
导读
多点DMALL 是一站式全渠道数字零售解决方案服务商,提供端到端的商业 SaaS 解决方案。多点DMALL 通过 Dmall OS 提供零售联合云一站式解决方案,帮助零售商和品牌商数字化转型,实现线上线下一体化;同时通过多点 App 等工具赋能全渠道经营能力,并提供各类增值服务。
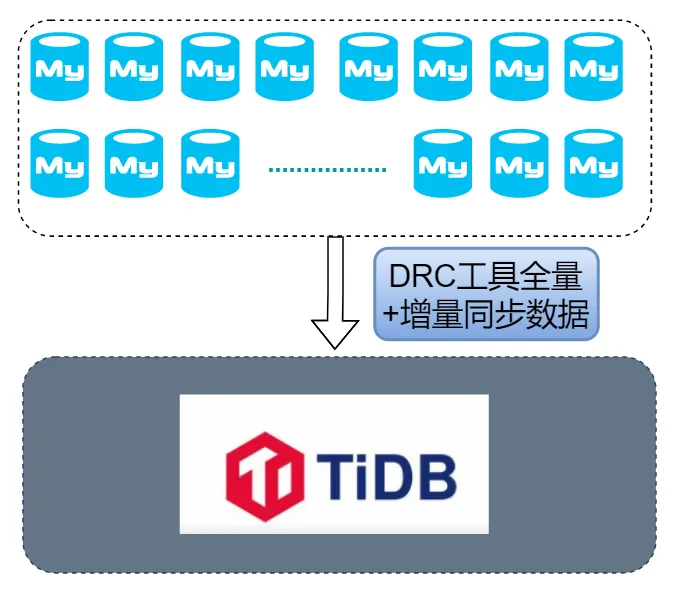
随着业务的蓬勃发展,面对多库数据管理的复杂性,多点 DMALL 将 100 多套 MySQL 实例合并为一套 TiDB 集群。本文将探讨这一转型背后的策略,包括合并策略、迁移实施、版本升级等,并详细介绍了合并后如何利用 TiDB 的资源管控功能对有压力库进行资源隔离,实现成本效率的双重提升。
背景
多点DMALL 作为一家提供一站式全渠道数字零售解决方案的服务商,随着业务的增长和全球化步伐的加快,目前正在积极推进零售 SaaS 私有化项目,旨在实现系统运行的高效和简化。
SaaS 业务的特点在于它基于云计算、无需本地安装、由服务提供商进行托管和管理,并且采用订阅制模式。此外,SaaS 业务需要频繁调整业务逻辑,并对业务连续性有极高的要求。对于数据库而言,这就意味着需要具备可扩展性、多租户管理、方便运维、高可靠性和高可用性、高性能、数据安全合规、成本效益、在线 DDL 能力、资源隔离和管控以及支持 HTAP 等特性。
TiDB 数据库以其在线 DDL 操作、细粒度资源控制和多租户支持等优势,能够有效满足这些需求,当前已经在多点DMALL 业务系统中大规模应用。
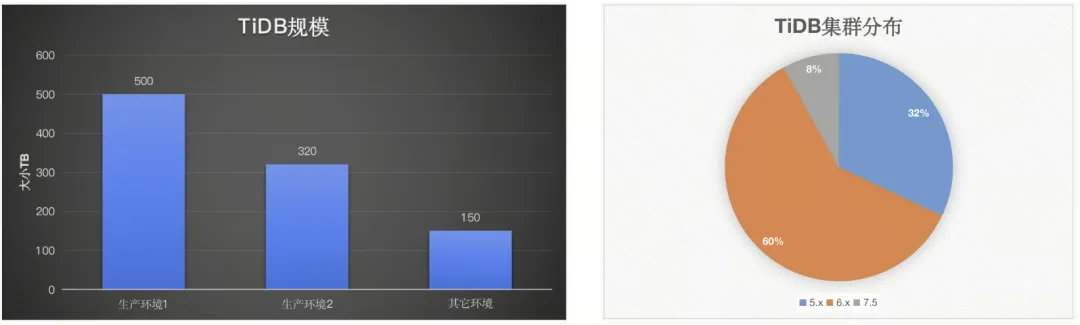
在本次系统改造中,我们计划通过整合应用和数据库来降低系统复杂性,并减少硬件成本与运维管理开支。在前期改造过程中,我们已经将 Docker 应用实例从 300 个减少至 150 个,并将数据库集群数量从 200 个精简至 100 个。目前,我们主要采用 MySQL 作为数据库技术,其中最大的生产环境拥有上千个 MySQL 集群。
