
导读
在 TiDB 走进多点活动中,来自马上消费金融的 DBA 段勇老师分享了《TiDB vs MySQL:消费金融公司在高并发、跨中心热备场景下的实践探索》,本文为分享实录。
段老师是一枚 TiDB 粉丝,在公司内部主要负责 TiDB 的维护管理工作,他分享了马上消费金融在选型、使用 TiDB 过程中遇到的一些经验和问题,包括高并发、多活热备等场景下的使用实践,您可以从中了解到 TiDB 和 MySQL 各自应用场景以及优劣势。相较于 MySQL,TiDB 在水平扩展能力、高可用性和简化数据栈等方面的优势。希望本文在数据库选型和应用层面对您有所裨益。

马上消费金融股份有限公司(简称“马上消费”)是一家经原中国银保监会批准,持有消费金融牌照的科技驱动型金融机构。从 2015 年 6 月成立以来,完成三次增资扩股,注册资本金达到 40 多亿,累计交易额超过万亿。随着业务数据量的增长,马上消费使用的数据库面临着新的挑战。
消费金融机构为什么使用 MySQL?
MySQL 是一个典型的关系型数据库,经过多年深耕发展,已成为业内应用最广泛的数据库。它提供了关系型数据库里典型的功能,如数据安全性、事务处理、高可用以及性能优化等。其稳定性经过多年的考验,不论中小型企业,还是传统金融行业,都有很多的应用场景。

