导读
时隔 2 年,在 TiDB 社区成都地区组织者冯光普老师的协助下,TiDB 社区线下地区活动再次来到成都。来自多点 Dmall 的国内数据库负责人唐万民老师,在《出海多云架构,多点 TiDB 运维实战》的主题分享中,介绍了多点在出海业务场景部署和使用 TiDB 的经历。本文根据唐万民老师的演讲实录进行整理,你可以从中了解到多点从无到有使用 TiDB 的业务场景,多云架构的实践经验,以及版本升级遇到问题的解决方案。

多点的 TiDB 之路
目前,多点在国内和出海都有使用 TiDB 的业务,线上生产环境中共有 46 套 TiDB 集群,300+节点,400TB+ 数据量。这些集群支撑着包含业财融合、TMS、结算、采销、物流、库存凭证、履约、存货核算等在内丰富的业务场景。底层的云资源也根据各地业务需求,选择了腾讯云、华为云、微软云、火山云等众多公有云。
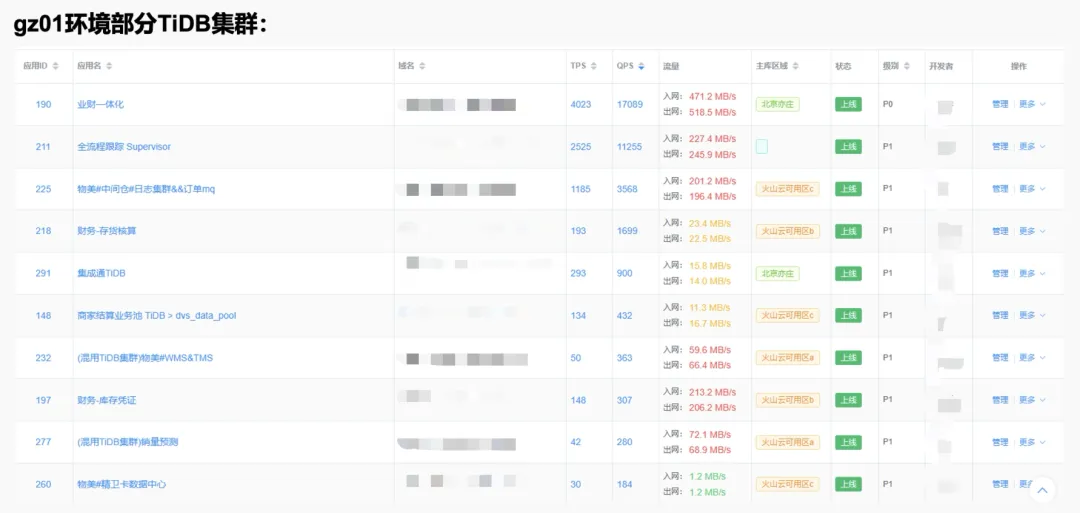
多点大概有二十多个线上生产环境,上图是其中一个环境的部分 TiDB 集群,从中能看出业财一体化的数据库流量非常大,入网出网都是 500 MB/s 左右,QPS 17, 000 看着好像不高,但其实都是一些大的查询和操作。
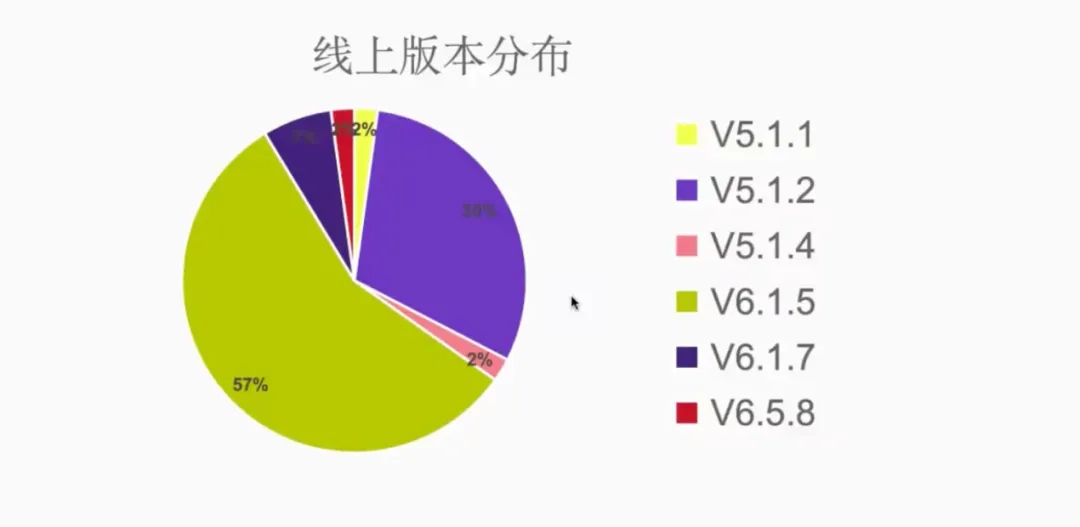
多点目前部署的 TiDB 版本很多,从上图可以看出,从 5.1.1、5.1.2,一直到现在最新升级的 6.5.8 版本都有。其中,线上版本分布最多的是 6.1.5 版。那为什么多点会有如此多的 TiDB 版本,而不全部升级到 6.5.8?其实作为 DBA 而言,对待数据库一般情况下都是能不动就不动,一旦动了就有出问题的风险。而数据库的绝大多数问题、风险是由变更引起的。
但为什么我们又要做升级呢?一是因为业务推动,数据库当前这个版本可能已经满足不了业务需求,不得不升;二是高版本实在太香了,有一些新功能很想用,这个需求已经超过了升级带来的风险。一旦做出选择,我们就会对 TiDB 的新版本做一些调研,看看升级到哪个版本更好。这时候就不得不提到 TiDB 社区的氛围真的非常好,TiDB 的各个版本社区小伙伴都有在用,社区里会有很多人热心地回答我们的一些问题,也会有很多升级、部署的实践分享,我们在选择新版本时就会有更多的经验来参考。
