
在数字化系统扮演重要角色的今天,数据库稳定性成为企业关注的核心问题。对于重要计算机系统而言,突发的性能下降可能对业务造成不可估量的损失。为了稳定数据库性能,用户可以从管理流程入手规范变更的测试,或者利用产品手段减少预期外的变化。然而,这仍旧无法完全规避突发的 SQL 性能问题,其中的原因包括但不仅限于:
- 数据量和数据分布剧烈变化,从前被验证过的执行计划可能变得效率更低。
- 数据库中的查询变得越来越复杂,优化器对执行计划的选择存在不可控因素。
- 频繁的业务更新给测试带来巨大压力,未经充分验证的 SQL 有潜在的性能问题。
对于一些对延迟非常敏感的应用而言,这些潜在问题有可能对业务造成不可估量的损失。如何降低这类不可控的突发问题对业务的影响,是摆在每个管理者面前的难题。
作为资源管控的一部分,TiDB 在 7.2.0 引入 Runaway Queries 管理,并持续增强,旨在通过系统化的手段缓解上述难题。
本文将从从适用场景、实现原理等角度详细介绍 TiDB 的 Runaway Queries 管理功能,并通过一个示例展示其在系统中的作用。
什么是 Runaway Queries
Runaway Queries 是指执行时间或消耗资源超出预期的查询,在运行时间和资源消耗上有显著特征。
Runaway Queries 管理旨在提供一种高效、可控、自动化的资源识别和管控机制,以降低突发 SQL 性能问题带来的负面影响,保护复杂工作负载下系统的稳定性,让 TiDB 更加可靠。
Runaway Queries 管理适用哪些场景
- 为了保障重要系统的服务质量,需要能够自动识别并处理异常 SQL 性能问题。
- 当遇到突发 SQL 性能问题,但又没有立即有效的修复手段时,希望临时缓解其影响。
- 当已知个别 SQL 有安全或性能问题,希望加入黑名单或对其进行限流。
Runaway Queries 管理能做什么
Runaway Queries 管理主要提供两个重要能力,即对查询的“识别”和“处置”。
查询的识别
TiDB 资源管控模块提供两类识别方式
动态识别 - 根据运行时规则识别。指根据 SQL 实际运行指标自动识别 (通过 resource group 定义),目前支持利用EXEC_ELAPSED 设置实际执行时间,即当查询运行时间超过EXEC_ELAPSED 的定义时,这个查询会被识别为 Runaway Query。比如:
ALTER RESOURCE GROUP default QUERY_LIMIT=(EXEC_ELAPSED='5s', ACTION=KILL);- 上面命令执行的效果是, 属于
default资源组的查询运行超过 5 秒钟,那么这个查询会被识别为 Runaway Query。(识别规则的生效范围为“资源组”,如果你没有创建任何资源组,那么可以修改default资源组的规则将会对全局有效。) - TiDB 特意提供了每个资源组
Query Max Duration的监控指标,能够查看一段时间内运行时间最长的查询,这个指标能够协助设置一个合理的EXEC_ELAPSED.
Resource Group 的定义同时支持将识别到的 SQL 特征同时加入监控列表特定一段时间,即一段时间内,资源管控直接识别 SQL 特征而无需用规则识别。相当于将 SQL 放入监控名单,并阶段性检查是否它已经恢复健康。
ALTER RESOURCE GROUP default QUERY_LIMIT=(EXEC_ELAPSED='5s', ACTION=KILL, WATCH=SIMILAR DURATION='10m');- 上述例子里,我们向配置里加入了
WATCH规则, 那么和被识别成 Runaway Query 查询类似的查询(比如只有过滤值不同),在接下来的 10 分钟里,会直接执行对应操作,而不会再等待 5 秒。10 分钟之后,如果这个查询的性能已经恢复,则不再对其进行限制;如果没有恢复,则再次对这个查询监控 10 分钟。
静态识别 - 根据 SQL 特征识别。自动筛选规则并不能精确的识别出所有有问题的查询,因此我们加入了对监控列表的人工管理。通过 query watch 命令定义 SQL 特征识别及处置规则, 能够达到数据库查询黑名单的作用。目前已支持的 SQL 特征的设置:
SQL Text: 根据 SQL 文本做精确匹配。SQL Digest: 根据 SQL Digest 匹配模式相同的查询。比如 select c from t1 where a=1 和 select c from t1 where a=2 拥有相同的 Digest。Plan Digest: 根据 Plan Digest 匹配执行计划相同的查询。相同 SQL 可能存在多个执行计划,造成性能问题的往往是其中少部分执行计划。
SQL 特征可以通过“慢查询”等方式采集,这里是一个“慢查询”示例
SELECT count(1) FROM sbtest.sbtest1 AS S1 ,sbtest.sbtest2 AS S2 ,sbtest.sbtest3 AS S3 WHERE S1.c=S2.c AND S1.c=S3.c;
# Time: 2023-09-19T17:16:56.640436+08:00
...