大家都知道金融机构对数据安全性的要求非常严苛,MySQL 之所以能够成为金融行业的选择对象,首先是因为它具有很高的可靠性和稳定性,这对于涉及大量交易记录、账户管理和风险管理的金融行业来说至关重要。其次是扩展性、性能表现、成本效益以及安全合规。这里重点介绍扩展性,MySQL 支持主从复制、读写分离、集群部署等多种高可用架构设计,可以有效应对金融行业日益增长的数据处理需求和并发访问量。但 MySQL 如果不做分库分表,就只能通过增加从库的方式进行只读扩展,写扩展需要做分库分表,实现难度大大增加。

在使用 MySQL 过程中遇到的问题
MySQL 存在很多局限性,第一是大数据集处理,第二是高并发处理,第三是高可用与容灾恢复。前两个问题可以归结为一个,就是无法突破单机性能瓶颈的问题。高可用和容灾恢复同样也存在问题,比如异步复制,如果主节点的压力过大,就会存在主从延迟。如果选择高一致性,比如 MGR,那性能就会有损耗,这是一个两难的选择。
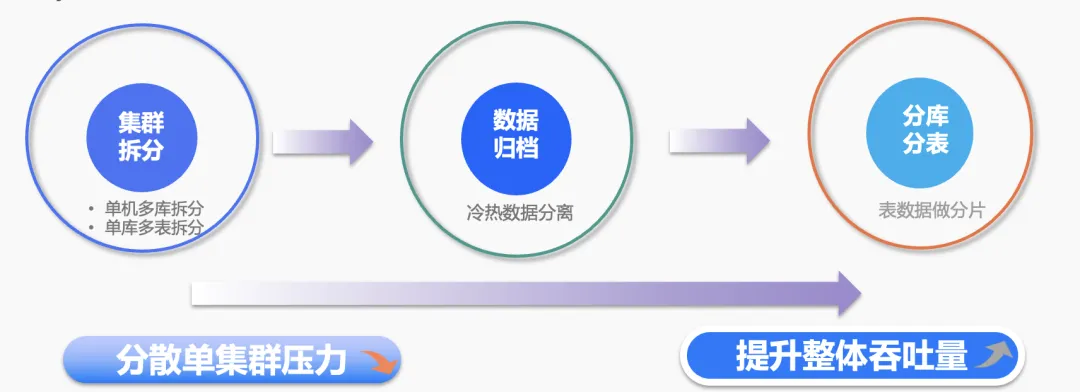
基于这三个痛点,我们在日常使用 MySQL 的时候,都会经历过三个阶段:首先是单机多库拆分,单库多表拆分,然后到冷热数据分离,最后到表数据分片。这三个处理方案其实都有各自的缺陷,下面一一展开:
集群拆分
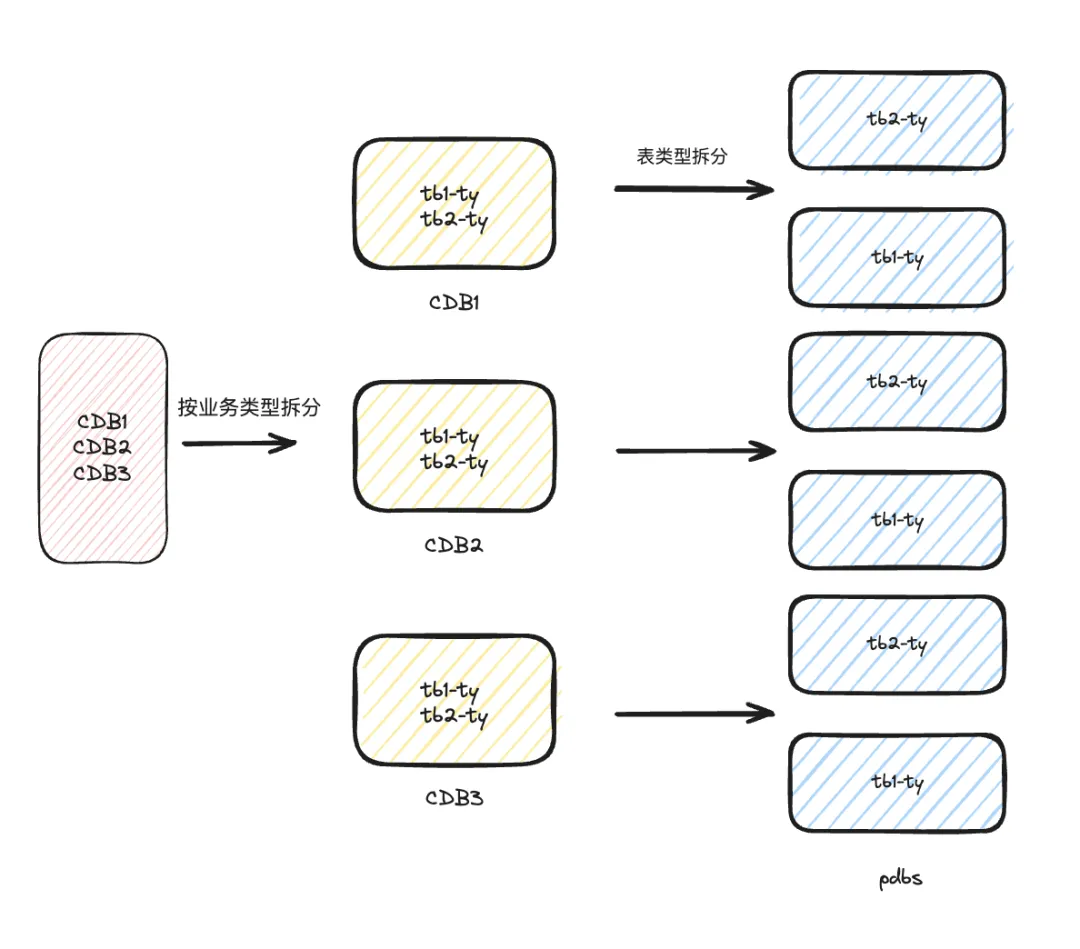
