
简介
TiDB Binlog 组件用于收集 TiDB 的 binlog,并提供实时备份和同步功能。该组件在功能上类似于 MySQL 的主从复制,MySQL 的主从复制依赖于记录的 binlog 文件,TiDB Binlog 组件也是如此,主要的不同点是 TiDB 是分布式的,因此需要收集各个 TiDB 实例产生的 binlog,并按照事务提交的时间排序后才能同步到下游。如果你需要部署 TiDB 集群的从库,或者想订阅 TiDB 数据的变更输出到其他的系统中,TiDB Binlog 则是必不可少的工具。
架构演进
TiDB Binlog 这个组件已经发布了 2 年多时间,经历过几次架构演进,去年十月到现在大规模使用的是 Kafka 版本,架构图如下:
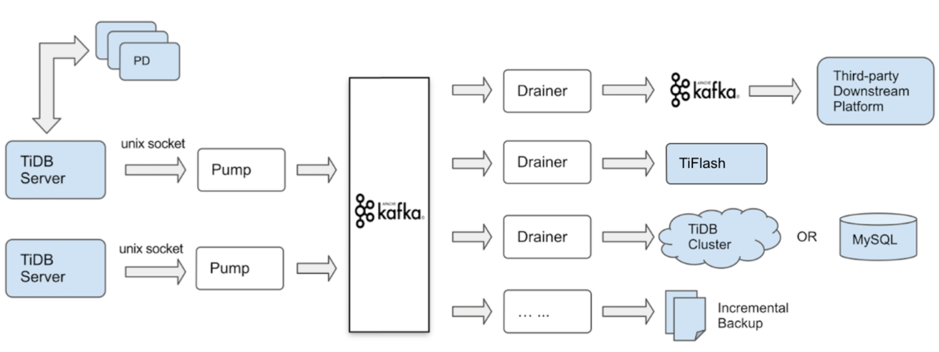
Kafka 版本的 TiDB Binlog 主要包括两个组件:
Pump:一个守护进程,在每个 TiDB 主机的后台运行。其主要功能是实时记录 TiDB 产生的 binlog 并顺序写入 Kafka 中。
Drainer: 从 Kafka 中收集 binlog,并按照 TiDB 中事务的提交顺序转化为指定数据库兼容的 SQL 语句或者指定格式的数据,最后同步到目的数据库或者写到顺序文件。
这个架构的工作原理为:
- TiDB 需要与 Pump 绑定,即 TiDB 实例只能将它生成的 binlog 发送到一个指定的 Pump 中;
- Pump 将 binlog 先写到本地文件,再异步地写入到 Kafka;
- Drainer 从 Kafka 中读出 binlog,对 binlog 进行排序,对 binlog 解析后生成 SQL 或指定格式的数据再同步到下游。
根据用户的反馈,以及我们自己做的一些测试,发现该版本主要存在一些问题。
首先,TiDB 的负载可能不均衡,部分 TiDB 业务较多,产生的 binlog 也比较多,对应的 Pump 的负载高,导致数据同步延迟高。
其次,依赖 Kafka 集群,增加了运维成本;而且 TiDB 产生的单条 binlog 的大小可达 2G(例如批量删除数据、批量写入数据),需要配置 Kafka 的消息大小相关设置,而 Kafka 并不太适合单条数据较大的场景。
最后,Drainer 需要读取 Kafka 中的 binlog、对 binlog 进行排序、解析 binlog,同步数据到下游等工作,可以看出 Drainer 的工作较多,而且 Drainer 是一个单点,所以往往同步数据的瓶颈都在 Drainer。
以上这些问题我们很难在已有的框架下进行优化,因此我们对 TiDB Binlog 进行了重构,最新版本的 TiDB Binlog 的总体架构如下图所示:
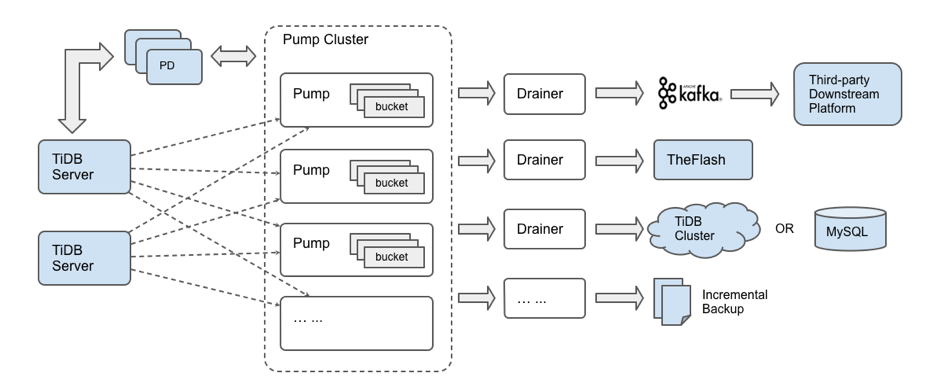
新版本 TiDB Binlog 不再使用 Kafka 存储 binlog,仍然保留了 Pump 和 Drainer 两个组件,但是对功能进行了调整:
- Pump 用于实时记录 TiDB 产生的 binlog,并将 binlog 按照事务的提交时间进行排序,再提供给 Drainer 进行消费。
- Drainer 从各个 Pump 中收集 binlog 进行归并,再将 binlog 转化成 SQL 或者指定格式的数据,最终同步到下游。
该版本的主要优点为:
- 多个 Pump 形成一个集群,可以水平扩容,各个 Pump 可以均匀地承担业务的压力。
- TiDB 通过内置的 Pump Client 将 binlog 分发到各个 Pump,即使有部分 Pump 出现故障也不影响 TiDB 的业务。
- Pump 内部实现了简单的 kv 来存储 binlog,方便对 binlog 数据的管理。
- 原来 Drainer 的 binlog 排序逻辑移到了 Pump 来做,而 Pump 是可扩展的,这样就能提高整体的同步性能。
- Drainer 不再需要像原来一样读取一批 binlog 到内存里进行堆排序,只需要依次读取各个 Pump 的 binlog 进行归并排序,这样可以大大节省内存的使用,同时也更容易做内存控制。