鉴于 TiDB 在处理大量数据合并时,相较于传统的 MySQL 到 MySQL 合并,展现出更高的效率和灵活性,并且能够通过其资源管控特性,在有限的系统资源下保障业务的平稳运行,我们决定利用现有的 TiDB 集群,借助其动态扩缩容和高效压缩存储的能力,进一步优化数据库合并流程。目标是将现有的多个 MySQL 集群合并为一个 TiDB 集群。
我们的合并策略包括将源端 MySQL 中的库表数据完全迁移到目标 TiDB 集群中,并通过更新配置中心和重启业务应用来完成数据迁移和系统切换。本次迁移合并的步骤涵盖了迁移实施、数据一致性验证、资源隔离和性能压测等环节。在本文中,我们将重点介绍合并过程中的注意事项,并探讨如何通过灵活运用 TiDB 7 版本发布的资源管控特性来提升成本效率。
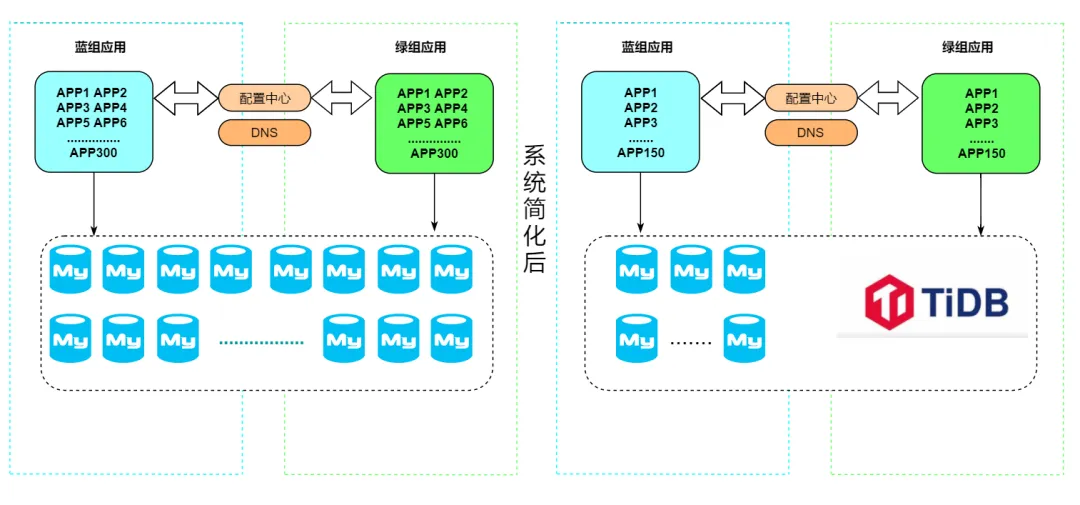
迁移实施
MySQL 合库到 TiDB 前提条件
二八原则在每个行业都是适用的:80% 的业务高 QPS 流量是由 20% 的数据库产生的。某私有化项目生产环境有 170 个 MySQL v8.0 集群, QPS 高的约有 30 个,大部分 MySQL 属于 QPS 较低的长尾部分,我们计划是将 QPS 较低的 MySQL 集群全部合并至一套 TiDB。
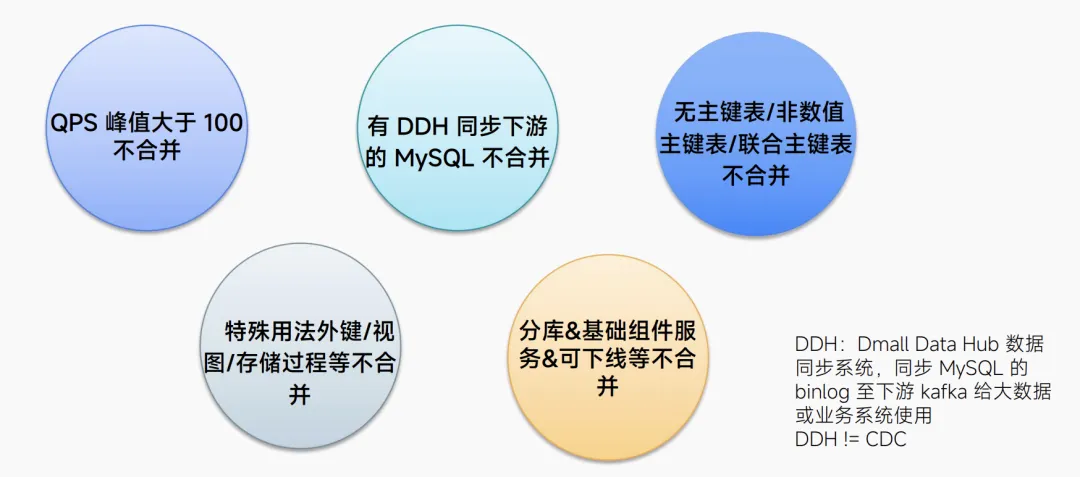
经过内部讨论,受限于本次改造的硬件资源,避免下游大数据或业务系统改造适配 kafka 新格式的成本风险,以及尽量减少对业务的影响,我们划定了参与到本次合库的集群的选取原则:含有 QPS 较高的业务的集群、应用了多点自研的 Dmall Data Hub 数据同步系统(简称 DDH)的 MySQL 集群;无主键表/非数值主键表/联合主键表的表、有特殊用法外键/视图/存储过程等的表、有分库、未接入配置中心、可下线的集群不合并。
此次调整涉及到 104 个一主一从的 MySQL 集群(75 个合并至 TiDB ,29 个下线)共可释放资源 212G 内存,1.1T 磁盘
合库目标 TiDB 版本升级至 7.5
