
本文作者:
邵 健|杭州银行股份有限公司数据库专家
张显华丨杭州银行股份有限公司数据库专家
导读
本文探讨了金融企业区域集中库的设计构想和测试验证,包括架构设想、数据库整合场景测试及优势和使用设想。作者提出利用 TiDB 数据库产品集中建设区域集中库,解决 MySQL 存量节点的整合问题,实现部署的标准化、按需扩展和统一运维管理。文章详细介绍了测试内容和结果,强调了区域集中库在建设和运行成本、服务质量等方面的优势,并提出了相应的管理措施,为金融企业数据库架构提供了有价值的参考。
区域集中库的架构设想
在银行等金融企业的网络设计中,会根据服务主题将内部网络分割成若干个网络安全域,如:核心网络域、网银网络域等。在各个网络域中,根据业务应用对数据库的需求配置资源。随着业务的创新和发展,MySQL 存量节点多,管理难度大,资源利用率低,背离了规模部署、高效运维、敏态供给的云化发展理念,在生产运行的各阶段中存在不少的能力短板,比如:
- 部署建设阶段
- 以业务发展目标或者每日批量压力高峰进行数据库资源规格评估,可能存在资源浪费和发展不同步的可能性。
- 不同的版本、部署方案、变量参数和管理平台共存, 配置的碎片化不利于团队知识管理,阻碍标准化发展。
- 生产运行阶段
- 应用数模设计阶段缺少主键约束造成主从同步延迟,影响从库数据时效,高可用机制可能存在不稳定。
- 业务应用重复订阅全行统一的人员、机构和客户等主数据推送,浪费存储容量,占用数据库和网络资源。
- 数据库面对下游业务的数据供给需求,复制链路构成较为复杂的网状结构,管理和维护成本较高,客户上限制了数据价值的进一步挖掘。
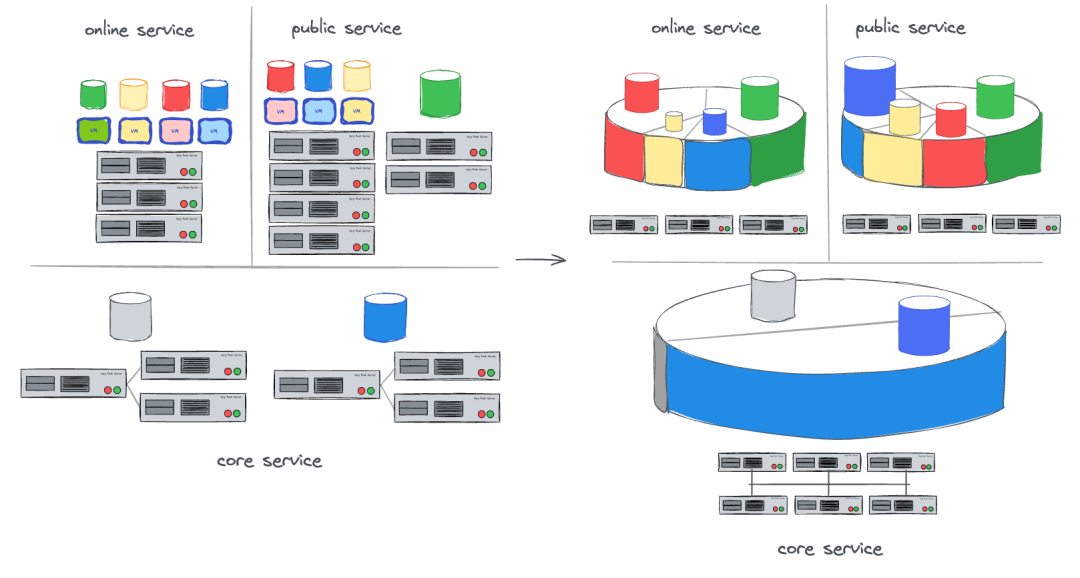
