
导读
本文根据平凯星辰解决方案技术部总经理戴涛在 2024 金融科技大会“数智化激活城商行服务体质增效新引擎”论坛上的演讲整理。
文章通过具体案例展示了 TiDB 如何在金融行业中海量数据明细查询、金融核心、新技术和 AI 创新以及多租户和小库归集等场景下实现“多、快、好、省”的目标。随着技术的不断进步,相信 TiDB 能够进一步推动国产数据库技术的应用,助力金融企业实现数字化转型和业务创新。
TiDB 是一款新兴的企业级开源分布式数据库,自创立以来已走过十个年头。平凯星辰公司的创立灵感源自三篇具有里程碑意义的科技论文:Google 在 2012 年和 2013 年发表的关于分布式系统的研究——涉及 Spanner 和 F1 数据库,以及 2014 年斯坦福大学关于 Raft 共识算法的博士论文。这些论文激发了 TiDB 团队,致力于满足用户对于分布式数据库在可扩展性和性能方面的极致需求。
TiDB 最引人注目的标签有两个,一个标签是“自主开源”,另一个是“技术引领”。TiDB 产品源代码 100% 自主原创,从公司成立伊始即全面开源。TiDB 已成为国人主导的全球知名开源数据库项目,贡献者超过 2,200 人,全球用户数量突破 3,000 家。在国际市场,TiDB 同样取得了骄人成绩。2024 年,TiDB 荣膺 Gartner® Peer Insights™ 云数据库管理系统“客户之选”,是唯一获此殊荣的中国数据库;TiDB 连续三年( 2022-2024)在日本最大的数据库展会 DB Tech Showcase“未来最想使用的数据库”评选中位列第一。
2024 年 9 月,平凯数据库(TiDB 企业版)通过了国家信息安全评测中心的安全可靠测评,是首批通过的分布式数据库厂商之一。目前,平凯数据库广泛应用于金融、运营商、能源、医疗、电力、政企等行业用户的关键业务系统。
/ TiDB 在金融行业的四大场景的应用 /
在金融行业,尤其是银行业,核心需求之一是能够迅速查询和分析庞大的明细数据集。数据库的主要挑战在于如何在庞大的数据环境中实现可扩展性,这对于处理银行的高价值数据至关重要。第二个关键场景是银行核心系统的支撑,其目标是通过优化延迟和采用更敏捷的开发方法来提升系统性能,从而支持业务的快速增长。第三个场景展现了 TiDB 的技术创新,通过提供 GraphRAG 解决方案,加速金融机构在人工智能领域的探索步伐。第四个场景针对金融机构在国产化升级过程中普遍面临的成本效益问题,TiDB 的 MySQL 小库归集和多租户解决方案提供了有效的成本控制和性能提升。

