导读
在技术领域,持续地优化和改进是确保产品可靠性和性能的关键。本文探讨了 TiKV 在解决内存泄露问题时遇到的挑战,介绍了内存泄露的隐蔽性和排查难度,分析了 TiKV 在提升内存可观测性方面的实践,包括 Heap Profiling、Memory Stats 和 Memory Trace 三种方法,以及将 jeprof 集成到 TiDB Dashboard 的经验。新发布的 TiDB 8.1 LTS 版本综合运用了三种方法,有效地提升了排查和解决内存问题的效率,保障系统稳定性。
背景
在过去的一段时间内,TiKV 碰到了一些内存泄露导致 OOM 的问题。虽然最终都得以一一解决,但排查过程有些情况需要依赖猜测,很难直观确定问题所在。生产场景中必须及时定位问题,因此,提升内存的可观测性、及时发现和解决内存泄露问题,显得尤为重要。
而内存泄露导致的 OOM 问题总是非常棘手:
- 内存泄露难以察觉:内存泄露往往是一个缓慢积累的过程,可能需要数天甚至数周才能显现出问题。这种细水长流的泄露方式使得问题难以被及时发现,给排查带来了极大的挑战。
- 缺乏排查现场:当 OOM 事件发生时,系统会直接崩溃或进程被杀掉,导致没有现场数据可以用来排查问题。这种情况使得事后分析和诊断变得非常困难。
- 难以复现问题:内存泄露问题在测试环境中通常很难重现,尤其是在泄露积累需要较长时间的情况下。即使在相似的环境下,也可能因为不同的工作负载和系统状态而无法复现。
不同于 Go 标准库中强大的开箱即用的 pprof,TiKV 基于 Rust 构建,而 Rust 本身并没有集成类似的工具。普遍做法是利用第三方 allocator 提供的 Heap Profiling 功能。TiKV 就是通过 Jemalloc 来进行 Heap Profiling,同时实现 Memroy Trace 对内存消耗大户进行手动追踪内存使用量。但现有(指在 v7.5.0 之前) 的这些机制存在着一些不足,要么准确性不足要么不够易用,导致在排查问题时往往不能提供太多有效信息。
综上,我们看到不同手段都有其局限性。所以针对内存可观测性,我们需要的不仅仅是单一的 Heap Profiling,多维度的交叉参考才能让内存泄露无所遁形。这里可以归纳为三个维度:点线面,分别针对不同维度的信息。
- 面:某个时刻的内存切面,即 Heap Profiling 获得的全局现有分配内存的堆栈
- 线:某段时间各个模块线程的内存使用量,通过 metrics 记录以展示变化趋势
- 点:精确的内存使用量统计与控制,通过 Memory Trace 手动追踪内存,精确知道内存大户的具体位置,并同时进行管控控制使用率。比如 block cache,entry cache,coprocessor 中间结果等等
下面我们就分别以这三方面,介绍在 TiKV 在提高可观测性方面的实践。
面——Heap Profiling
Heap Profiling 指对应用程序的堆分配进行收集或采样,来向我们报告程序的内存使用情况,以便分析内存占用原因或定位内存泄漏根源。前面提到了 TiKV 可以通过 Jemalloc 进行 Heap Profiling,但是实用性上很差:
- 没有默认开启,需要通过 HTTP debug 接口手动触发获得那一段时间增量的 profile data
- 操作麻烦(如下所示),获得的 profile data 还需要在 TiKV 宿主机上用 jemalloc 的命令行工具 jeprof 进行解析,在实际情况下常常因为环境等问题导致解析失败,十分影响效率
$curl -X GET 'http://$TIKV_ADDRESS/debug/pprof/heap?seconds=30' > prof_data
$jeprof --svg /path/to/tikv prof_data针对以上问题,那优化的最终期望是:
- 默认开启,那统计的就是全量的已有内存占用,通过全量做差也可以知道增量的变化
- 不依赖 binary 进行解析,不需要额外命令一键式获取火焰图
默认开启
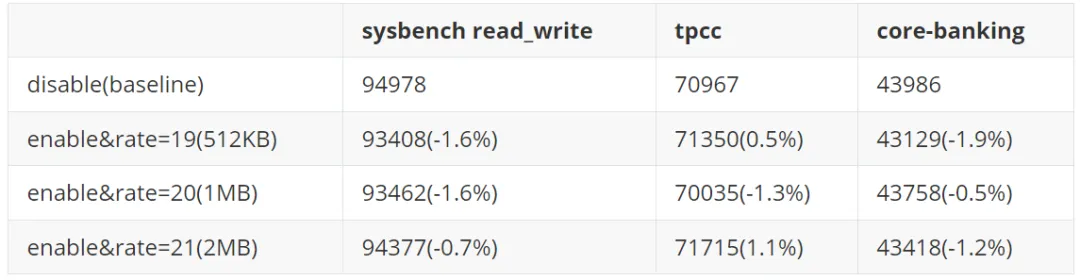
默认开启并不复杂,主要是要考虑对性能的影响。Heap Profiling 原理上是在 malloc 时记录栈信息以及申请内存的大小,当 free 时再把相应的记录去除。关于 heap profiling 更详细的原理介绍请参考内存泄漏的定位与排查:Heap Profiling 原理解析。显然,每次 malloc 都去获取栈的性能开销和记录栈的内存开销是可观的。因此不管是 Heap Profiling 还是 CPU Profiling 都会进行采样,也就是每申请多少 bytes 才记录一次栈信息。Jemalloc 默认配置下,每 512KB 进行一次采样。
我们分别测试了 512KB,1MB,2MB 三种采样率下的性能,相比与禁用 Heap Profiling 下, 有 1%+ 的性能开销,是可以接受的。而这三个不同采样率下性能损耗没有明显区别,因此最终选择 512KB 的采样率下默认开启 Heap Profiling。
