
导读
在快速发展的互联网时代,数据库技术作为支撑现代应用的基石,其重要性日益凸显。尤其在游戏行业,随着用户规模的不断扩大和业务需求的日益复杂,传统的数据库解决方案面临着诸多挑战。分布式数据库以其高可扩展性、高可用性和强大的处理能力,成为解决这些问题的理想选择。
本文为竞技世界 DBA 魏建强在 TiDB 地区活动北京站分享“TiDB 在竞技世界从 1-N 的应用实践”的实录回顾。文章从四个关键方面展开讨论:选择 TiDB 的初衷、构建 TiDB 应用服务的起步阶段、使用 TiDB 带来的显著收益,以及在实践过程中遇到的一些典型问题和解决方案。

大家好,我是来自竞技世界的魏建强。今天我将分享的主题是 TiDB 在我们公司从最初的引入到广泛应用的整个实践过程。
竞技世界成立于 2007 年,主要致力于网络游戏的研发和运营。我们旗下的游戏平台“JJ 斗地主”注册用户数已超过 5 亿。在推广竞技棋牌文化的同时,我们还涉足自研手游领域,例如《曙光英雄》和《热血街篮》等。至今,我们已经成功举办了 16 届“JJ 斗地主”冠军杯赛事。
TiDB 首次在竞技世界落地是在 2021 年 7 月到 8 月间。接下来,我将从四个方面介绍我们的 TiDB 实践:为什么选择 TiDB,如何从 0 到 1 构建 TiDB 应用服务,使用 TiDB 过程中的收益,以及遇到的一些典型问题。
为什么选择 TiDB

在采用 TiDB 之前,我们主要使用 MySQL 和 MyCAT 集群架构,在业务使用场景中,遭遇了存储瓶颈、性能瓶颈、高可用性问题以及弹性扩缩容等的问题。例如,超大表的并发能力有限,读写分离中从库延迟可能导致读到脏数据以及 MHA 高可用在出现网络抖动时可能出现误切甚至数据丢失的问题。
