
本文根据多点 Dmall 数据库团队负责人冯光普在 TUG 企业行成都站的分享整理而成,介绍了在数字化零售场景下,TiDB 在多点的使用情况、核心业务场景支撑、价值分析、及经验总结。
一、Dmall OS 数字化零售方案
Dmall OS 是多点全渠道数字化零售方案,通过对零售场景中人、货、场全方位数字化解构+重构,赋能零售商和品牌商,帮助客户实现会员数字化、搭建线上线下一体化营销体系、实现门店作业在线化协同、以及智能供应链,助力商家降本、增效、提升客户体验。
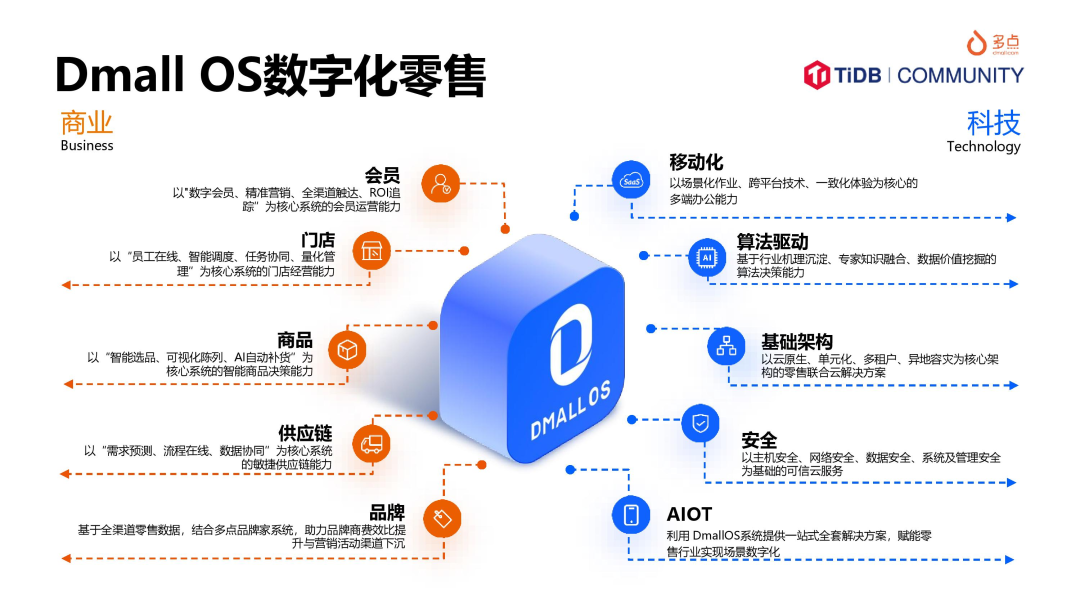
截止到 2021 年 6 月,Dmall OS 已助力物美,麦德龙,711,新百,中百,重百,锅圈食汇,DairyFarm,万宁等 120+ 国内外零售商,覆盖连锁商超、便利店、专营零售等业态;并基于全渠道零售数据为国内外知名品牌实现高速增长。

二、TiDB 整体使用情况
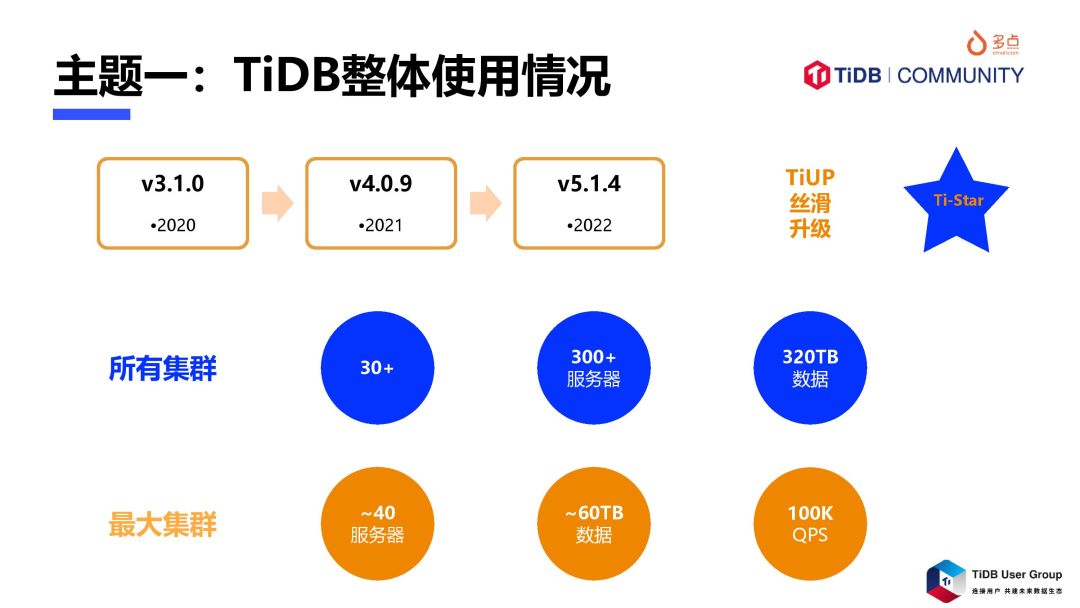
多点自 2019 年接触 TiDB,目前有超过 30 个 TiDB 集群,服务器节点超过 300 个,总数据量 320TB 以上,其中,最大的 TiDB 集群有 40 台服务器规模,数据量级 60TB,集群 QPS 峰值达到了 100K。
-
2020 年开始调研并在非关键业务中试用,当时版本是 v3.1;
-
2021 年正式跑通上线,在业财融合场景中落地,版本 v4.0.9,除 TiCDC 偶尔出问题,整体比较稳定;
-
2022 年整体升级到 v5.1.4 后,TiCDC 稳定性问题也得到彻底解决,研发和 DBA 睡觉非常踏实;
TiDB 大版本升级,使用 TiUP 仅一条命令即可完成,滚动的方式,过程中业务也很平滑,深得 DBA 喜爱
