
简介
TiDB Data Migration 是用于将数据从 MySQL/MariaDB 迁移到 TiDB 的工具。该工具既支持以全量备份文件的方式将 MySQL/MariaDB 的数据导入到 TiDB,也支持通过解析执行 MySQL/MariaDB binlog 的方式将数据增量同步到 TiDB。特别地,对于有多个 MySQL/MariaDB 实例的分库分表需要合并后同步到同一个 TiDB 集群的场景,DM 提供了良好的支持。如果你需要从 MySQL/MariaDB 迁移到 TiDB,或者需要将 TiDB 作为 MySQL/MariaDB 的从库,DM 将是一个非常好的选择。
架构设计
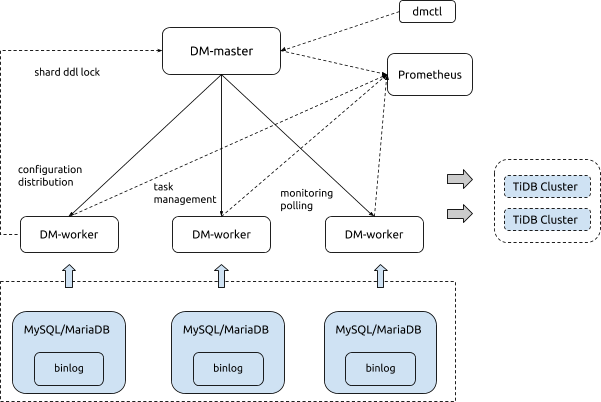
DM 是集群模式的,其主要由 DM-master、DM-worker 与 DM-ctl 三个组件组成,能够以多对多的方式将多个上游 MySQL 实例的数据同步到多个下游 TiDB 集群,其架构图如下:
-
DM-master:管理整个 DM 集群,维护集群的拓扑信息,监控各个 DM-worker 实例的运行状态;进行数据同步任务的拆解与分发,监控数据同步任务的执行状态;在进行合库合表的增量数据同步时,协调各 DM-worker 上 DDL 的执行或跳过;提供数据同步任务管理的统一入口。
-
DM-worker:与上游 MySQL 实例一一对应,执行具体的全量、增量数据同步任务;将上游 MySQL 的 binlog 拉取到本地并持久化保存;根据定义的数据同步任务,将上游 MySQL 数据全量导出成 SQL 文件后导入到下游 TiDB,或解析本地持久化的 binlog 后增量同步到下游 TiDB;编排 DM-master 拆解后的数据同步子任务,监控子任务的运行状态。
-
DM-ctl:命令行交互工具,通过连接到 DM-master 后,执行 DM 集群的管理与数据同步任务的管理。
实现原理
数据迁移流程
单个 DM 集群可以同时运行多个数据同步任务;对于每一个同步任务,可以拆解为多个子任务同时由多个 DM-worker 节点承担,其中每个 DM-worker 节点负责同步来自对应的上游 MySQL 实例的数据。对于单个 DM-worker 节点上的单个数据同步子任务,其数据迁移流程如下,其中上部的数据流向为全量数据迁移、下部的数据流向为增量数据同步:
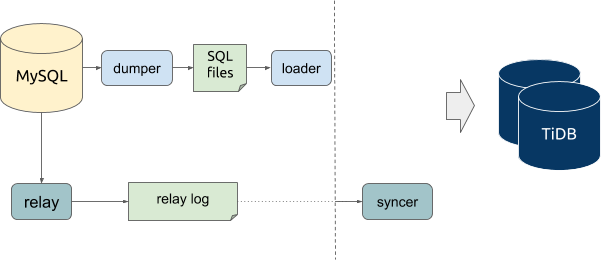
在每个 DM-worker 节点内部,对于特定的数据同步子任务,主要由 dumper、loader、relay 与 syncer(binlog replication)等数据同步处理单元执行具体的数据同步操作。
-
对于全量数据迁移,DM 首先使用 dumper 单元从上游 MySQL 中将表结构与数据导出成 SQL 文件;然后使用 loader 单元读取这些 SQL 文件并同步到下游 TiDB。
-
对于增量数据同步,首先使用 relay 单元作为 slave 连接到上游 MySQL 并拉取 binlog 数据后作为 relay log 持久化存储在本地,然后使用 syncer 单元读取这些 relay log 并解析构造成 SQL 语句后同步到下游 TiDB。这个增量同步的过程与 MySQL 的主从复制类似,主要区别在于在 DM 中,本地持久化的 relay log 可以同时供多个不同子任务的 syncer 单元所共用,避免了多个任务需要重复从上游 MySQL 拉取 binlog 的问题。
数据迁移并发模型
为加快数据导入速度,在 DM 中不论是全量数据迁移,还是增量数据同步,都在其中部分阶段使用了并发处理。
对于全量数据迁移,在导出阶段,dumper 单元调用 mydumper 导出工具执行实际的数据导出操作,对应的并发模型可以直接参考 mydumper 的源码。在使用 loader 单元执行的导入阶段,对应的并发模型结构如下:
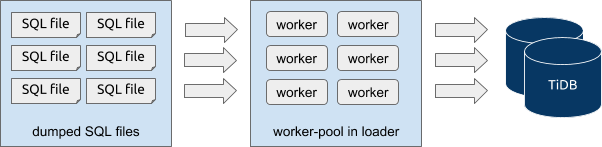
