导读
本文深入介绍了 TiKV 中的垃圾回收(GC)机制,包括其工作原理、处理流程以及如何通过 GC safepoint 清理旧版本数据。文章比较了传统 GC 和基于 compaction filter 的 GC 两种方式,指出了后者在优化性能方面的优势,讨论了监控 GC 进度、处理 GC 压力等常见问题。此外,文章还提供了针对物理空间回收问题的解决策略和操作建议,旨在帮助用户更好地理解和管理 TiKV 的 GC 过程,确保数据库的稳定与高效运作。
在前两篇文章中,我们介绍了:
- 为什么需要 GC?TiDB MVCC 版本堆积相关原理及排查手段
- TiDB 集群 GC 的定义、实现原理及常见问题:TiDB 组件 GC 原理及常见问题
在前面的文章我们知道,TiDB 中的 GC worker 最后是将 GC safepoint 上传到了 pd-server, 所有的 TiKV 实例会定期从 pd 上获取 GC safepoint,如果发生了变更,则会拿着最新的 GC safepoint 开启本地 TiKV 的具体 GC 工作。本文,我们将详细介绍 TiKV 侧 GC 的原理及常见的问题。
GC_key in TiKV
在上一篇文章中,我们知道 TiDB 在 GC 时,会通过 resolve locks 将集群中所有 GC safepoint 之前的 lock 清理掉,也就是到了 TiKV 之后,我们所有 GC safepoint 之前的事务状态都已经明确了,没有 lock 需要从所在分布式事务的 primary key 中获取事务状态了,我们可以放心大胆的删除旧版本数据了。那么,具体怎么删除呢?
我们来看下面的这个例子:
当前 key 一共有四个版本,写入顺序如下:
- 1:00 新写入或更新,数据存在 default cf
- 2:00 更新,数据存在 default cf
- 3:00 删除
- 4:00 新写入,数据存在 default cf
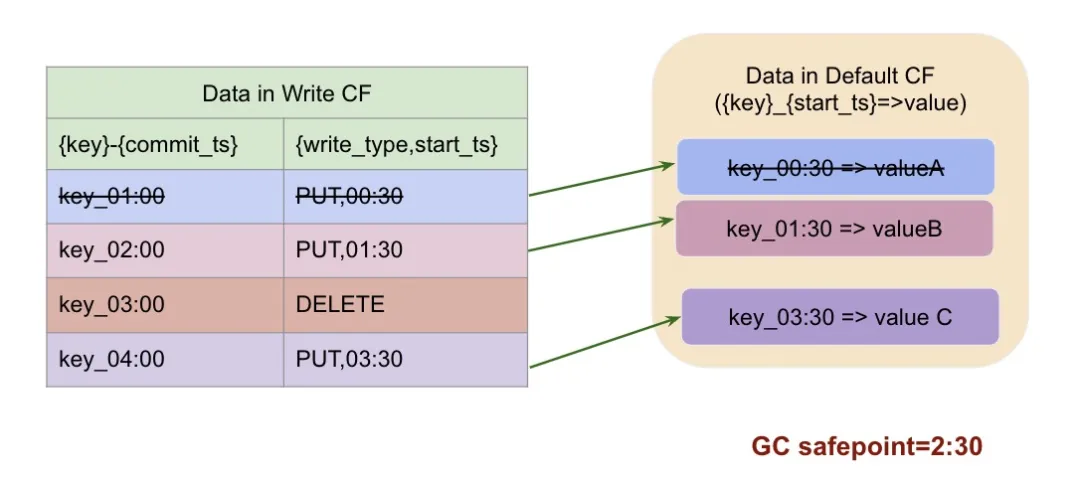
如果 GC safepoint 是 2:30 , 即最多保证到 2:30 这个时刻的快照一致性,那么我们会保留 2:30 这个时刻读到的版本:key_02:00=>(PUT,01:30), 他之前的版本数据全部删除,这里我们 key_01:00 对应事务的 write-cf 和 default cf 都会被删除掉。
如果 GC safepoint 是 3:30 呢?