当前各行业数字化转型,将领域对象、流程、场景数字化,实现实时在线、高效协同、智能决策,垂直领域的 SaaS 解决方案不断涌现,它们在助力企业降本增效的同时,在数据方面也面临以下技术挑战:
-
数据持续快速增长,对于 MySQL 等开源单机数据库,达到容量上限需引入分库分表方案,比如 Sharding-JDBC,这类方案虽然逻辑上透明,但使用后 SQL 能力受限,实际很难执行跨节点 SQL;
-
实时商业洞察,数据规模大且产生速度快,对 AP 也提出了挑战,T+1 的方式已经难以满足商业洞察和决策的需求了,比如:商家营销活动的执行效果分析,如果依赖 ETL 抽数+离线计算的技术方案,就无法在活动进行中及时优化营销策略,提升有限资源的回报率;
-
更低的成本,不仅是资源层面的存储成本,计算成本,也包括架构及维护成本,弹性可扩展的云原生架构是未来的发展趋势;

三、核心业务场景支撑
TiDB 在多点 Dmall 的典型应用场景,简单归纳,主要有以下三类:
1.海量流水类存储,使用 TiDB 直接替换了 MySQL,多并发批量写的方式,充分发挥 TiDB 高吞吐的优势,典型场景:App 推送记录,短信发送记录,单次营销活动产生的记录可达千万规模,从 MySQL 切换到 TiDB 后,DBA 就告别了容量焦虑,不用频繁归档历史数据,且 RocksDB 引擎相对 InnoDB 引擎有 3~10 的压缩优势,成本比使用 MySQL 更低;

2.冷热分离全量存储,对于响应时间敏感,同时数据持续快速增长的在线业务,采用读写分离架构,将近期热数据存储在 MySQL,提供高并发低延迟的在线读写,同时实时同步到 TiDB,保存全量数据,提供历史快照查询及统计分析,支持业务数据变更溯源。