对于 MyCAT 集群而言,如果在上线业务前分片选择不合理,可能会导致数据倾斜,降低查询性能;同时数据聚合查询的难度非常大,对事务的支持也十分有限。而 MySQL 集群我们则是更多地应用于 OLTP 类场景,在大数据量下统计分析类的查询效率非常低下。
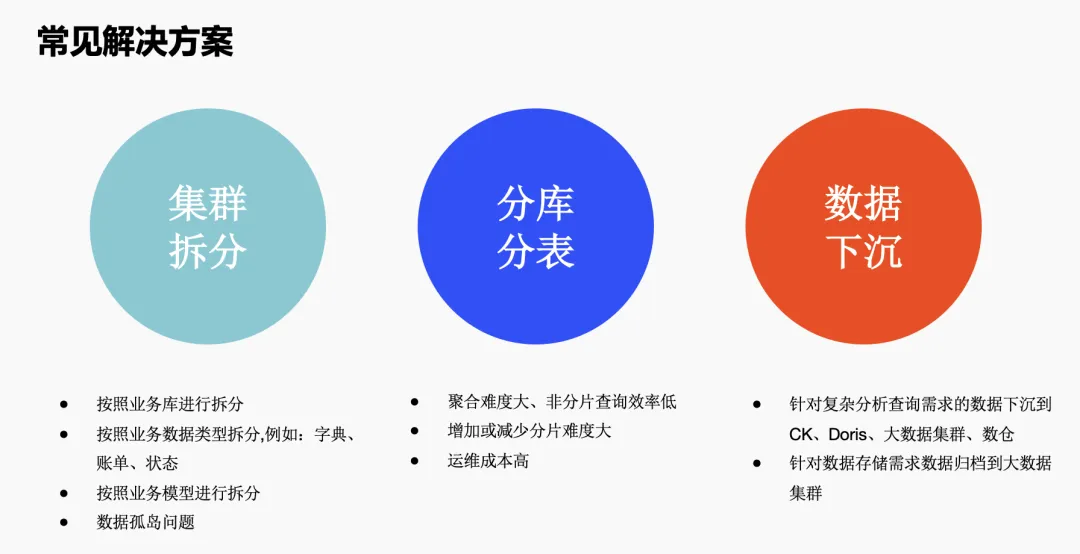
针对上述遇到的一些问题,我们尝试通过集群拆分、分库分表等方式来缓解单个集群的压力、提升整体的吞吐量;同时将分析性场景数据下沉到 ClickHouse、Doris 这样的分析型库中,但同时但也带来了数据孤岛、数据一致性保障以及运维复杂性问题。
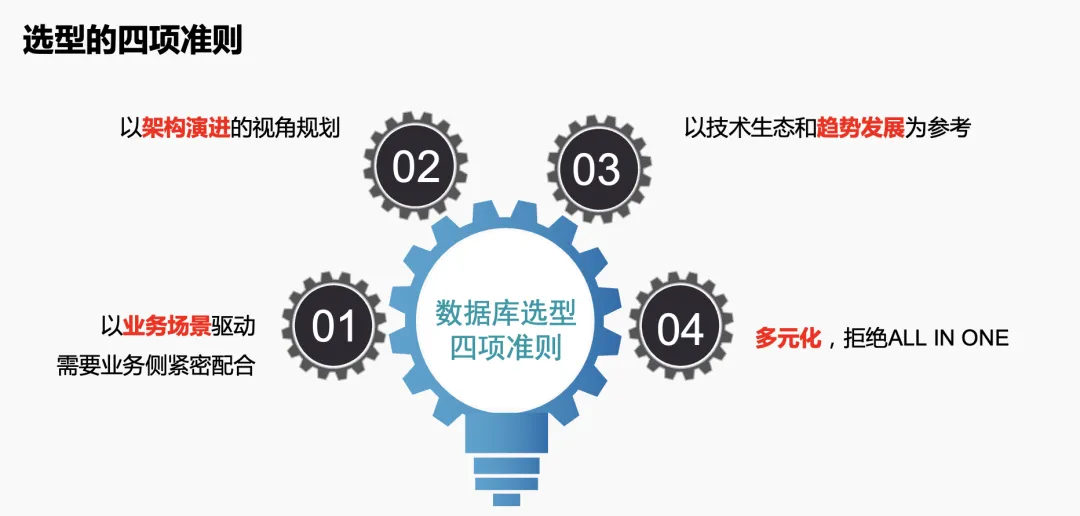
为了解决这些问题,我们在 2021 年初对数据库进行了调研,并依据四个准则进行选型:业务场景驱动、架构演进视角、技术生态和趋势发展,以及多元化选择,拒绝 ALL IN ONE 的方案。
我们选择 TiDB 的原因可以归纳为四点:稳定性和扩展性、业务需求、运维管理以及成熟度。TiDB 提供了数据库一致性、原生高可用和容灾能力、弹性扩缩容以及事务支持。它满足了我们对海量数据存储、高性能和高并发、低业务改造和接入成本、实时 HTAP 的需求。同时,TiDB 作为开源产品,拥有丰富的周边生态和成熟的社区支持。

如何从 0 到 1 应用 TiDB
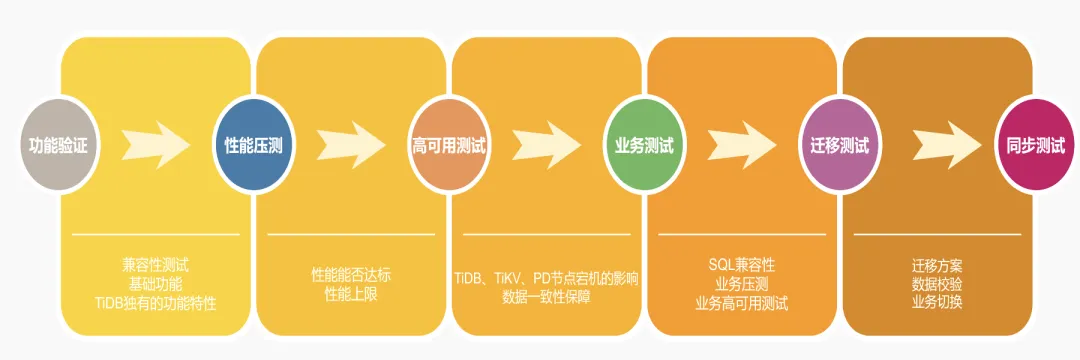
在选型阶段,我们进行了一系列的验证性测试,包括功能验证、性能压测、高可用测试、业务接入测试、迁移测试以及迁移后的同步测试。这一系列的测试帮助我们确保了从 MySQL 到 TiDB 的迁移过程的顺利进行。