使用 mydumper 执行导出时,可以通过 --chunk-filesize 等参数将单个表拆分成多个 SQL 文件,这些 SQL 文件对应的都是上游 MySQL 某一个时刻的静态快照数据,且各 SQL 文件间的数据不存在关联。因此,在使用 loader 单元执行导入时,可以直接在一个 loader 单元内启动多个 worker 工作协程,由各 worker 协程并发、独立地每次读取一个待导入的 SQL 文件进行导入。即 loader 导入阶段,是以 SQL 文件级别粒度并发进行的。在 DM 的任务配置中,对于 loader 单元,其中的 pool-size 参数即用于控制此处 worker 协程数量。
对于增量数据同步,在从上游拉取 binlog 并持久化到本地的阶段,由于上游 MySQL 上 binlog 的产生与发送是以 stream 形式进行的,因此这部分只能串行处理。在使用 syncer 单元执行的导入阶段,在一定的限制条件下,可以执行并发导入,对应的模型结构如下:
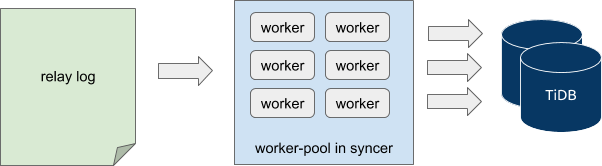
当 syncer 读取与解析本地 relay log 时,与从上游拉取 binlog 类似,是以 stream 形式进行的,因此也只能串行处理。当 syncer 解析出各 binlog event 并构造成待同步的 job 后,则可以根据对应行数据的主键、索引等信息经过 hash 计算后分发到多个不同的待同步 job channel 中;在 channel 的另一端,与各个 channel 对应的 worker 协程并发地从 channel 中取出 job 后同步到下游的 TiDB。即 syncer 导入阶段,是以 binlog event 级别粒度并发进行的。在 DM 的任务配置中,对于 syncer 单元,其中的 worker-count 参数即用于控制此处 worker 协程数量。
但 syncer 并发同步到下游 TiDB 时,存在一些限制,主要包括:
-
对于 DDL,由于会变更下游的表结构,因此必须确保在旧表结构对应的 DML 都同步完成后,才能进行同步。在 DM 中,当解析 binlog event 得到 DDL 后,会向每一个 job channel 发送一个特殊的 flush job;当各 worker 协程遇到 flush job 时,会立刻向下游 TiDB 同步之前已经取出的所有 job;等各 job channel 中的 job 都同步到下游 TiDB 后,开始同步 DDL;等待 DDL 同步完成后,继续同步后续的 DML。即 DDL 不能与 DML 并发同步,且 DDL 之前与之后的 DML 也不能并发同步。sharding 场景下 DDL 的同步处理见后文。
-
对于 DML,多条 DML 可能会修改同一行的数据,甚至是主键。如果并发地同步这些 DML,则可能造成同步后数据的不一致。DM 中对于 DML 之间的冲突检测与处理,与 TiDB-Binlog 中的处理类似,具体原理可以阅读《TiDB EcoSystem Tools 原理解读(一)TiDB-Binlog 架构演进与实现原理》中关于 Drainer 内 SQL 之间冲突检测的讨论。
合库合表数据同步
在使用 MySQL 支撑大量数据时,经常会选择使用分库分表的方案。但当将数据同步到 TiDB 后,通常希望逻辑上进行合库合表。DM 为支持合库合表的数据同步,主要实现了以下的一些功能。
table router
为说明 DM 中 table router(表名路由)功能,先看如下图所示的一个例子:
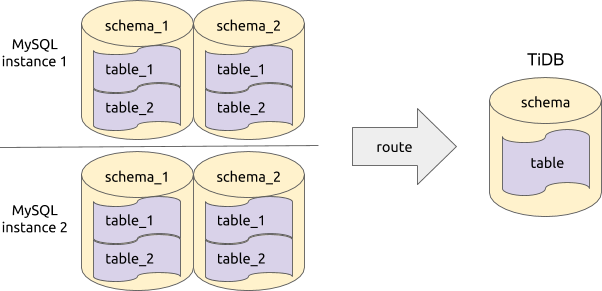
在这个例子中,上游有 2 个 MySQL 实例,每个实例有 2 个逻辑库,每个库有 2 个表,总共 8 个表。当同步到下游 TiDB 后,希望所有的这 8 个表最终都合并同步到同一个表中。
但为了能将 8 个来自不同实例、不同库且有不同名的表同步到同一个表中,首先要处理的,就是要能根据某些定义好的规则,将来自不同表的数据都路由到下游的同一个表中。在 DM 中,这类规则叫做 router-rules。对于上面的示例,其规则如下:
name-of-router-rule:
schema-pattern: "schema_*"