摆脱 binary 依赖
Profile 解析原理
为了减少对 TiKV binary 的依赖,我们首先需要理解 jeprof 工具在处理 jemalloc 堆栈分析时为何需要 TiKV 的二进制文件。在触发 jemalloc 进行堆栈分析时,其操作实质是导出内存中记录的栈信息。以下是对导出的 profile 的简要说明:
heap_v2/524288
t*: 28106: 56637512 [0: 0]
[...]
t3: 352: 16777344 [0: 0]
[...]
t121: 17754: 29341640 [0: 0]
@ 0x5629e1b96e20 0x5629e1b97401 [...] 0x7fe62a7ce083 0x5629dce516fe
t*: 1: 67108864 [0: 0]
t0: 1: 67108864 [0: 0]
@ 0x5629e1b96e20 0x5629e1b97401 [...] 0x7fe62a8c9353
t*: 1: 4096 [0: 0]
t5: 1: 4096 [0: 0]
[...]
@ 0x5629e1b96e20 0x5629e1b97401 [...] 0x5629e186553d 0x7fe62a7ce083 0x5629dce516fe
t*: 1: 10485760 [0: 0]
t0: 1: 10485760 [0: 0]
MAPPED_LIBRARIES:
5629dc5fb000-5629dcb71000 r--p 00000000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629dcb71000-5629e24bc000 r-xp 00576000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629e24bc000-5629e384b000 r--p 05ec1000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629e384b000-5629e3c20000 r--p 0724f000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629e3c20000-5629e3c2e000 rw-p 07624000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629e3c2e000-5629e3e97000 rw-p 00000000 00:00 0
[...]
7fe61545c000-7fe61565c000 rw-p 00000000 00:00 0
7fe61565c000-7fe61fe00000 r--p 00000000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
7fe61fe00000-7fe620200000 rw-p 00000000 00:00 0
[...]这是从一个实际 TiKV 导出的 heap profile,其中 [...] 省略了一部分以方便展示。以 heap_v2/524288 为头表明了 heap profile 的版本信息和平均采样率,其后分为三个部分:
- 先是各个线程统计的仍然活跃的采样点对象个数(malloc 时被采样到 +1,free 时如果是之前被采样到的内存地址则 -1)以及内存使用量 bytes,其中
t*表示所有线程的加合。至于[0: 0]表明的是历史累加值,而非当前活跃的,由于默认不开启统计累加值,因此总是为 0。 - 紧跟着的多个
@ <frame> <frame> ... <frame>是每次采样的栈信息,自顶向下得列出各层栈帧的运行时地址。同时相同的栈可能来自于不同的线程,因此也列出该栈来自于不同线程的采样点对象个数和内存占用量 bytes,格式同上。 - 最后是 MAPPED_LIBRARIES,实际就是当时
/proc/<tikv_pid>/maps的内容,有什么作用我们后面会提到
具体格式如下:
<heap_profile_format_version>/<mean_sample_interval>
<aggregate>: <curobjs>: <curbytes> [<cumobjs>: <cumbytes>]
[...]
<thread_3_aggregate>: <curobjs>: <curbytes>[<cumobjs>: <cumbytes>]
[...]
<thread_99_aggregate>: <curobjs>: <curbytes>[<cumobjs>: <cumbytes>]
[...]
@ <top_frame> <frame> [...] <frame> <frame> <frame> [...]
