
本文会详细的介绍 TiKV 是如何处理读写请求的,通过该文档,同学们会知道 TiKV 是如何将一个写请求包含的数据更改存储到系统,并且能读出对应的数据的。
基础知识
在开始之前,我们需要介绍一些基础知识,便于大家去理解后面的流程。
Raft
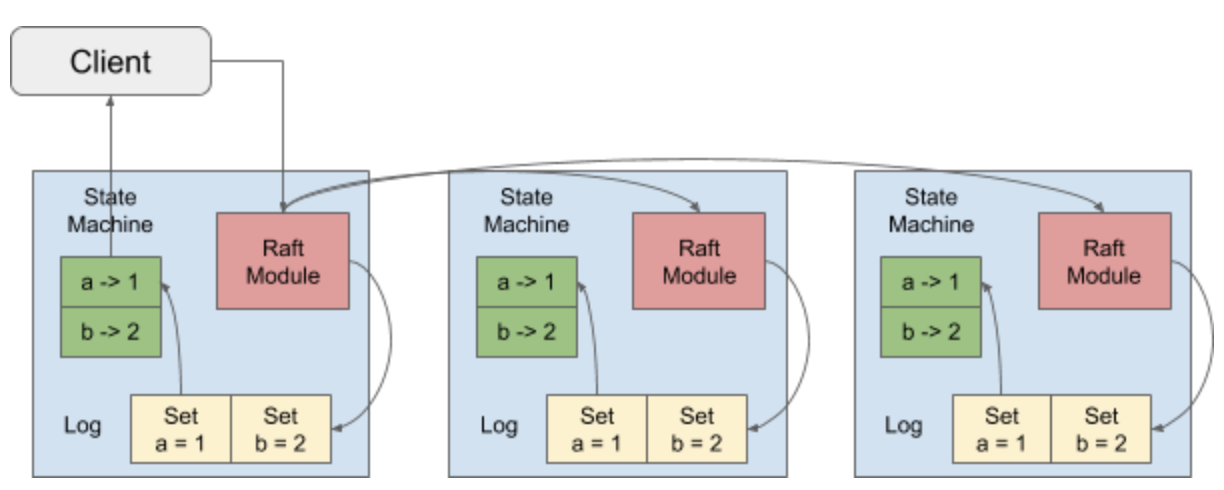
TiKV 使用 Raft 一致性算法来保证数据的安全,默认提供的是三个副本支持,这三个副本形成了一个 Raft Group。
当 Client 需要写入某个数据的时候,Client 会将操作发送给 Raft Leader,这个在 TiKV 里面我们叫做 Propose,Leader 会将操作编码成一个 entry,写入到自己的 Raft Log 里面,这个我们叫做 Append。
Leader 也会通过 Raft 算法将 entry 复制到其他的 Follower 上面,这个我们叫做 Replicate。Follower 收到这个 entry 之后也会同样进行 Append 操作,顺带告诉 Leader Append 成功。
当 Leader 发现这个 entry 已经被大多数节点 Append,就认为这个 entry 已经是 Committed 的了,然后就可以将 entry 里面的操作解码出来,执行并且应用到状态机里面,这个我们叫做 Apply。
在 TiKV 里面,我们提供了 Lease Read,对于 Read 请求,会直接发给 Leader,如果 Leader 确定自己的 lease 没有过期,那么就会直接提供 Read 服务,这样就不用走一次 Raft 了。如果 Leader 发现 lease 过期了,就会强制走一次 Raft 进行续租,然后在提供 Read 服务。
Multi Raft
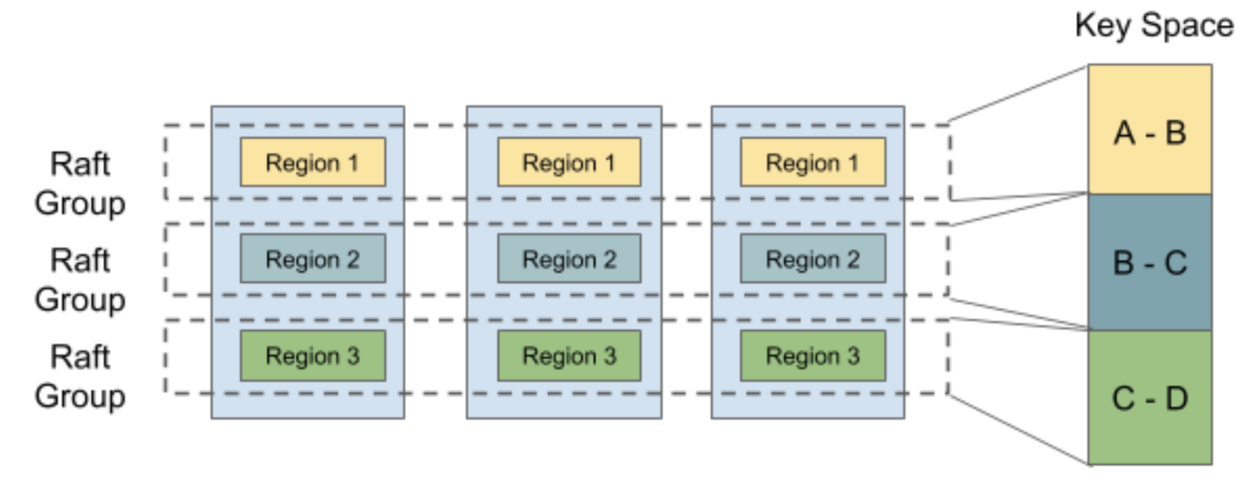
因为一个 Raft Group 处理的数据量有限,所以我们会将数据切分成多个 Raft Group,我们叫做 Region。切分的方式是按照 range 进行切分,也就是我们会将数据的 key 按照字节序进行排序,也就是一个无限的 sorted map,然后将其切分成一段一段(连续)的 key range,每个 key range 当成一个 Region。