table-pattern: "table_*"
target-schema: "schema"
target-table: "table"-
name-of-router-rule:规则名,用户指定。当有多个上游实例需要使用相同的规则时,可以只定义一条规则,多个不同的实例通过规则名进行引用。 -
schema-pattern:用于匹配上游库(schema)名的模式,支持在尾部使用通配符(*)。这里使用schema_*即可匹配到示例中的两个库名。 -
table-pattern:用于匹配上游表名的模式,与schema-pattern类似。这里使用table_*即可匹配到示例中的两个表名。 -
target-schema:目标库名。对于库名、表名匹配的数据,将被路由到这个库中。 -
target-table:目标表名。对于库名、表名匹配的数据,将被路由到target-schema库下的这个表中。
在 DM 内部实现上,首先根据 schema-pattern / table-pattern 构造对应的 trie 结构,并将规则存储在 trie 节点中;当有 SQL 需要同步到下游时,通过使用上游库名、表名查询 trie 即可得到对应的规则,并根据规则替换原 SQL 中的库名、表名;通过向下游 TiDB 执行替换后的 SQL 即完成了根据表名的路由同步。有关 router-rules 规则的具体实现,可以阅读 TiDB-Tools 下的 table-router pkg 源代码。
column mapping
有了 table router 功能,已经可以完成基本的合库合表数据同步了。但在数据库中,我们经常会使用自增类型的列作为主键。如果多个上游分表的主键各自独立地自增,将它们合并同步到下游后,就很可能会出现主键冲突,造成数据的不一致。我们可看一个如下的例子:
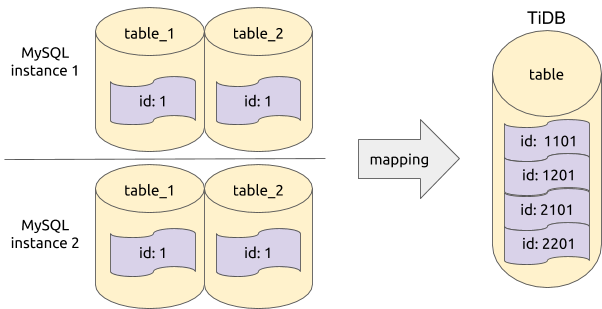
在这个例子中,上游 4 个需要合并同步到下游的表中,都存在 id 列值为 1 的记录。假设这个 id 列是表的主键。在同步到下游的过程中,由于相关更新操作是以 id 列作为条件来确定需要更新的记录,因此会造成后同步的数据覆盖前面已经同步过的数据,导致部分数据的丢失。
在 DM 中,我们通过 column mapping 功能在数据同步的过程中依据指定规则对相关列的数据进行转换改写来避免数据冲突与丢失。对于上面的示例,其中 MySQL 实例 1 的 column mapping 规则如下:
mapping-rule-of-instance-1:
schema-pattern: "schema_*"
table-pattern: "table_*"
expression: "partition id"
source-column: "id"
target-column: "id"
arguments: ["1", "schema_", "table_"] -
mapping-rule-of-instance-1:规则名,用户指定。由于不同的上游 MySQL 实例需要转换得到不同的值,因此通常每个 MySQL 实例使用一条专有的规则。 -
schema-pattern/table-pattern:上游库名、表名匹配模式,与router-rules中的对应配置项一致。 -
expression:进行数据转换的表达式名。目前常用的表达式即为"partition id",有关该表达式的具体说明见下文。 -
source-column:转换表达式的输入数据对应的来源列名,"id"表示这个表达式将作用于表中名为 id 的列。暂时只支持对单个来源列进行数据转换。 -
target-column:转换表达式的输出数据对应的目标列名,与source-column类似。暂时只支持对单个目标列进行数据转换,且对应的目标列必须已经存在。 -
arguments:转换表达式所依赖的参数。参数个数与含义依具体表达式而定。
partition id 是目前主要受支持的转换表达式,其通过为 bigint 类型的值增加二进制前缀来解决来自不同表的数据合并同步后可能产生冲突的问题。partition id 的 arguments 包括 3 个参数,分别为:
