 MySQL 方案,在出报表时总会给数据库集群服务造成很大压力,指标的计算性、时效性也很差。尤其当面临海量数据时,查询与指标变更成本会变得很高。引入 TiDB 后,vivo 可以从实时链路里直接把数据秒级写入,再通过 DM 工具,把关系型数据库里面维度的数据,以及其他相关联的数据都同步过来,最终在 TiDB 中进行多表关联,为最终用户提供数据服务,如 BI 报表等。在该场景中,TiDB 的高性能、低延时等特性解决了 vivo 数据量大、时效性高等难题。
云服务业务基于 TiDB 的海量元数据管理方案
vivo 云服务是 vivo 为用户提供的在手机上进行数据备份、数据恢复同步的一款服务。这款服务用到了对象存储与文件存储,同时有大量的元数据需要存储。原方案使用了 MySQL 分库分表的方式,但 MySQL 实际上还是一个单集群方案,分库分表的业务逻辑需要在业务层实现,这就需要解决复杂的业务逻辑问题。同时,分库分表造成运维十分困难,扩容成本高、扩容耗时间长。基于以上原因,vivo 基于 TiDB 实现了一套海量元数据管理方案,支撑了 vivo 百亿级别的元数据表和日志数据表存储,核心业务时延小于 50ms。
基于 TiKV 自研的 NoSQL 数据库实践
由于 TiDB 整个产品都采用开源的模式,vivo 并没有满足于只作为 TiDB 的使用者,还基于 TiDB 的底层存储引擎 TiKV 自研了一款 NoSQL 数据库,希望能够实现一个高性能的、高稳定的多数据模型的分布式数据库,用以服务内部大数据量存储场景,降低整体数据库的运营成本,同时还针对一些 AI 特殊业务场景的应用进行定制优化。
在此之前,vivo 的 NoSQL 数据库产品矩阵中 KV 产品实际上只有 Redis,但 Redis 是基于内存的存储,性能虽然很好,但存在数据无法持久化及成本高等问题。基于此,vivo 基于 TiKV 研发了自己的 NoSQL 数据库。它兼容 Redis 协议,能够以很低的成本进行迁移,可以持久化大规模存储 TB 级别,甚至 PB 级别数据,还具备高性能、水平扩展、高效故障切换、数据安全保证一致性等特点。之所以能做到这些,很大程度上是因为 TiKV 原本就具备了很好的能力,如存储引擎水平扩展能力、高效故障切换能力、数据安全保证能力等。目前,这款 NoSQL 数据库已经在 vivo 内部的推荐平台、内部管理平台、应用中心中应用。
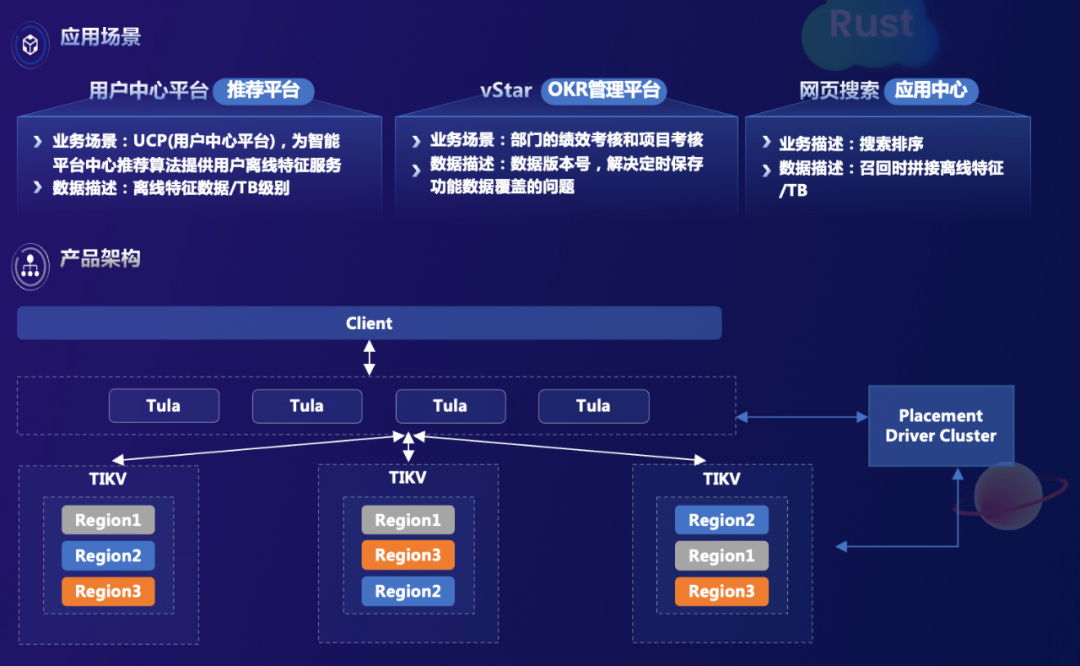
通过引入 TiDB,vivo 解决了原 MySQL 架构无法应对数据量大、流量大等挑战,优秀的水平扩展能力及高可用特性支撑了 vivo 百亿级别的元数据表和日志数据表存储,核心业务时延不到 50ms。同时,TiDB 的实时 HTAP 能力还帮助 vivo 解决了报表时效性问题。未来,vivo 还将持续在内部混合云中云化 TiDB 产品,将 TiDB 全生命周期的各个能力,在 vivo 内部云上实现出来,支持更多的业务场景。

客户简介
行业:汽车与制造
vivo 是一家全球性的移动互联网智能终端公司,品牌产品包括智能手机、平板电脑、智能手表等,截至 2022 年 8 月,已进驻 60 多个国家和地区,全球用户覆盖 4 亿多人。