由于该版本最大的特点是多个 Pump 组成了一个集群(cluster),因此该版本命名为 cluster 版本。下面我们以最新的 cluster 版本的架构来介绍 TiDB Binlog 的实现原理。
工作原理
binlog
首先我们先介绍一下 TiDB 中的 binlog,TiDB 的事务采用 2pc 算法,一个成功的事务会写两条 binlog,包括一条 Prewrite binlog 和 一条 Commit binlog;如果事务失败,会发一条 Rollback binlog。
binlog 的结构定义为:
// Binlog 记录事务中所有的变更,可以用 Binlog 构建 SQL
message Binlog {
// Binlog 的类型,包括 Prewrite、Commit、Rollback 等
optional BinlogType tp = 1 [(gogoproto.nullable) = false];
// Prewrite, Commit 和 Rollback 类型的 binlog 的 start_ts,记录事务开始的 ts
optional int64 start_ts = 2 [(gogoproto.nullable) = false];
// commit_ts 记录事务结束的 ts,只记录在 commit 类型的 binlog 中
optional int64 commit_ts = 3 [(gogoproto.nullable) = false];
// prewrite key 只记录在 Prewrite 类型的 binlog 中,
// 是一个事务的主键,用于查询该事务是否提交
optional bytes prewrite_key = 4;
// prewrite_value 记录在 Prewrite 类型的 binlog 中,用于记录每一行数据的改变
optional bytes prewrite_value = 5;
// ddl_query 记录 ddl 语句
optional bytes ddl_query = 6;
// ddl_job_id 记录 ddl 的 job id
optional int64 ddl_job_id = 7 [(gogoproto.nullable) = false];
}binlog 及相关的数据结构定义见:binlog.proto
其中 start_ts 为事务开始时的 ts,commit_ts 为事务提交的 ts。ts 是由物理时间和逻辑时间转化而成的,在 TiDB 中是唯一的,由 PD 来统一提供。在开始一个事务时,TiDB 会请求 PD,获取一个 ts 作为事务的 start_ts,在事务提交时则再次请求 PD 获取一个 ts 作为 commit_ts。 我们在 Pump 和 Drainer 中就是根据 binlog 的 commit_ts 来对 binlog 进行排序的。
TiDB 的 binlog 记录为 row 模式,即保存每一行数据的改变。数据的变化记录在 prewrite_value 字段中,该字段的数据主要由序列化后的 TableMutation 结构的数据组成。TableMutation 的结构如下所示:
// TableMutation 存储表中数据的变化
message TableMutation {
// 表的 id,唯一标识一个表
optional int64 table_id = 1 [(gogoproto.nullable) = false];
// 保存插入的每行数据
repeated bytes inserted_rows = 2;
// 保存修改前和修改后的每行的数据
repeated bytes updated_rows = 3;
// 已废弃
repeated int64 deleted_ids = 4;
// 已废弃
repeated bytes deleted_pks = 5;
// 删除行的数据
repeated bytes deleted_rows = 6;
// 记录数据变更的顺序
repeated MutationType sequence = 7;
}下面以一个例子来说明 binlog 中是怎么存储数据的变化的。
例如 table 的结构为:
create table test (id int, name varchar(24), primary key id)