<backtrace_aggregate>: <curobjs>: <curbytes> [<cumobjs>: <cumbytes>]
<backtrace_thread_3>: <curobjs>: <curbytes> [<cumobjs>: <cumbytes>]
<backtrace_thread_99>: <curobjs>: <curbytes> [<cumobjs>: <cumbytes>]
[...]
MAPPED_LIBRARIES:
</proc/<pid>/maps>有了这个 heap profile 就可以用 jeprof 去生成火焰图,火焰图中我们看到的都是函数名而不是那些地址,因此 jeprof 就需要将这个地址映射成人类可读的 symbol。而这个映射就需要 binary 中的额外信息,分为两种:
-
Symbol table,ELF 使用两个 sections 来表示 symbol table:
$ readelf -S tikv-server | grep sym [ 5] .dynsym DYNSYM 0000000000000988 00000988 [41] .symtab SYMTAB 0000000000000000 080071d0- .symtab:局部符号,程序中标识符和内存地址的对应关系
- .dynsym:动态符号,前者的子集,用来保存与动态链接相关的导入导出符号
-
DWARF debug 信息(即 gcc -g 生成的调试符号表),ELF 使用以 debug 开头为 sections 来表示
$ readelf -S tikv-server | grep debug
[33] .debug_aranges PROGBITS 0000000000000000 07631338
[34] .debug_info PROGBITS 0000000000000000 076367d8
[35] .debug_abbrev PROGBITS 0000000000000000 078ee3e8
[36] .debug_line PROGBITS 0000000000000000 07903b90
[37] .debug_str PROGBITS 0000000000000000 07a3ae1a
[38] .debug_loc PROGBITS 0000000000000000 07a905d0
[39] .debug_ranges PROGBITS 0000000000000000 07e57978
[40] .debug_macro PROGBITS 0000000000000000 07fc8198所以 jeprof 实际做的事情就是将 profile 中所有的地址提取出来,然后通过 addr2line 或者 nm 去查 symbol,而 addr2line 和 nm 背后就是依赖上面这两种 debug 信息进行解析。
等下!那之前说的 MAPPED_LIBRARIES 有什么用?
其实拿上面的一个栈帧地址用 addr2line 试一下,你将只会得到一个问号
$addr2line 7fe62a7ce083 -e tikv-server -f -C
??
??:0为什么会有这样的结果?因为如今 OS 都支持地址空间配置随机载入 (ASLR),即在装载时将程序装载在随机地址,以防止黑客利用已知地址信息执行恶意代码。为支持这一功能,编译器默认会编译程序为位置无关可执行文件(PIE)的形式,以方便加载到任意位置。因此每次进程的 text section 起始地址都是随机的,这就导致同样的代码每次运行时地址是变的,但不变的是该代码相对于 text section 起始位置的偏移。
所以我们从 profile 中拿到的栈帧地址是运行时地址,不能直接传给 addr2line,需要进行变换。
如图所示,我们从 profile 中获得的地址是 Foo(mem),而 addr2line 需要传入的地址是 Foo(vma) 或者是当使用 addr2line --section=.text 时传入相对于 text section 的偏移,即 Foo(file) - text(file) 。对于 PIE 文件,一般 VMA(base) = 0,所以我们需要的 Foo(vma) = Foo(file) = Foo(mem) - ELF(mem)。
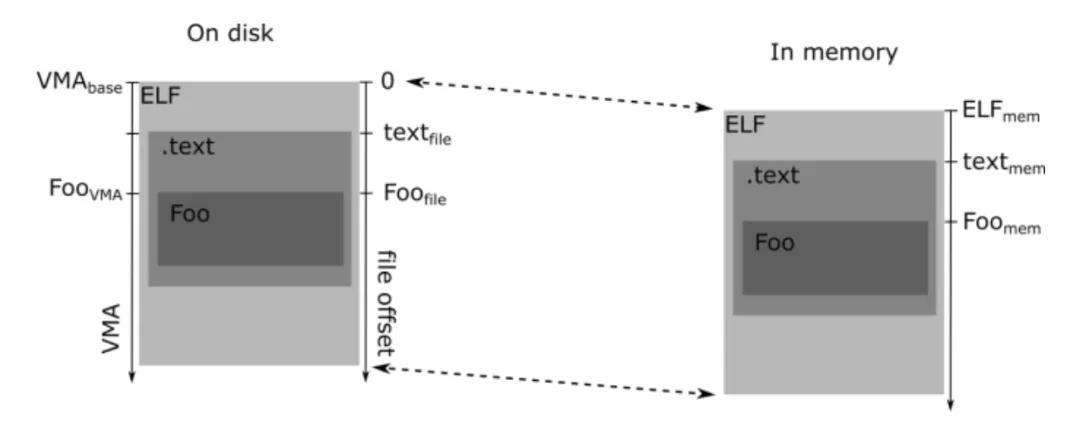
我们并不直接知晓 ELF 的内存地址(ELF(mem)),这正是MAPPED_LIBRARIES发挥作用的地方。正如前文所述,MAPPED_LIBRARIES实际上反映了进程的内存布局,它的内容就是/proc/<pid>/maps的输出。
$ cat /proc/<tikv_pid>/maps
5629dc5fb000-5629dcb71000 r--p 00000000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629dcb71000-5629e24bc000 r-xp 00576000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629e24bc000-5629e384b000 r--p 05ec1000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629e384b000-5629e3c20000 r--p 0724f000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629e3c20000-5629e3c2e000 rw-p 07624000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
5629e3c2e000-5629e3e97000 rw-p 00000000 00:00 0
[...]