在企业起步阶段,单个集群可能融合了多个数据库。随着业务量的增加,单个集群无法承载压力时,就会做库的拆分,按业务类型各自使用单独的集群,从而分散压力。如果是单库没法拆的情况下,我们会按照业务场景去分拆表,比如说 a 业务使用三个表, b 业务也使用三个表,那 a 业务的三个表就放到一个集群, b 业务放到另一个集群。这个方案局限性在哪?主要是单库的并发量,即使做了拆分,表的数据量达到一定程度之后,也无法满足业务的并发需求。此外,有的业务模型拥有几百张表,它们平常在处理业务的过程中,之间是有相互 join 的,这种情况就不满足拆分场景。还有一种是跨库关联,多个库里的一些表,需要去做一些 join,拆分之后显然无法实现了。
数据归档
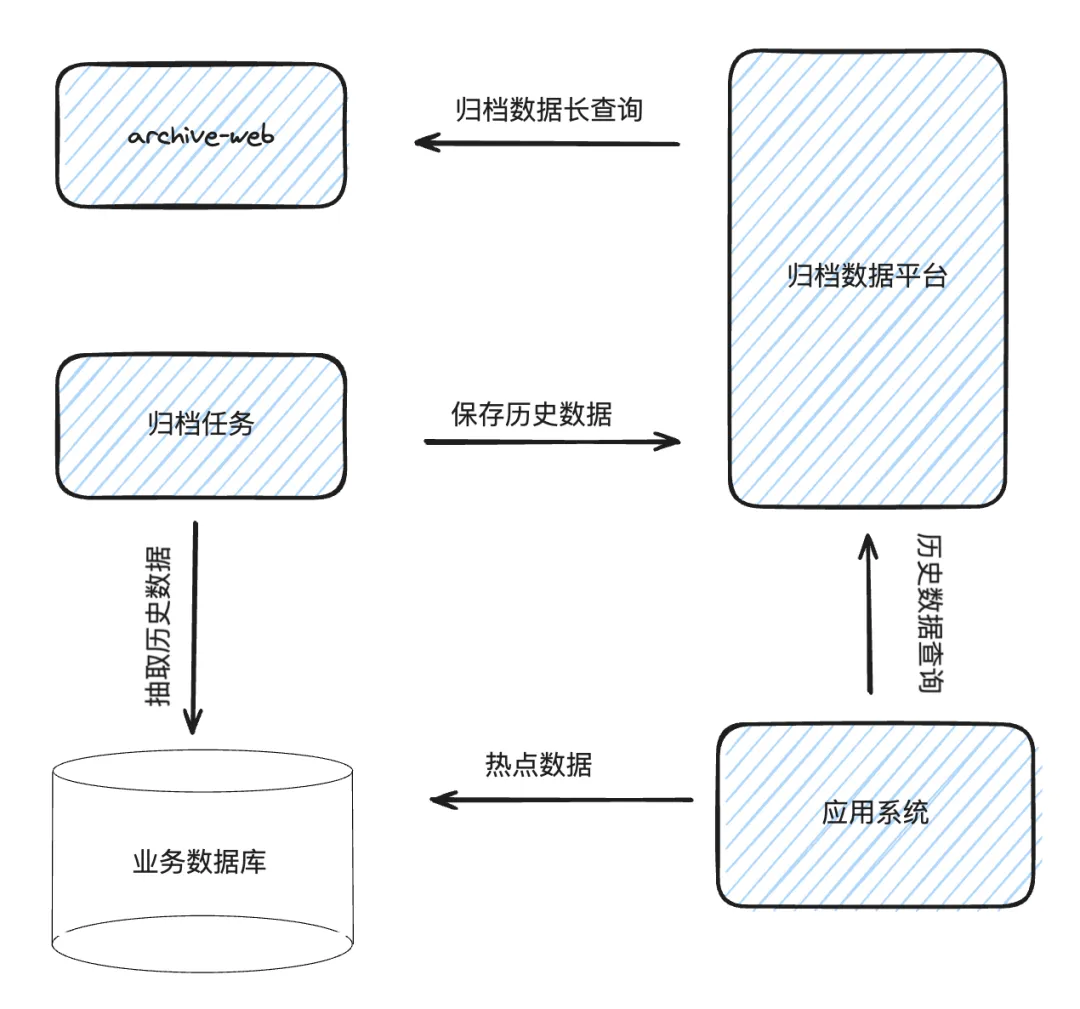
当单库的数据量已经到达一定规模,拆无可拆时,就需要做历史数据归档。比如说三个月前的数据可能用得不是特别频繁,那就可以把这三个月的数据直接放到归档平台。上图是一个典型的数据归档处理逻辑,首先提供一个归档平台,热数据放到在线的数据库集群,历史数据放到归档平台。但这个方案也有一些局限,比如历史数据保存了 3 年,但这 3 年的数据都有比较高频的访问,而且数据量特别大,数据没法做冷热分离,这个场景下归档就无法实现。我们的归档平台很多时候是基于 HBase 大数据平台搭建,对于高频的查询需求无法满足。此外,如果是单集群,近三个月的热点数据已经超过了单机性能瓶颈,这个方案也无法适用。