两个相邻的 Region 之间不允许出现空洞,也就是前面一个 Region 的 end key 就是后一个 Region 的 start key。Region 的 range 使用的是前闭后开的模式 [start, end),对于 key start 来说,它就属于这个 Region,但对于 end 来说,它其实属于下一个 Region。
TiKV 的 Region 会有最大 size 的限制,当超过这个阈值之后,就会分裂成两个 Region,譬如 [a, b) -> [a, ab) + [ab, b),当然,如果 Region 里面没有数据,或者只有很少的数据,也会跟相邻的 Region 进行合并,变成一个更大的 Region,譬如 [a, ab) + [ab, b) -> [a, b)
Percolator
对于同一个 Region 来说,通过 Raft 一致性协议,我们能保证里面的 key 操作的一致性,但如果我们要同时操作多个数据,而这些数据落在不同的 Region 上面,为了保证操作的一致性,我们就需要分布式事务。
譬如我们需要同时将 a = 1,b = 2 修改成功,而 a 和 b 属于不同的 Region,那么当操作结束之后,一定只能出现 a 和 b 要么都修改成功,要么都没有修改成功,不能出现 a 修改了,但 b 没有修改,或者 b 修改了,a 没有修改这样的情况。
最通常的分布式事务的做法就是使用 two-phase commit,也就是俗称的 2PC,但传统的 2PC 需要有一个协调者,而我们也需要有机制来保证协调者的高可用。这里,TiKV 参考了 Google 的 Percolator,对 2PC 进行了优化,来提供分布式事务支持。
Percolator 的原理是比较复杂的,需要关注几点:
首先,Percolator 需要一个服务 timestamp oracle (TSO) 来分配全局的 timestamp,这个 timestamp 是按照时间单调递增的,而且全局唯一。任何事务在开始的时候会先拿一个 start timestamp (startTS),然后在事务提交的时候会拿一个 commit timestamp (commitTS)。