# Digest: d3c7846bb8f6b817ae395db30eadedec57af08f7983466f68db93d9ce1ac5872
...
# Plan_digest: 41fee801f07e06aa4aba4c0142ce4c624e8dc932c9e14d49854b8ce57366b443用户可以根据经验选择其中一种识别方式,比如下面例子里用 SQL DIGEST 子句将类似的查询加入监控队列, 那么和此查询类似的查询会被识别并做出对应的处置。
mysql> QUERY WATCH ADD ACTION KILL SQL DIGEST 'd3c7846bb8f6b817ae395db30eadedec57af08f7983466f68db93d9ce1ac5872';
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT * FROM INFORMATION_SCHEMA.RUNAWAY_WATCHES ORDER BY id\G
*************************** 1. row ***************************
ID: 54
RESOURCE_GROUP_NAME: default
START_TIME: 2023-09-20 01:59:14
END_TIME: UNLIMITED
WATCH: Similar
WATCH_TEXT: d3c7846bb8f6b817ae395db30eadedec57af08f7983466f68db93d9ce1ac5872
SOURCE: manual
ACTION: Kill
1 row in set (0.04 sec)查询的处置
处置,指被识别到的 Runaway Queries 要如何处理。目前支持以下几个处理方式。
DRYRUN:仅识别不做处理,在日志和对应视图中显示。初期配置的时候,可以利用 DRYRUN试运行一段时间,检测是否有误判的风险。COOLDOWN:将查询置于资源组的最低优先级,限制其处理速度。KILL:终止被识别的查询,防止其进一步影响数据库性能。- 在 7.5.0 版本,
COOLDOWN在复杂场景下的限制作用有限,如果对服务质量要求比较高,则推荐设置KILL
- 在 7.5.0 版本,
在这个例子里,被识别为 Runaway Queries 的查询会被自动取消。
ALTER RESOURCE GROUP default QUERY_LIMIT=(EXEC_ELAPSED='5s', ACTION=KILL, WATCH=SIMILAR DURATION='10m');历史记录及观测性
以上所有的设置,及识别和处置的历史记录,TiDB 提供了一组系统表用于查询:
INFORMATION_SCHEMA.RESOURCE_GROUPS:资源组定义,包括对 Runaway Queries 识别规则和处置设置。INFORMATION_SCHEMA.RUNAWAY_WATCHES:监控队列中的规则。MYSQL.TIDB_RUNAWAY_QUERIES:记录被识别和处置的 Runaway Queries 历史记录。
运行示例
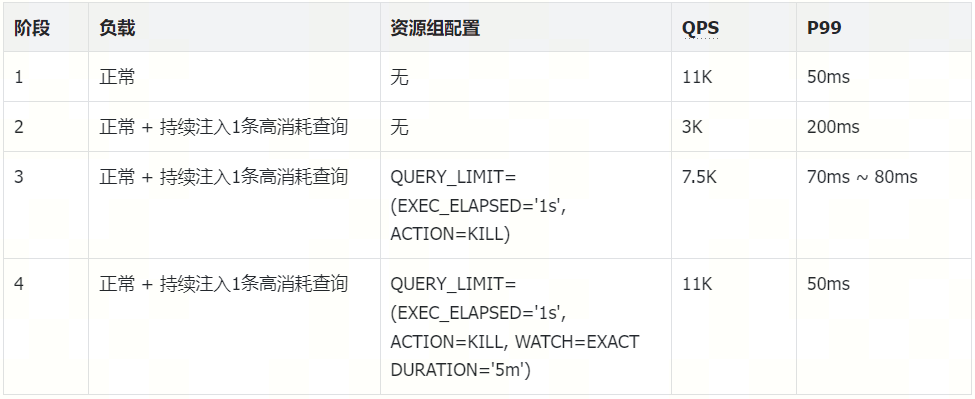
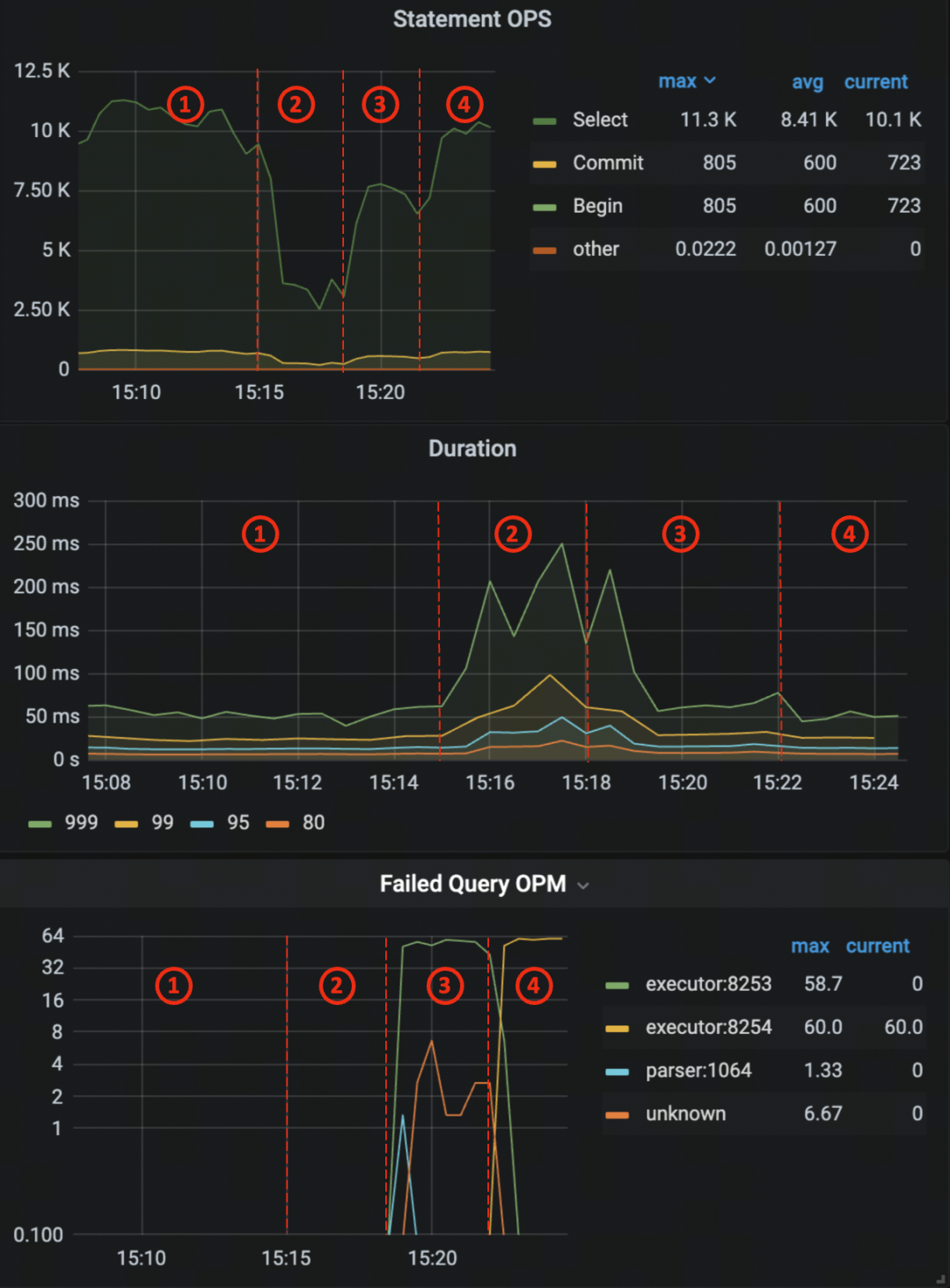
- 正常负载下, 整体 QPS 接近
11k, P999 在50ms上下。 - 出现一个异常查询,每秒提交一次,运行时间在 3~8 秒, QPS 从
11k急剧下降至3k左右,P999 由60ms增加到200ms。 - 这时我们尝试向
default资源组加入一条规则,自动杀掉运行时间超过 1 秒的查询。QPS 回升至7.5k, P999 下降。
