
什么是 Sort Merge Join
在开始阅读源码之前, 我们来看看什么是 Sort Merge Join (SMJ),定义可以看 wikipedia。简单说来就是将 Join 的两个表,首先根据连接属性进行排序,然后进行一次扫描归并, 进而就可以得出最后的结果。这个算法最大的消耗在于对内外表数据进行排序,而当连接列为索引列时,我们可以利用索引的有序性避免排序带来的消耗, 所以通常在查询优化器中,连接列为索引列的情况下可以考虑选择使用 SMJ。
TiDB Sort Merge Join 实现
执行过程
TiDB 的实现代码在 tidb/executor/merge_join.go 中 MergeJoinExec.NextChunk 是这个算子的入口。下面以 SELECT * FROM A JOIN B ON A.a = B.a 为例,对 SMJ 执行过程进行简述,假设此时外表为 A,内表为 B,join-keys 为 a,A,B 表的 a 列上都有索引:
- 顺序读取外表 A 直到 join-keys 中出现另外的值,把相同 keys 的行放入数组 a1,同样的规则读取内表 B,把相同 keys 的行放入数组 a2。如果外表数据或者内表数据读取结束,退出。
- 从 a1 中读取当前第一行数据,设为 v1。从 a2 中读取当前第一行数据,设为 v2。
-
根据 join-keys 比较 v1,v2,结果分为几种情况:
- cmpResult > 0, 表示 v1 大于 v2,把当前 a2 的数据丢弃,从内表读取下一批数据,读取方法同 1。重复 2。
- cmpResult < 0, 表示 v1 小于 v2,说明外表的 v1 没有内表的值与之相同,把外表数据输出给 resultGenerator(不同的连接类型会有不同的结果输出,例如外连接会把不匹配的外表数据输出)。
- cmpResult == 0, 表示 v1 等于 v2。那么遍历 a1 里面的数据,跟 a2 的数据,输出给 resultGenerator 作一次连接。
- 回到步骤 1。
下面的图展示了 SMJ 的过程:
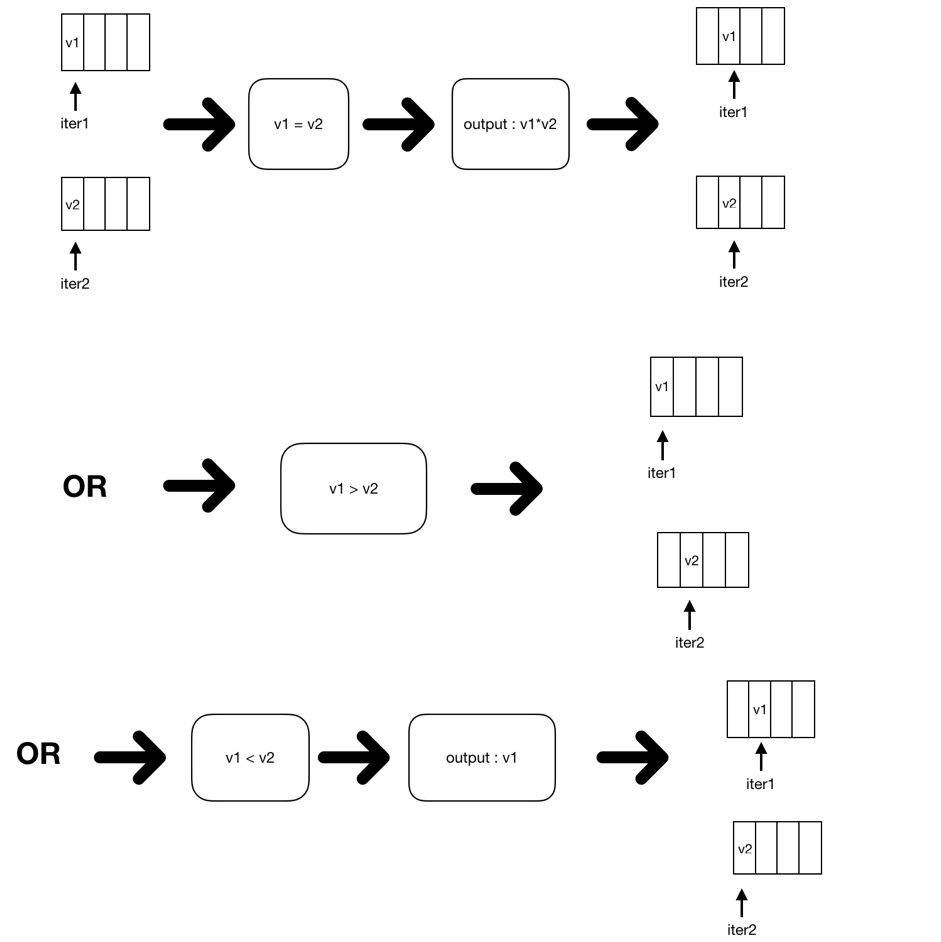
读取内表 / 外表数据
我们分别通过 fetchNextInnerRows 或者 fetchNextOuterRows 读取内表和外表的数据。这两个函数实现的功能类似,这里只详述函数 fetchNextInnerRows 的实现。
MergeSortExec 算子读取数据,是通过迭代器 readerIterator 完成,readerIterator 可以顺序读取数据。MergeSortExec 算子维护两个 readerIterator:outerIter 和 innerIter,它们在 buildMergeJoin 函数中被构造。
真正读取数据的操作是在 readerIterator.nextSelectedRow 中完成, 这里会通过 ri.reader.NextChunk 每次读取一个 Chunk 的数据,关于 Chunk 的相关内容,可以查看我们之前的文章 TiDB 源码阅读系列文章(十)Chunk 和执行框架简介 。