Percolator 提供三个 column family (CF),Lock,Data 和 Write,当写入一个 key-value 的时候,会将这个 key 的 lock 放到 Lock CF 里面,会将实际的 value 放到 Data CF 里面,如果这次写入 commit 成功,则会将对应的 commit 信息放到入 Write CF 里面。
Key 在 Data CF 和 Write CF 里面存放的时候,会把对应的时间戳给加到 Key 的后面。在 Data CF 里面,添加的是 startTS,而在 Write CF 里面,则是 commitTS。
假设我们需要写入 a = 1,首先从 TSO 上面拿到一个 startTS,譬如 10,然后我们进入 Percolator 的 PreWrite 阶段,在 Lock 和 Data CF 上面写入数据,如下:
Lock CF: W a = lock
Data CF: W a_10 = value后面我们会用 W 表示 Write,R 表示 Read, D 表示 Delete,S 表示 Seek。
当 PreWrite 成功之后,就会进入 Commit 阶段,会从 TSO 拿一个 commitTS,譬如 11,然后写入:
Lock CF: D a
Write CF: W a_11 = 10当 Commit 成功之后,对于一个 key-value 来说,它就会在 Data CF 和 Write CF 里面都有记录,在 Data CF 里面会记录实际的数据, Write CF 里面则会记录对应的 startTS。
当我们要读取数据的时候,也会先从 TSO 拿到一个 startTS,譬如 12,然后进行读:
Lock CF: R a
Write CF: S a_12 -> a_11 = 10
Data CF: R a_10在 Read 流程里面,首先我们看 Lock CF 里面是否有 lock,如果有,那么读取就失败了。如果没有,我们就会在 Write CF 里面 seek 最新的一个提交版本,这里我们会找到 11,然后拿到对应的 startTS,这里就是 10,然后将 key 和 startTS 组合在 Data CF 里面读取对应的数据。