mysql> alter resource group default QUERY_LIMIT=(EXEC_ELAPSED='1s', ACTION=KILL);
Query OK, 0 rows affected (1.02 sec)
mysql> SELECT * FROM information_schema.resource_groups;
+---------+------------+----------+-----------+--------------------------------+------------+
| NAME | RU_PER_SEC | PRIORITY | BURSTABLE | QUERY_LIMIT | BACKGROUND |
+---------+------------+----------+-----------+--------------------------------+------------+
| default | UNLIMITED | MEDIUM | YES | EXEC_ELAPSED='1s', ACTION=KILL | NULL |
+---------+------------+----------+-----------+--------------------------------+------------+
1 row in set (0.01 sec)通过系统表 mysql.tidb_runaway_queries,我们看到 Runaway 管理开始介入,有问题的 SQL 被持续标记并处理。
mysql> select * from mysql.tidb_runaway_queries limit 1 \G
*************************** 1. row ***************************
resource_group_name: default
time: 2023-09-19 15:18:10
match_type: identify
action: kill
original_sql: SELECT count(1)
FROM sbtest.sbtest1 AS S1
,sbtest.sbtest2 AS S2
,sbtest.sbtest3 AS S3
WHERE S1.c=S2.c
AND S1.c=S3.c
plan_digest: 41fee801f07e06aa4aba4c0142ce4c624e8dc932c9e14d49854b8ce57366b443
tidb_server: 127.0.0.1:4000
mysql> select count(*) from mysql.tidb_runaway_queries;
+----------+
| count(*) |
+----------+
| 56 |
+----------+
1 row in set (0.02 sec)这里 QPS 仍没有回升至原先的水平, 因为虽然会把运行超过 1 秒的查询杀掉,但每个查询仍旧都会运行 1 秒,对系统仍旧造成消耗。
- 修改资源组规则,把符合 runaway 规则的查询的文本,加入到监控列表中,时长为 5 分钟。这意味着,如果文本匹配到被标记为 runaway 的查询,那么会被直接杀掉,不再等待 1 秒;而每隔 5 分钟,TiDB 会自动放开限制,检查一下查询的性能是否恢复。如果恢复,则不再对此查询进行取消处理。这时系统的 QPS 和 P999 恢复到阶段 1 的水平。
mysql> alter resource group default QUERY_LIMIT=(EXEC_ELAPSED='1s', ACTION=KILL, WATCH=EXACT DURATION='5m');