按照顺序执行如下 SQL:
begin;
insert into test(id, name) values(1, "a");
insert into test(id, name) values(2, "b");
update test set name = "c" where id = 1;
update test set name = "d" where id = 2;
delete from test where id = 2;
insert into test(id, name) values(2, "c");
commit;则生成的 TableMutation 的数据如下所示:
inserted_rows:
1, "a"
2, "b"
2, "c"
updated_rows:
1, "a", 1, "c"
2, "b", 2, "d"
deleted_rows:
2, "d"
sequence:
Insert, Insert, Update, Update, DeleteRow, Insert可以从例子中看出,sequence 中保存的数据变更类型的顺序为执行 SQL 的顺序,具体变更的数据内容则保存到了相应的变量中。
Drainer 在把 binlog 数据同步到下游前,就需要把上面的这些数据还原成 SQL,再同步到下游。
另外需要说明的是,TiDB 在写 binlog 时,会同时向 TiKV 发起写数据请求和向 Pump 发送 Prewrite binlog,如果 TiKV 和 Pump 其中一个请求失败,则该事务失败。当 Prewrite 成功后,TiDB 向 TiKV 发起 Commit 消息,并异步地向 Pump 发送一条 Commit binlog。由于 TiDB 是同时向 TiKV 和 Pump 发送请求的,所以只要保证 Pump 处理 Prewrite binlog 请求的时间小于等于 TiKV 执行 Prewrite 的时间,开启 binlog 就不会对事务的延迟造成影响。
Pump Client
从上面的介绍中我们知道由多个 Pump 组成一个集群,共同承担写 binlog 的请求,那么就需要保证 TiDB 能够将写 binlog 的请求尽可能均匀地分发到各个 Pump,并且需要识别不可用的 Pump,及时获取到新加入集群中 Pump 信息。这部分的工作是在 Pump Client 中实现的。
Pump Client 以包的形式集成在 TiDB 中,代码链接:pump_client。
Pump Client 维护 Pump 集群的信息,Pump 的信息主要来自于 PD 中保存的 Pump 的状态信息,状态信息的定义如下(代码链接:Status):
type Status struct {
// Pump/Drainer 实例的唯一标识
NodeID string json:"nodeId"
// Pump/Drainer 的服务地址
Addr string json:"host"
// Pump/Drainer 的状态,值可以为 online、pausing、paused、closing、offline
State string json:"state"
// Pump/Drainer 是否 alive(目前没有使用该字段)
IsAlive bool json:"isAlive"
// Pump的分数,该分数是由节点的负载、磁盘使用率、存储的数据量大小等因素计算得来的,
// 这样 Pump Client 可以根据分数来选取合适的 Pump 发送 binlog(待实现)
Score int64 json:"score"
// Pump 的标签,可以通过 label 对 TiDB 和 Pump 进行分组,
// TiDB 只能将 binlog 发送到相同 label 的 Pump(待实现)
Label *Label json:"label"
// Pump: 保存的 binlog 的最大的 commit_ts
// Drainer:已消费的 binlog 的最大的 commit_ts
MaxCommitTS int64 json:"maxCommitTS"
// 该状态信息的更新时间对应的 ts.