-
MySQL 实例 ID:标识数据的来源 MySQL 实例,用户自由指定。如
"1"表示匹配该规则的数据来自于 MySQL 实例 1,且这个标识将被转换成数值后以二进制的形式作为前缀的一部分添加到转换后的值中。 -
库名前缀:标识数据的来源逻辑库。如
"schema_"应用于schema_2逻辑库时,表示去除前缀后剩下的部分(数字2)将以二进制的形式作为前缀的一部分添加到转换后的值中。 -
表名前缀:标识数据的来源表。如
"table_"应用于table_3表时,表示去除前缀后剩下的部分(数字3)将以二进制的形式作为前缀的一部分添加到转换后的值中。
各部分在经过转换后的数值中的二进制分布如下图所示(各部分默认所占用的 bits 位数如图所示):

假如转换前的原始数据为 123,且有如上的 arguments 参数设置,则转换后的值为:
1<<(64-1-4) | 2<<(64-1-4-7) | 3<<(64-1-4-7-8) | 123另外,arguments 中的 3 个参数均可设置为空字符串(""),即表示该部分不被添加到转换后的值中,且不占用额外的 bits。比如将其设置为["1", "", "table_"],则转换后的值为:
1 << (64-1-4) | 3<< (64-1-4-8) | 123有关 column mapping 功能的具体实现,可以阅读 TiDB-Tools 下的 column-mapping pkg 源代码。
sharding DDL
有了 table router 和 column mapping 功能,DML 的合库合表数据同步已经可以正常进行了。但如果在增量数据同步的过程中,上游待合并的分表上执行了 DDL 操作,则可能出现问题。我们先来看一个简化后的在分表上执行 DDL 的例子。
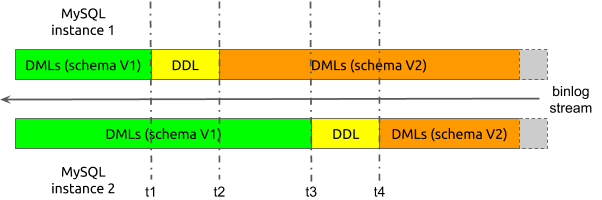
在上图的例子中,分表的合库合表简化成了上游只有两个 MySQL 实例,每个实例内只有一个表。假设在开始数据同步时,将两个分表的表结构 schema 的版本记为 schema V1,将 DDL 执行完成后的表结构 schema 的版本记为 schema V2。
现在,假设数据同步过程中,从两个上游分表收到的 binlog 数据有如下的时序:
-
开始同步时,从两个分表收到的都是
schema V1的 DML。 -
在 t1 时刻,收到实例 1 上分表的 DDL。
-
从 t2 时刻开始,从实例 1 收到的是
schema V2的 DML;但从实例 2 收到的仍是schema V1的 DML。 -
在 t3 时刻,收到实例 2 上分表的 DDL。
-
从 t4 时刻开始,从实例 2 收到的也是
schema V2的 DML。
假设在数据同步过程中,不对分表的 DDL 进行处理。当将实例 1 的 DDL 同步到下游后,下游的表结构会变更成为 schema V2。但对于实例 2,在 t2 时刻到 t3 时刻这段时间内收到的仍然是 schema V1 的 DML。当尝试把这些与 schema V1 对应的 DML 同步到下游时,就会由于 DML 与表结构的不一致而发生错误,造成数据无法正确同步。
继续使用上面的例子,来看看我们在 DM 中是如何处理合库合表过程中的 DDL 同步的。
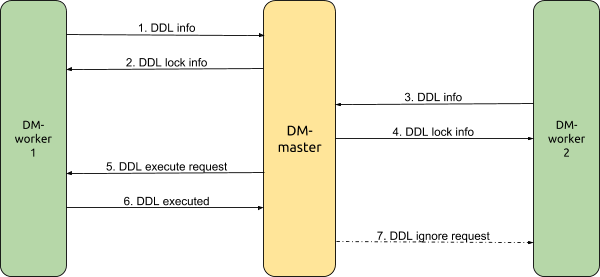
在这个例子中,DM-worker-1 用于同步来自 MySQL 实例 1 的数据,DM-worker-2 用于同步来自 MySQL 实例 2 的数据,DM-master 用于协调多个 DM-worker 间的 DDL 同步。从 DM-worker-1 收到 DDL 开始,简化后的 DDL 同步流程为:
-
DM-worker-1 在 t1 时刻收到来自 MySQL 实例 1 的 DDL,自身暂停该 DDL 对应任务的 DDL 及 DML 数据同步,并将 DDL 相关信息发送给 DM-master。
-
DM-master 根据 DDL 信息判断需要协调该 DDL 的同步,为该 DDL 创建一个锁,并将 DDL 锁信息发回给 DM-worker-1,同时将 DM-worker-1 标记为这个锁的 owner。