分库分表
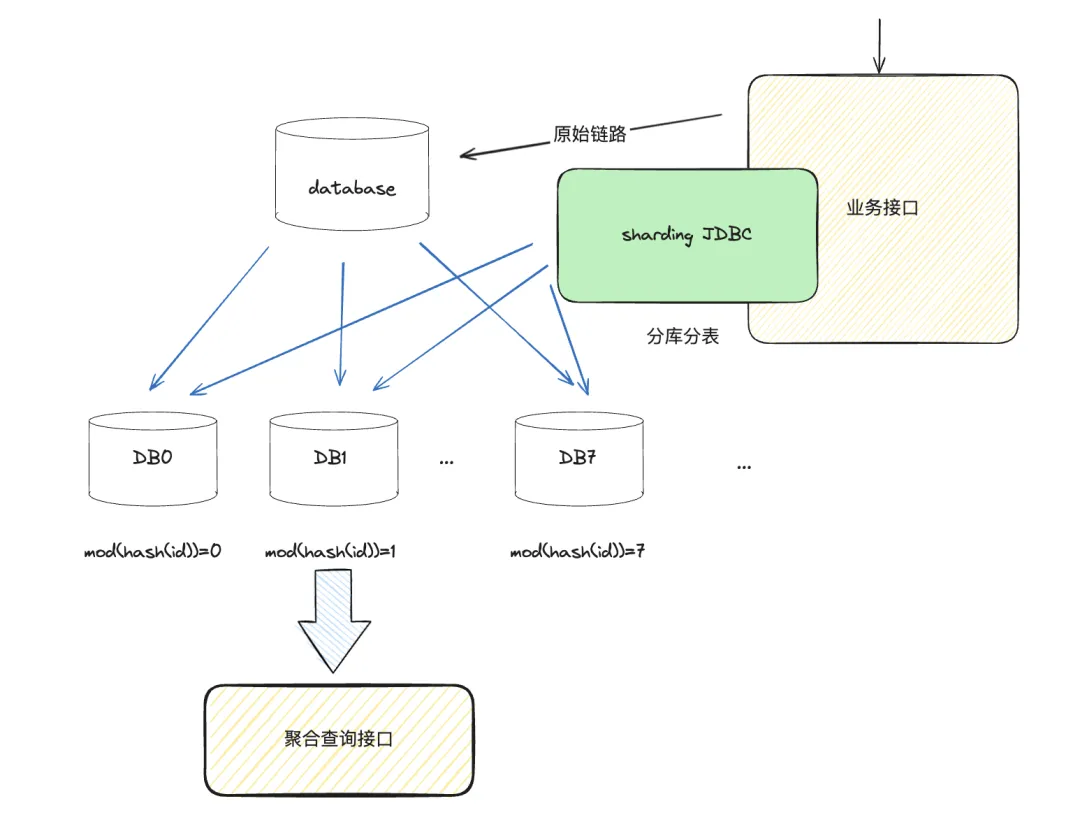
在 MySQL 层面,最终的解决方案就是大家常说的分库分表。它的基本逻辑就是把一个库拆成多个库,按这个库的 ID 取哈希,取模,然后分成若干个库。这个方案也存在一些难点,一是聚合查询,这么多库如果要关联查询怎么办?二是增加分片的时候,业务改造难度太大,也会导致运维成本增高。比如说有 64 个分片,如果要添加一个字段,在没有自动化管理平台的情况下,需要一个个手动添加这个字段。此外,从单库拆库时的业务改造难度也特别大,每一次拆库都会面临着业务的改造。

基于以上这些问题,我们迫切地想要引入分布式数据库。当时,我们做数据库选型主要关注以下几个方面:
- 开源社区活跃度。社区活跃度直接反映了这个数据库的成熟度,以及它在市场上的使用量;
- 读写协议兼容统一。我们之前的所有业务基本都是在 MySQL 上使用,要迁到一款新的分布式数据库,必须要兼容 MySQL 所有协议,尽量降低代码改造量;
- 有明确的服务边界。锚定分布式数据库的使用场景,我不想去挑战数据库的极限,如果这个数据库不支持我的业务场景,那也是不行的;
- 高可用。这款分布式数据库一定要满足业务对 PTO 和 RTO 的要求。
TiDB 与 MySQL 的关键特性对比:Why TiDB?