TiDB 数据库产品具备良好的水平扩展能力,能满足高并发大数据量业务的使用需求。通过 resource control 特性可划分集群资源,承载不同的业务应用。设想在单个网络域中集中建设一套 TiDB 集群,进行当前业务的迁移,整合替代“孤岛式”的 MySQL 集群(见图一),实现部署的标准化、按需扩展和统一运维管理。
数据库整合场景测试
基于网络区域集中库的设计构想,进行实际整合场景的需求抽象,使用 TiDB 做为测试平台,验证在分布式数据库上快速创建不同规格的数据库服务以提高设备利用率,并通过标准化高可用等管理体系降低总体成本。
资源管控
Request Unit (RU) 是对 CPU、IO 等系统资源的统一抽象的计量单位,用于表示对单个请求消耗的资源量。请求消耗的 RU 数量取决于多种因素,例如操作类型或正在检索或修改的数据量。
- 集群资源的评估
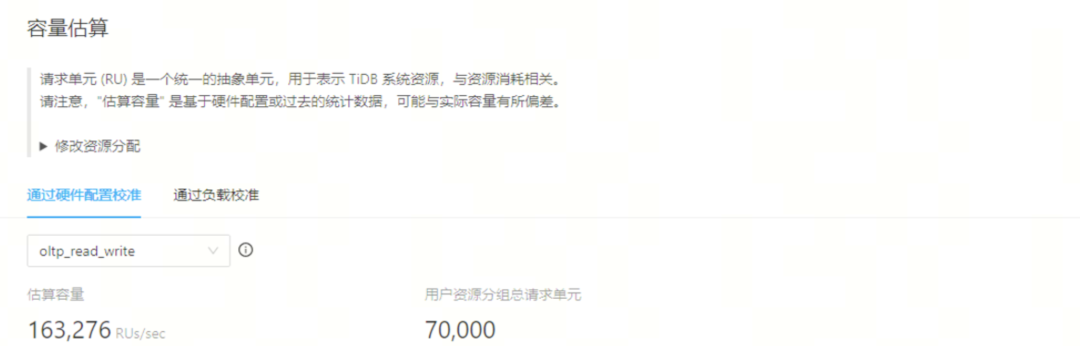
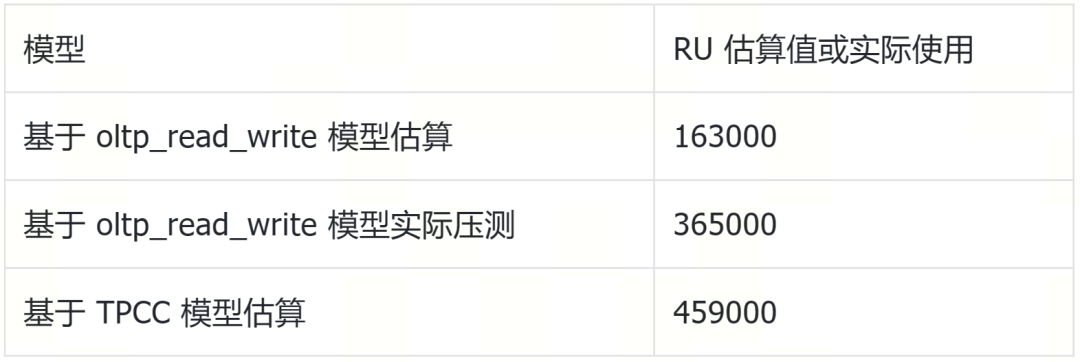
测试集群配置为三台两路 ARM 服务器。使用 oltp_read_write 模型估算集群的 RU 上限为 163000 RU(见图二)。
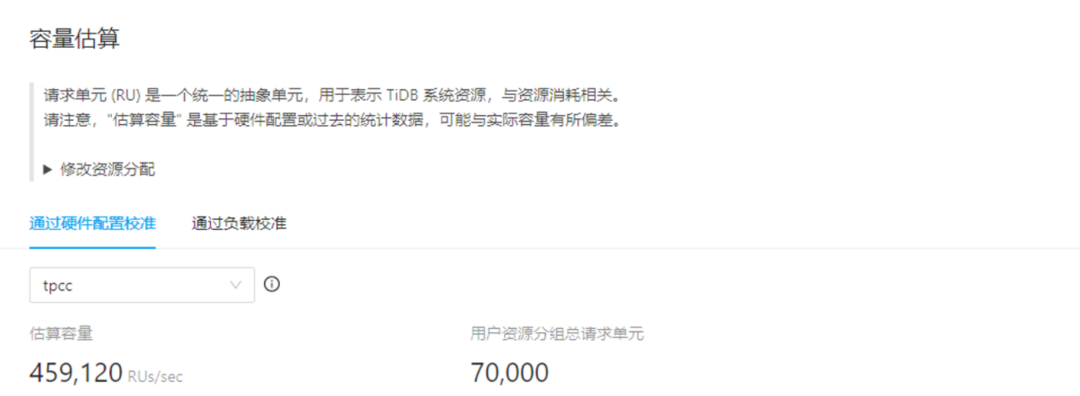
使用 TPCC 模型估算为 459000 RU(见图三)。
使用 root 用户进行 oltp_read_write 模型高并发压测可得集群最大 RU 365000(图四)。
三种评估方法结果(见表一)表明,估算和实际的差距较大,估算方法需要改进。
- 不同规格 RU 对联机交易的影响
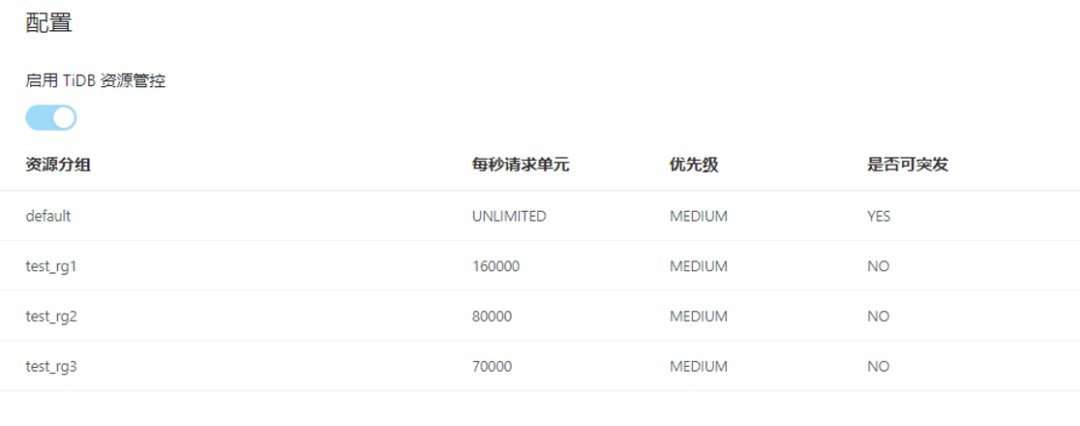
配置三个资源组的每秒 RU 参数 (见图五),数据库用户归属于资源组后,每秒使用的 RU 上限受该参数控制。