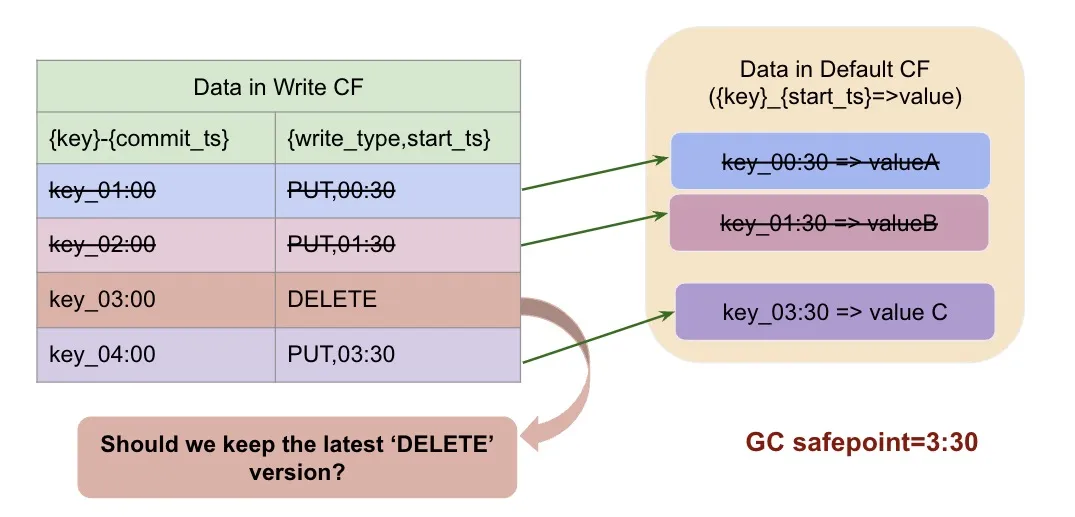
同样的,保留 3:30 这一时刻读到的 key_03:00=>DELETE,3:00 以前的旧版本就会被删除掉。
我们看到,3:30 读到的快照里 key_03:00 的事务是在删除这个 key, 那我们是否有必要保留 03:00 这条 MVCC 呢?
当然是不用了,所以正常情况下,如果 gc safepoint = 3:30, 那么这个 key 需要被 GC 的数据为:
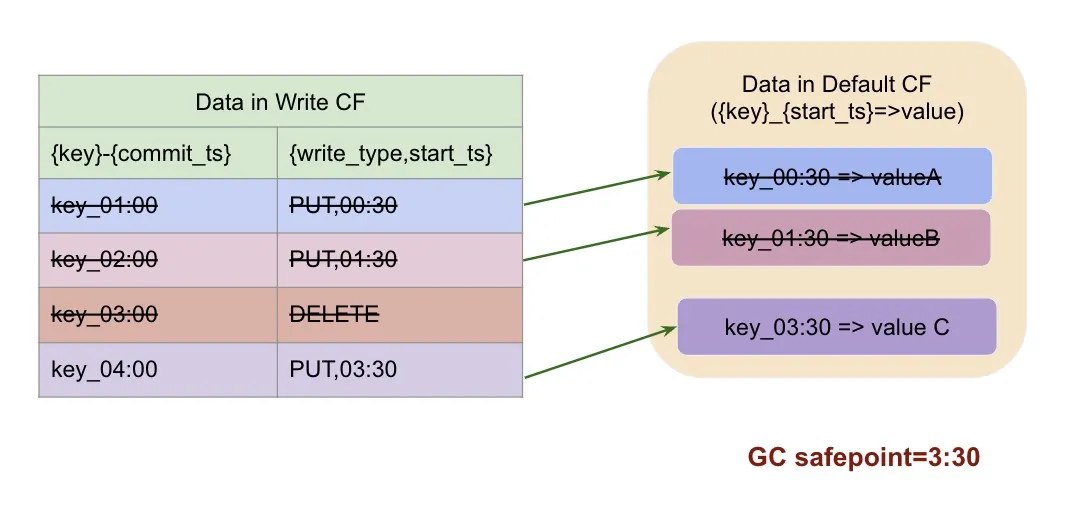
以上,就是对于某个明确的 key, GC 所需要具体清理的数据。TiKV 的 GC,则需要把当前 TiKV 实例上,所有的 key 进行扫描并删除符合条件的旧版本。
相关监控
gc_keys 因为需要读取当前 key 的所有版本才能确认是否删除旧版本,所以会对系统产生读压力,相关监控在 tikv-details->GC-> GC scan write/default details:记录了 GC worker 在执行过程中对 rocksdb write/default cf 的压力:

gc_keys 的 duration 可以在 tikv-details->GC-> GC tasks duration 里面看,如果这一块延迟比较高,说明 gc 压力比较大或者系统本身读写压力比较大影响到了 GC。
GC in TiKV
本章,我们来具体介绍每个 TiKV 实例上,GC 的执行原理和相关监控。TiKV 侧主要有两个常驻线程负责驱动和管理 GC:
- GC worker
- GC manager
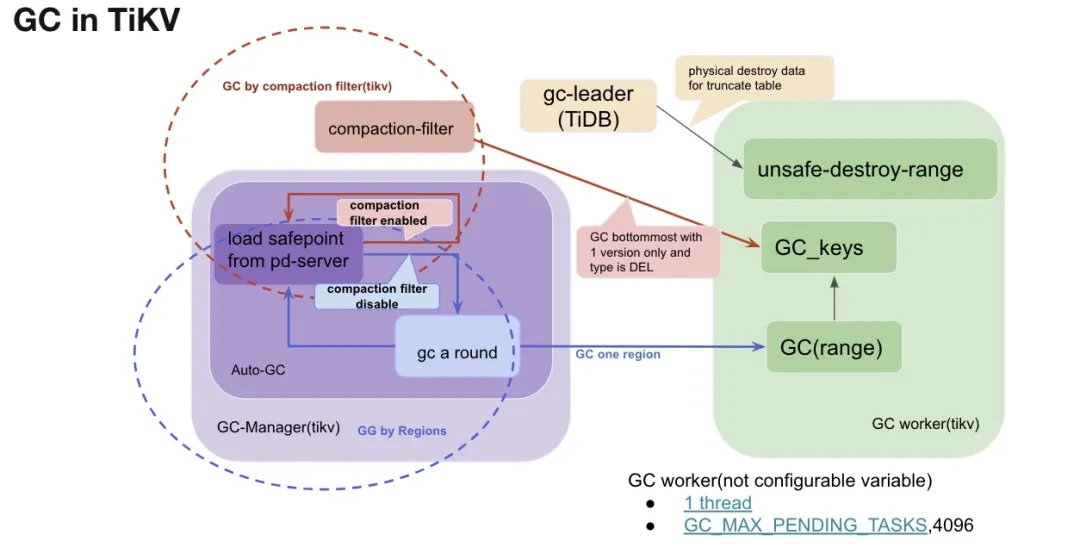
GC worker
每个 TiKV 侧有一个 GC worker 线程来处理具体的 GC 工作,TiKV 的 GC worker 主要负责处理以下两类请求:
- GC_keys,简言之,就是对于具体的 key, 扫描并删除符合条件的旧版本。详细过程我们已经在第一章描述过。