-
DM-worker-2 继续进行 DML 的同步,直到在 t3 时刻收到来自 MySQL 实例 2 的 DDL,自身暂停该 DDL 对应任务的数据同步,并将 DDL 相关信息发送给 DM-master。
-
DM-master 根据 DDL 信息判断该 DDL 对应的锁信息已经存在,直接将对应锁信息发回给 DM-worker-2。
-
DM-master 根据启动任务时的配置信息、上游 MySQL 实例分表信息、部署拓扑信息等,判断得知已经收到了需要合表的所有上游分表的该 DDL,请求 DDL 锁的 owner(DM-worker-1)向下游同步执行该 DDL。
-
DM-worker-1 根据 step 2 时收到的 DDL 锁信息验证 DDL 执行请求;向下游执行 DDL,并将执行结果反馈给 DM-master;若执行 DDL 成功,则自身开始继续同步后续的(从 t2 时刻对应的 binlog 开始的)DML。
-
DM-master 收到来自 owner 执行 DDL 成功的响应,请求在等待该 DDL 锁的所有其他 DM-worker(DM-worker-2)忽略该 DDL,直接继续同步后续的(从 t4 时刻对应的 binlog 开始的)DML。
根据上面 DM 处理多个 DM-worker 间的 DDL 同步的流程,归纳一下 DM 内处理多个 DM-worker 间 sharding DDL 同步的特点:
-
根据任务配置与 DM 集群部署拓扑信息,在 DM-master 内建立一个需要协调 DDL 同步的逻辑 sharding group,group 中的成员为处理该任务拆解后各子任务的 DM-worker。
-
各 DM-worker 在从 binlog event 中获取到 DDL 后,会将 DDL 信息发送给 DM-master。
-
DM-master 根据来自 DM-worker 的 DDL 信息及 sharding group 信息创建/更新 DDL 锁。
-
如果 sharding group 的所有成员都收到了某一条 DDL,则表明上游分表在该 DDL 执行前的 DML 都已经同步完成,可以执行 DDL,并继续后续的 DML 同步。
-
上游分表的 DDL 在经过 table router 转换后,对应需要在下游执行的 DDL 应该一致,因此仅需 DDL 锁的 owner 执行一次即可,其他 DM-worker 可直接忽略对应的 DDL。
从 DM 处理 DM-worker 间 sharding DDL 同步的特点,可以看出该功能存在以下一些限制:
-
上游的分表必须以相同的顺序执行(table router 转换后相同的)DDL,比如表 1 先增加列
a后再增加列b,而表 2 先增加列b后再增加列a,这种不同顺序的 DDL 执行方式是不支持的。 -
一个逻辑 sharding group 内的所有 DM-worker 对应的上游分表,都应该执行对应的 DDL,比如其中有 DM-worker-2 对应的上游分表未执行 DDL,则其他已执行 DDL 的 DM-worker 都会暂停同步任务,等待 DM-worker-2 收到对应上游的 DDL。
-
由于已经收到的 DDL 的 DM-worker 会暂停任务以等待其他 DM-worker 收到对应的 DDL,因此数据同步延迟会增加。
-
增量同步开始时,需要合并的所有上游分表结构必须一致,才能确保来自不同分表的 DML 可以同步到一个确定表结构的下游,也才能确保后续各分表的 DDL 能够正确匹配与同步。
在上面的示例中,每个 DM-worker 对应的上游 MySQL 实例中只有一个需要进行合并的分表。但在实际场景下,一个 MySQL 实例可能有多个分库内的多个分表需要进行合并,比如前面介绍 table router 与 column mapping 功能时的例子。当一个 MySQL 实例中有多个分表需要合并时,sharding DDL 的协调同步过程增加了更多的复杂性。
假设同一个 MySQL 实例中有 table_1 和 table_2 两个分表需要进行合并,如下图:

由于数据来自同一个 MySQL 实例,因此所有数据都是从同一个 binlog 流中获得。在这个例子中,时序如下:
-
开始同步时,两个分表收到的数据都是
schema V1的 DML。 -
在 t1 时刻,收到了
table_1的 DDL。 -
从 t2 时刻到 t3 时刻,收到的数据同时包含 table_1 schema V2 的 DML 及
table_2schema V1的 DML。 -
在 t3 时刻,收到了
table_2的 DDL。 -
从 t4 时刻开始,两个分表收到的数据都是
schema V2的 DML。
假设在数据同步过程中不对 DDL 进行特殊处理,当 table_1 的 DDL 同步到下游、变更下游表结构后,table_2 schema V1 的 DML 将无法正常同步。因此,在单个 DM-worker 内部,我们也构造了与 DM-master 内类似的逻辑 sharding group,但 group 的成员是同一个上游 MySQL 实例的不同分表。
但 DM-worker 内协调处理 sharding group 的同步不能完全与 DM-master 处理时一致,主要原因包括:
-
当收到
table_1的 DDL 时,同步不能暂停,需要继续解析 binlog 才能获得后续table_2的 DDL,即需要从 t2 时刻继续向前解析直到 t3 时刻。 -
在继续解析 t2 时刻到 t3 时刻的 binlog 的过程中,
table_1的schema V2的 DML 不能向下游同步;但在 sharding DDL 同步并执行成功后,这些 DML 需要同步到下游。
在 DM 中,简化后的 DM-worker 内 sharding DDL 同步流程为:
-
在 t1 时刻收到
table_1的 DDL,记录 DDL 信息及此时的 binlog 位置点信息。 -
继续向前解析 t2 时刻到 t3 时刻的 binlog。
-
对于属于
table_1的schema V2DML,忽略;对于属于table_2的schema V1DML,正常同步到下游。 -
在 t3 时刻收到
table_2的 DDL,记录 DDL 信息及此时的 binlog 位置点信息。 -
根据同步任务配置信息、上游库表信息等,判断该 MySQL 实例上所有分表的 DDL 都已经收到;将 DDL 同步到下游执行、变更下游表结构。
-
设置新的 binlog 流的解析起始位置点为 step 1 时保存的位置点。
-
重新开始解析从 t2 时刻到 t3 时刻的 binlog。
-
对于属于
table_1的schema V2DML,正常同步到下游;对于属于table_2的shema V1DML,忽略。 -
解析到达 step 4 时保存的 binlog 位置点,可得知在 step 3 时被忽略的所有 DML 都已经重新同步到下游。
-
继续从 t4 时刻对应的 binlog 位置点正常同步。
从上面的分析可以知道,DM 在处理 sharding DDL 同步时,主要通过两级 sharding group 来进行协调控制,简化的流程为:
-
各 DM-worker 独立地协调对应上游 MySQL 实例内多个分表组成的 sharding group 的 DDL 同步。
-
当 DM-worker 内所有分表的 DDL 都收到时,向 DM-master 发送 DDL 相关信息。
-
DM-master 根据 DM-worker 发来的 DDL 信息,协调由各 DM-worker 组成的 sharing group 的 DDL 同步。
-
当 DM-master 收到所有 DM-worker 的 DDL 信息时,请求 DDL lock 的 owner(某个 DM-worker)执行 DDL。
-
owner 执行 DDL,并将结果反馈给 DM-master;自身开始重新同步在内部协调 DDL 同步过程中被忽略的 DML。
-
当 DM-master 发现 owner 执行 DDL 成功后,请求其他所有 DM-worker 开始继续同步。
-
其他所有 DM-worker 各自开始重新同步在内部协调 DDL 同步过程中被忽略的 DML。
-