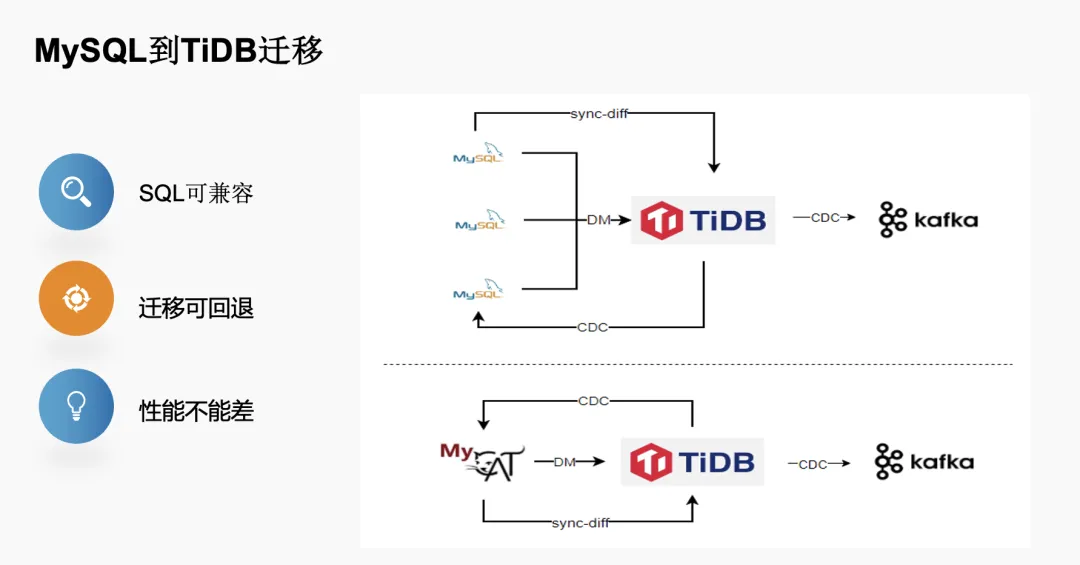
从 MySQL 迁移到 TiDB,有三个基本要求:SQL 可兼容、迁移可回退、性能不能差。在这个基础上,我们针对 MySQL 和 MyCAT 设计了两套迁移流程。
第一种就是刚才提到的集群拆分:按照之前的架构,针对单个实例业务达到瓶颈后,我们会针对单个业务按照业务维度拆分,需要上游的业务做路由,来写到对应的实例上。引入 TiDB 后,我们通过 DM 把之前拆分的实例合并到同一个 TiDB 集群中,为了满足“迁移可回退”的要求,我们将通过 DM 同步到 TiDB 的数据在通过 TiCDC 把迁移的数据写回 MySQL 中;保证业务切换到 TiDB 后能后随时回退到原来的环境;在数据一致性校验上,我们是通过官方的工具 sync-diff-inspector 来满足业务切换前数据最终一致性保证。
类似地,针对 MyCAT 集群,我们也是从底层的数据节点,通过 DM 实时同步到 TiDB 集群,再通过 TiCDC 进行反向写入,再通过 sync-diff-inspector 去做数据的完整性校验。
过去我们的数据是从 MySQL 同步到 Kafka,再通过 Canal 去采增量数据传输到 Kafka;迁移到 TiDB 后可以通过 CDC 接入 Canal 协议,无缝地切到 Kafka,满足下游消费端的需求。
使用 TiDB 的收益
迁移到 TiDB 后,我们观察到了显著的性能提升。
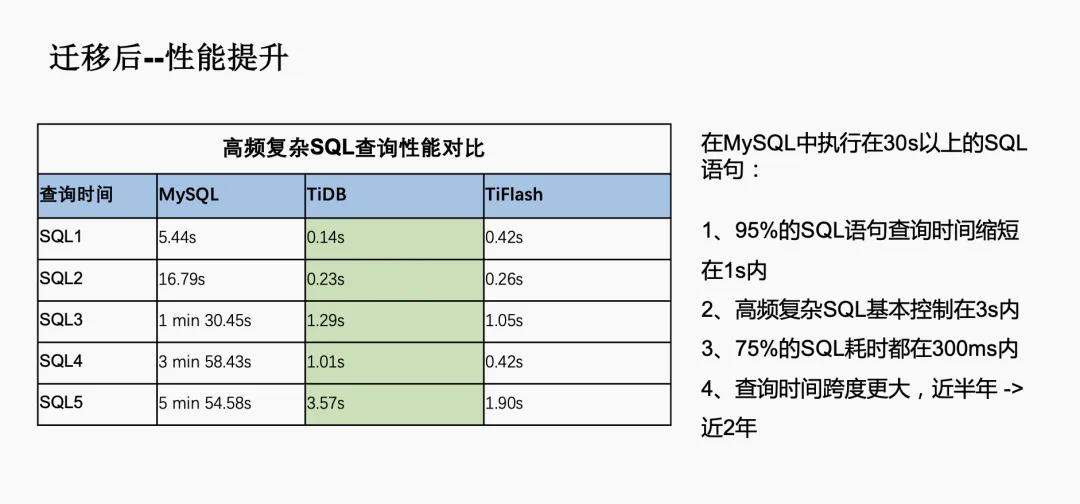