多点与 TiDB 携手前行

作为 TiDB 的老朋友,多点和 TiDB 的缘分很早,从 2018 年起就接触了 TiDB,那时候还是 2.0.3 版本。当时我们想把 MySQL 的一些复杂查询拿到 TiDB 里做,但是测试发现 TiDB 2.0.3 版性能确实不是那么好,MySQL 解决不了的问题,TiDB 也解决不了。
直到 2020 年的 TiDB 4.0 版本开始,TiFlash 出现了,我们就又想尝试一下 TiDB。当时多点的业财业务非常复杂,数据量非常多,MySQL 已经承载不了这个数据。通过调研,我们最终选择将这部分数据迁移到 TiDB。2020 年 6 月开始,TiDB 上线测试环境;9 月,生产环境正式升级到 TiDB 4.0 GA 版本;10 月,生产环境又升级到 4.0.6 版本;2021 年 4 月,继续升级到 4.0.9 版本;2021 年 10 月,升级到 5.1.2 版本;2022 年,升级到 5.1.4;2023 年,升级到 6.1.5;直到最近,我们升级到 TiDB 的 6.5.8 版本。其实,多点每年都在升级新的版本,这里面当然也有一些线上的问题在推动着我们升级,后面会详细展开。
数据库类型选择
多点用 TiDB 到底在做什么?为什么要选择 TiDB?我会从四个场景展开分享多点将 TiDB 应用到哪些场景中。

第一个场景是持续增长类数据。TiDB 在持续增长类的场景中是非常适合使用的,一个是它只管写入,无限扩容,不像 MySQL,如果写多了就要做迁移,做分库分表,要去保证集群的高可用,迁移代价也非常高,要去做各种各样的沟通,还有很多迁移风险。TiDB 有一个平滑迁移的功能,并且存储成本降低了 70%。同时,TiDB 在存储数据时和 MySQL 不一样, MySQL 是没有经过压缩的, TiDB 会经过压缩算法将数据进行压缩。经过我们测试,TiDB 的一个单副本和 MySQL 的单副本比起来最大有接近 10 倍的差距。即便是日志类的数据, TiDB 是三副本, MySQL 是主从两份数据,TiDB 的数据存储成本也会降低很多。