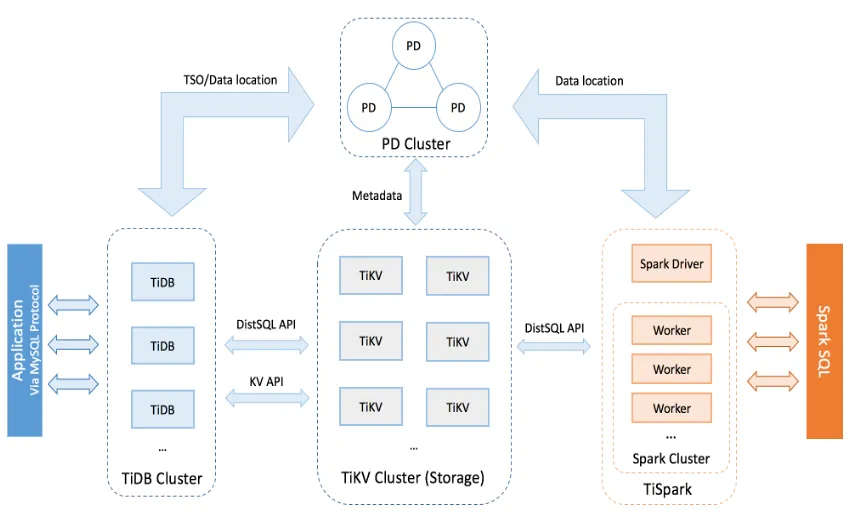
基于上述这些选型标准,我们来看 TiDB 的架构特点:
- 首先,TiDB 在数据一致性、可靠性、高可用以及可扩展性等方面表现成熟,与金融行业的属性比较吻合。
- 其次,TiDB 完全能够满足可扩展性和并发要求高的 OLTP 场景。很多行业可能都把 TiDB 用在 OLAP 场景里,但其实对于大并发的 OLTP 场景,TiDB 也是不错的选择。
- 第三,TiDB 满足 HTAP 场景需求,既做 OLTP 业务,也做 OLAP 业务。
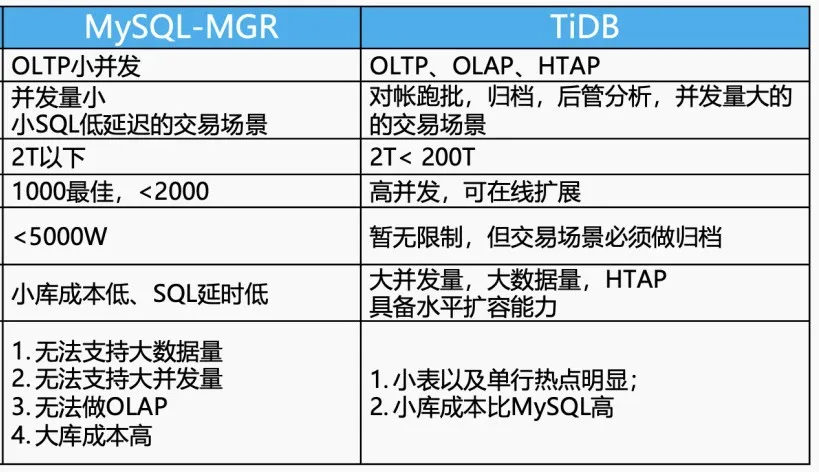
基于 TiDB 的这些特性,我们将 TiDB 与 MySQL-MGR 做了关键特性对比。对于 MySQL,我们有完整的 SOP,比如开发规范有严格的标准,数据量必须在什么范围内来使用 MySQL。超过了这个范围,就要去做拆分。此外,哪些参数必须满足,也都形成了严格的规范,比如说关联查询限制在多少个表,这些都是基于 MySQL 的局限性来考虑的。
支持场景类型:MySQL 支持 OLTP 的小并发场景,而 TiDB 对于 OLTP、OLAP 都能够支持。如果落地场景是 SQL 并发小,低延迟的交易系统,MySQL 的性能其实相对 TiDB 来说是要更优一点,而对于对账、跑批、归纳分析,以及并发量比较大的交易场景,TiDB 都有比较大的优势。