比如某个业务的特点是大宽表,同时有 OLTP 和 OLAP 类的请求,且 SQL 非常复杂,在迁移到 TiDB 后性能有了明显的提升。例如,之前在 MySQL 中执行超过 30 秒的 SQL 语句,在 TiDB 中 95% 的查询时间缩短至 1 秒内,高频复杂 SQL 基本控制在 3 秒内。过去由于数据量的限制,只能查询近半年的数据,迁移到 TiDB 后能够对近 2-3 年的数据进行查询和分析。
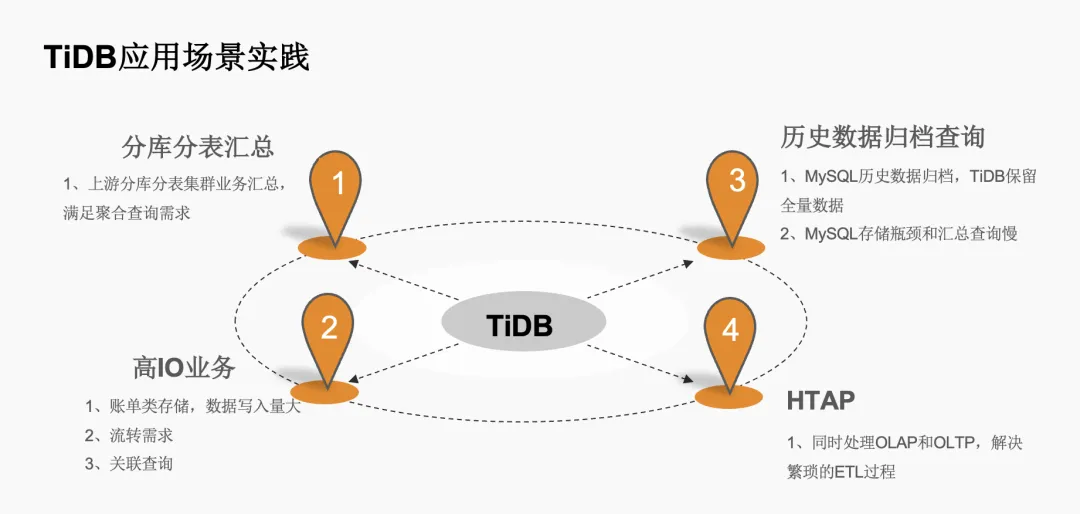
TiDB 在我们公司的应用场景包括分库分表汇总、高 IO 型业务、历史数据归档以及实时 HTAP 场景。目前,我们线上有 9 套集群,共 115 个节点,主要运行版本为 5.0 和 6.5,预计今年将全部升级到 6.5。
使用 TiDB 后,我们获得了显著的收益。
- 从研发侧角度来说,接入成本变得非常便捷,数据存储容量增加,聚合查询速率加快,数据统计分析更加实时,使业务团队能够更专注于业务创新。
- 从运维侧角度来看,TiDB 的引入降低了运维成本,提高了集群的稳定性和数据一致性,同时通过弹性扩缩容和主机迁移,运维效率提升了 10 倍以上。

遇到的一些问题
当然,在使用 TiDB 的过程中,我们也遇到了一些典型问题,如热点问题、GC 不工作、Write Stalls 以及隐式数据类型转换问题。针对这些问题,我们采取了相应的解决方案。
热点问题
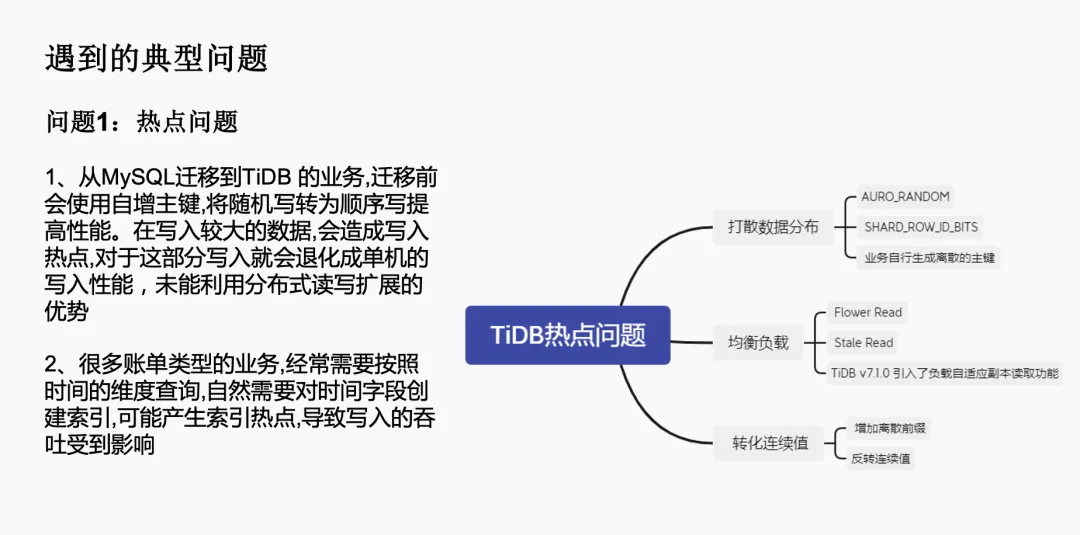
首先,是在从 MySQL 迁移到 TiDB 后遇到的热点问题。在 MySQL 中,我们通常会设置自增主键,将随机写入转换为顺序写入以提高性能。但在 TiDB 中,如果继续使用自增主键,在高 IO 型的账单类业务场景下,就会出现写入热点,导致写入性能退化,无法充分利用 TiDB 的分布式特性。