7fe61545c000-7fe61565c000 rw-p 00000000 00:00 0
7fe61565c000-7fe61fe00000 r--p 00000000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server
7fe61fe00000-7fe620200000 rw-p 00000000 00:00 0
[...]每一行的格式如下:
<address start>-<address end> <mode> <offset> <major id:minor id> <inode id> <file path>
5629dcb71000-5629e24bc000 r-xp 00576000 08:03 8041447 /root/zbk/tikv/target/release/tikv-server- address start – address end 表示的这段内存映射的范围
- mode (permissions) 表示具有的权限和模式,r 读,w 写,x 可执行,p/s 私有
- offset 表示该段内存起始位置在原文件中的偏移
- major:minor ids 表示映射文件所在硬件的 major and minor id
- inode id 表示映射文件的 inode
- file path 表示映射文件的路径
其中有 x 权限的映射 tikv-server 的内存段就是 text section,其 address start 就相当于 text(mem),而 offset 就相当于 text(mem) - ELF(mem)。那么我们就能根据

计算得出传给 addr2line 的地址。
Symbol 服务
理解了 profile 的解析原理后,我们便有了明确的解决方向。我们的目标是能够从其他来源获取所需的映射信息,以消除对 binary 的依赖。
那么,这些映射信息应从何处获取?答案很明确:TiKV 本身就包含了这些信息。
值得注意的是,jeprof 工具支持远程获取分析文件的机制,它可以通过访问 host:port/pprof/symbol 路径来检索 symbol。
$ jeprof --help
Usage:
...
jeprof [options] <profile>
<profile> is a remote form. Symbols are obtained from host:port/pprof/symbol
Each name can be:
/path/to/profile - a path to a profile file
host:port[/<service>] - a location of a service to get profile from
The /<service> can be /pprof/heap, /pprof/profile, /pprof/pmuprofile,
/pprof/growth, /pprof/contention, /pprof/wall,
/pprof/censusprofile(?:\?.*)?, or /pprof/filteredprofile.现在 TiKV 就是实现了 pprof/heap 的接口,那么让 TiKV 也支持 symbol 服务,jeprof 就可以不依赖 binary 直接解析了。jemalloc 的 heap profile 格式实际上是 pprof 的 heap profile 的衍生版本,因此在接口上也是遵循了 pprof 的协议。在 pprof remote server 文档中详细定义了 /pprof/symbol 的接口格式:
- 如果是 GET 请求返回 symbol 的个数,返回数据的格式为
num_symbols: ###,其中 ### 是可执行文件中 symbol 的数量(目前,唯一重要的区别是这个值是否为 0,对于缺少调试信息的可执行文件,此值为 0;否则不为 0)。 - 如果是 POST 请求返回地址对应的函数名,传入的数据为多个十六进制的地址以
+连接,返回的数据则为多行,每一行以<hex address><tab><function name>格式输出地址对应的函数名,
那剩下就是 TiKV 怎么去实现 pprof/symbol 这个 HTTP 接口。
- 首先读取
/proc/self/maps获得内存映射信息 - 依次用传入的地址去对比看落在内存映射信息中的哪个 range 中, 并用该 range 的 address start 和 offset 来计算出转化后的 addr
- 从 /proc/self/exe 获取 TiKV 自身 binary 的路径并加载 debug 信息
- 利用现成的库从 debug 信息中找到 addr 所对应的 symbol
通过该方式 jeprof 获取的 heap profile,你会发现除了之前 heap profile 中的三个部分,在最开头还会多出来一个 symbol 部分,其包括了后面所有栈帧地址对应的 symbol 映射。这个就是 symbolized profile,有了它即使脱离 TiKV binary 或者 symbol 服务,我们也可以将这个原始数据转换成任意的图表,比如火焰图,或者 call-graph。
--- symbol
binary=/root/zbk/tikv/target/release/tikv-server
0x00005629e1db950c rocksdb::Arena::AllocateAligned(unsigned long, unsigned long, rocksdb::Logger*)
[...]