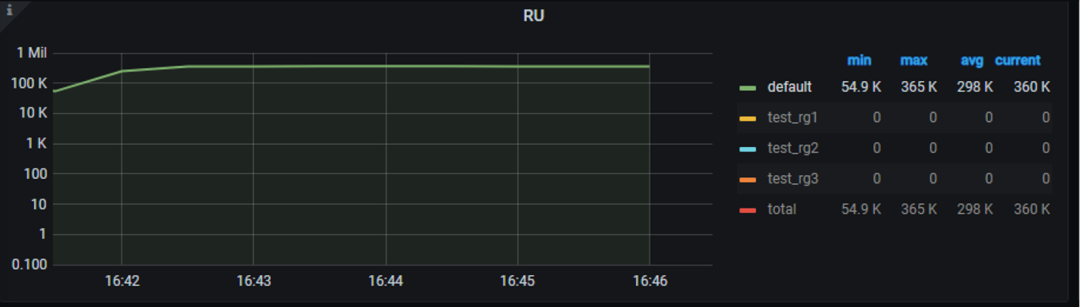
三个用户对应三个资源组同时压测,RU 使用平稳(见图六)。
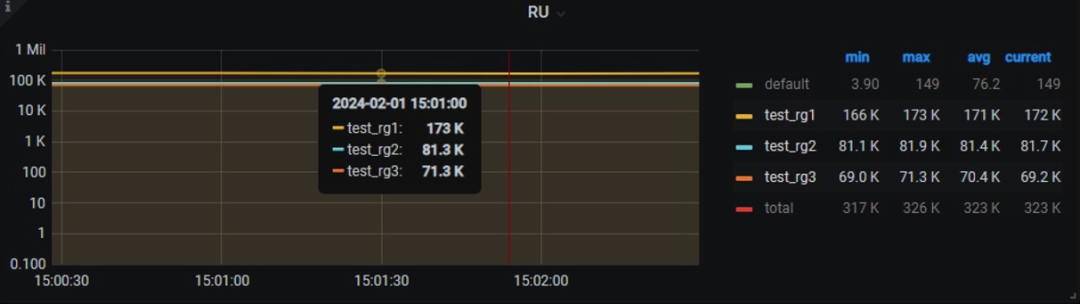
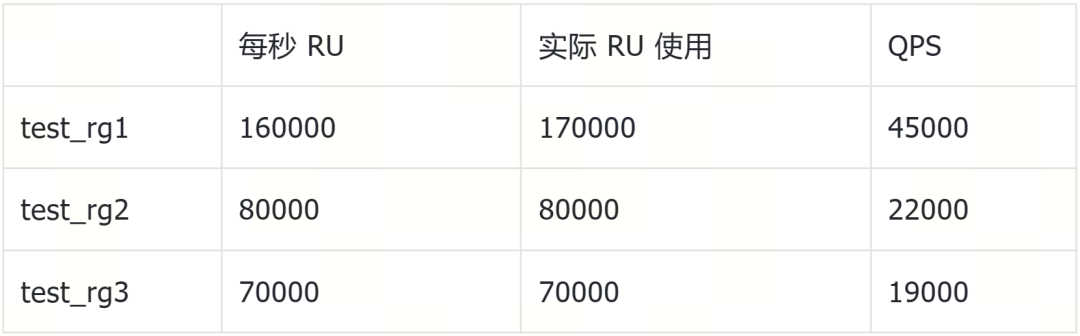
压测结果(见表二)表明,实际使用上限基本符合配置,QPS 与 RU 成正比关系,符合配置规则。
- 资源组 BURSTABLE 属性对调度的影响
配置资源组 test_rg1 启用可突发(BURSTABLE)属性(见图七),当系统资源闲置时,该资源组可以超出上限。
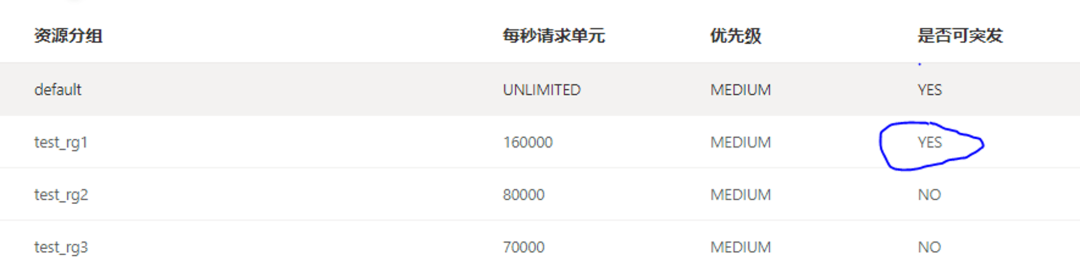
先发起 test_rg1 资源组中用户的压测,RU 使用达到了 293000 左右,体现 burstable 参数在集群空闲状态下的配置效果,再发起另外两个资源组的压测,test_rg1 逐步回落到资源组配置上限 160000 左右(见图八)。
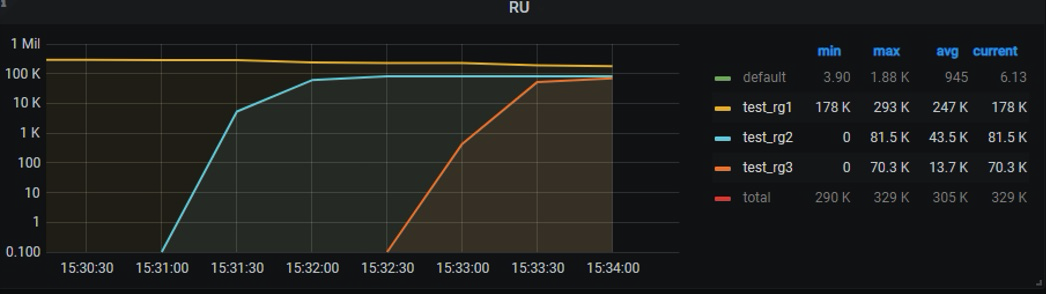
压测结果(见表三)表明,BURSTABLE 属性可以充分利用闲置资源。繁忙时,会优先保证上限内的 RU 分配。

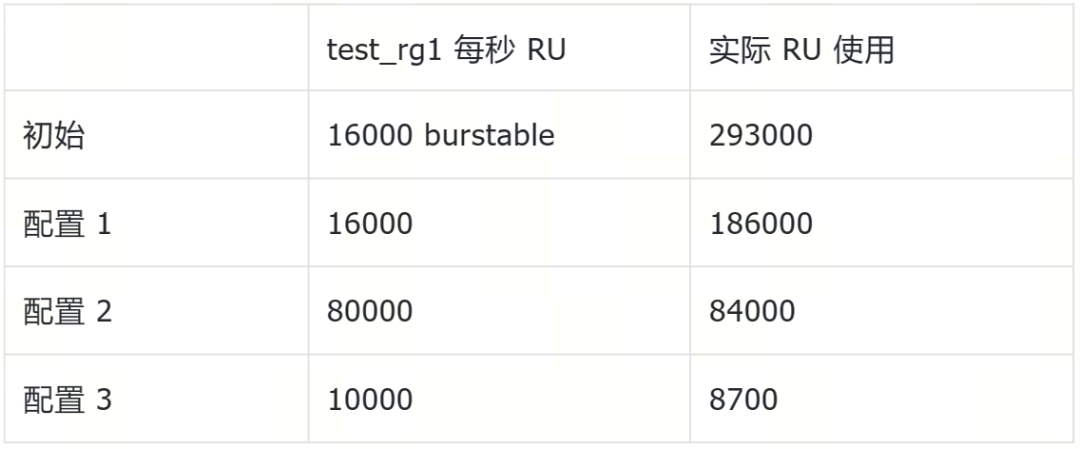
- 在线调整 RU 对联机交易的影响
发起 test_rg1 组中用户的压测,在线调整资源组的每秒 RU 值,即时反应到实际 RU 使用(见图九)。
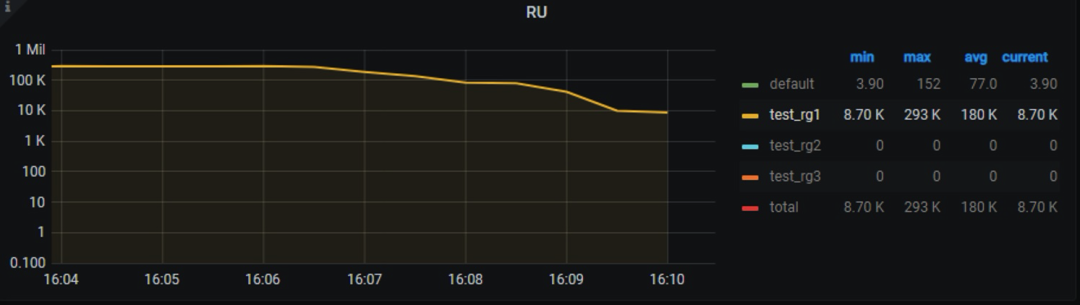
压测结果(见表四)表明,资源组配置变更即时反应到业务的 QPS 上。
读写分离