总体来说,TiDB 提供的四大场景应用可以用四个字来概括:多(数据量大)、快(查询速度快)、好(系统性能优)、省(成本效益高)。
“多”-海量数据明细查询场景
首先是关于“多”的场景。在银行业务中,处理大量数据的场景非常普遍,尤其是在明细账单查询和综合业务查询等关键领域。从底层数据流转的角度来看,银行的海量明细交易数据通过逻辑复制的方式迁移到 TiDB。TiDB 支持通过同城双活或两地三中心的部署策略,实现冷数据、温数据和热数据的分层存储,优化数据管理。此外,TiDB 还能够对批量处理和交易型任务进行资源隔离,确保业务之间的处理互不干扰。该场景的业务价值主要体现在为前端客户提供了宽表形式的数据访问,这不仅提升了查询效率,也增强了数据处理的效能。同时,TiDB 支持多条件组合查询,增强了服务接口的灵活性,从而更好地满足不同客户的个性化需求。

以一家国有大型银行的综合业务查询系统为例,该系统在使用 TiDB 之前依赖于 Oracle、MongoDB 和 Hive 三套不同的数据库来处理业务需求。这种多技术栈的架构导致了高昂的开发和维护成本,同时也面临着大容量弹性存储、可用性不足以及 OLTP/OLAP 混合处理能力不足等技术挑战。2023 年 7 月,该银行成功地将原有的三套数据库系统完全替换为一套 TiDB 数据库,该系统被归类为 A5 级别。
目前,TiDB 集群已扩展至超过 2,700 个虚拟节点和 300 个物理节点,数据量达到 PB 级别,涵盖了银行对公、对私以及海外业务的明细数据,并与近百个上下游业务系统对接,提供综合业务查询服务。无论是通过该银行的 APP 还是在其柜台办理业务,所有客户和对公维度的明细账单数据都已存储在 TiDB 中。
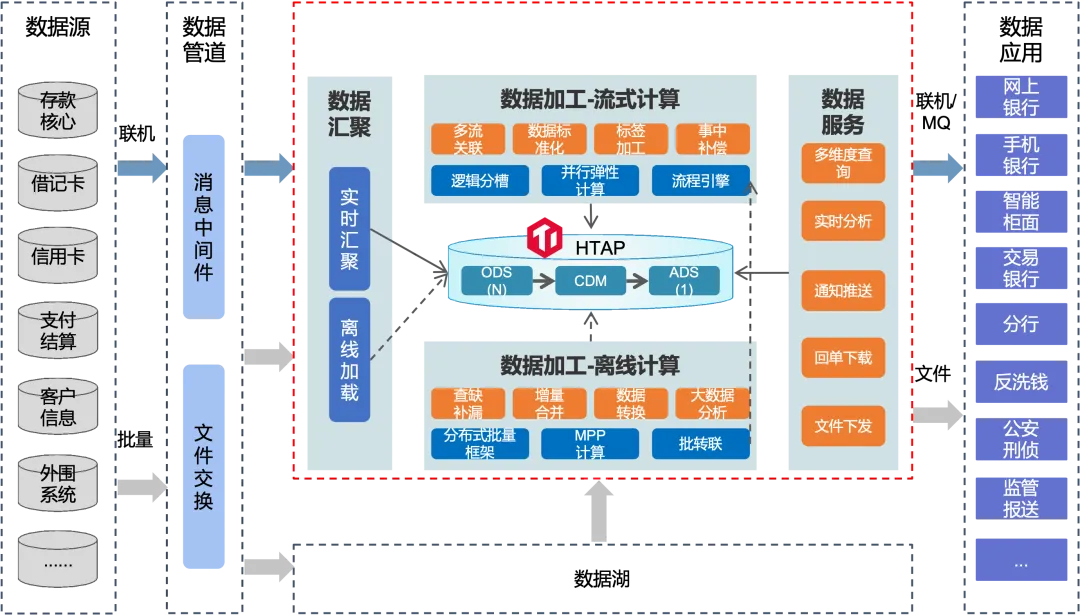
TiDB 在多维查询场景的成功应用不仅限于大型银行。在北京银行和招商银行,TiDB 同样被应用于历史账单查询和信用卡明细查询,能够支持大规模的高并发操作,并极大地提升了查询效率。对于复杂的查询,响应时间能够控制在 1 秒以内,而简单查询则在 50 毫秒内完成,TPS 约为 3,000 左右。关于这个场景更多的案例分享,大家可以在平凯星辰官网下载《场景解决方案白皮书——银行领域交易明细查询》进行了解。
“快”-金融核心场景