多点已有一套老版本 v5.4 TiDB 集群,目前已经负载着一些业务。我们计划将这套 TiDB 升级至 v7.5 版本(官方长期支持 LTS)。一是连接协议兼容 MySQL v8.0(@@version 8.0.11- TiDB -v7.5.0 我们源要合并的都是 MySQL v8.0,目标是让业务方不做任何改动把 MySQL 合并至 TiDB),二是 v7.x 版本推出了一些新特性,如 RU 资源管控、TTL 自动清理无用数据,性能提升等。
升级前我们已经在测试环境中进行了充分的验证,并进行了备份兜底。本次我们通过 tiup 进行升级,过程相对顺利,升级前后读写延迟有降低 40-50% 左右,性能提升明显。
升级前
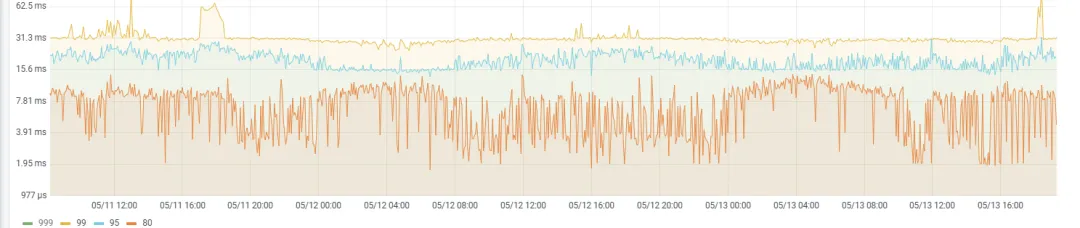
升级后

TiDB 计算节点新扩容两台
我们现有的 TiDB 集群,在配置较低的情况下,已经成功支撑了多个只读业务的平稳运行,实现了从 MySQL 到 TiDB 的无缝迁移。该集群由 3 台 2 核 8GB 的计算节点和 3 台 4 核 32GB 的高性能存储节点组成,确保了数据处理的高效性。
为了进一步提升性能并满足日益增长的业务需求,我们在现有的 MySQL 服务器上扩展了 2 个计算节点。这一策略不仅利用了 MySQL 服务器上未充分利用的内存资源,还通过分散新增计算节点的负载,有效减轻了写入操作的延迟,特别是在处理高并发数据库操作时。
通过这种优化,我们不仅提升了集群的计算能力,还通过智能分配资源,确保了数据同步和合库操作的流畅性,为业务的持续增长和稳定性提供了坚实的基础。
同步过程中的参数配置
启用该参数后 TiDB 主键自增列行为才和 MySQL 单调顺序递增一致。
- 中心化自增 ID 分配,auto_increment MySQL 兼容模式
- 确保多个 TiDB 计算节点生成的自增列是单调递增( MySQL 中可能有依赖主键 id 做分页排序用法 select xxx from t order by id where id>? limit n),v6.4.0 版本之前存在自增 id 不连续问题
- 不支持在已有表增加 auto_id_cache,只能新建表设置