数据量要求:我们在生产环境中对数据量的要求是在 2TB 以下时使用 MySQL,大于 2T 小于 200T 使用 TiDB。目前,我们交易系统的数据量要求是在 50T 范围内,超过 50T 做归档的业务必须拆出去。在 TPS 层面,小于 2, 000 的 TPS 在 MySQL 上表现相对良好。如果业务增长特别快,必须在线扩展,对于 MySQL 来说相对比较困难,TiDB 就可以支持在线横向扩展。
单表大小:对单表的限制,我们现在一般在 MySQL 层面要求 5,000w 以内,在 TiDB 层面不会做太多限制。
总体而言,MySQL 在单机性能和成熟度上有明显优势,而 TiDB 在处理分布式、高并发、大规模数据场景下展现出卓越的扩展性和强一致性保证。
真实场景下的应用实践
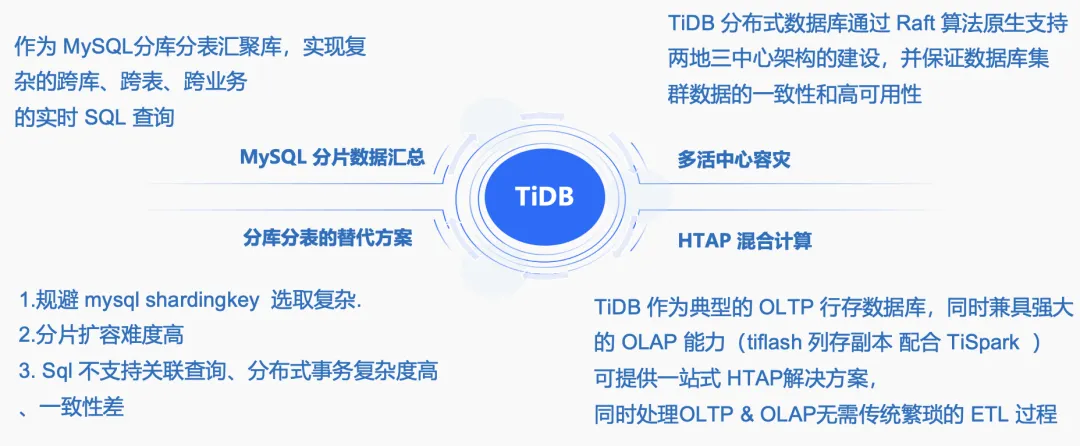
我们对 TiDB 的应用实践,主要分为以下四个场景:
- 作为 MySQL 分片数据的聚合库。实现复杂的跨库、跨表、跨业务的实时查询。
- 三中心多活容灾。MySQL 在实现多活跨中心部署的时候,难度相对来说比较大。因为跨中心访问,要不建立主从,要不引入第三方同步工具,对它的主从延迟都是比较大的考验。而 TiDB 天然支持两地三中心的部署,每一个 zone 可以分别在自己的数据中心部署,任何一个数据中心宕机,数据完整性不受影响。
- 作为分库分表的替代方案。MySQL 需要做分表的时候,用 Sharding 选取相对比较复杂,分片的扩容难度相对来说也较高,用 TiDB 的话就可以规避这些问题。
- HTAP 混合计算。TiDB 作为典型的 OLTP 行存数据库,同时又兼具 OLAP 能力,比如 TiFlash、TiSpark 等,我们在真实的生产环境中也在使用。
海量交易数据存储与检索
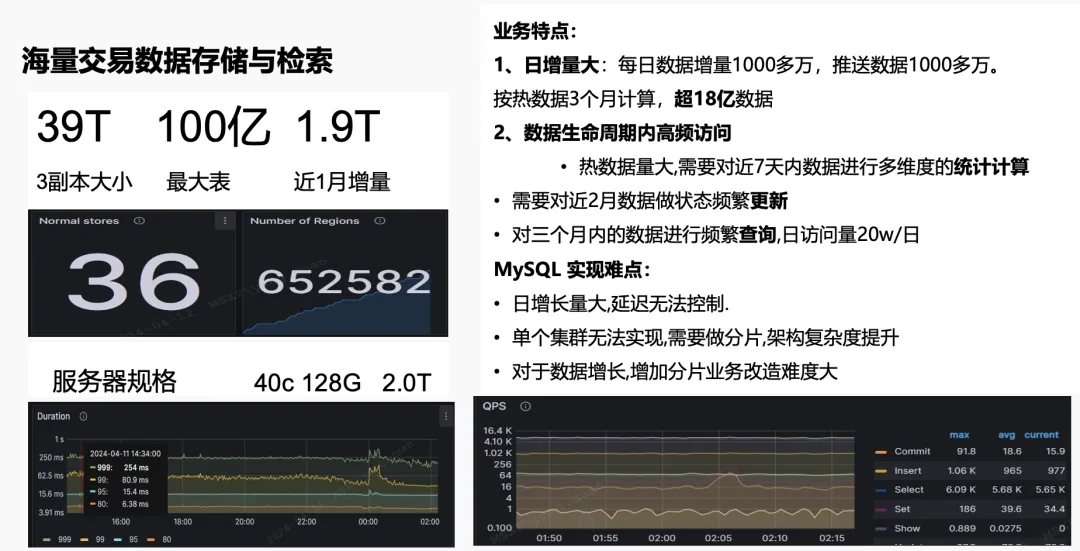