第二个场景是数据冷热分离,历史数据归档。我们在刚开始用 TiDB 时, DM 还没有现在的 DM cluster 那么成熟,所以我们自研了 DRC-TiDB 同步工具,用这个工具去做从 MySQL 到 TiDB 的同步,将一些冷数据、历史归档数据放到 TiDB 里面。然后 MySQL 就保持高性能读写, TiDB 全量储存。

第三个场景是合库合表,OLAP 聚合查询。MySQL 里的数据分布在不同的库和不同的表里面,研发在查询时就会非常痛苦。做分库分表的都知道,在分库分表里去做查询、聚合都非常痛苦。研发其实很喜欢把很多的分库分表,很多的数据聚合在一起,TiDB 可以非常好地支持做这个事情,并且 TiFlash 是列存的数据,有全量数据,我们可以用 TiFlash 去加速一些统计的操作。
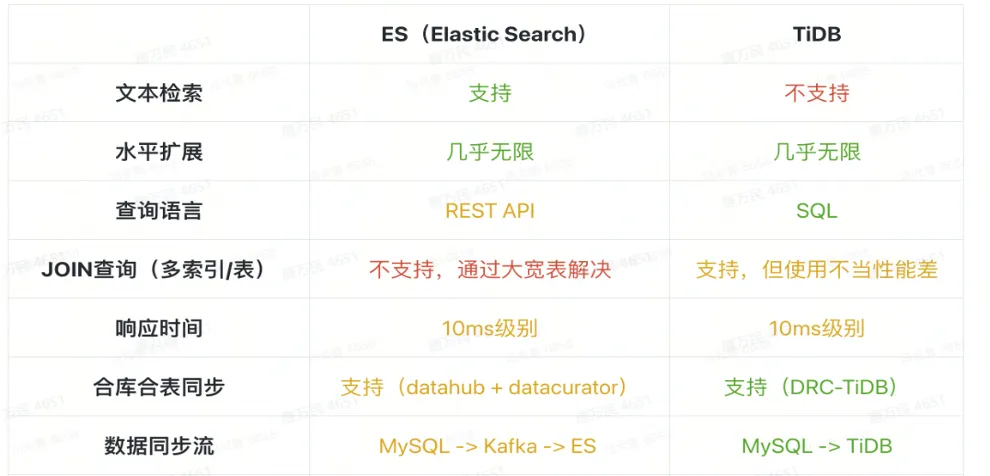
第四个场景是替换 ES。在多点内部, ES 用的非常多,但 ES 的成本非常高。如果涉及到大数据量存储的话,ES 需要很多机器,我们用 TiDB 做了一些 ES 的替换。实话实说,有一些查询场景,比如模糊查询, ES 其实比 TiDB 会更好一些。所以做 ES 替换的时候,我们也做了一些测试,如果迁到 TiDB 里查询性能没有 ES 好,我们就不会去替换。实际结果测下来,有大概 60% 的 ES 是可以替换的,整体成本也降低了很多。
多点的数据技术栈架构
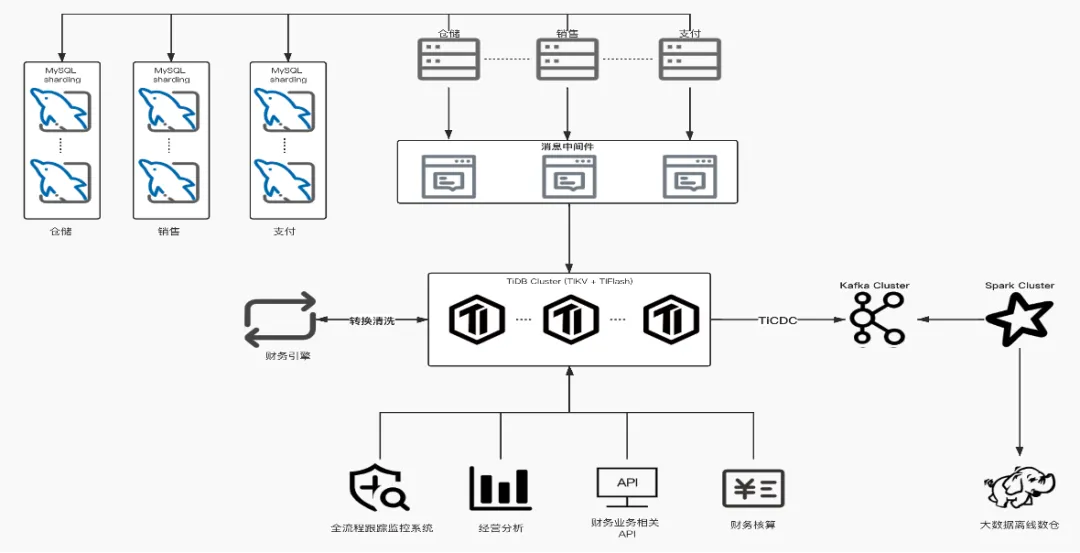
上图是多点数据技术栈的整体架构。数据从 MySQL、仓储、销售、支付这些数据库,通过 DRC-TiDB,流转到 TiDB 集群里;财务引擎也可以直接把数据清洗转换过来,在 TiDB 里面去做读写;其他一些业务也会在 TiDB 里面去做读写。在这个流程的下游,我们会在 TiDB 里面直接去做一些分析,比如一些财务相关 API 、财务核算、全流程的跟踪系统、经营分析等。此外,我们还有一些大数据的需求,是通过 TiCDC 将数据流转到 Kafka,然后再到 Spark,再到大数据离线数仓。比如说有一些离线的报表需求,都是到 Hive 里面去做,整个流程较长。
出海业务 TiDB 部署的架构选择