0x00005629e08485aa tikv::read_pool::build_yatp_read_pool_with_name::{{closure}}::h6881170ec4231a36
---
--- heap
heap_v2/524288
t*: 572: 649942 [0: 0]
t0: 246: 891339 [0: 0]集成进 TiDB Dashboard
TiDB Dashboard 提供了一个用户友好的性能分析界面,它能够方便地获取和展示集群中各个组件的 CPU 和 Heap Profiling 数据。然而,由于之前的实现需要依赖 TiKV binary 文件来进行数据解析,这导致它无法与 TiDB Dashboard 集成。现在,随着我们不再需要依赖 TiKV binary 文件,我们可以探索将 jeprof 工具集成到 TiDB Dashboard 中的可能性。
不过,我们面临一个挑战:尽管 jeprof 最初是为了与 pprof 兼容而设计的,但由于它需要支持每个线程的 heap profiling,jemalloc 导出的数据格式与 pprof 的标准格式并不完全一致。这意味着我们无法直接使用 TiDB Dashboard 现有的 Go 语言编写的 pprof 工具来处理这些分析数据。因此,我们需要让 TiDB Dashboard 能够调用 jeprof 来进行数据解析,而 jeprof 是用 Perl 编写的。
针对此有如下几个思路:
a. 用 go 重写 jeprof 实现相关逻辑集成在 TiDB Dashboard 中
b. 保证 TiDB Dashboard 部署环境安装 perl 运行时,jeprof 这个 perl 脚本嵌入 go 代码资源中作为一个字符串,然后通过 os/exex 来执行外部命令 perl 并传入 jeprof 脚本
c. 在 TiKV 侧导出 profile 时,使用 https://github.com/polarsignals/rust-jemalloc-pprof 将 jemalloc 的 profile 转换成 pprof 的格式
方案 a 的成本比较高,需要重写 jeprof 相关逻辑同时还要考虑之后的维护成本。方案 b 是最简单的,当然会给 TiDB Dashboard 引入一些单独处理 TiKV profile 的逻辑。而方案 c 是最优雅通用的,对 TiDB Dashboard 透明,转换成 pprof 的格式在以后也可以方便的传给其他工具处理。但可惜的是,在代码调研阶段 rust-jemllaoc-pprof 库并未公开,所以当时还没有方案 c。因此最终代码的实现是按照方案 b 来的。
除此以外还需要对于 jemalloc 的 profile data 特殊处理,TiDB Dashboard 使用 speedscope 来展示火焰图,speedscope 支持解析 pprof 的数据格式但不支持 jemalloc 的数据格式。因此其中需要通过 jeprof -- collapsed 先将 profile data 转换成中间格式 Brendan Gregg's collapsed stack format,然后再传递给 speedscope 才能正常显示火焰图。
至此 Heap Profiling 的全链路打通,集成进 TiDB Dashboard 后可以获得同 Go 一样丝滑的体验。
线——Memory Stats