在 MySQL 架构中,为防止对业务主交易造成影响,将从库用于数据抽取、异步检查等只读场景。区域集中库也需要实现等同于读写分离的隔离效果,分布式数据库配置 Learner 角色,只参与同步数据而不参与多数派投票。
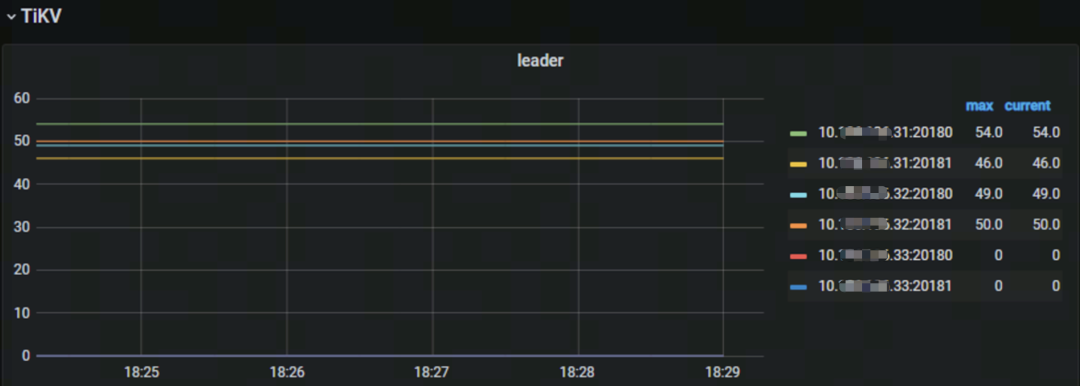
使用 Placement Rules 将 33 节点的 TiKV 实例标签配置为 Learner 数据副本,监控中对应实例的 Leader 数量为 0(见图十),只同步数据,不响应交易的读写请求。
- 会话的读写分离
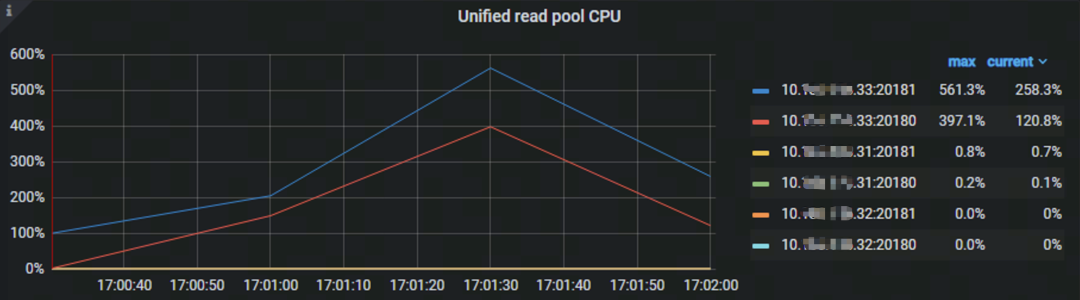
设置变量 set session tidb_replica_read=‘learner',执行查询 SQL 时只使用 33 节点的资源(见图十一)。
- 物理备份的读写分离
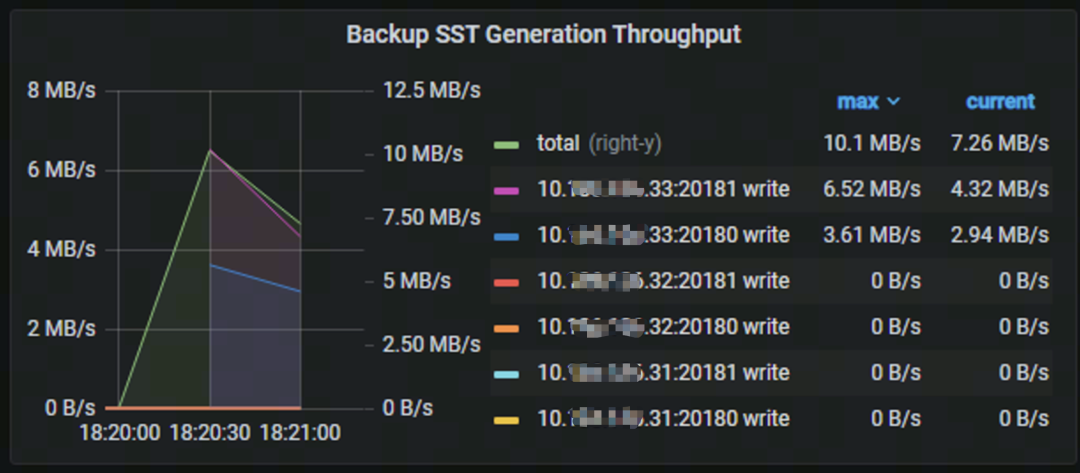
使用 --replica-read-label 参数执行 br 备份命令,只使用 33 节点写入备份文件(见图十二)。
业务管理
多业务整合的场景中,不仅需要关注资源开销,还需要关注数据库的业务管理特性,比如 SQL 黑名单、细粒度监控、连接标识等,提升管理员的运维效率。
SQL 黑名单功能
- 资源组的自动策略
配置 default 资源组属性 query_limit=(exec_elapsed='100s', action=kill,watch=similar ),实现语句执行超过 100s 后自动 kill。慢 SQL 语句执行超时后被 kill(测试效果如下),说明自动策略可以支持慢 SQL 的自动化管理。