之前,多点出海业务只部署在微软云上,但慢慢出现了一些问题:
- 第一是多点的 RTA OS (多点的零售技术平台)部署在微软云新加坡 region 上,但经常出现基础设施不稳定的状况,比如云主机异常重启,网络异常,这些问题会导致多点的机器重启或者服务不可用、服务之间断联;
- 第二是 IO 性能不符合预期。比如说有一些磁盘虽然支持 ADE 磁盘加密,但 IO 性能就不是很好。如果不支持,可能又无法满足我们在海外的一些安全要求;
- 第三是微软云的成本较高。
基于这些原因,我们就从只部署微软云改为“微软云+华为云”双机房的部署模式,目标是当任意机房不可用时,TiDB 都可以自动恢复补救数据。我们通过微软云和华为云,在新加坡为 RTA 搭建同城双活架构,应用、中间件、数据库跨 2 个公有云部署,实现 3 个同城机房,任意一个机房不可用业务都可以快速恢复,提高 RTA OS 可用性。
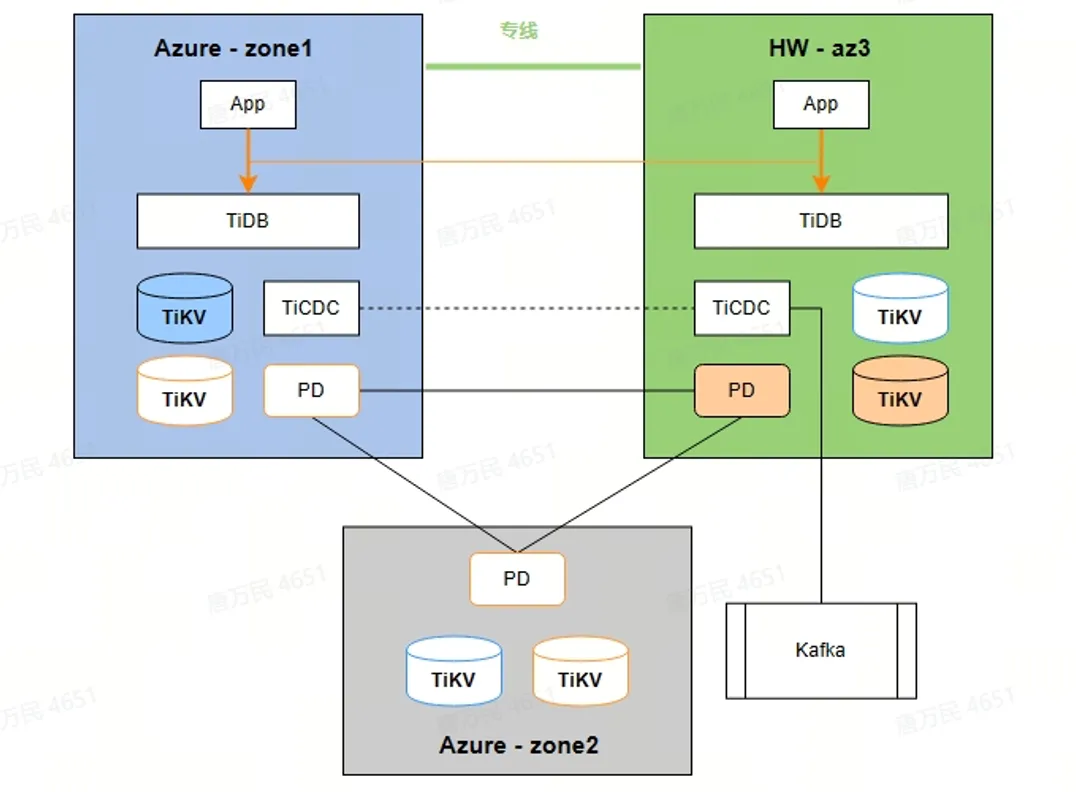
上图是双机房部署方案的架构图,微软云有两个 zone,华为云有一个 zone,TiDB 的 PD 集群跨三个 zone 部署, TiCDC 在微软云和华为云各部署一个节点,TiDB 也在微软云和华为云各部署一套,各部署一些节点。这样做的话,需要在 TiKV 节点打上 dc 的 label,然后去把 region 分布在三个机房。TiDB 至少 2 个节点,跨 2 个机房部署,TiCDC 也是跨 2 个机房部署。我们也对 DRC-TiDB 同步链路恢复做了一些优化,做了一些 master standby 的结构,如果一个 DRC-TiDB 链路中, MySQL 到 TiDB 的链路挂了,另外一个能起到 standby 的作用。

这是我们在 TiKV 上打的一些 dc 的 label,里面的 zone、dc、rack、 host 其实大家都可以自己配置,这只是标识出你要把 region 分布在哪些机器、zone 上。不过,Placement rules 跟这个方法是不能一起使用的,有可能出现预期外的一些问题。
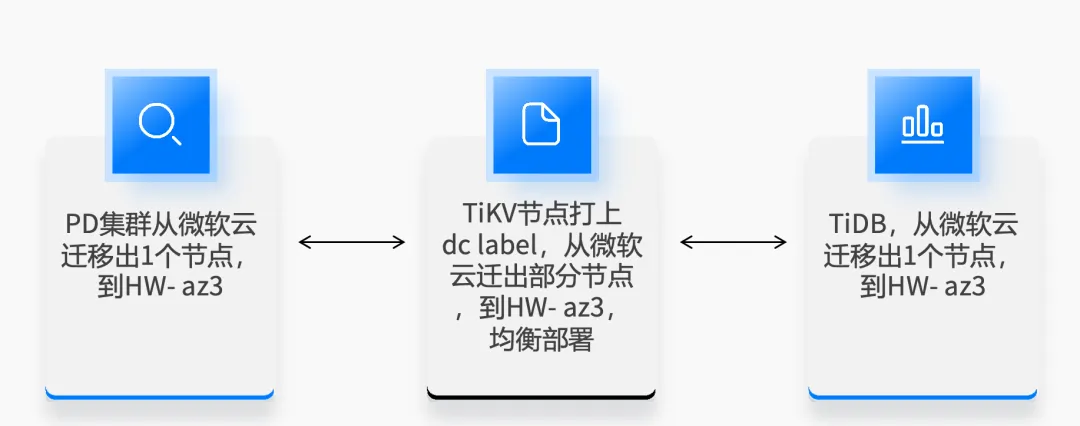