- GC(range):就是对于一块连续的范围的数据调用 GC_keys, 对指定范围内中的每个 key 单独进行 GC 处理。
- unsafe-destroy-range:对于连续范围的数据,直接物理清理。对应于上一篇文章提到的 truncate/drop table/partion.
当前我们 GC worker 一共有两个关键配置,且参数不可调:
- 线程数:GC worker 目前具体只有一个线程,当前代码中硬编码 ( https://github.com/tikv/tikv/blob/v6.3.0/src/server/gc_worker/gc_worker.rs#L1201 ),我们没有提供外部可配的配置。
- GC_MAX_PENDING_TASKS ( https://github.com/tikv/tikv/blob/v6.3.0/src/server/gc_worker/gc_worker.rs#L1201 )GC worker 队列中最多可以接收的任务数,为 4096。
相关监控
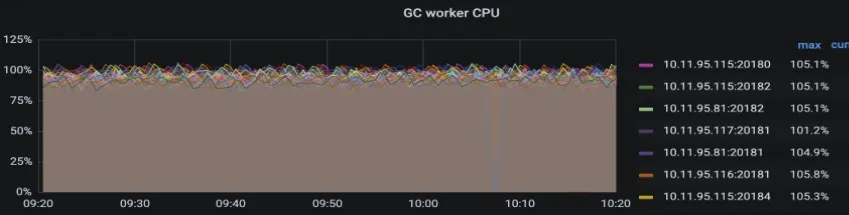
GC tasks QPS/duration: tikv-details->GC->GC tasks/GC tasks duration,一般发现 GC tasks duration 比较高时,需要结合 QPS 及 GC worker 的 CPU 是否够用。
GC worker CPU 的使用情况:tikv-details-> thread CPU->GC worker。
GC manager
GC manager 是 TiKV 中负责驱动 GC 工作的线程,主要步骤为:
- 同步 GC safepoint 到本地
- 全局指导实施具体的 GC 工作
同步 GC safepoint 到本地
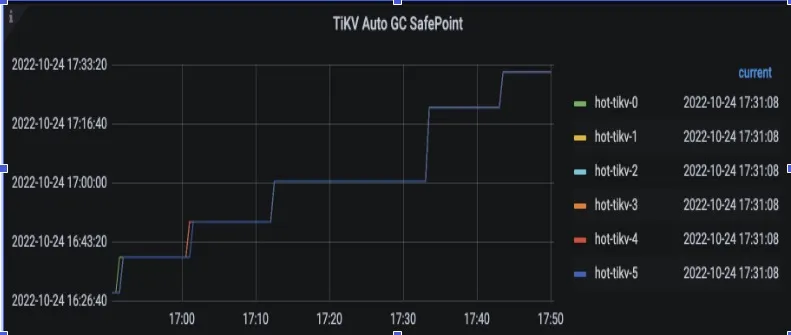
GC-manager 定期(每隔十秒)向 PD 索取最新 GC safepoint,将最新 GC safepoint 刷新到内存里,相关监控(tikv-details->GC):