MySQL> select now();select *,(select max(c) from sbtest2 where sbtest1.c=sbtest2.c group by id ) avgc from sbtest1 where sbtest1.id< 5000;select now();
+---------------------+
| now() |
+---------------------+
| 2024-02-05 15:33:15 |
+---------------------+
1 row in set (0.000 sec)
ERROR 1105 (HY000): other error: Coprocessor task terminated due to exceeding the deadline
+---------------------+
| now() |
+---------------------+
| 2024-02-05 15:34:55 |
+---------------------+
1 row in set (0.000 sec)- 手工配置黑名单
配置 query watch 清单 query watch add action kill sql digest 'DIGEST 值'中。SQL 语句执行后提示被中断(测试效果如下),说明可以支持慢 SQL 的手工管理。
MysQL> select *,(select max(c) from sbtest2 where sbtest1.c=sbtest2.c group by id ) avgc from sbtest1 where sbtest1.id< 100;
ERROR 8254 (HY000): Quarantined and interrupted because of being in runaway watch list查询验证限制记录(测试效果如下),说明可分析黑名单生效记录。
MySQL> select * from mysq1.tidb_runaway_queries order_by time desc limit 1\G
*************************** 1. row ***************************
resource_group_name: default
time: 2024-02-05 14:57:37
match_type: watch
action: ki11
original_sq1: select *,(select max(c) from sbtest2 where sbtest1.c=sbtest2.c group by id ) avgc from sbtest1 where sbtest1.id< 100
plan_digest: 85484f90b715278bd114095a4bbbe168da158f24e824a04d11c09be7268fe2ab tidb_server: 10.186.136.31:4000
1 row in set (0.002 sec)业务会话标识功能
- 会话变量
会话变量 tidb_session_alias 可动态定义会话中业务标识,如当前运行的交易码信息,会话视图、慢日志及 General log 的 session_alias 列中会记录运行值,类似 Oracle 数据库 v$session 的 module 列可以帮助识别应用程序功能模块信息。
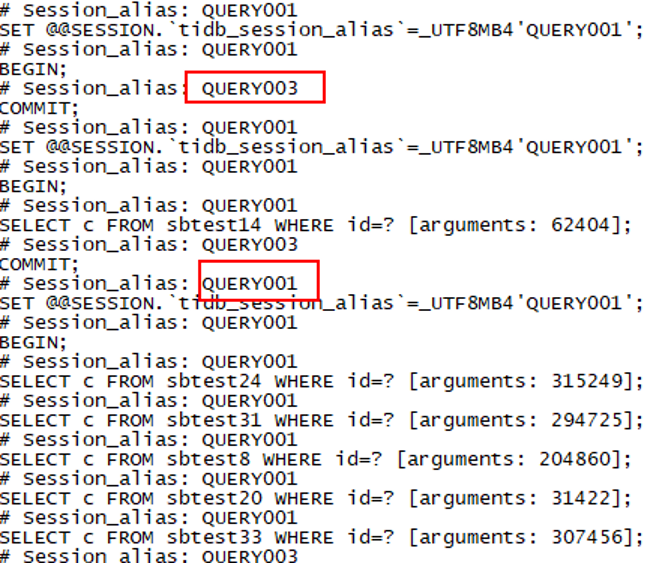
