什么是 Hash Join
Hash Join 的基本定义可以参考维基百科:Hash join。简单来说,A 表和 B 表的 Hash Join 需要我们选择一个 Inner 表来构造哈希表,然后对 Outer 表的每一行数据都去这个哈希表中查找是否有匹配的数据。
我们不用 “小表” 和 “大表” 这两个术语是因为:对于类似 Left Outer Join 这种 Outer Join 来说,如果我们使用 Hash Join,不管 Left 表相对于 Right 表而言是大表还是小表,我们都只能使用 Right 表充当 Inner 表并在之上建哈希表,使用 Left 表来当 Outer 表,也就是我们的驱动表。使用 Inner 和 Outer 更准确,没有迷惑性。在 Build 阶段,对 Inner 表建哈希表,在 Probe 阶段,对由 Outer 表驱动执行 Join 过程。
TiDB Hash Join 实现
TiDB 的 Hash Join 是一个多线程版本的实现,主要任务有:
-
Main Thread,一个,执行下列任务:
-
读取所有的 Inner 表数据;
-
根据 Inner 表数据构造哈希表;
-
启动 Outer Fetcher 和 Join Worker 开始后台工作,生成 Join 结果,各个 goroutine 的启动过程由 fetchOuterAndProbeHashTable 这个函数完成;
-
将 Join Worker 计算出的 Join 结果返回给
NextChunk接口的调用方法。
-
-
Outer Fetcher,一个,负责读取 Outer 表的数据并分发给各个 Join Worker;
-
Join Worker,多个,负责查哈希表、Join 匹配的 Inner 和 Outer 表的数据,并把结果传递给 Main Thread。
接下来我们细致的介绍 Hash Join 的各个阶段。
Main Thread 读 Inner 表数据
读 Inner 表数据的过程由 fetchInnerRows 这个函数完成。这个过程会不断调用 Child 的 NextChunk 接口,把每次函数调用所获取的 Chunk 存储到 innerResult 这个 List 中供接下来的计算使用。
Main Thread 构造哈希表
构造哈希表的过程由 buildHashTableForList 这个函数完成。
我们这里使用的哈希表(存储在变量 hashTable 中)本质上是一个 MVMap。MVMap 的 Key 和 Value 都是 []byte 类型的数据,和普通 map 不同的是,MVMap 允许一个 Key 拥有多个 Value。这个特性对于 Hash Join 来说非常方便和实用,因为表中同一个 Join Key 可能对应多行数据。
构造哈希表的过程中,我们会遍历 Inner 表的每行数据(上文提到,此时所有的数据都已经存储在了 innerResult 中),对每行数据做如下操作:
-
计算该行数据的 Join Key,得到一个
[]byte,它将作为 MVMap 的 Key; -
计算该行数据的位置信息,得到另一个
[]byte,它将作为 MVMap 的 Value; -
将这个
(Key, Value)放入 MVMap 中。
Outer Fetcher
Outer Fetcher 是一个后台 goroutine,他的主要计算逻辑在 fetchOuterChunks 这个函数中。
它会不断的读大表的数据,并将获得的 Outer 表的数据分发给各个 Join Worker。这里多线程之间的资源交互可以用下图表示:
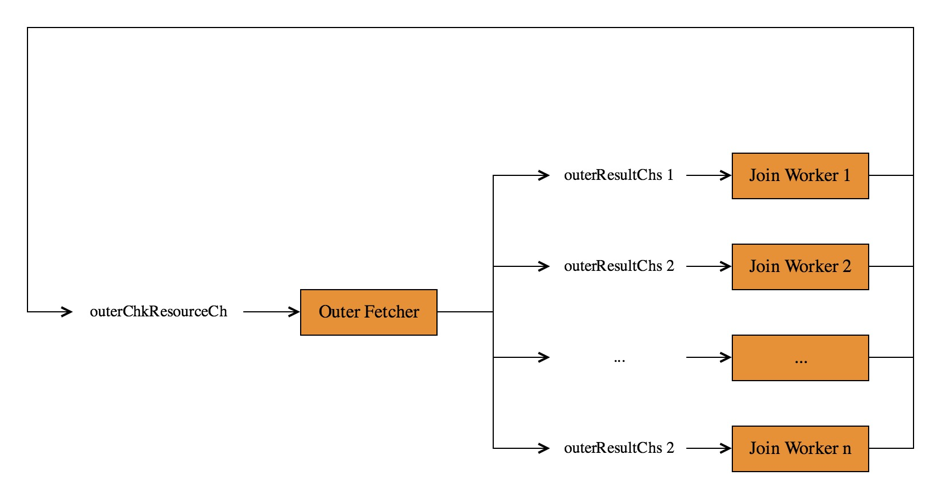
上图中涉及到了两个 channel:
-
outerResultChs[i]:每个 Join Worker 一个,Outer Fetcher 将获取到的 Outer Chunk 写入到这个 channel 中供相应的 Join Worker 使用;
-
outerChkResourceCh:当 Join Worker 用完了当前的 Outer Chunk 后,它需要把这个 Chunk 以及自己对应的 outerResultChs[i] 的地址一起写入到 outerChkResourceCh 这个 channel 中,告诉 Outer Fetcher 两个信息:
-
我提供了一个 Chunk 给你,你直接用这个 Chunk 去拉 Outer 数据吧,不用再重新申请内存了;
-
我的 Outer Chunk 已经用完了,你需要把拉取到的 Outer 数据直接传给我,不要给别人了。
-
所以,整体上 Outer Fetcher 的计算逻辑是:
-
从 outerChkResourceCh 中获取一个 outerChkResource,存储在变量 outerResource 中;
-
从 Child 拉取数据,将数据写入到 outerResource 的 chk 字段中;
-
将这个 chk 发给需要 Outer 表的数据的 Join Worker 的
outerResultChs[i]中去,这个信息记录在了 outerResource 的 dest 字段中。
Join Worker
每个 Join Worker 都是一个后台 goroutine,主要计算逻辑在 runJoinWorker4Chunk 这个函数中。Join Worker 的数量由 tidb_hash_join_concurrency 这个 session 变量来控制,默认是 5 个。
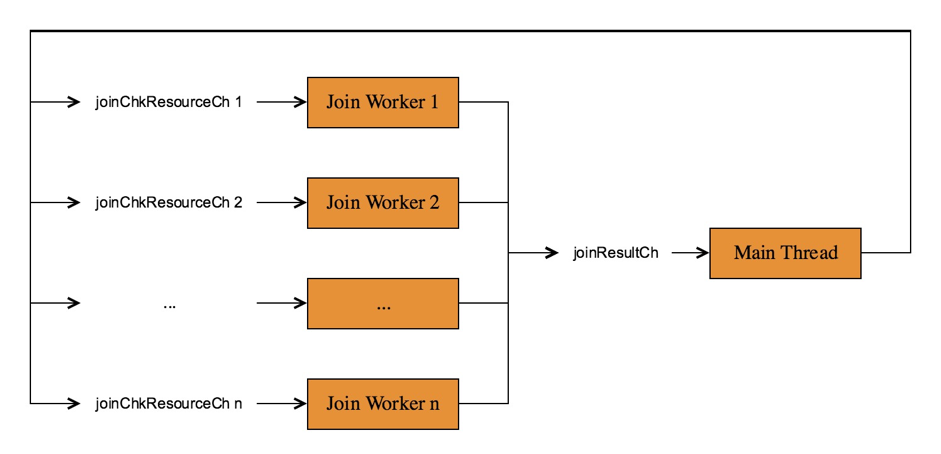
上图中涉及到两个 channel:
-
joinChkResourceCh[i]:每个 Join Worker 一个,用来存 Join 的结果;
-
joinResultCh:Join Worker 将 Join 的结果 Chunk 以及它的 joinChkResourceCh 地址写入到这个 channel 中,告诉 Main Thread 两件事:
-
我计算出了一个 Join 的结果 Chunk 给你,你读到这个数据后可以直接返回给你 Next 函数的调用方;
-
你用完这个 Chunk 后赶紧还给我,不要给别人,我好继续干活。
-
所以,整体上 Join Worker 的计算逻辑是:
-
获取一个 Outer Chunk;
-
获取一个 Join Chunk Resource;
-
查哈希表,将匹配的 Outer Row 和 Inner Rows 写到 Join Chunk 中;
-
将写满了的 Join Chunk 发送给 Main Thread。
Main Thread
主线程的计算逻辑由 NextChunk 这个函数完成。主线程的计算逻辑非常简单:
-
从 joinResultCh 中获取一个 Join Chunk;
-
将调用方传下来的 chk 和 Join Chunk 中的数据交换;
-
把 Join Chunk 还给对应的 Join Worker。
Hash Join FAQ
如何确定 Inner 和 Outer 表?