- 生产环境保险起见,需手动导出 MySQL 表结构加上 auto_id_cache 后再导入表结构到目标 TiDB
#v6.4.0 之前
SELECT * FROM t ORDER BY b;
+---------+---------------------+
| a | b |
+---------+---------------------+
| 1 | 2020-09-09 20:38:22 |
| 2 | 2020-09-09 20:38:22 |
| 3 | 2020-09-09 20:38:22 |
| 2000001 | 2020-09-09 20:43:43 |
| 4 | 2020-09-09 20:44:43 |
| 2030001 | 2020-09-09 20:54:11 |
+---------+---------------------+
6 rows in set (0.00 sec)
#v6.4.0 以后支持
CREATE TABLE t(a int AUTO_INCREMENT key) AUTO_ID_CACHE 1;
#已有表增加 auto_id_cache 报错
[错误]: (1105, "Can't Alter AUTO_ID_CACHE between 1 and non-1, the underlying implementation is different"sql_mode

TiDB sql_mode 修改为和 MySQL 一致,避免对业务应用产生不可预期的错误,如:
ERROR 1067 (42000): Invalid default value for 'update_time'对 TiDB 有压力库进行资源隔离
TiDB 资源管控特性提供了两层资源管理能力,包括在 TiDB 层的流控能力和 TiKV 层的优先级调度的能力。两个能力可以单独或者同时开启,TiDB 提供用户、会话级、语句级别设置资源组,可将压力大的应用绑定到某个资源组后,TiDB 层会根据用户所绑定资源组设定的配额对用户的读写请求做流控,TiKV 层会根据配额映射的优先级来对请求做调度。通过流控和调度这两层控制,可以实现应用的资源隔离,满足服务质量 (QoS) 要求。