上面只是简单的介绍了下 Percolator 的读写流程,实际会比这个复杂的多。
RocksDB
TiKV 会将数据存储到 RocksDB,RocksDB 是一个 key-value 存储系统,所以对于 TiKV 来说,任何的数据都最终会转换成一个或者多个 key-value 存放到 RocksDB 里面。
每个 TiKV 包含两个 RocksDB 实例,一个用于存储 Raft Log,我们后面称为 Raft RocksDB,而另一个则是存放用户实际的数据,我们称为 KV RocksDB。
一个 TiKV 会有多个 Regions,我们在 Raft RocksDB 里面会使用 Region 的 ID 作为 key 的前缀,然后再带上 Raft Log ID 来唯一标识一条 Raft Log。譬如,假设现在有两个 Region,ID 分别为 1,2,那么 Raft Log 在 RocksDB 里面类似如下存放:
1_1 -> Log {a = 1}
1_2 -> Log {a = 2}
…
1_N -> Log {a = N}
2_1 -> Log {b = 2}
2_2 -> Log {b = 3}
…
2_N -> Log {b = N}因为我们是按照 range 对 key 进行的切分,那么在 KV RocksDB 里面,我们直接使用 key 来进行保存,类似如下:
a -> N
b -> N里面存放了两个 key,a 和 b,但并没有使用任何前缀进行区分。
RocksDB 支持 Column Family,所以能直接跟 Percolator 里面的 CF 对应,在 TiKV 里面,我们在 RocksDB 使用 Default CF 直接对应 Percolator 的 Data CF,另外使用了相同名字的 Lock 和 Write。
PD
TiKV 会将自己所有的 Region 信息汇报给 PD,这样 PD 就有了整个集群的 Region 信息,当然就有了一张 Region 的路由表,如下:
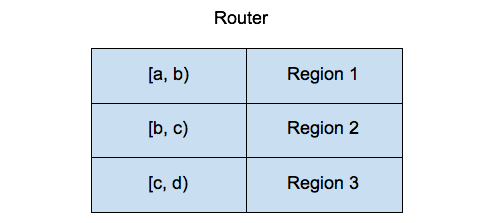