为了解决这个问题,我们采取了几种策略:
- 打散数据分布,例如将自增主键替换为随机主键,使用
AUTO_RANDOM的方式强制打散到不同的 TiKV 节点。 - 业务端自行生成离散的组件,如使用 UUID。
- 均衡集群负载,利用 TiDB 官方提供的
Follower Reads和Stereo RAID方式,将读请求转移到 Follower 节点,减轻 Leader 节点的压力。 - 利用 TiDB 7.1 版本引入的负载自适应副本读功能,进一步优化负载分布。
通过 TiDB 提供的 Dashboard 热力图,我们可以明显看到优化前后写入热点的变化,优化后的写入更加均衡。

GC 不工作
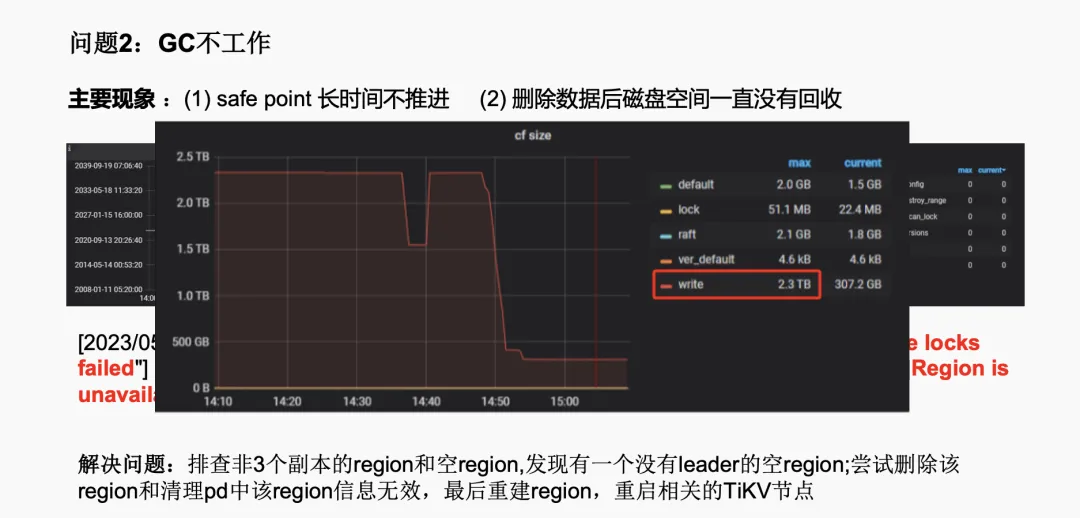
我们还遇到了 TiDB 的 GC(Garbage Collection)机制不工作的问题,这在 5.0.3 版本中发生了两次。具体现象是删除数据后磁盘空间没有被回收。正常情况下,数据删除后,GC 默认设置的 10 分钟内应该进行回收,但实际上并没有发生,导致存储空间持续增长。
通过排查,我们发现是由于某个 Region 不可用导致的。其原因是在缩容后,出现了一个没有 Leader 的空 Region,造成了这个问题。最初我们尝试删除这个 Region 并清理 PD 中的记录,但这两种方法都没有效果。最终,我们通过重建 Region 并重启相关的 TiKV 节点来解决了这个问题。解决后,可以看到存储空间明显下降。
Write Stalls