常见问题
当监控中看到 TiKV auto GC safepoint 长时间卡住不推进时,意味着 tidb 侧的 GC 状态可能出现了问题,此时需要按照上一篇文章指导去排查 TiDB 侧 GC 卡住的原因。
实施 GC 作业
如 gc manager 发现 GC safepoint 往前推进了,则根据当前的系统配置开始实施具体的 GC 工作,这部分目前根据参数 gc.enable-compaction-filter 主要分为两种:
- 传统的 GC,即以 region 为单位调用 GC(range) 进行 GC。
- 借用 compaction filter 进行 GC(5.0 以后默认方式):这里不做真正的 GC,而是等到 rocksdb 的 compaction 时借助 compaction filter 的方式进行旧版本的回收。
TiKV GC 实施方式
下面我们具体来介绍一下这两种 GC 方式的原理及常见问题排查。
GC by region(传统 GC)
传统的 GC 即 gc.enable-compaction-filter 为 false 时,gc manager 会根据当前 TiKV 上的 region, 以 region 为单位逐一往下展开 GC。这个过程,我们叫 gc a round。
GC a round
在传统的 GC 种,一轮 GC 完成,我们定义为 gc a round。我们在定义 GC 的具体进度时,如果 gc a round 完成,则进度标记为 100%。如果 GC 进度一直到不了 100%,说明 GC 压力很大,会影响到具体物理空间的回收进度。GC 进度相关监控在 tikv-details->GC-> tikv-auto-gc-progress:我们也可以通过这个监控,观察每一轮 GC 在 TiKV 侧完成需要的时间。
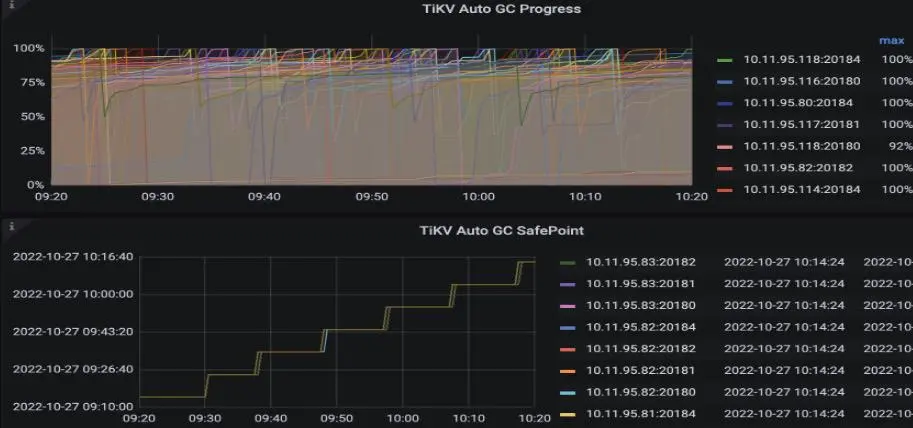
有了 gc a round 的概念,在具体的执行过程中,TiKV 是怎么来定义这个 a round 的呢?