编辑测试描述文件 oltp_read_write.lua,添加 con:query("set tidb_session_alias='QUERYXXX'"),模拟应用切换交易码。慢日志(见图十三)和 processlist 视图(见图十四)中 session_alias 标识 SQL,可分析 SQL 语句的业务行为。

- 会话属性
系统视图 session_connect_attrs 可查看连接的固定属性信息,数据库侧可用于梳理应用的自定义连接信息。配置连接串参数 connectionAttributes=app_name:bank,ver:v1.0&(见图十五)或者使用 JDBC 内置方法,实现应用版本等标识。
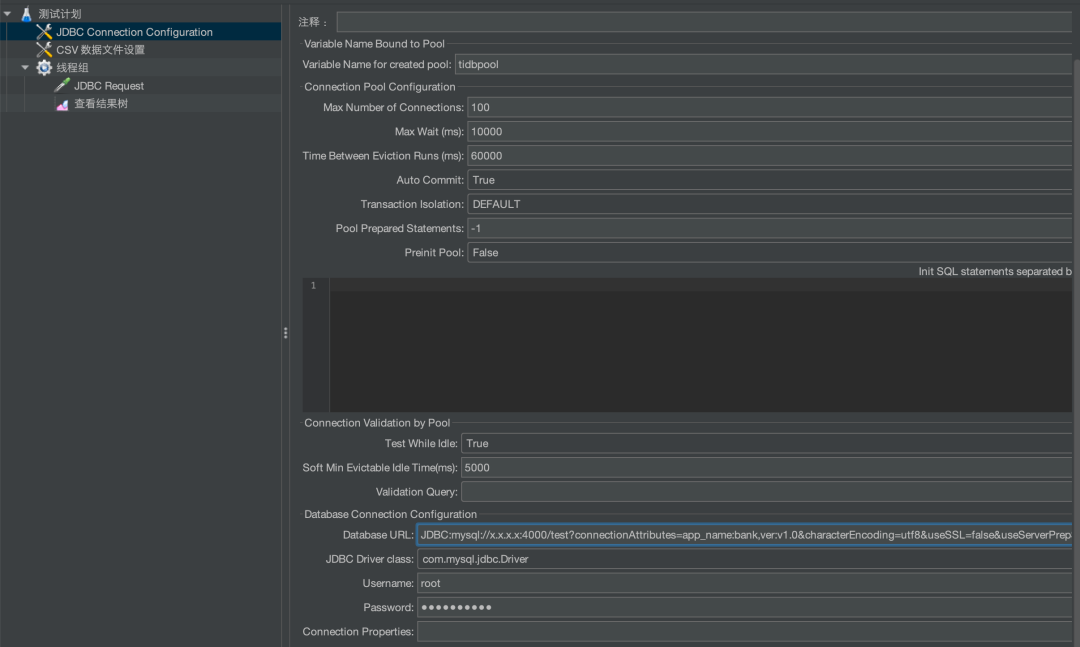
系统视图 session_connect_attrs 可查看应用的自定义属性(见图十六),说明可分析客户端信息。
细粒度监控功能
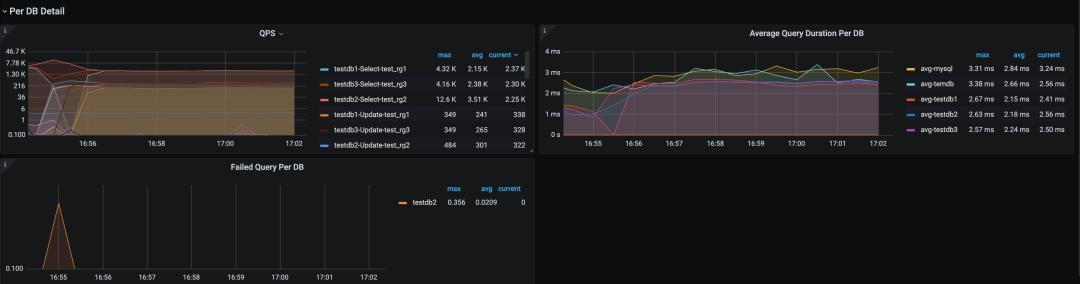
配置 record-db-label 可以在 db 和 resource_group 粒度上提供 QPS、Duration 等 metrics 指标,在 grafana 添加监控面板(见图十七)。
测试小结
通过以上的测试,基本上验证了利用分布式数据库实现区域集中库的设想:
- 资源隔离特性具备数据库规格限制,支持用户、会话及语句等粒度。在线调整即时生效的特点,可以基于不同业务资源消耗的时间窗口进行资源“调度”,实现资源利用效益最大化。
- Learner 角色副本可用于数据抽取、查询和备份等场景,保证生产隔离,节省“从集群”的资源开销。
- 通过规则和已知的 SQL 指纹对不良 SQL 能实现有效防范。
- 通过业务会话标识和细粒度监控功能,基本满足应用整合后的观测需求。
- 集群 RU 评估方法、Query Limit 策略添加扫描行数或 RU 资源使用监控、资源组添加时间计划等有待继续改进。