另一个问题是 Write Stalls,这是 RocksDB 的一种流控机制。当 RocksDB 的 flush 或 compaction 跟不上写入速率时,会降低写入速率,甚至停止写入。我们通过监控发现,Write Stalls 通常由以下三种情况引起:
- Memtable 文件数量过多。
- L0 层 SST 文件数量过多。
- L1 到 Ln 层待 Compaction 的 SST 文件大小过大。
解决这个问题的方法包括:
- 如果磁盘 IO 和 CPU 压力不大,适当调整 TiKV 并发刷盘参数可以解决问题。
- 如果磁盘 IO 和 CPU 压力较大,说明 Write Stalls 的本质原因是磁盘 IO 跟不上,这时需要考虑业务端限流或集群扩容。


隐式数据类型转换
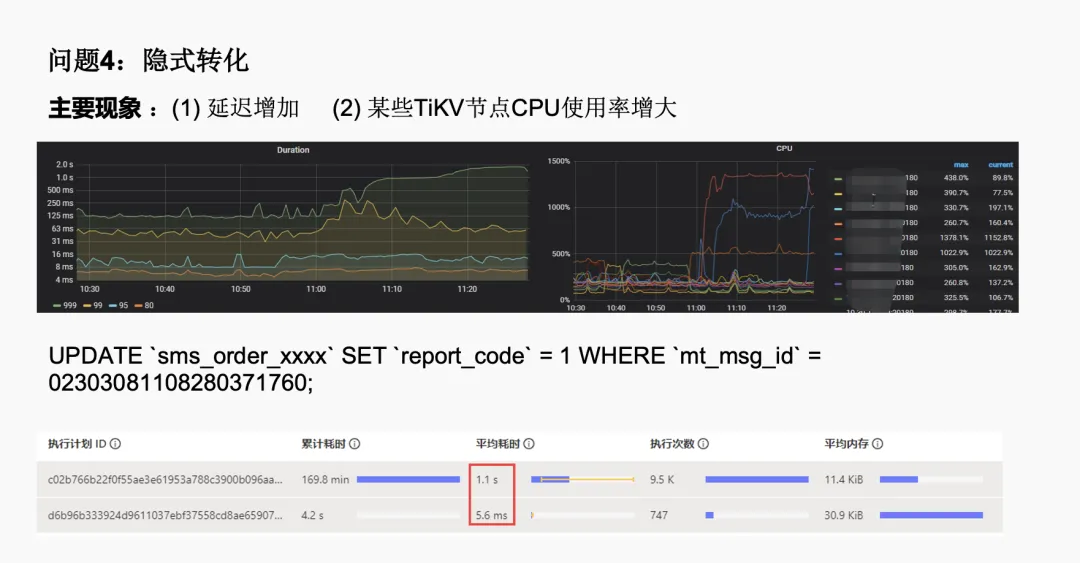
最后一个问题是隐式数据类型转换问题。在执行并发的 update 操作时,即使 where 条件中有索引,但执行延迟仍在增加,某些 TiKV 节点的 CPU 使用率异常突增。经过分析,我们发现是由于数据类型不匹配导致的隐式转换问题。例如,建表语句中使用了 VARCHAR,但更新时使用了 INT 类型。
解决方案是确保数据类型的一致性,对于过滤条件加上引号,使其与建表语句中的数据类型相对应。优化后,执行时间从平均 1.1 秒减少到只有 5.6 毫秒。
通过这些实际的案例,我们可以看到在使用 TiDB 时可能会遇到的挑战以及相应的解决策略。这些问题的解决不仅提高了我们对 TiDB 的理解,也增强了我们在使用分布式数据库时的运维能力。
结语
TiDB 作为一个活跃的开源项目,它的成功实施需要社区、用户和开发者的共同努力。希望通过今天的分享,能够让大家更深入地了解 TiDB,并在各自的业务场景中发挥其最大价值。
目录