UpdateTS int64 json:"updateTS"
}Pump Client 根据 Pump 上报到 PD 的信息以及写 binlog 请求的实际情况将 Pump 划分为可用 Pump 与不可用 Pump 两个部分。
划分的方法包括:
- 初始化时从 PD 中获取所有 Pump 的信息,将状态为 online 的 Pump 加入到可用 Pump 列表中,其他 Pump 加入到非可用列表中。
- Pump 每隔固定的时间会发送心跳到 PD,并更新自己的状态。Pump Client 监控 PD 中 Pump 上传的状态信息,及时更新内存中维护的 Pump 信息,如果状态由非 online 转换为 online 则将该 Pump 加入到可用 Pump 列表;反之加入到非可用列表中。
- 在写 binlog 到 Pump 时,如果该 Pump 在重试多次后仍然写 binlog 失败,则把该 Pump 加入到非可用 Pump 列表中。
- 定时发送探活请求(数据为空的 binlog 写请求)到非可用 Pump 列表中的状态为 online 的 Pump,如果返回成功,则把该 Pump 重新加入到可用 Pump 列表中。
通过上面的这些措施,Pump Client 就可以及时地更新所维护的 Pump 集群信息,保证将 binlog 发送到可用的 Pump 中。
另外一个问题是,怎么保证 Pump Client 可以将 binlog 写请求均匀地分发到各个 Pump?我们目前提供了几种路由策略:
- range: 按照顺序依次选取 Pump 发送 binlog,即第一次选取第一个 Pump,第二次选取第二个 Pump...
-
hash:对 binlog 的
start_ts进行 hash,然后选取 hash 值对应的 Pump。 - score:根据 Pump 上报的分数按照加权平均算法选取 Pump 发送 binlog(待实现)。
需要注意的地方是,以上的策略只是针对 Prewrite binlog,对于 Commit binlog,Pump Client 会将它发送到对应的 Prewrite binlog 所选择的 Pump,这样做是因为在 Pump 中需要将包含 Prewrite binlog 和 Commit binlog 的完整 binlog(即执行成功的事务的 binlog)提供给 Drainer,将 Commit binlog 发送到其他 Pump 没有意义。
Pump Client 向 Pump 提交写 binlog 的请求接口为 pump.proto 中的 WriteBinlog,使用 grpc 发送 binlog 请求。
Pump
Pump 主要用来承担 binlog 的写请求,维护 binlog 数据,并将有序的 binlog 提供给 Drainer。我们将 Pump 抽象成了一个简单的 kv 数据库,key 为 binlog 的 start _ts(Priwrite binlog) 或者 commit_ts(Commit binlog),value 为 binlog 的元数据,binlog 的数据则存在数据文件中。Drainer 像查数据库一样的来获取所需要的 binlog。
Pump 内置了 leveldb 用于存储 binlog 的元信息。在 Pump 收到 binlog 的写请求时,会首先将 binlog 数据以 append 的形式写到文件中,然后将 binlog 的 ts、类型、数据长度、所保存的文件以及在文件中的位置信息保存在 leveldb 中,如果为 Prewrite binlog,则以 start_ts作为 key;如果是 Commit binlog,则以 commit_ts 作为 key。