这里值得注意的是,我们通过 expression.VectorizedFilter 对外表数据进行过滤,返回一个 curSelected 布尔数组,用于外表的每一行数据是否是满足 filter 过滤条件。以 select * from t1 left outer join t2 on t1.a=100; 为例, 这里的 filter 是 t1.a=100, 对于没有通过这个过滤条件的行,我们通过 ri.joinResultGenerator.emitToChunk 函数发送给 resultGenerator, 这个 resultGenerator 是一个 interface,具体是否输出这行数据,会由 join 的类型决定,比如外连接则会输出,内连接则会忽略。具体关于 resultGenerator, 可以参考之前的文章:TiDB 源码阅读系列文章(九)Hash Join
rowsWithSameKey 通过 nextSelectedRow 不断读取下一行数据,并通过对每行数据的 join-keys 进行判断是不是属于同一个 join-keys,如果是,会把相同 join-keys 的行分别放入到 innerChunkRows 和 outerIter4Row 数组中。然后对其分别建立迭代器 innerIter4Row 和 outerIter4Row。在 SMJ 中的执行过程中,会利用这两个迭代器来获取数据进行真正的比较得出 join result。
Merge-Join
实现 Merge-Join 逻辑的代码在函数 MergeJoinExec.joinToChunk, 对内外表迭代器的当前数据根据各自的 join-keys 作对比,有如下几个结果:
-
cmpResult > 0,代表外表当前数据大于内表数据,那么通过
fetchNextInnerRows直接读取下一个内表数据,然后重新比较即可。 -
cmpResult < 0,代表外表当前数据小于内表数据,这个时候就分几种情况了,如果是外连接,那么需要输出外表数据 + NULL,如果是内连接,那么这个外表数据就被忽略,对于这个不同逻辑的处理,统一由
e.resultGenerator来控制,我们只需要把外表数据通过e.resultGenerator.emitToChunk调用它即可。然后通过fetchNextOuterRows读取下一个外表数据,重新比较。 -
cmpResult == 0,代表外表当前数据等于内表当前数据,这个时候就把外表数据跟内表当前数据做一次连接,通过
e.resultGenerator.emitToChunk生成结果。之后外表跟内表分别获取下一个数据,重新开始比较。
重复上面的过程,直到外表或者内表数据被遍历完,退出 Merge-Join 的过程。
更多
我们上面的分析代码基于 Source-code 分支,可能大家已经发现了一些问题,比如我们会一次性读取内外表的 Join group(相同的 key)。这里如果相同的 key 比较多,是有内存 OOM 的风险的。针对这个问题,我们在最新的 master 分支做了几个事情来优化:
- 外表其实不需要把相同的 keys 一次性都读取上来, 它只需要按次迭代外表数据,再跟内表逐一对比作连接即可。这里至少可以减少外表发生 OOM 的问题,可以大大减少 OOM 的概率。
-
对于内表,我们对 OOM 也不是没有办法,我们用
memory.Tracker这个内存追踪器来记录当前内表已经使用的中间结果的内存大小,如果它超过我们设置的阈值,我们会采取输出日志或者终止 SQL 继续运行的方法来规避 OOM 的发生。关于memory.Tracker我们不在此展开,可以留意我们后续的源码分析文章。
后续我们还会在 Merge-Join 方面做一些优化, 比如我们可以做多路归并,中间结果存外存等等,敬请期待。
点击查看更多 TiDB 源码阅读系列文章
目录