第二个场景是“快”。银行核心系统的需求有两个维度,一个是更敏捷,一个是更快。在设计之初,TiDB 采用了原生分布式架构,避免了传统分库分表的复杂设计。TiDB 的底层架构内置了自动分散热点数据的机制,这一特性对开发者来说是完全透明的,他们在开发过程中无需担忧分库分表或跨单元连接的性能问题。这样的设计简化了开发流程,同时提升了系统的响应速度和处理能力。

TiDB 从诞生之日起就将极致的扩展性纳入考量,使得运维扩容过程变得非常直观和便捷,允许系统轻松进行扩容和缩容操作。与之相比,传统的 MySQL 数据库扩容通常需要按照固定倍数进行,例如从 2 个节点扩展到 4 个节点,或从 4 个节点扩展到 8 个节点。TiDB 采用计算存储分离架构,使得计算层和存储层可以独立进行扩容,整个过程对用户完全透明。此外,TiDB 支持 HTAP 混合负载,能够同时进行事务处理和分析查询,即使是轻量级的查询分析,也能做到极致的透明性。面对热点数据,用户可以利用 TiDB 内置的技术手段,实现进一步的性能优化。
2023 年 11 月,杭州银行新一代核心业务系统成功投产上线。新核心系统是业内首个实际投产的云原生、分布式、全栈国产化的银行核心系统。在众多城市商业银行普遍采用双中心机房布局的背景下,主流分布式数据库通常需要三中心部署。杭州银行的核心系统基于 TiDB 实现了行业内领先的双中心双活架构,这在国内城市商业银行中尚属首次。
TiDB 创新性地提出了 3-3:1:1 容灾架构,即基于同城双中心的基础上,使用 3:3 非对称方式部署,引入 1 个学习节点,有效解决了技术层面的多数派选举问题,实现了故障的自动转移。与常见的三中心架构相比,这种双中心双活架构在减少资源投入和降低运维复杂度方面具有显著优势。
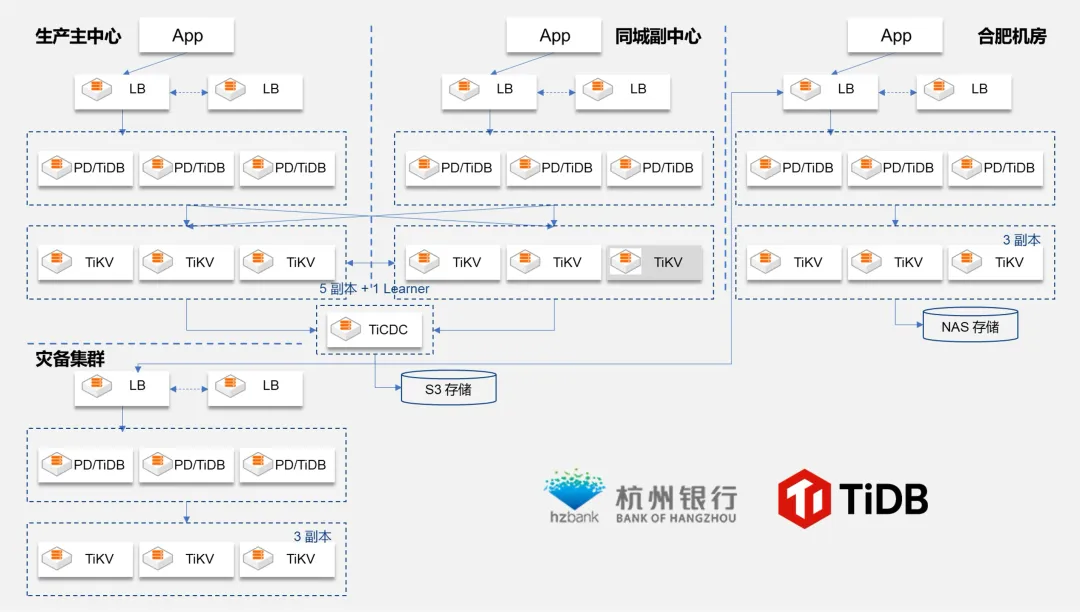
新核心系统上线以来,运行高效且稳定,联机交易性能提升了 1.5 倍,平均交易延时小于 100 毫秒。与之前的 Oracle 数据库相比,日终批量处理性能提升了 2.5 倍,夜间批处理任务在一小时内即可完成。
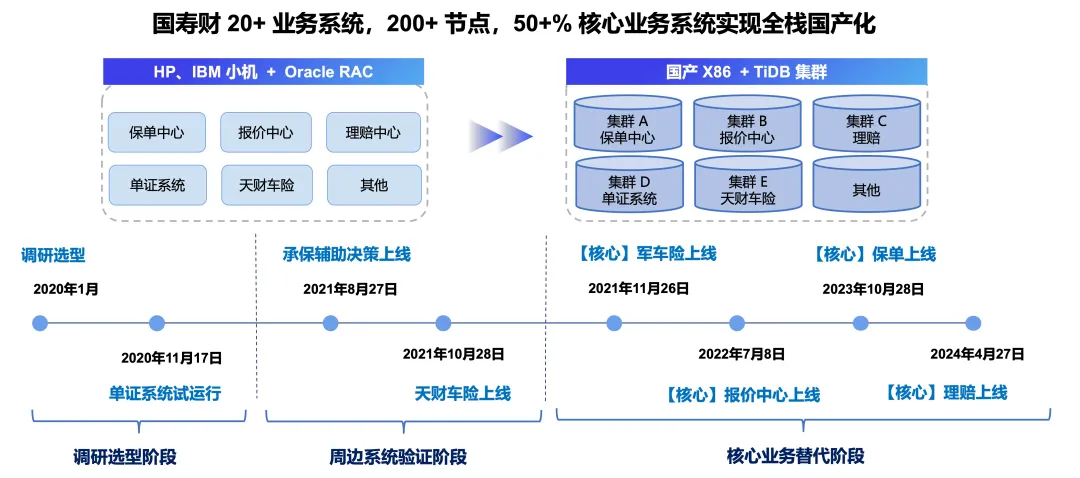
TiDB 也在中国人寿财险多个核心业务系统得到了成功应用。原先,中国人寿财险的业务系统主要依赖 Oracle 数据库,从最初的选型到边缘系统的上线,经过两年多的升级改造,最终实现了核心业务系统的全面替换升级。2023 年,国寿财保单系统首先迁移至 TiDB,今年理赔系统也顺利完成了从 Oracle 到 TiDB 的迁移。目前,国寿财多个核心业务系统都是基于 TiDB 来开发和提供服务的。正如客户所言:“国寿财通过采用自主可控的软硬件技术,对现有的保险核心业务系统进行深度升级和改造,开创了全栈自主技术在超大型保险公司核心系统中的应用先河,为国内金融行业关键系统的国产化建设提供了有力的实践经验。”