当 Drainer 向 Pump 请求获取指定 ts 之后的 binlog 时,Pump 则查询 leveldb 中大于该 ts 的 binlog 的元数据,如果当前数据为 Prewrite binlog,则必须找到对应的 Commit binlog;如果为 Commit binlog 则继续向前推进。这里有个问题,在 binlog 一节中提到,如果 TiKV 成功写入了数据,并且 Pump 成功接收到了 Prewrite binlog,则该事务就提交成功了,那么如果在 TiDB 发送 Commit binlog 到 Pump 前发生了一些异常(例如 TiDB 异常退出,或者强制终止了 TiDB 进程),导致 Pump 没有接收到 Commit binlog,那么 Pump 中就会一直找不到某些 Prewrite binlog 对应的 Commit binlog。这里我们在 Pump 中做了处理,如果某个 Prewrite binlog 超过了十分钟都没有找到对应的 Commit binlog,则通过 binlog 数据中的 prewrite_key 去查询 TiKV 该事务是否提交,如果已经提交成功,则 TiKV 会返回该事务的 commit_ts;否则 Pump 就丢弃该条 Prewrite binlog。
binlog 元数据中提供了数据存储的文件和位置,可以通过这些信息读取 binlog 文件的指定位置获取到数据。因为 binlog 数据基本上是按顺序写入到文件中的,因此我们只需要顺序地读 binlog 文件即可,这样就保证了不会因为频繁地读取文件而影响 Pump 的性能。最终,Pump 以 commit_ts 为排序标准将 binlog 数据传输给 Drainer。Drainer 向 Pump 请求 binlog 数据的接口为 pump.proto 中的 PullBinlogs,以 grpc streaming 的形式传输 binlog 数据。
值得一提的是,Pump 中有一个 fake binlog 机制。Pump 会定时(默认三秒)向本地存储中写入一条数据为空的 binlog,在生成该 binlog 前,会向 PD 中获取一个 ts,作为该 binlog 的 start_ts 与 commit_ts,这种 binlog 我们叫作 fake binlog。这样做的原因在 Drainer 中介绍。
Drainer
Drainer 从各个 Pump 中获取 binlog,归并后按照顺序解析 binlog、生成 SQL 或者指定格式的数据,然后再同步到下游。
既然要从各个 Pump 获取数据,Drainer 就需要维护 Pump 集群的信息,及时获取到新增加的 Pump,并识别出不可用的 Pump,这部分功能与 Pump Client 类似,Drainer 也是通过 PD 中存储的 Pump 的状态信息来维护 Pump 信息。另外需要注意的是,如果新增加了一个 Pump,必须让该 Pump 通知 Drainer 自己上线了,这么做是为了保证不会丢数据。例如:
集群中已经存在 Pump1 和 Pump2,Drainer 读取 Pump1 和 Pump2 的数据并进行归并:
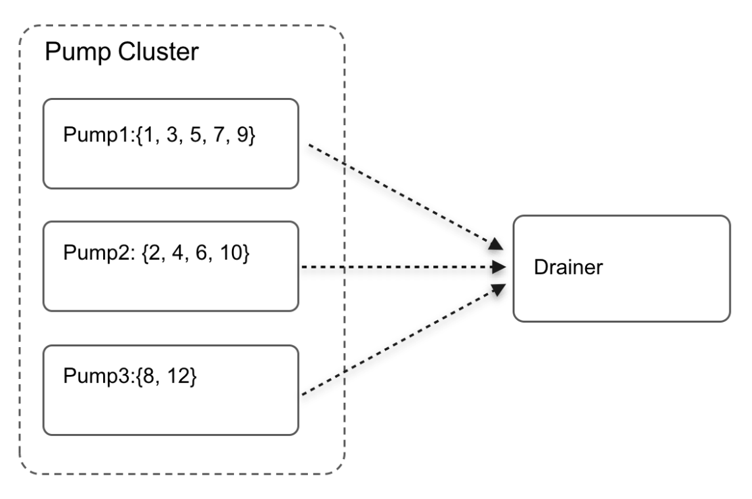
Pump1 存储的 binlog 为{ 1,3,5,7,9 },Pump2 存储的 binlog 为{2,4,6,10}。Drainer 从两个 Pump 获取 binlog,假设当前已经读取到了{1,2,3,4,5,6,7}这些 binlog,已处理的 binlog 的位置为 7。此时 Pump3 加入集群,从 Pump3 上报自己的上线信息到 PD,到 Drainer 从 PD 中获取到 Pump3 信息需要一定的时间,如果 Pump3 没有通知 Drainer 就直接提供写 binlog 服务,写入了 binlog{8,12},Drainer 在此期间继续读取 Pump1 和 Pump2 的 binlog,假设读取到了 9,之后才识别到了 Pump3 并将 Pump3 加入到归并排序中,此时 Pump3 的 binlog 8 就丢失了。为了避免这种情况,需要让 Pump3 通知 Drainer 自己已经上线,Drainer 收到通知后将 Pump3 加入到归并排序,并返回成功给 Pump3,然后 Pump3 才能提供写 binlog 的服务。
Drainer 通过如上所示的方式对 binlog 进行归并排序,并推进同步的位置。那么可能会存在这种情况:某个 Pump 由于一些特殊的原因一直没有收到 binlog 数据,那么 Drainer 中的归并排序就无法继续下去,正如我们用两条腿走路,其中一只腿不动就不能继续前进。我们使用 Pump 一节中提到的 fake binlog 的机制来避免这种问题,Pump 每隔指定的时间就生成一条 fake binlog,即使某些 Pump 一直没有数据写入,也可以保证归并排序正常向前推进。