简单的来说,gc manager 观察到 GC safepoint 有更新,从第一个 region 开始 gc 工作, 直到最后一个 region 的 gc 工作完成。
但是,如果在这个过程中,需要做的 gc 工作太多了,导致 GC safepoint 又往前推了,但是 gc 还没到达最后一个 region, 这个时候,我们是继续用旧的 GC safepoint 进行 GC ,还是用新的 safepoint 呢?
答案是实时用最新的 GC safepoint 去 gc 接下去的每个 region, 这是我们对传统 GC 的简单优化。
下面我们来看一下具体 GC 过程中,面对 GC safepoint 更新的情况,我们是怎么做的。
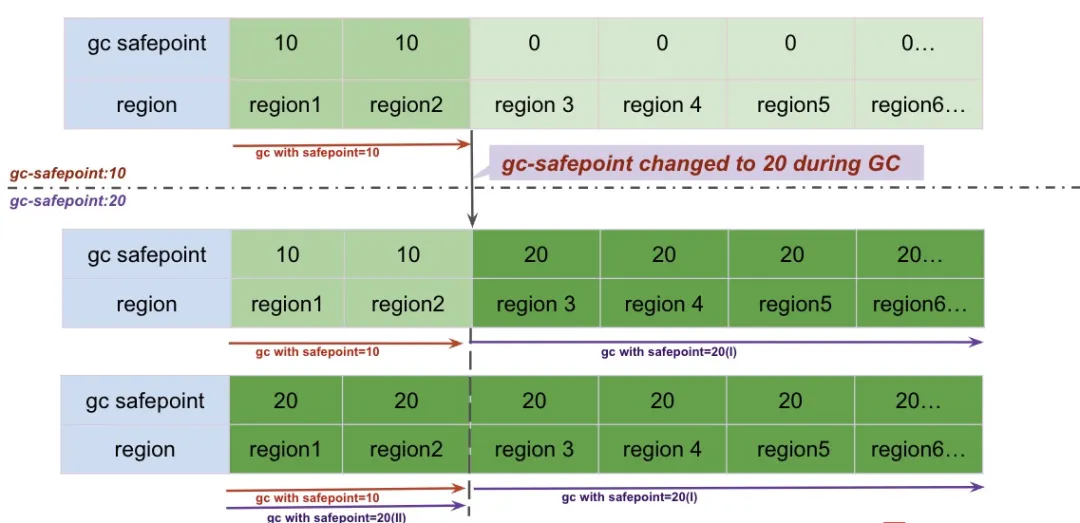
- GC 开始时,gc-safepoint 为 10 , 我们用 safepoint =10 GC 了 region 1 - region2
- 在 GC 完 region2 后,我们发现 GC safepoint 变成了 20 , 从这以后,我们拿着 20 继续 GC 剩下的 region.
- 所有的 region 的 gc 完毕后,我们继续从第一个 region 开始用 gc safepoint=20 进行 GC,直到所有的 region 都用 gc safepoint=20 GC 完毕。
以上,就是一轮 GC (https://github.com/tikv/tikv/blob/v6.3.0/src/server/gc_worker/gc_manager.rs#L437)完毕的例子。
常见问题
在传统的 GC 过程中,因为所有的旧版本在清理之前都要先扫出来,再写入 delete 版本到 rocksdb 的 mvcc。对整个系统的影响比较大,具体表现为:
-
影响 GC 进度:
GC worker 成为瓶颈。因为所有的回收都需要打到 GC worker 上,而 GC worker 只有一个线程,所以表现为它的 CPU 跑满,具体可以查看监控:tikv-details->thread CPU-> GC worker -
影响业务读写:
- raftstore 读写压力变大:GC worker 在执行具体的 gc_keys 任务时,需要将所有的数据版本扫出来,再将符合条件的删除。
- 因为短期内 rocksdb 的写入量变大,导致 L0 文件快速堆积而触发 rocksdb 的 compaction
-
物理空间使用量不减反增:
- 因为对 rocksdb 发起 DELETE, 在 rocksdb 内部最终也是转化为对当前 Key 写入一个新版本,所以在这种情况下,物理空间使用量反而会变大。