“好”-新技术和 AI 创新场景
TiDB 的架构设计灵感源自三篇具有里程碑意义的论文,TiDB 基于数据库行业最新的理论和工程实践进行架构演进。
- NewSQL:其初衷是在维持关系型数据库模型的基础上,融入 NoSQL 的卓越可扩展性,以此应对海量数据的高吞吐挑战。正因如此,TiDB 在处理极端扩展性和高吞吐方面具有天然优势。
- HTAP:随着用户在实际应用场景中反馈的不断积累,TiDB 实现了快速而持续的迭代优化。TiDB 在 2019 年率先推出了 HTAP 功能,实现了在一个数据库系统中行存与列存的自动实时同步,同时支持 OLTP 以及实时 OLAP 负载。
- 云原生:2021 年,TiDB 进化到云原生架构,并在 AWS、GCP 上推出了 DBaaS 产品 TiDB Cloud,助力中国用户扬帆出海。同时,TiDB 也在阿里云、金山云、移动云成功上线,为企业用户带来新一代 HTAP 数据库的云端体验。
- AI 智能:2022 年,随着大模型和 AI 技术的爆发式发展,TiDB 开始探索与大模型的结合,以提供更强大的数据处理能力。例如,TiDB 在 2023 年初推出了 Chat2Query 功能,它通过 Data API 与 TiDB Cloud 进行交互,把自然语言转换成 SQL 编程语言,用户可以通过输入自然语言,实现与数据库进行交互。这使得企业中除了 DBA 之外更多的数据消费者可以充分利用 AI 和云数据库的能力,快速地获取数据洞察。

在银行业务领域,图数据库的应用正变得日益广泛,这通常涉及到多种数据库技术的整合。然而,这种整合往往会增加系统的复杂性以及运维的开销。为了应对这一挑战,TiDB 将在即将发布的 8.4 版本中集成向量搜索的能力。
由于 TiDB 本身是一个关系型数据库,也可以模拟图数据库的某些功能。结合 TiDB 在替换宽表数据库方面的丰富经验,单一实例的 TiDB 就能够替代传统的关系型数据库、向量数据库、宽表数据库以及图数据库,从而解决了技术栈复杂和初始成本高昂的问题。TiDB 结合向量搜索(TiDB+Vector)通过多数据库合一的方式,极大地简化了 GraphRAG 解决方案。目前,TiDB 正在与国内多家股份制银行和城市商业银行探讨实施这一方案,在不久的将来,我们能够看到 TiDB GraphRAG 一体化解决方案在银行的落地实践。