上图是马上消费金融比较典型的在线业务系统消息平台,也是我们的 13 大核心系统之一。当前总数据量三副本已经达到 39 TB,最大表过了上百亿,每个月的增量差不多在 1.9T 左右。
消息平台的业务特点主要有两个:
- 日增量大:每天的数据增量大约有 1, 000 多万,推送的跑批数据也有 1, 000 多万。热度数据按三个月计算,已超 18 亿。
- 数据生命周期内高频访问:热数据量大,需要对 7 天内的数据进行多维度的统计计算;对近 2 个月的数据做频繁变更;对 3 个月内的数据进行频繁查询,日访问量达 20 万。
如果这个业务使用 MySQL 会特别困难,需要及时做分库分表,当时估算下来的成本差不多是 TiDB 的 2-3 倍。引入 TiDB 之后,我们使用了 36 个 TiKV,服务器规格都是 40C/128G/2TB,延迟控制在 500 毫秒以内。QPS 虽然看着并不高,但实际这个表都是上百亿的大表,这个 QPS 其实并不小,任何一点波动,它的延迟至少是两三倍。
数据仓库与分析平台
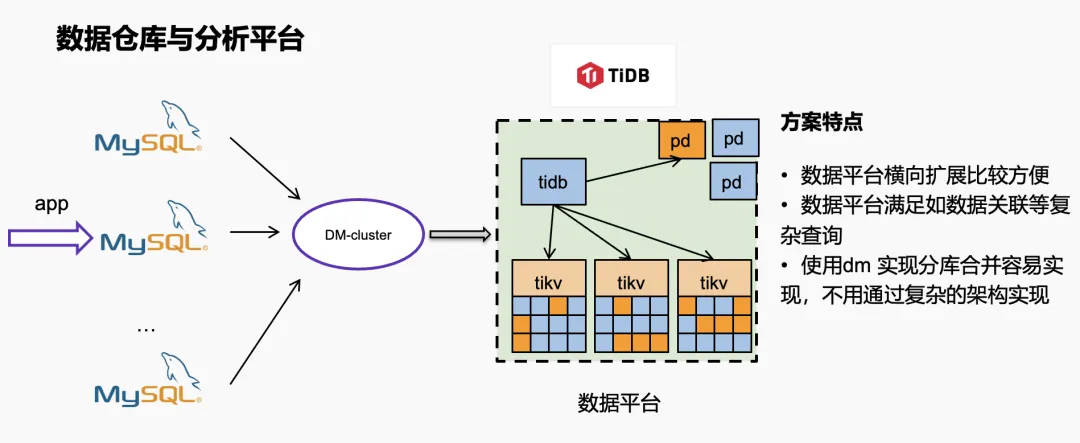
第二个场景是数据仓库与分析平台。我们的数据库是做了分片的,线上的数据做了 64 个分片,数据通过 DM 汇聚到 TiDB 做分析查询。这个方案特点是 TiDB 横向扩展比较方便,不管业务数据怎么增长,通过 DM 同步过来之后,只要堆机器就行了。使用 DM 合并比较容易,无需通过 HBase 归档平台做复杂的关联查询,不用去想那些复杂的架构去做同步方案。
多中心部署
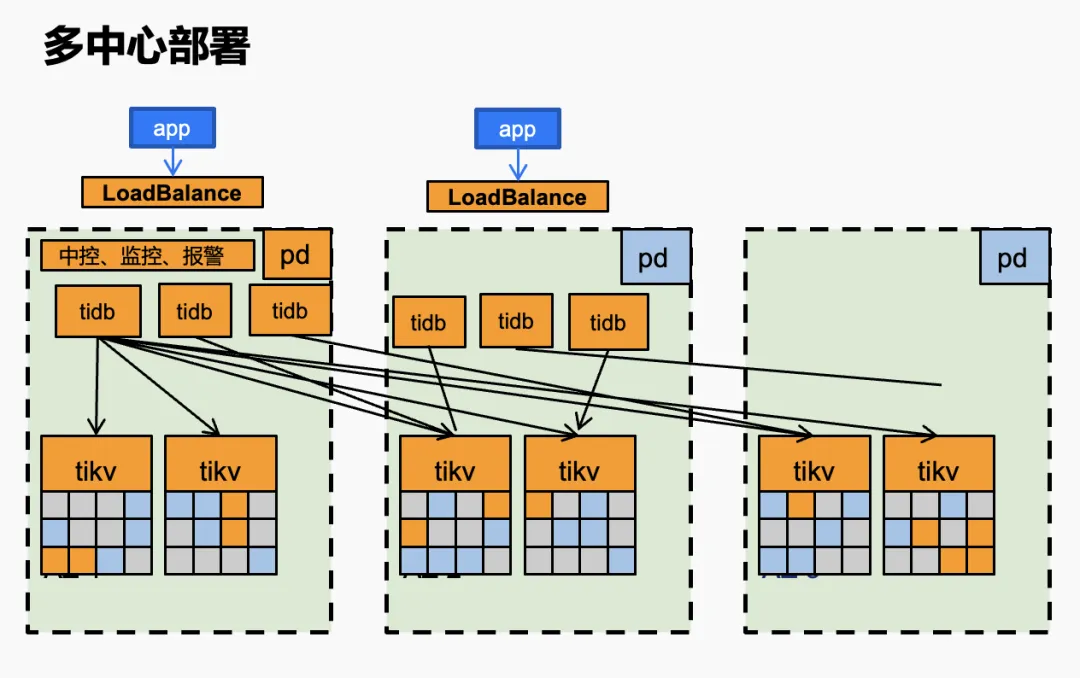