Heap Profiling 是一个功能强大的工具,但在未启用 Continuous Profiling 的情况下,我们可能会面临无法及时获取OOM问题现场数据的挑战。这就需要一种能够展示历史变化趋势的方法,以便协助我们调查和解决问题。
使用 Metrics 来体现这种历史变化趋势是最合适的选择。Jemalloc 提供了一些现成的指标,如实例级别的 mapped、retained、allocated 和 metadata 等数据。我们已经将这些指标集成到了 Grafana,但这样的粒度对于我们的需求来说还不够细致。
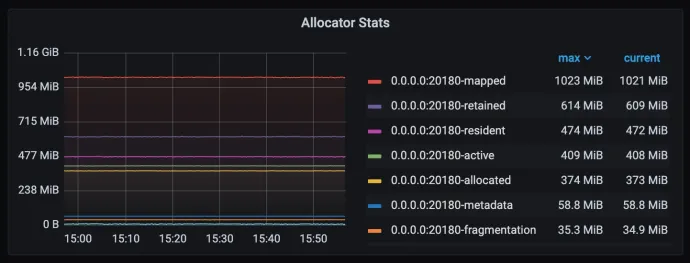
为了实现更细粒度的监控,我们可以考虑按照功能模块来划分。即使在没有进行 Heap Profiling 的情况下,这种划分也有助于我们缩小问题的怀疑范围,为排查问题提供有价值的帮助。
Jemalloc 提供了线程级别的 allocated 和 deallocated 的累积统计信息。然而,由于内存的申请和释放可能不在同一个线程中进行,仅使用 deallocated - allocated 并不能准确反映线程尚未释放的内存总量。为了进行更准确的统计,我们需要更深入地了解 Jemalloc 的内存管理模型。
Jemalloc Arena
为了提升多线程并发环境下的内存分配效率,操作系统常采用一种策略:将单一的大型全局锁(global lock)分解为多个与线程相关的小型锁。这样的设计旨在分离不同线程的内存分配行为,减少线程间对同一缓存行(cache line)的竞争。基于这一理念,jemalloc 引入了 arena 的概念。
Arena 机制将内存分割成多个区域,每个线程最终将与一个特定的 arena 绑定。例如,在下图中,thread#A 和 thread#B 分别绑定到了 arena #1 和 arena #3。由于这些 arena 在地址空间上几乎没有关联,因此可以在无需锁的情况下完成内存分配。此外,由于这些内存空间的分布不连续,它们落在同一个缓存行的概率也大大降低,从而确保了线程间的独立性。
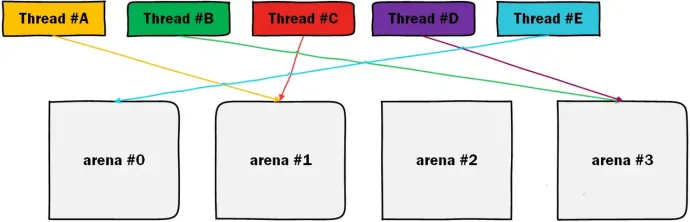
由于 arena 的数量是有限的,并不是所有线程都能独占一个arena。例如,在上图中,thread #A 和 thread #C 都绑定到了同一个 arena #1。作为内存管理的基本单元,每个 arena 自然拥有自己的 mapped 指标。因此,确保关键线程能够独占绑定到一个 arena,可以简化该线程的内存占用统计。
尽管 arena 内部继续划分了多个层级的结构,但在此我们只关注 arena 层面的指标。此外,这种做法还有一个额外的好处:它避免了关键线程之间在内存分配上的冲突,从而减少了锁竞争。
然而,需要注意的是,arena 的数量不宜过多,以免增加内存碎片。默认情况下, jemalloc 会根据 CPU 核心数创建相应数量的 arena,通常是 CPU 核心数的四倍。
TiKV 线程模型
TiKV 采用 pipeline 模型,即读写请求以消息的形式,从 grpc 再到 scheduler 再到 raftstore 进行数据流转。
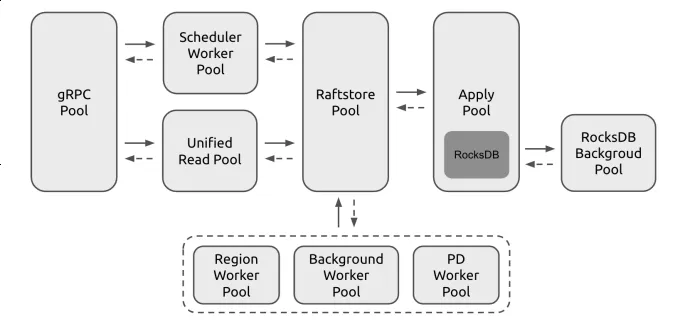
在大多数情况下,TiKV 的功能模块配备有一个或多个专用线程池,这些线程池中的线程仅处理特定类型的消息和任务。基于这种设计,TiKV 的线程模型非常适合利用线程绑定的 arena 进行内存统计,从而监控各个模块的内存使用情况。通过简单地将同一线程池中多个线程的内存统计数据进行累加,即可得到该功能模块的总内存使用量。