实施方面,我们将 PD 集群从微软云迁移 1 个节点到华为云,TiKV 节点打上 dc label,从微软云迁出部分节点到华为云,等它自动 rebalance 完,然后 TiDB 也从微软云迁出一个节点到华为云。整个过程其实是非常平滑的,如果我们用 MySQL 从一个云迁移到多个云的话,就会非常麻烦。或者将 MySQL 从一个云迁移到另外一个云,也非常麻烦。我们其实做过很多 MySQL 的迁移工作,比如前段时间把腾讯云上的 MySQL 整体迁移到火山云,其中一些环境的工作量非常大,而且风险也很大,但 TiDB 做这种迁移就非常平滑。
多云 TiDB 集群实践过程中的问题
我们在使用 TiDB 的时候也会遇到一些问题,并不是说 TiDB 就完美无缺了。但 TiDB 的社区非常开放活跃,不管遇到什么问题,你去 asktug 上一查,很多问题都有人遇到过了,从他们的分享中你可以直接获得帮助。
比如在 4.0.9 版本,我们遇到过 TiDB Server 的 OOM 问题。它的 expensive SQL hashagg to sreamagg 有一个问题,在内存里面去做一个哈希,TiDB server 耗费的内存非常高。我们当时改成 stream aggregation 走这个执行计划,内存消耗一下就降下来。在 TiDB 更新的版本里,这些问题都已经解决了。其实,在 TiDB 4.0.9 版本中,不论是 TiDB Server、TiKV 或是 TiFlash,内存控制都没现在的版本好。那为什么现在的版本就会好很多?这是因为大量的社区用户都反馈了使用 TiDB 时遇到的问题,经过官方优化,新版本自然就解决了。
4.0.9 还有一个 CDC 的问题。CDC 因为主要是涉及到一些大数据需求,或者需要流转到下游的需求才会用到。如果数据量小的话,应该不会遇到很多问题。当时,我们的 CDC 就是重启后 checkpoint 不推进,挂了以后起不来。这主要是因为当时 sort-engine 默认是 memory,如果机器内存不够,在重启后做排序的时候,它内存就不够了。后面的新版本有 unified sort DR,内存不够了就会先放到磁盘,然后再去做一些排序,做一些 check。