TiDB 资源隔离不是分配 IO CPU 具体多少,而是通过配置 RU(Request Unit,是 TiDB 对 CPU、IO 等系统资源的统一抽象的计量单位,读写请求消耗不同的 RU)来实现。
配置规则
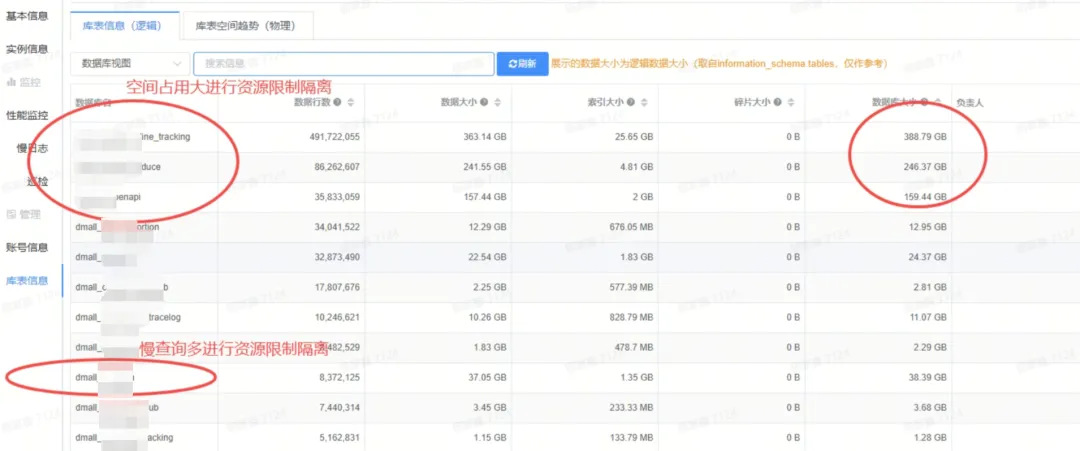
- 本次合并一共涉及 85 个数据库,其中 3 个大库超过 100GB(大库有大 DML、SQL 查询会消耗大量硬件资资源,引起整个 TiDB 集群雪崩),1 个库存在慢查询多的情况,针对这 4 个数据库我们进行了 RU 的配置;其它 81 个业务资源使用量低,没有开启资源管控能力。
- TiDB 集群通过硬件配置预估可用 RU 2.7 万个,按 70%安全资源利用算(用最大额 RU 的话服务器压力会很大),可使用 RU 约 2 万个,分配 70% 的 RU 给 4 个大库(约 1.4 万,当前 TiDB 集群 IO、CPU 已达到了 70%~80%,因此分别对 4 个大压力库配置 RU 避免引起雪崩)。
- RU 形式隔离对大业务慢查询相对暴力些,RU 用完后 SQL 会报错,而不单纯是执行变慢,需要谨慎地评估和设置 RU。
- 当前 7.5 GA 功能下,是超过分配 RU 会预估等待一定时间,预估时间较长还没有执行就报错。这个时间是动态可调的,默认 30s,可以调整 ltb-max-wait-duration 控制。
Runaway Queries 可以避免报错问题,但是 7.5 是实验特性,因此需要等升级 8.x 版本解决。
#给不同资源组分配不同RU
CREATE RESOURCE GROUP IF NOT EXISTS xxxx1 RU_PER_SEC = 3000 PRIORITY = MEDIUM;
CREATE RESOURCE GROUP IF NOT EXISTS xxxx2 RU_PER_SEC = 3000 PRIORITY = MEDIUM;
CREATE RESOURCE GROUP IF NOT EXISTS xxxx3 RU_PER_SEC = 3000 PRIORITY = MEDIUM;