具体实现上,是对进行 thread spawn 进行 hook,通过 spwan 后先确保绑定到一个独立的 arena 上。Jemalloc 提供接口 arenas.create 创建独占的 arena,以及 thread.arena 设置线程绑定的 arena。
然而,这里存在一个问题:多个线程在读取 RocksDB 时会涉及到 Block Cache。Block Cache 分配的内存会在长时间内被占用,直到缓存失效。如果将 Block Cache 的内存分配计入各个 thread 的内存使用量,那么 Block Cache 占用的内存会与 thread 本身数据结构的内存消耗混在一起,这将导致无法准确反映每个 thread 的实际内存使用情况。因此,我们需要从 thread 的内存统计中排除 Block Cache 的使用。
为了解决这个问题,RocksDB 为 Block Cache 提供了一个专门的 allocator 接口。所有 Block Cache 的内存申请都通过这个 allocator 进行,该 allocator 可以创建一个或多个专用的 arena。在申请内存时,通过 mallocx 接口指定 arena 的 index,就可以将所有 Block Cache 相关的内存集中到一个或多个专用的 arena 中。这样,在统计其他线程的内存使用量时,就不会受到 Block Cache 的影响。
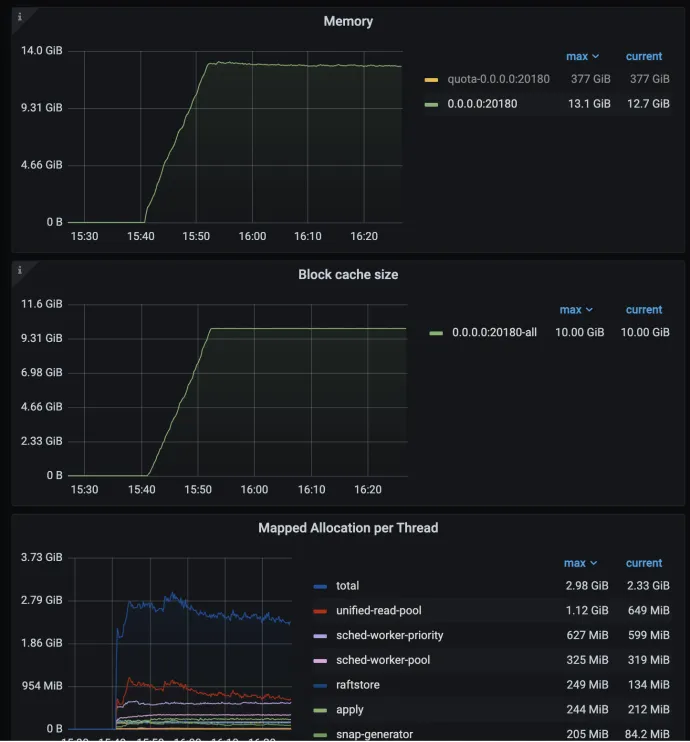
最终如上图,可以看到分线程池的内存使用量,同样可以看到各个线程池的总使用量 + Block Cache 使用率差不多就等于 os 层面看到的进程内存使用量。(rocksdb background 线程池的内存使用量暂时未统计)
点——Memory Trace
Heap Profiling 和 Memory Stats 虽然提供了有价值的内存使用信息,但它们共同面临一个问题:内存可能在一个线程中被分配,随后所有权转移到另一个线程,并在那里长时间保留而不释放。这种情况下,Heap Profiling 和 Memory Stats 显示的高内存使用区域并不一定指向内存泄漏的真正位置。特别是对于 raftstore 这样处理过程复杂的线程,Memory Stats 的粒度可能不足以精确定位问题。这时,我们需要 Memory Trace 来执行更精细的诊断。
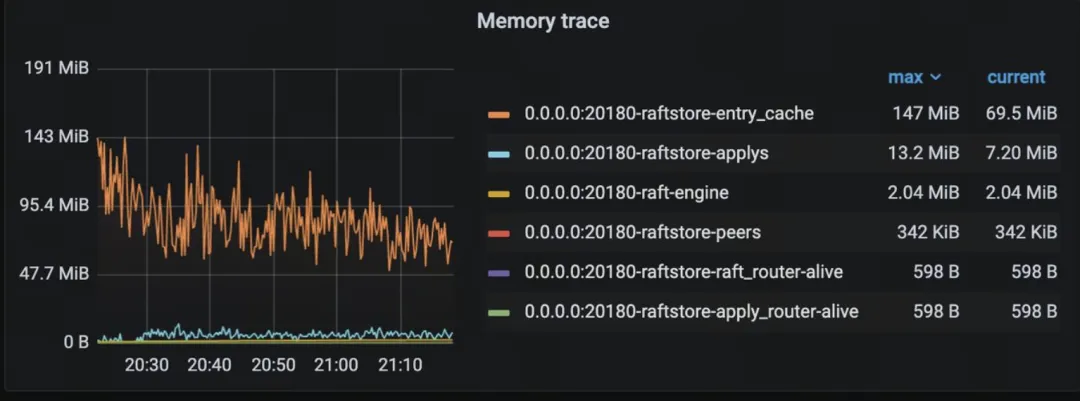
目前的 Memory Trace 主要基于增量变化,需要在 raftstore 等关键路径上手动进行记录和追踪。
- 能覆盖到的地方有限且不准确,只能覆盖已知的地方,不能发现未知的泄露
- 维护成本高,新修改的代码都需要手动添加逻辑追踪内存使用开销
- 增量容易遗漏导致累计误差
为何不通过过程宏自动化实现 Memory Trace 的统计逻辑,以提高其覆盖率并消除对 Heap Profiling 的依赖呢?理论上,这将提供最精确的结果。然而,现有的一些库在实践中无法自动处理 Arc、Rc 等智能指针的引用问题。如果不考虑这些引用,同一对象可能会因为被多次引用而被重复统计,这将导致最终的内存使用量数据不准确。
此外,还有一种全面的方法来进行 Memory Trace 统计。可以为常用的数据结构实现一个 MallocSizeOf Trait,用以统计它们的内存占用量。结合过程宏,可以为每个自定义结构自动实现 MallocSizeOf Trait。这种方法可以自顶向下地根据代码结构统计各个部分的内存使用量。统计结果可以以较粗的粒度展示在监控 Metrics上,也可以导出形成一个类似火焰图的详细视图,以便进行细粒度的分析。