-
Left Outer Join:左表是 Outer 表,右表是 Inner 表;
-
Right Outer Join:跟 Left Outer Join 相反,右表是 Outer 表,左表是 Inner 表;
-
Inner Join:优化器估算出的较大表是 Outer 表,较小的表是 Inner 表;
-
Semi Join、Anti Semi Join、Left Outer Semi Join 或 Anti Left Outer Semi Join:左表是 Outer 表,右表是 Inner 表。
Join Key 中 NULL 值的问题
NULL 和 NULL 不等,所以:
-
在用 Inner 表建
NULL值的时候会忽略掉 Join Key 中有NULL的数据(代码在 这里); -
当 Outer 表中某行数据的 Join Key 中有
NULL值的时候我们不会去查哈希表(代码在 这里)。
Join 中的 4 种 Filter
-
Inner 表上的 Filter:这种 Filter 目前被优化器推到了 Hash Join Inner 表上面,在 Hash Join 实现的过程中不用考虑这种 Filter 了。推下去的原因是能够尽早的在 coprocessor 上就把不能匹配到的 Inner 表数据给过滤掉,给上层计算减压。
-
Outer 表上的 Filter:这种 Filter 的计算目前在 join2Chunk 中,由 Join Worker 进行。当 Join Worker 拿到一个 Outer Chunk 以后需要先计算 Outer Filter,如果通过了 Outer Filter 再去查哈希表。
-
两个表上的等值条件:这就是我们说的 Join Key。比如 A 表和 B 表的等值条件是:
A.col1=B.col2 and A.col3=B.col4,那么 A 表和 B 表上的 Join Key 分别是(col1, col3)和(col2, col4)。 -
两个表上的非等值条件:这种 Filter 需要在 Join 的结果集上计算,如果能够过这个 Filter 才认为两行数据能够匹配。这个 Filter 的计算过程交给了 joinResultGenerator。
Join 方式的实现
目前 TiDB 支持的 Join 方式有 7 种,我们使用 joinResultGenerator 这个接口来定义两行数据的 Join 方式,实现一种具体的 Join 方式需要特殊的去实现 joinResultGenerator 这个接口,目前有 7 种实现:
-
semiJoinResultGenerator:实现了 Semi Join 的链接方式,当一个 Outer Row 和至少一个 Inner Row 匹配时,输出这个 Outer Row。
-
antiSemiJoinResultGenerator:实现了 Anti Semi Join 的链接方式,当 Outer Row 和所有的 Inner Row 都不能匹配时才输出这个 Outer Row。
-
leftOuterSemiJoinResultGenerator:实现了 Left Outer Semi Join 的链接方式,Join 的结果是 Outer Row + 一个布尔值,如果该 Outer Row 能和至少一个 Inner Row 匹配,则输出该 Outer Row + True,否则输出 Outer Row + False。
-
antiLeftOuterSemiJoinResultGenerator:实现了 Anti Left Outer Semi Join 的链接方式,Join 的结果也是 Outer Row + 一个布尔值,不同的是,如果该 Outer Row 不能和任何 Inner Row 匹配上,则输出 Outer Row + True,否则输出 Outer Row + False。
-
leftOuterJoinResultGenerator:实现了 Left Outer Join 的链接方式,如果 Outer Row 不能和任何 Inner Row 匹配,则输出 Outer Row + NULL 填充的 Inner Row,否则输出每个匹配的 Outer Row + Inner Row。
-
rightOuterJoinResultGenerator:实现了 Right Outer Join 的链接方式,如果 Outer Row 不能和 Inner Row 匹配,则输出 NULL 填充的 Inner Row + Outer Row,否则输出每个匹配的 Inner Row + Outer Row。
-
innerJoinResultGenerator:实现了 Inner Join 的链接方式,如果 Outer Row 不能和 Inner Row 匹配,不输出任何数据,否则根据 Outer Row 是左表还是右表选择性的输出每个匹配的 Inner Row + Outer Row 或者 Outer Row + Inner Row。
点击查看更多 TiDB 源码阅读系列文章
目录