CREATE RESOURCE GROUP IF NOT EXISTS xxxx4 RU_PER_SEC = 5000 PRIORITY = MEDIUM;
#通过账号名给不同库(一个库一个账号名)绑定资源组
ALTER USER dmall_xxx@'xx.xx.%.%' RESOURCE GROUP xxxx1;
ALTER USER dmall_xxx@'xx.xx.%.%' RESOURCE GROUP xxxx2 ;
ALTER USER dmall_xxx@'xx.xx.%.%' RESOURCE GROUP xxxx3 ;
ALTER USER dmall_xxx@'xx.xx.%.%' RESOURCE GROUP xxxx4 ; #写入量大的库账号设置5000RU如图所示,针对空间占用大、慢查询多的两类数据库进行资源隔离限制,保障资源充足。
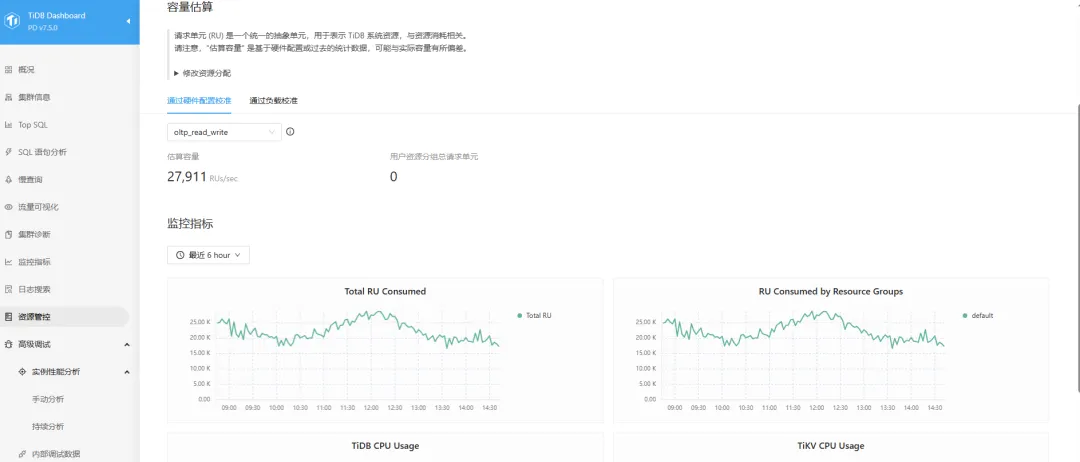
效果验证
通过 TiDB 提供的 Dashboard 面板可以看到 TiDB 对 RU 的容量估算情况以及用户分配使用情况,监控粒度以及评估实现可视化。
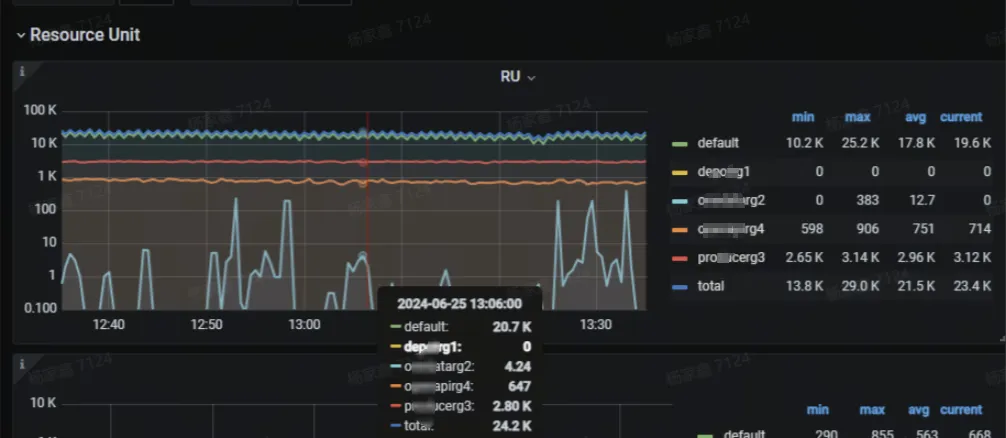
配置 RU 后,在 Grafana 的监控面板中可以看到不同资源组 RU 消耗使用情况
Grafana 中 TiDB -Resource-Control 面板可以检测到 RU 更详细监控数据,包括 RU、Query、RRU 和 WRU 等监控。
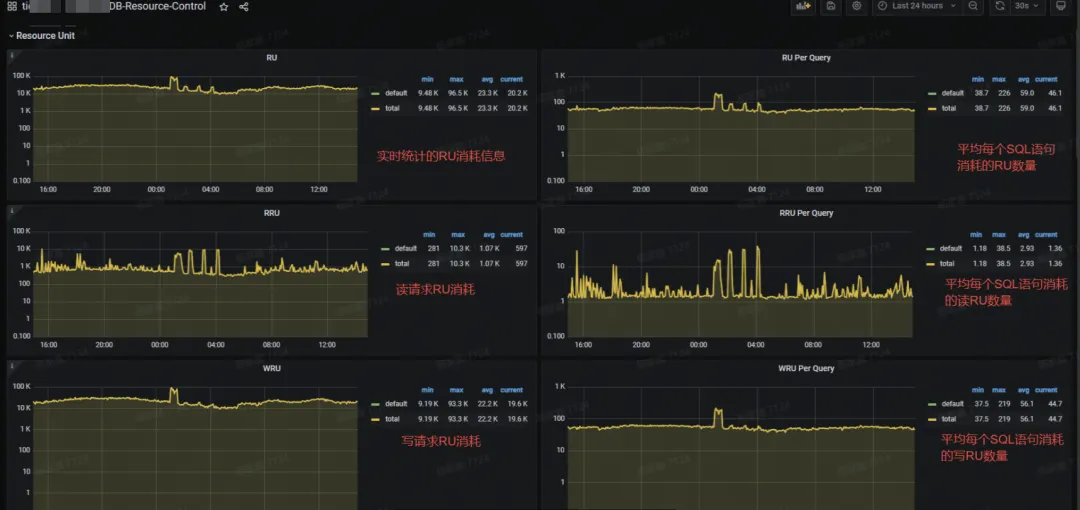
注意事项
值得注意的是,RU 分配不合理情况下,可能因 RU 资源不足,导致业务 SQL 查询报错的情况,需要调整 RU 分配情况。

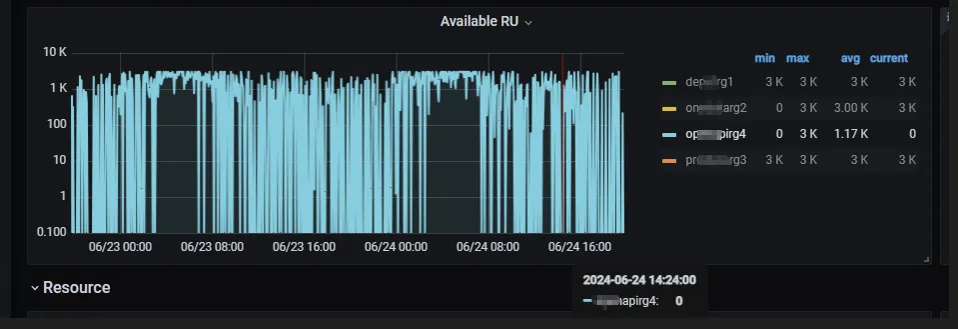
在 Grafana 的 RU 监控面板中,Available RU 监控数据显示有为 0 情况,实际业务写入数据正常,可能监控数据采集有点异常(已知问题:这个监控和 RU_PER_SEC 这个流速的概念是不对等的,这里显示的只是令牌桶瞬时的一个状态,后面会去掉)。