Query OK, 0 rows affected (0.53 sec)
mysql> SELECT * FROM information_schema.resource_groups;
+---------+------------+----------+-----------+-------------------------------------------------------------+------------+
| NAME | RU_PER_SEC | PRIORITY | BURSTABLE | QUERY_LIMIT | BACKGROUND |
+---------+------------+----------+-----------+-------------------------------------------------------------+------------+
| default | UNLIMITED | MEDIUM | YES | EXEC_ELAPSED='1s', ACTION=KILL, WATCH=EXACT DURATION='5m0s' | NULL |
+---------+------------+----------+-----------+-------------------------------------------------------------+------------+
1 row in set (0.00 sec)查看视图,有一条 watch 规则生成:
mysql> SELECT * FROM INFORMATION_SCHEMA.RUNAWAY_WATCHES ORDER BY id\G
*************************** 1. row ***************************
ID: 50
RESOURCE_GROUP_NAME: default
START_TIME: 2023-09-19 16:58:20
END_TIME: 2023-09-19 17:03:20
WATCH: Exact
WATCH_TEXT: SELECT count(1)
FROM sbtest.sbtest1 AS S1
,sbtest.sbtest2 AS S2
,sbtest.sbtest3 AS S3
WHERE S1.c=S2.c
AND S1.c=S3.c
SOURCE: 127.0.0.1:4000
ACTION: Kill
1 row in set (0.01 sec)有问题的查询被执行时会直接退出,告知已经被监控隔离:
ERROR 8254 (HY000): Quarantined and interrupted because of being in runaway watch list至此,我们看到, 通过对异常查询的自动识别和监测,能够有效限制个别 SQL 的资源消耗, 缓解其对整体性能的影响。
在上述示例中,即使没有设置资源组对查询的自动识别,在出现 SQL 性能问题时,我们仍可以通过“慢日志”或者系统表找出问题查询的“特征”,用 QUERY WATCH 手工将查询加入监视列表,达到设置黑名单的效果。
展望
TiDB Runaway Queries 管理的一个显著优势是提升了用户体验。通过自动化和手动管理的结合,用户能够更轻松地监控和控制数据库中的 Runaway Queries,避免它们对正常业务的干扰。
未来, TiDB 会持续增强管理 Runaway Queries 的能力,支持更多且复杂的识别规则, 增加更丰富的处理手段,全面提升可观测性,通过引入图形化管理的方式进一步提升用户体验, 为 TiDB 迈向企业级数据库平台保驾护航。
目录