当 Client 需要操作某一个 key 的数据的时候,它首先会向 PD 问一下这个 key 属于哪一个 Region,譬如对于 key a 来说,PD 知道它属于 Region 1,就会给 Client 返回 Region 1 的相关信息,包括有多少个副本,现在 Leader 是哪一个副本,这个 Leader 副本在哪一个 TiKV 上面。
Client 会将相关的 Region 信息缓存到本地,加速后续的操作,但有可能 Region 的 Raft Leader 变更,或者 Region 出现了分裂,合并,Client 会知道缓存失效,然后重新去 PD 获取最新的信息。
PD 同时也提供全局的授时服务,在 Percolator 事务模型里面,我们知道事务开始以及提交都需要有一个时间戳,这个就是 PD 统一分配的。
RawKV
前面介绍了一些基础知识,下面将开始详细的介绍 TiKV 的读写流程。TiKV 提供两套 API,一套叫做 RawKV,另一套叫做 TxnKV。TxnKV 对应的就是上面提到的 Percolator,而 RawKV 则不会对事务做任何保证,而且比 TxnKV 简单很多,这里我们先讨论 RawKV。
Write
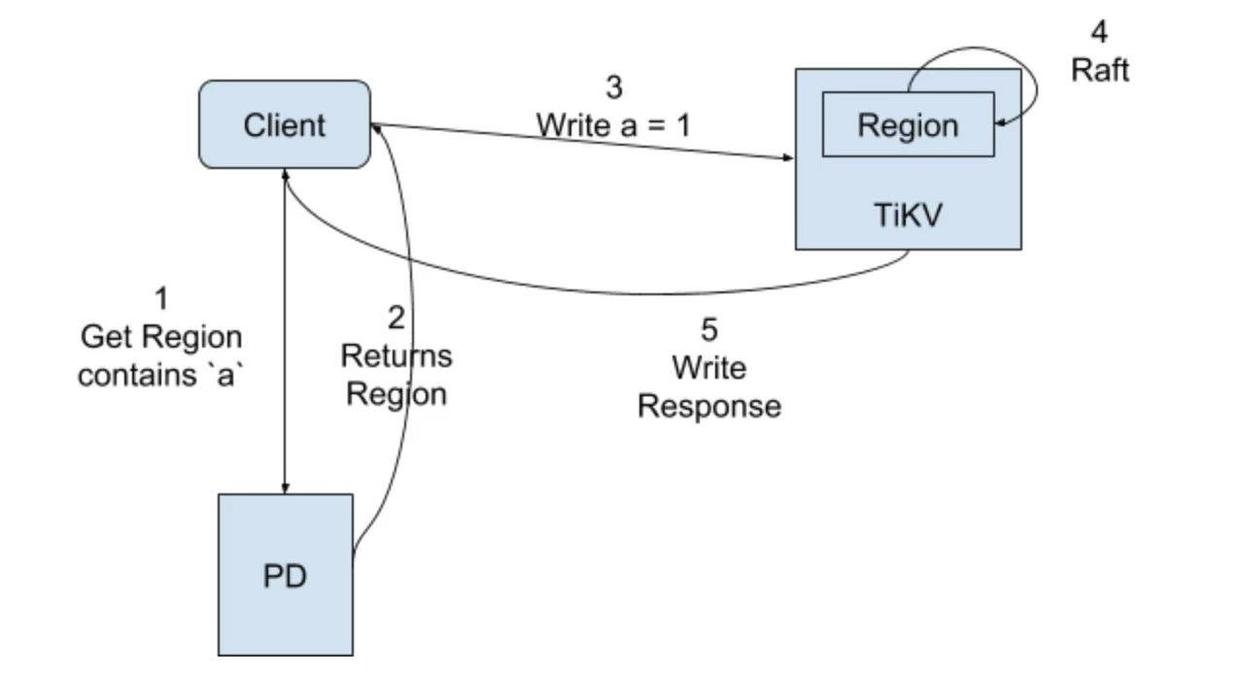
当进行写入,譬如 Write a = 1,会进行如下步骤:
-
Client 找 PD 问 a 所在的 Region
-
PD 告诉 Region 相关信息,主要是 Leader 所在的 TiKV
-
Client 将命令发送给 Leader 所在的 TiKV
-
Leader 接受请求之后执行 Raft 流程
-
Leader 将 a = 1 Apply 到 KV RocksDB 然后给 Client 返回写入成功
Read
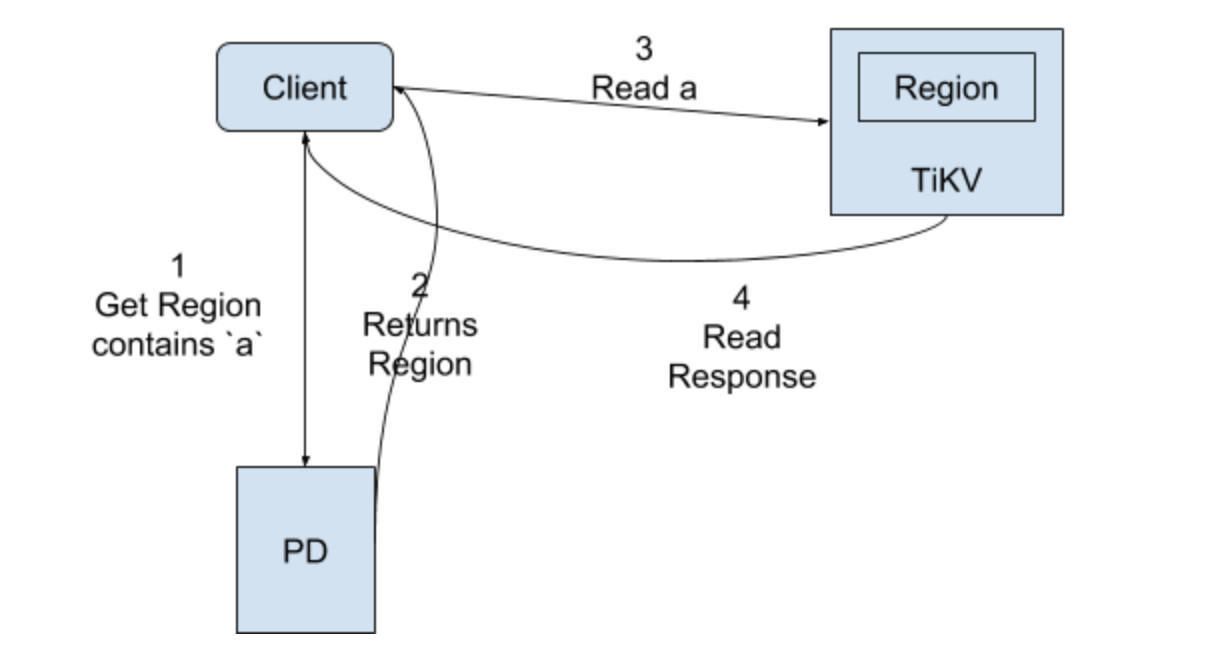
对于 Read 来说,也是一样的操作,唯一不同在于 Leader 可以直接提供 Read,不需要走 Raft。
TxnKV
Write
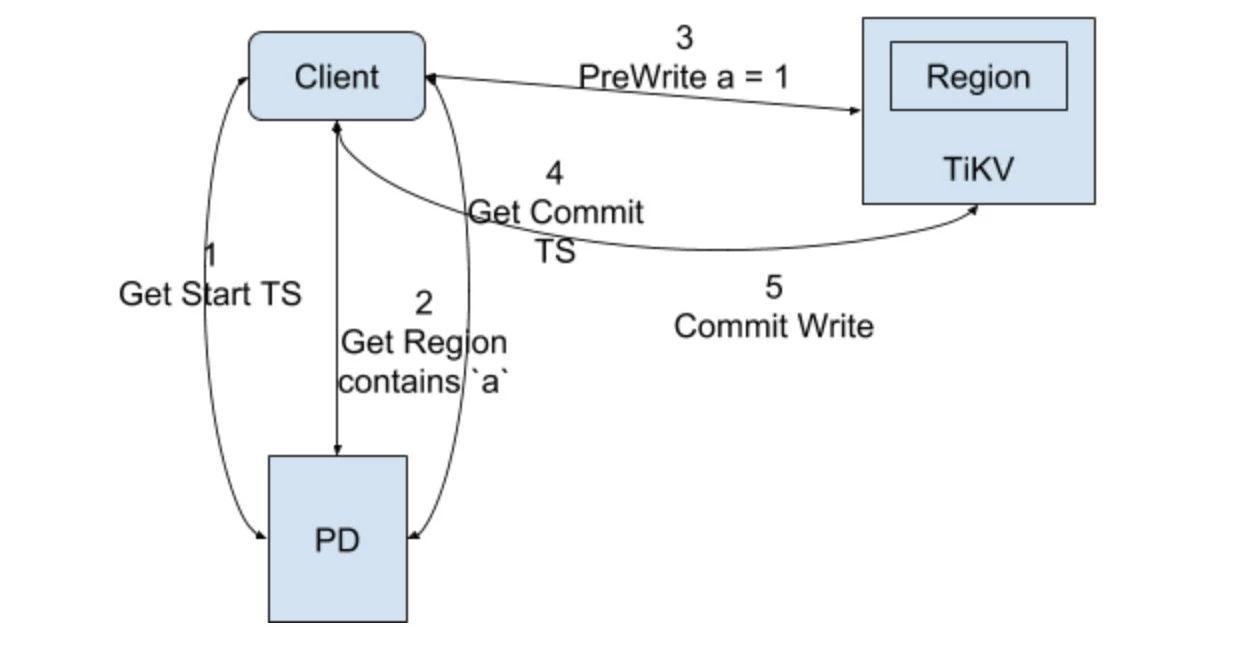