“省”-多租户和小库归集场景
多租户的本质在于多个用户共享同一套硬件资源,通常有四种不同的方案。下图中纵轴代表资源的整合程度,横轴代表资源的隔离程度。左侧最早的多租户方案其实是在应用层解决的,通过在数据库中增加租户字段来控制不同租户的数据访问。图的右下方展示了通过虚拟化技术实现最高级别的资源隔离,但这种方法在资源整合上存在不足。
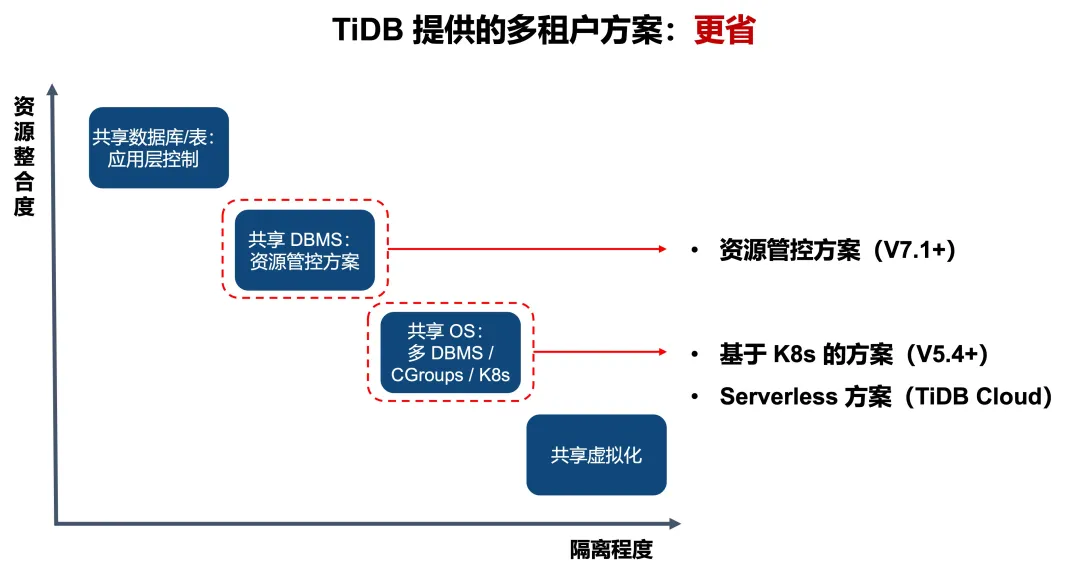
当前,主流数据库厂商普遍采用中间的两种方案来实现多租户架构。一种方案是使用共享的数据库管理系统(DBMS),并通过多实例技术来实现。TiDB 在 7.1 版本中引入了资源管控功能,这使得企业能够构建一套 TiDB 数据库集群,并通过资源管控来有效处理不同租户间的资源分配和隔离问题。多个业务系统共享一个 TiDB 集群,当整体资源有空闲时,单个业务系统可以错峰借用资源。目前,国内的金融机构,如杭州银行以及中信证券、中泰证券等,都已经采用了这个解决方案。根据调研,采用 TiDB 的资源管控方案,硬件成本可以减少至原来的 50% 以下。
另一种是共享操作系统,例如使用 CGroup 或 K8s。TiDB 也提供了两种具体的实施途径。一种是在私有云环境中基于 K8s 来部署数据库,在国内多家大型国有企业,如建设银行、中国移动都得到了应用。这些企业在私有云平台上部署 TiDB 后,实现了显著的成本效益,节约了 66% 的计算和存储资源,并且能够轻松实现同城双活和异地灾备的一键式部署。第二种途径则是通过 TiDB Cloud Serverless 在公有云上提供服务,这种方式完全集成在 TiDB Cloud 内部,通过资源组的形式对不同用户和应用进行调度和隔离,无需依赖外部的 K8s 平台。
在过去的十年中,平凯数据库(TiDB 企业版)在金融行业积累了丰富的实践经验,部署了超过 1,000 套关键业务系统,集群节点总数超过了 10,000 个。借助平凯数据库,金融机构能够高效地管理海量数据并进行实时分析,不仅提升了业务效率,降低了运营成本,还增强了系统的可扩展性和弹性。展望未来,随着技术的不断进步,平凯数据库有望进一步推动国产数据库技术在全球的应用,助力更多企业实现数字化转型和业务创新。
TiDB 的崛起不仅是一家企业的成功,更是国产开源数据库在全球市场潜力的有力证明。通过持续的技术创新和全球市场拓展,TiDB 正逐渐成为现代金融行业中不可或缺的技术基石。
目录