典型场景:商品调价、库存变更,数据量超过了单机 MySQL 容量,且持续增长,基于自研的 DRC-TiDB 组件(它可过滤源端 MySQL 归档 DELETE 事件,同步 MySQL 数据到 TiDB),避免了数据增长超过 MySQL 单机容量后水平拆分的技术复杂度;

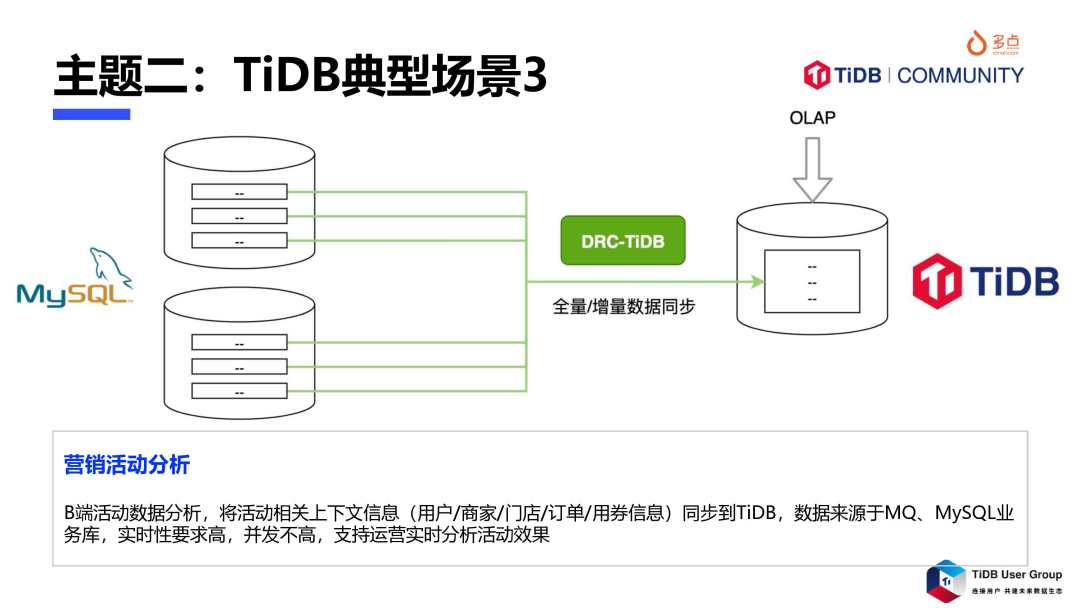
3.多源聚合存储及分析,中台思想及微服务技术架构,实现了在业务域清晰划分下的技术能力复用,及研发高效分工协同,但也导致了数据散落到各个业务子系统中,全链路的业务聚合分析变得困难,在数据规模超过单机存储容量,且要求准实时性分析时,问题更甚。TiDB 透明的水平扩展能力,及 TiFlash 引擎 AP 能力,为这类场景提供了可行方案,典型场景:营销活动分析,聚合同步了多个在线 MySQL 业务库及 MQ 的数据,在 TiDB 中实时计算活动效果,助力运营评估和优化营销策略。
四、TiDB 价值分析
站在研发的视角,使用 TiDB 的好处:
-
更简单的架构,TP 分库分表 + ETL 同步聚合 + AP 分析引擎,这种技术架构,除了技术复杂度、资源成本高、运维困难外,结构/数据一致性难以保证,ETL 同步延迟也是常态。TiDB 提供了另外一种可能:基于内建的 Raft learner 数据复制技术简化了架构,实现 TP 业务和 AP 业务基于同一份数据,避免了一致性和延迟问题。
-
实时数据分析能力,基于 TiFlash 列存引擎,及 MPP 计算架构,实时业务数据集上的直接分析得以实现,得益于 TiKV 的水平扩展能力,上游数据的流入和存储几乎无限制,更多的数据,可放大实时数据分析的价值。
-