此外,我们的 dashboard 当时按非时间排序查询 slowlog ,导致了 TiDB OOM ,这是因为 plan decode 引起 insert SQL 较大。如果 insert SQL 不大这个问题是不会产生的。还有一些执行计划跑偏的问题,TiFlash 重启起不来的问题,当时我们都遇到过,后续的版本都已经解决了。其实,任何数据库,数据量很小的时候都会没问题,一旦上了量,问题就会变多。所以有我们这种数据量比较大的用户使用 TiDB,就会帮大家把这些雷都排了,大家再遇到这些问题就可以放心使用了。
升级也是大家都会关心的问题,升级后 TiDB 万一起不来怎么办?我们在 5.1.2 版本就遇到了这个问题。TiDB 升级的正常顺序应该是 TiFlash、PD、TiKV、 pump、tidb、drainer、cdc、prometheus、grafana、alertmanager 这样一个顺序。有一次,我们升级的时候 TiFlash 升级完马上就升级 CDC 组件,跳过了 PD、TiKV、 pump,最后升级失败了。当时 TiUP 1.5.1 版本组件可能存在问题,升级到更新的 TiUP 版本就解决了这个问题。
在 6.1.5 版本升级的时候,我们也遇到过问题。当时升级后发现 TiDB 起不来,经过仔细检查发现是因为我们升级前有一个大的 DDL 在跑,升级过程中这个 DDL 阻塞了升级数据字典的操作,数据字典一直没有升级成功,导致 TiDB 就起不来。
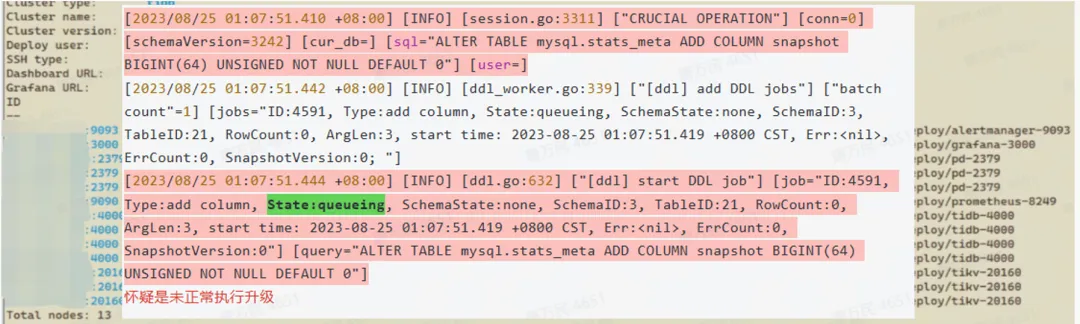
从上图可以看到,有一个 alter table mysql.stats_meta 去加字段的时候加不了,这是我们升级过程中遇到的异常。所以,我建议升级的时候一定要检查有没有大的 DDL。实际上,这个问题也是因为我们的数据量很大,DDL 执行的时间很长,当时没有等 DDL 跑完就重启了,如果数据量小的话应该就不会遇到这个问题。
综上所述,曾经遇到的问题都可以在 TiDB 的新版本得到解决。我给大家的建议是能用新版本就不要用旧版本。很多问题在我们这些老用户用的时候就已经遇到过,这些问题已经反馈给了社区,并陆续在新版本中都已经解决了。我相信,如果用 TiDB 的人越来越多,社区也像现在这样一直活跃的话,TiDB 就会越来越好!
目录