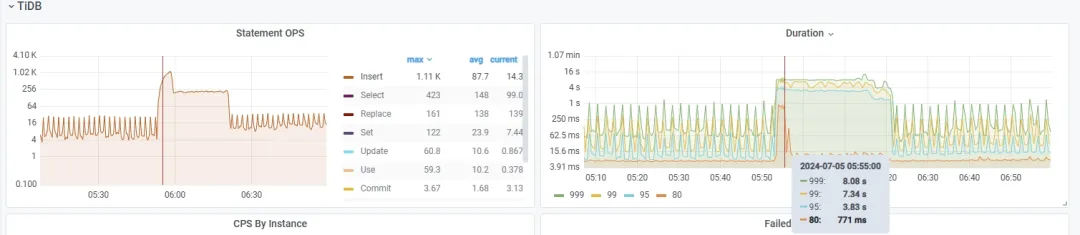
全链路压测
虽然 MySQL 合库至 TiDB 已经在测试环境跑过一段时间,但测试环境无法模拟真实生产环境,有些应用没使用或业务流量 QPS 都很小,仅对兼容性进行了验证。
本次私有化项目的上线临近大促活动前,在 MySQL 合并到 TiDB 落地生产合库上线后,我们进行了一次非常有意义的全链路压测,业务测试人员模拟发起前端请求高并发 QPS(3k+),经过应用层,压力传导到后端数据库 MySQL、TiDB 、MongoDB、Redis,来验证技术架构方案面对高并发场景的支撑能力。
扩容前
平峰期 3 台 2C 8G pd, TiDB 计算+3 台 4C 32G 高性能存储能够平稳运行,但是支撑不了压测的高峰流量,并发一上来写入 TiDB 延迟时间飙升(P99 到了 7s 多,tikv cpu 压力最高 70% 左右,IO 压力 75% 左右)
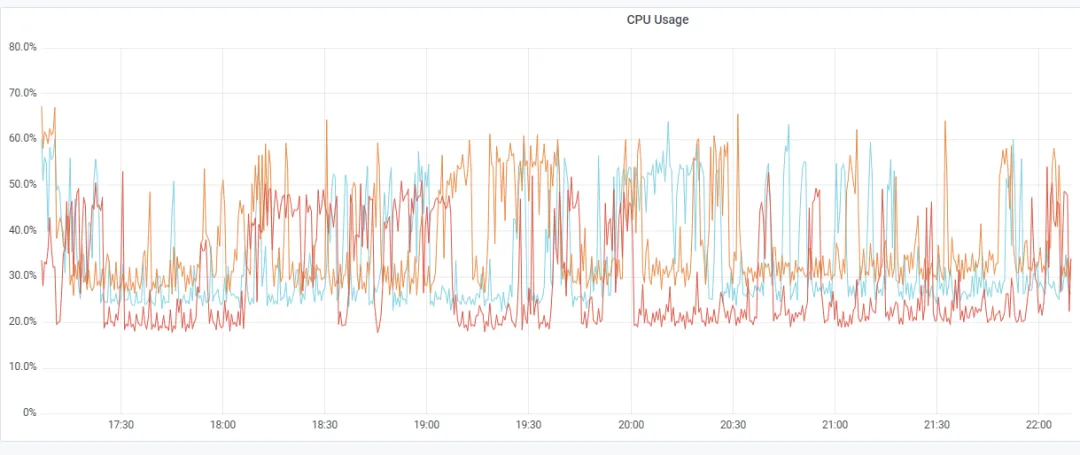
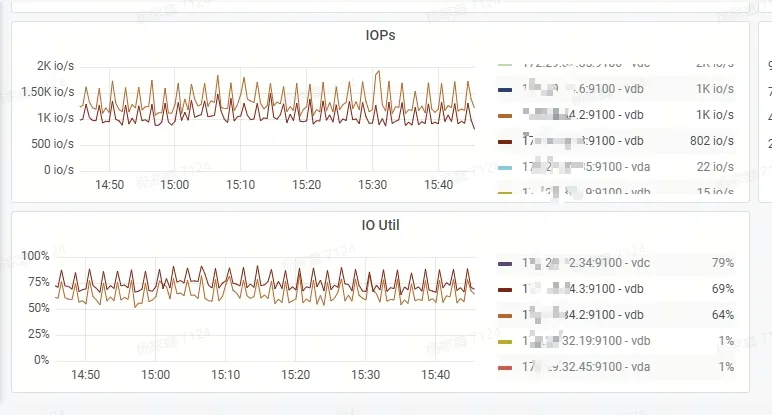
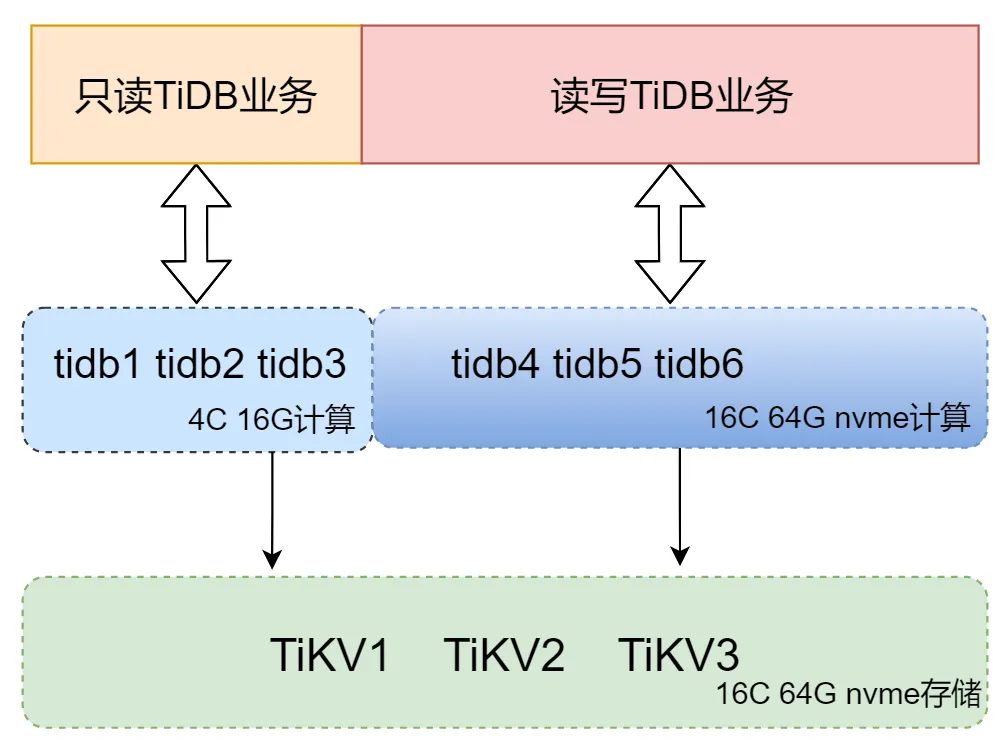
因此,我们进行了一次扩容:
- 3 台低配计算 2Core 8GB 升级至 4Core 16GB 服务器( MySQL -> TiDB 只读业务库使用计算节点)
- 3 台低配存储 4Core 32GB 升级至高配 16Core 64GB nvme 3.7TB 本地盘服务器
- 高配 16Core 64GB nvme 本地盘服务器上新扩容 3 台计算节点给直接读写 TiDB 业务使用(主要用计算资源, MySQL 合库至 TiDB )
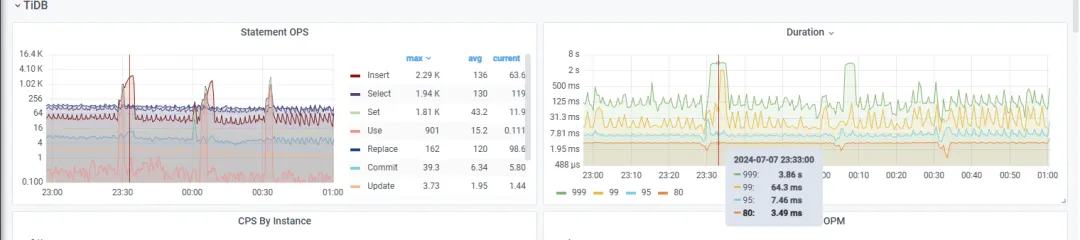
扩容后
3 台 16C 64G nvme 本地盘计算+存储扩容好后,并发压测上来, TiDB 延迟的表现明显比之前提升非常大(P99 64ms,P999 稍微高些 3s 多,tikv cpu 压力最高 30% 左右,IO 压力低),