专注业务创新,在充满不确定性的商业竞争中,为快速验证 MVP,业务早期存储选型采用简单易用的 MySQL,但在数据规模达到单机容量上限引入分库分表等技术后,业务研发就需要关注底层存储架构的约束和限制,开发效率降低;甚至权衡性能、稳定性、或成本被迫放弃部分需求特性,业务创新也受到影响,丢失早期竞争优势。TiDB 提供了另外一种可能:在业务进入快速增长阶段,底层存储的扩展对上层业务真正透明,让研发可以专注于业务创新和快速迭代。

站在运维 DBA 视角,使用 TiDB 的好处:
-
云原生红利,TiDB 符合云原生架构理念,不论计算层,还是存储层,加机器即扩容,可按需、弹性、近乎无限扩展,相较于 MySQL 分库分表方案的技术复杂、实施门槛高、SQL 能力受限,大规模快速增长数据场景下,运维 TiDB 幸福指数高于运维 MySQL;
-
MySQL生态友好,TiDB 兼容 MySQL 协议,已建成的平台工具,可直接复用,比如:查询工具,慢 SQL 分析,监控指令等,DBA 可快速上手为研发提供数据库接入服务;
-
数据可靠性高,MySQL 需要依赖外部 HA 组件实现故障切换,除部署配置复杂外,还难以彻底避免脑裂问题,TiDB 内部实现了基于 Raft 的数据同步和故障切换,failover 高效可靠,数据强一致保证,DBA 几乎没有心智负担;

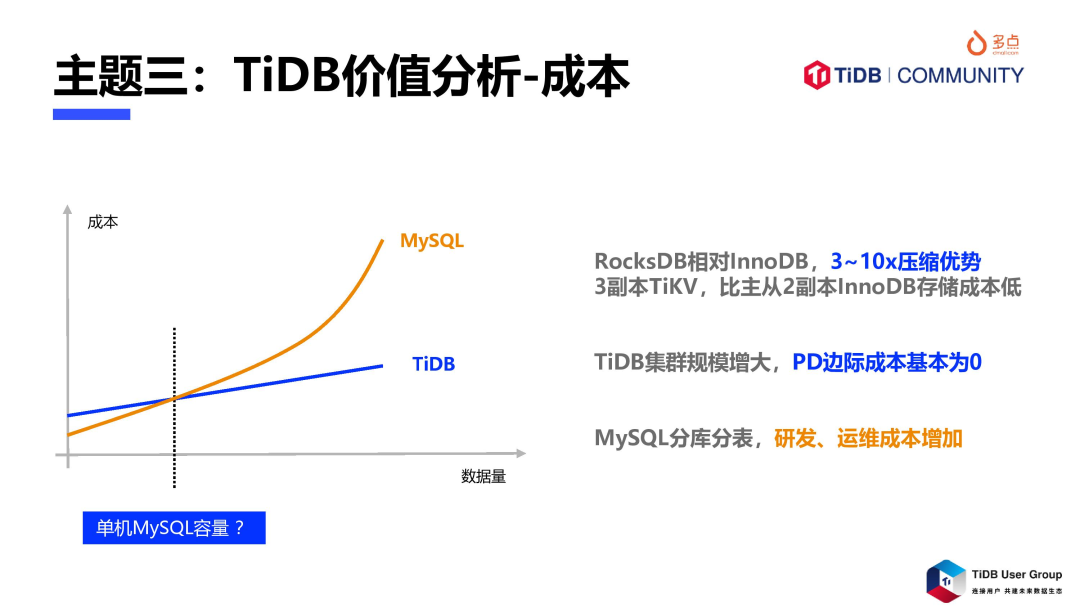
在成本方面,TiDB 一直有很多争议:1)组件多,有 PD、TiKV、TiDB 等;2)多副本+高可用,集群部署起步成本较高,会劝退很多用户。根据我们实际使用经验,成本方面的真实情况是:
-
在数据规模较小,如在单机 MySQL 容量以内,主从两节点 MySQL 集群,成本是远低于 TiDB 集群的;
-