区域集中库的优势和使用设想
区域集中库是将数据库整合落地在数据库层,通过标准化部署和细粒度资源配置,得到更高的服务可用性、规格弹性和资源利用率。两种整合方式的适用情况对比如表五。
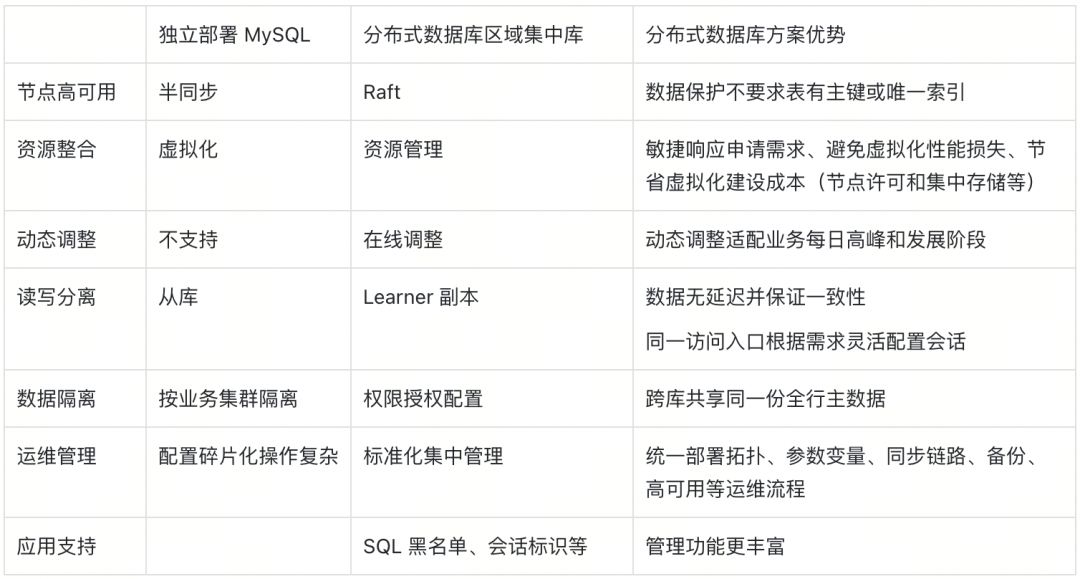
综合各个能力项对比结果,评估区域集中库在建设和运行成本、服务质量上均具有较大的优势。在使用过程中,需要配套管理措施:
- 开发建设典型业务压测模型(如转账交易)作为标尺,根据该模型得到集群交易性能上限,按典型业务性能设计成多个规格,再由需求方根据该模型评估业务交易性能需求规格和业务批量窗口特点进行对接。
- 统一管理区域集中库的全行主数据,数据团队只需要接入一次数据,实现资源集约使用。
- 利用单副本的 Learner 节点实现读写分离,对接备份、ETL 抽取、数据查询平台等非业务的数据需求。
- 与行内的低代码开发平台进行对接,通过框架的配置功能使用数据库的会话属性和业务会话标识功能,实现更加有效的 SQL 定位和管理。
- 引导应用运维自助查看资源组监控和细粒度日志。
通过区域集中库的建设整合,将简化数据库能力分层模型(图十八)。
- 第一层关键业务使用两地三中心的分布式数据库。
- 第二层高并发大数据量业务使用独立的分布式数据库。
- 第三层规模较小或者业务发展规模较灵活的业务使用区域集中库。
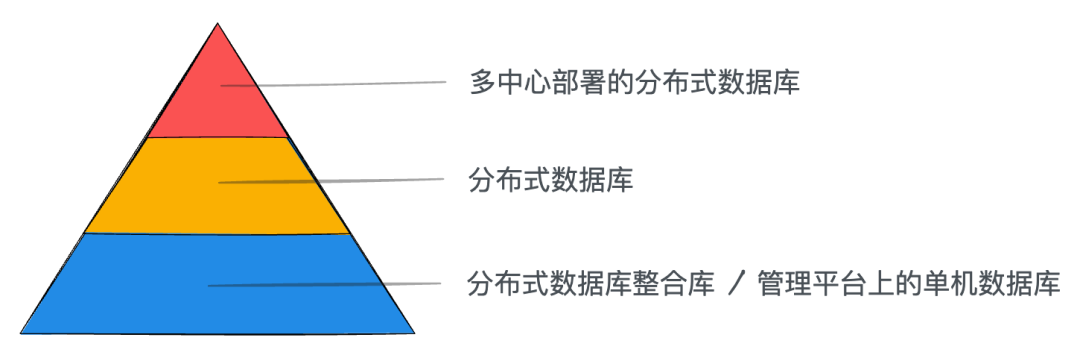
通过区域集中库的建设,实现数据库部署架构的收敛。在此基础上,可进一步对业务数据操作行为的采集和分析,有利于生产运行向智能化转型。
延展阅读:
- 金融行业内容专区上线,为金融机构数据库选型和应用提供深入洞察和可靠参考路径。立即浏览
目录