所有 DM-worker 在重新同步完成被忽略的 DML 后,继续正常同步。
数据同步过滤
在进行数据同步的过程中,有时可能并不需要将上游所有的数据都同步到下游,这时一般期望能在同步过程中根据某些规则,过滤掉部分不期望同步的数据。在 DM 中,支持 2 种不同级别的同步过滤方式。
库表黑白名单
DM 在 dumper、loader、syncer 三个处理单元中都支持配置规则只同步/不同步部分库或表。
对于 dumper 单元,其实际调用 mydumper 来 dump 上游 MySQL 的数据。比如只期望导出 test 库中的 t1、t2 两个表的数据,则可以为 dumper 单元配置如下规则:
name-of-dump-rule:
extra-args: "-B test -T t1,t2"-
name-of-dump-rule:规则名,用户指定。当有多个上游实例需要使用相同的规则时,可以只定义一条规则,多个不同的实例通过规则名进行引用。 -
extra-args:dumper 单元额外参数。除 dumper 单元中明确定义的配置项外的其他所有 mydumper 配置项都通过此参数传入,格式与使用 mydumper 时一致。
有关 mydumper 对库表黑白名单的支持,可查看 mydumper 的参数及 mydumper 的源码。
对于 loader 和 syncer 单元,其对应的库表黑白名单规则为 black-white-list。假设只期望同步 test 库中的 t1、t2 两个表的数据,则可配置如下规则:
name-of-bwl-rule:
do-tables:
- db-name: "test"
tbl-name: "t1"
- db-name: "test"
tbl-name: "t2"示例中只使用了该规则的部分配置项,完整的配置项及各配置项的含义,可阅读该功能对应的用户文档。DM 中该规则与 MySQL 的主从同步过滤规则类似,因此也可参考 Evaluation of Database-Level Replication and Binary Logging Options 与 Evaluation of Table-Level Replication Options。
对于 loader 单元,在解析 SQL 文件名获得库名表名后,会与配置的黑白名单规则进行匹配,如果匹配结果为不需要同步,则会忽略对应的整个 SQL 文件。对于 syncer 单元,在解析 binlog 获得库名表名后,会与配置的黑白名单规则进行匹配,如果匹配结果为不需要同步,则会忽略对应的(部分)binlog event 数据。
binlog event 过滤
在进行增量数据同步时,有时会期望过滤掉某些特定类型的 binlog event,两个典型的场景包括:
-
上游执行
TRUNCATE TABLE时不希望清空下游表中的数据。 -
上游分表上执行
DROP TABLE时不希望DROP下游合并后的表。
在 DM 中支持根据 binlog event 的类型进行过滤,对于需要过滤 TRUNCATE TABLE 与 DROP TABLE 的场景,可配置规则如下:
name-of-filter-rule:
schema-pattern: "test_*"
table-pattern: "t_*"
events: ["truncate table", "drop table"]
action: Ignore规则的匹配模式与 table router、column mapping 类似,具体的配置项可阅读该功能对应的用户文档。
在实现上,当解析 binlog event 获得库名、表名及 binlog event 类型后,与配置的规则进行匹配,并在匹配后依据 action 配置项来决定是否需要进行过滤。有关 binlog event 过滤功能的具体实现,可以阅读 TiDB-Tools 下的 binlog-filter pkg 源代码。
相关阅读:
TiDB Ecosystem Tools 原理解读系列(一):TiDB Binlog 架构演进与实现原理;
TiDB Ecosystem Tools 原理解读系列(二):TiDB-Lightning Toolset 介绍
目录