当数据规模超过单机 MySQL 容量,需要引入 sharding 方案后,情况会发生变化,使用 TiDB 可能比使用 MySQL 更便宜,主要因为:
-
TiKV 的 RocksDB 引擎相对 InnoDB 引擎,有 3~10 倍压缩优势,存储相同规模数据,TiDB 的存储节点数远远低于 MySQL 集群;
-
随着数据规模增长,只有 TiKV 节点数是随之增长,PD 节点的成本基本不增长,而 TiDB 节点数是与 QPS 相关;
-
还需考虑引入 sharding 方案后,技术复杂度提升,SQL 能力受限,会带来运维成本的升高,以及开发效率的降低;
五、实践经验及场景对比
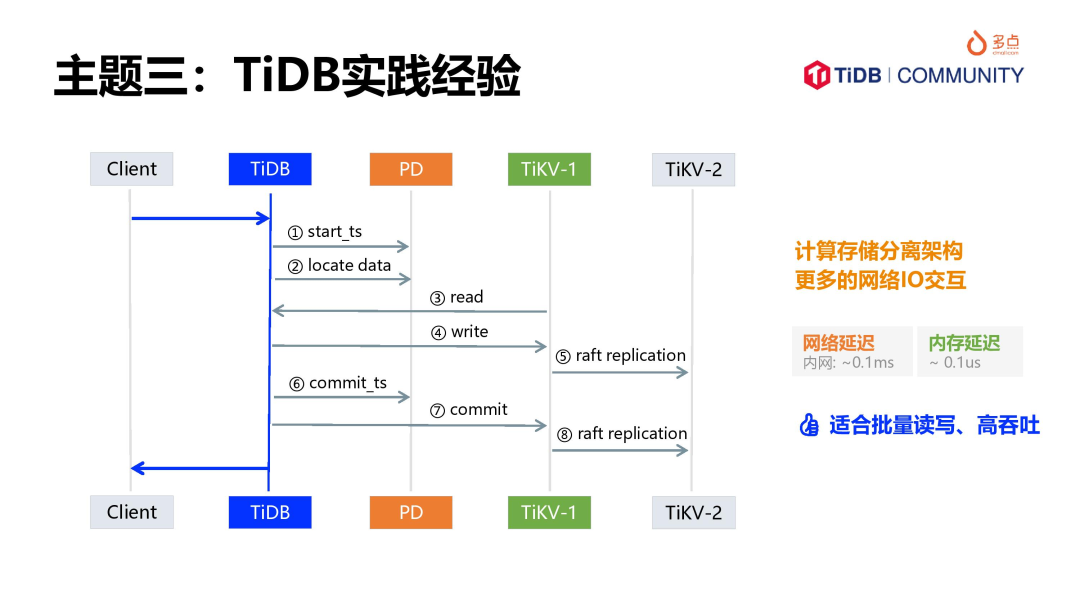
从使用 MySQL 切换到使用 TiDB,需要重点关注和理解分布式架构的优缺点,尤其是算存分离以及分布式事务带来的网络开销,局域网的网络交互延迟,与读写 SSD 的 IO 延迟在一个级别,它远远高于单机数据库进程内的数据交互,简单总结一下,结论:
-
TiDB 相比 MySQL 响应更慢;
-
TiDB 相比 MySQL 可输出吞吐更高;
因此,建议采用多并发、批量读写的方式,以发挥 TiDB 的优势。
在数据规模小,要求低延迟的 TP 业务场景中,MySQL 更加合适,而在数据规模远超单机容量、持续快速增长、对响应延迟不那么敏感的 HTAP 业务场景中,使用 TiDB 更加合适。
六、总结
-
TiDB 基于云原生理念,采用算存分离架构,可以按需、弹性、近乎无限的水平扩展;
-
基于 TiDB 的 HTAP 能力,可实现同时支撑 TP 业务和 AP 业务的一体化架构,综合成本低;
-
TiDB 与 MySQL 相辅相成,生态友好,是优秀的面向数据快速增长的理想选择。
延展阅读:
“新经济 DTC 转型背后的数据库”专题
目录