上图是我们目前的多中心部署架构。a 机房作为一个主机房,部署 3 个 TiDB,TiKV 每个分片按 3 个机房部署。其中,第三个机房作为多数派的投票机房,但它也真实存了数据。第二个机房作为热备机房。每个机房的 TiDB 数量一样,TiKV 数量一样。据我所知,目前国内很多金融机构也都是按照这套方案部署的。对于一写多读、双活、多活、RTO、RPO 这些标准,TiDB 都能够非常好地满足。
如果用 MySQL 实现多中心部署是比较困难的,因为主从延迟就没法规避,如果要减降低主从延迟,就得拆库,实现难度很高。对于这个架构而言,选择 TiDB 部署方案就会简单很多,但也有几个难点:
- 第一,对网络的延迟要求很高。当时线上跨机房的网络延迟过高时,业务上对延迟的感知会成倍增长。
- 第二,因为涉及到跨中心的网络访问,PD leader 要做合理规划。主机房的 PD leader 肯定要在自己的机房内,所以要做合理的策略调整。
- 第三,TiKV leader 规划和成本间的衡量,需要根据自己的业务做合理的平衡。
总结
总结来说,MySQL 在单机性能和成熟度上有明显优势,这毋庸置疑,毕竟 MySQL 在各个行业都有使用场景,而且深耕了多年。而 TiDB 在处理分布式、高并发、大规模数据场景下展现出卓越的扩展性和强一致性保证。TiDB 的 Raft 协议、多副本原理对一致性都有不错的保证。两者在具体使用时应根据项目需求、数据规模、团队技能等因素综合考量。由于金融行业的特殊性,数据库的选择还要满足监管要求、稳定性、性能、安全性和技术支持等多个因素。
关于数据库选型,我认为没有更好的数据库,适合自己业务的,就是最好的数据库。
目录