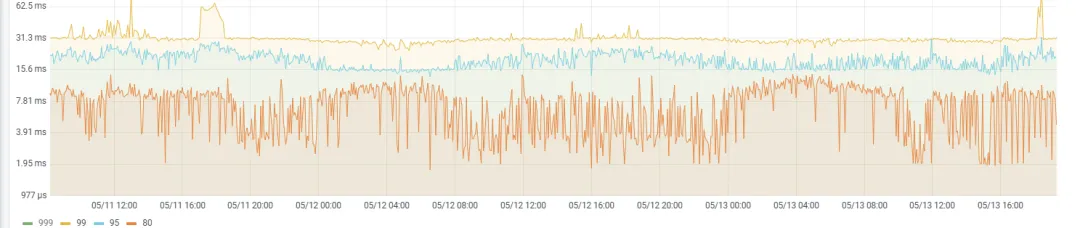
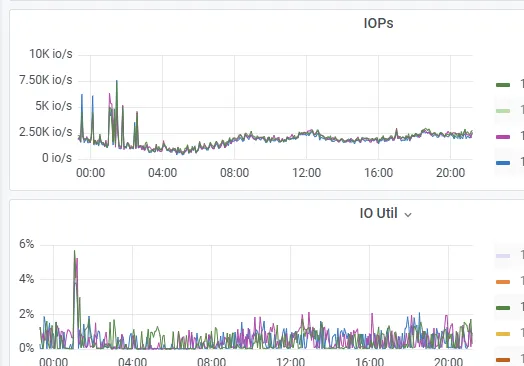
大多数业务压测通过,部分有活动任务的业务并发更新数值还是没有达到响应时间毫秒级别的标准,回滚到了 MySQL 集群中。
整体收益
完成此次迁移后,获得了以下收益:
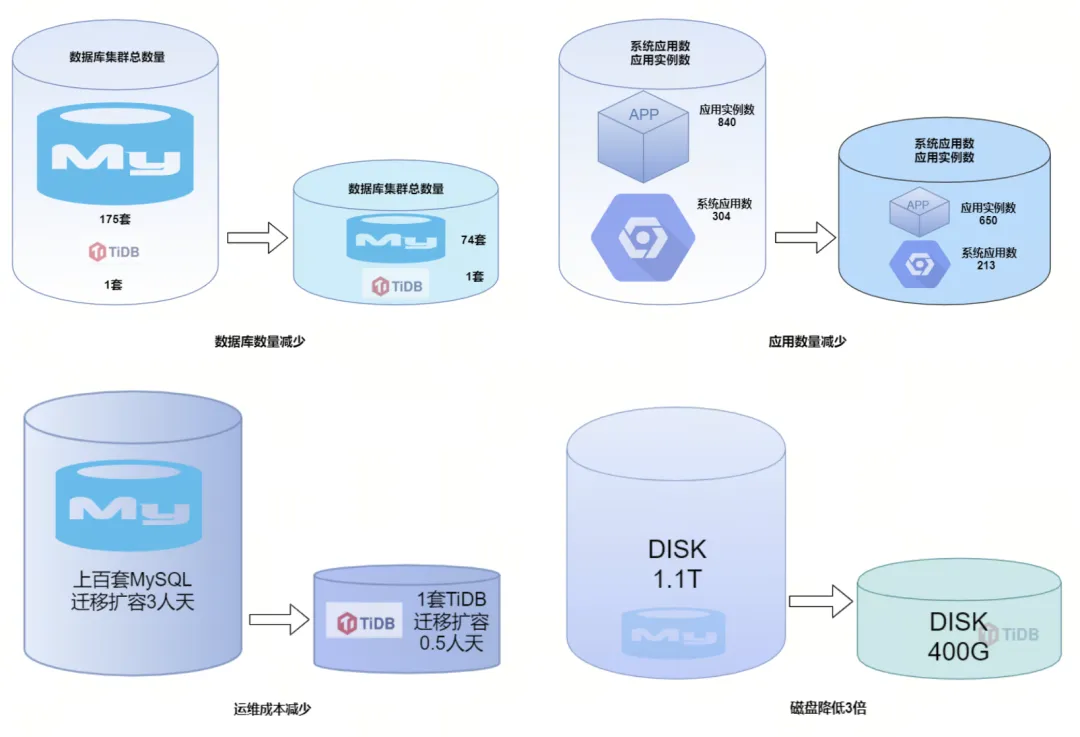
- 简化系统架构:将 100+套 MySQL 实例合并至 1 套 TiDB,简化了整体系统架构,降低了系统的复杂性,使得运维工作更为集中和高效;开发团队可以在统一的数据库平台上工作,减少了需要熟悉多种数据库系统的成本,提高了开发效率;
- 降低硬件成本:由于 TiDB 的高性能和良好的资源使用效率,可以用更少的硬件资源支撑相同的业务负载,减少了服务器的采购和运行成本;TiDB 的计算和存储分离架构允许更灵活的资源分配,可以在业务高峰期间快速扩展资源,低峰期间缩减资源,从而提高资源的利用率;TiDB 相比 MySQL 5 倍左右压缩率, 在 MySQL 一主一从两副本, TiDB 三副本的情况下存储成本降低了到了原来的 1/3;虽然 TiDB 的备份空间占用可能较大,但通过优化备份策略和忽略冗余数据,可以减少备份所需的存储空间,同时提升备份和恢复的效率;
- 提升运维效率:在实例数量减少的同时,TiDB 提供了更为自动化的管理工具和流程。整体的运维成本降低了 90%;使用 TiDB 后,可以通过统一的监控和管理界面来观察整个数据库集群的状态,简化了监控系统的部署和维护工作;TiDB 的动态扩缩容特性使得资源管理更加高效,TiDB 从迁移扩容的 3 人天降至仅需 0.5 人天,整体提高了 6 倍;
- 增强数据安全性:TiDB 提供了多副本和自动故障转移机制,增强了数据的安全性和可靠性,减少了因数据丢失或损坏导致的运维成本;通过资源隔离和动态扩缩容, TiDB 可以更好地应对业务流量波动,减少因资源不足导致的业务中断风险。
目录