对于 TxnKV 来说,情况就要复杂的多,不过大部分流程已经在 Percolator 章节进行说明了。这里需要注意的是,因为我们要快速的 seek 到最新的 commit,所以在 RocksDB 里面,我们会先将 TS 使用 bigendian 生成 8 字节的 bytes,然后将这个 bytes 逐位取反,在跟原始的 key 组合存储到 RocksDB 里面,这样就能保证最新的提交存放到前面,seek 的时候就能直接定位了,当然 seek 的时候,也同样会将对应的 TS 按照相同的方式编码处理。
譬如,假设一个 key 现在有两次提交,commitTS 分别为 10 和 12,startTS 则是 9 和 11,那么在 RocksDB 里面,key 的存放顺序则是:
Write CF:
a_12 -> 11
a_10 -> 9
Data CF:
a_11 -> data_11
a_9 -> data_9另外,还需要注意的是,对于 value 比较小的情况,TiKV 会直接将 value 存放到 Write CF 里面,这样 Read 的时候只要走 Write CF 就行了。在写入的时候,流程如下:
PreWrite:
Lock CF: W a -> Lock + Data
Commit:
Lock CF: R a -> Lock + 10 + Data
Lock CF: D a
Write CF: W a_11 -> 10 + Data对于 TiKV 来说,在 Commit 阶段无论怎样都会读取 Lock 来判断事务冲突,所以我们可以从 Lock 拿到数据,然后再写入到 Write CF 里面。
Read
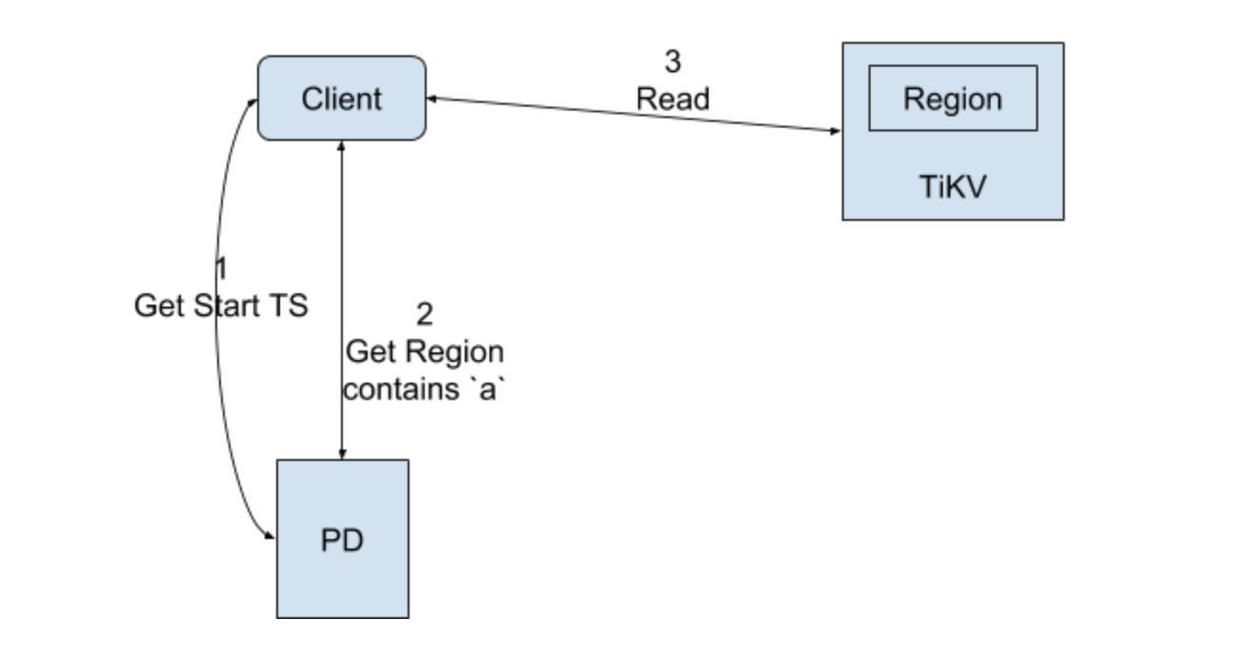
Read 的流程之前的 Percolator 已经有说明了,这里就不详细解释了。
SQL Key Mapping
我们在 TiKV 上面构建了一个分布式数据库 TiDB,它是一个关系型数据库,所以大家需要关注的是一个关系型的 table 是如何映射到 key-value 上面的。假设我们有如下的表结构:
CREATE TABLE t1 {
id BIGINT PRIMARY KEY,
name VARCHAR(1024),
age BIGINT,
content BLOB,
UNIQUE(name),
INDEX(age),
}上面我们创建了一张表 t1,里面有四个字段,id 是主键,name 是唯一索引,age 是一个索引。那么这个表里面的数据是如何对应到 TiKV 的呢?