impl<T> MallocShallowSizeOf for Vec<T> {
fn shallow_size_of(&self, ops: &mut MallocSizeOfOps) -> usize {
unsafe { ops.malloc_size_of(self.as_ptr()) }
}
}
impl<T: MallocSizeOf> MallocSizeOf for Vec<T> {
fn size_of(&self, ops: &mut MallocSizeOfOps) -> usize {
let mut n = self.shallow_size_of(ops);
for elem in self.iter() {
n += elem.size_of(ops);
}
n
}
}
#[derive(Clone, MallocSizeOf)]
struct BaseRowSampleCollector {
null_count: Vec<i64>,
count: u64,
fm_sketches: Vec<FmSketch>,
#[ignore_malloc_size_of = "Rng is not easy to calculate size"]
rng: StdRng,
total_sizes: Vec<i64>,
memory_usage: usize,
reported_memory_usage: usize,
uuid: String,
}当然同样也还是有些问题:
- 有相对较多额外的开销,降低频率即时性会差一点
- 对于 Arc 不能很好的处理,需要单独标注或者跳过,否则会被重复统计
- 对于 hashmap 或者 channel 等结构体的内存不一定是连续的,可能统计起来就没那么准确了。
除了统计以外,Memory Trace 为内存管理提供了基础手段,对于 coprocessor 等高并发模块进行内存控制防止 OOM 。想要获得更好覆盖的 Memory Trace 还是有一定的工作量,以及对各种 case 的进行自动化处理也是有些难度的。未来我们也将对此进行优化和改进。
总结
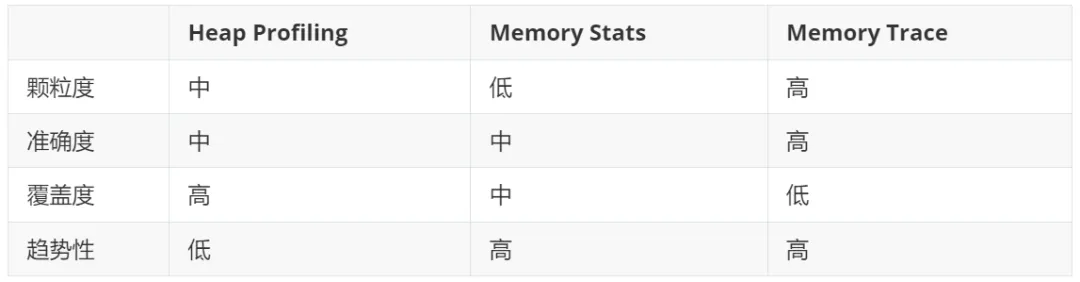
通过对 Heap Profiling、Memory Stats 和 Memory Trace 的深入分析和实践,我们可以更全面地提升 TiKV 的内存可观测性。这三种方法各有其独特的优势和局限性:
- Heap Profiling 提供了中等颗粒度和准确度的内存使用快照,适合在内存问题出现时进行详细分析,但不具备趋势性。
- Memory Stats 通过 metrics 记录内存使用量的变化趋势,能帮助我们监控和分析内存使用的历史数据,但其颗粒度和准确度较低。
- Memory Trace 提供了高颗粒度和高准确度的内存使用统计,能够精确定位内存消耗大的模块和位置,并进行内存控制,但覆盖范围有限且实现复杂。
综合来看,单一的内存监控手段无法全面解决内存泄露问题,我们需要多维度的交叉参考:结合 Heap Profiling、Memory Stats 和 Memory Trace,以便在不同场景下提供有效的信息,提升排查和解决内存问题的效率,从而确保 TiKV 的稳定性。
在 TiDB 最新的 8.1 版本中,我们已经集成了这些优化措施。我们相信,这些改进将为您带来更加稳定、可靠且可预期的用户体验。
目录