Drainer 将所有 Pump 的数据按照 commit_ts 进行归并排序后,将 binlog 数据传递给 Drainer 中的数据解析及同步模块。通过上面的 binlog 格式的介绍,我们可以看出 binlog 文件中并没有存储表结构的信息,因此需要在 Drainer 中维护所有库和表的结构信息。在启动 Drainer 时,Drainer 会请求 TiKV,获取到所有历史的 DDL job 的信息,对这些 DDL job 进行过滤,使用 Drainer 启动时指定的 initial-commit-ts(或者 checkpoint 中保存的 commit_ts)之前的 DDL 在内存中构建库和表结构信息。这样 Drainer 就有了一份 ts 对应时间点的库和表的快照,在读取到 DDL 类型的 binlog 时,则更新库和表的信息;读取到 DML 类型的 binlog 时,则根据库和表的信息来生成 SQL。
在生成 SQL 之后,就可以同步到下游了。为了提高 Drainer 同步的速度,Drainer 中使用多个协程来执行 SQL。在生成 SQL 时,我们会使用主键/唯一键的值作为该条 SQL 的 key,通过对 key 进行 hash 来将 SQL 发送到对应的协程中。当每个协程收集到了足够多的 SQL,或者超过了一定的时间,则将这一批的 SQL 在一个事务中提交到下游。
但是有些 SQL 是相关的,如果被分到了不同的协程,那 SQL 的执行顺序就不能得到保证,造成数据的不一致。例如:
SQL1: delete from test.test where id = 1;
SQL2: replace into test.test (id, name ) values(1, "a");按照顺序执行后表中存在 id = 1 该行数据,如果这两条 SQL 分别分配到了协程 1 和协程 2 中,并且协程 2 先执行了 SQL,则表中不再存在 id = 1 的数据。为了避免这种情况的发生,Drainer 中加入了冲突检测的机制,如果检测出来两条 SQL 存在冲突(修改了同一行数据),则暂时不将后面的 SQL 发送到协程,而是生成一个 Flush 类型的 job 发送到所有的协程, 每个协程在遇到 Flush job 时就会马上执行所缓存的 SQL。接着才会把该条有冲突的 SQL 发送到对应的协程中。下面给出一个例子说明一下冲突检测的机制:
有以下这些 SQL,其中 id 为表的主键:
SQL1: update itest set id = 4, name = "c", age = 15 where id = 3; key: 3, 4
SQL2: update itest set id = 5, name = "b", age = 14 where id = 2; key:5, 2
SQL3:delete from itest where id = 3; key: 3- 首先将 SQL1 发送到指定的协程,这时所有的 keys 为[3,4];
- SQL2 的 key[5,2]与 keys 中的[3,4]都没有冲突,将 SQL2 发送到指定的协程,这时 keys 为[3,4,5,2];
- SQL3 的 key[3]与 keys 中的[3]存在冲突,发送 Flush job 到所有协程,SQL1 和 SQL2 被执行,清空 keys;
- 将 SQL3 发送到指定的协程,同时更新 keys 为[3]。
Drainer 通过以上这些机制来高效地同步数据,并且保证数据的一致。
总结
TiDB Binlog 是 TiDB 生态的重要工具,通过该工具来实现 TiDB 集群的主从复制、数据订阅。我们将持续提升该工具的稳定性、易用性、可靠性。
相关阅读:
TiDB Ecosystem Tools 原理解读系列(二)TiDB-Lightning Toolset 介绍;
TiDB Ecosystem Tools 原理解读系列(三)TiDB Data Migration 架构设计与实现原理
目录