在 TiDB 里面,任何一张表都有一个唯一的 ID,譬如这里是 11,任何的索引也有唯一的 ID,上面 name 就是 12,age 就是 13。我们使用前缀 t 和 i 来区分表里面的 data 和 index。对于上面表 t1 来说,假设现在它有两行数据,分别是 (1, “a”, 10, “hello”) 和 (2, “b”, 12, “world”),在 TiKV 里面,每一行数据会有不同的 key-value 对应。如下:
PK
t_11_1 -> (“a”, 10, “hello”)
t_11_2 -> (“b”, 12, “world”)
Unique Name
i_12_a -> 1
i_12_b -> 2
Index Age
i_13_10_1 -> nil
i_13_12_2 -> nil因为 PK 具有唯一性,所以我们可以用 t + Table ID + PK 来唯一表示一行数据,value 就是这行数据。对于 Unique 来说,也是具有唯一性的,所以我们用 i + Index ID + name 来表示,而 value 则是对应的 PK。如果两个 name 相同,就会破坏唯一性约束。当我们使用 Unique 来查询的时候,会先找到对应的 PK,然后再通过 PK 找到对应的数据。
对于普通的 Index 来说,不需要唯一性约束,所以我们使用 i + Index ID + age + PK,而 value 为空。因为 PK 一定是唯一的,所以两行数据即使 age 一样,也不会冲突。当我们使用 Index 来查询的时候,会先 seek 到第一个大于等于 i + Index ID + age 这个 key 的数据,然后看前缀是否匹配,如果匹配,则解码出对应的 PK,再从 PK 拿到实际的数据。
TiDB 在操作 TiKV 的时候需要保证操作 keys 的一致性,所以需要使用 TxnKV 模式。
结语
上面简单的介绍了下 TiKV 读写数据的流程,还有很多东西并没有覆盖到,譬如错误处理,Percolator 的性能优化这些,如果你对这些感兴趣,可以参与到 TiKV 的开发,欢迎联系我 tl@pingcap.com。
目录