- 需要等 rocksdb 的 compaction 工作完成后才会真正的回收物理空间,而 rocksdb compaction 本身也需要先占用一大波临时空间。
综上,当业务对以上影响不能容忍时,我们的 workaround 都是:打开 gc.enable-compaction-filter 参数。
GC with compaction-filter
通过前面几章我们知道,使用传统的 GC 方式,我们会将 TiKV 层的 MVCC 一个个扫出来,根据 safepoint 确认其可以被删除后,再发送给 raftstore 也就是 rocksdb 一个(DELETE key)的操作。而 rocksdb 基于 LSM tree 实现,其内部也采用了 MVCC 机制,也就是当新写入,即使是删除写入时,旧版本数据不会被立刻被删除掉,而是与新写入的数据同时保留。
Why compaction in rocksdb
下面我们来通过 rocksdb 的架构,来简单了解一下 rocksdb 的 compaction 机制,熟悉的同学可以跳过本章。
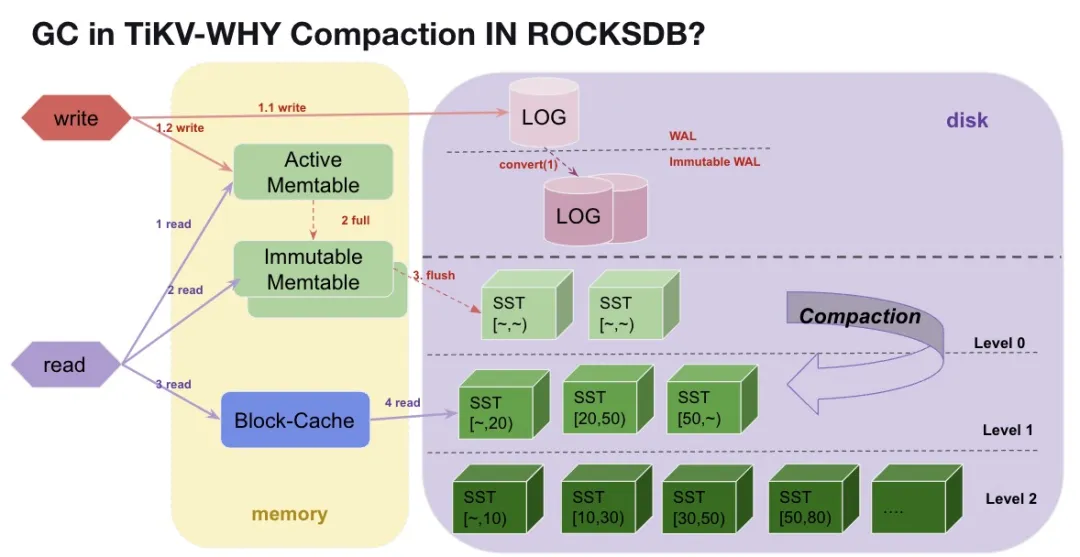
Rocksdb 为了提升写入的性能,采用了 LSM tree 的架构。
Rocksdb 写入流程
Rocksdb 在收到一个写入操作时(PUT(key=>Value))完整流程如下:
- 新写入 key 到 WAL 和 memtable 后返回成功。
- 1.1 rocksdb 会将数据直接 append 到 LOG 文件,也就是持久化到本地。
- 1.2 写入到一个活跃的 memtable 里面,因为在内存里,这个过程是非常快的,而且 memtable 里面的数据是有序的。
- 随着写入的数据越来越多,memtable 慢慢地就满了,这个时候,active memtable 就会被标记上不可更新,然后会生成一个新的 active memetable 存储新的业务写入。
- 对于不可更新的 memtable, 这部分数据会被直接 flush 到一个本地文件中,我们叫 SST 文件。
- 随着时间的推移,3 这样的 SST 文件会越来越多,注意直接从 memtable 转化过来的 SST,里面的数据虽然有序,但是数据范围都是全局的 [~,~],这类数据我们会放在第一层 Level 0。
Rocksdb 读取流程
Rocksdb 在收到一个读请求时,查找顺序如下:
- 从 memtable 中查找,如果能找到对应 key,返回数据
- 从 block-cache 里面找(block-cache 里的数据从 SST 中读取而来,下面我们简单称为 SST)。从 SST 文件中查找对应 Key。因为 L0 上 SST 文件是最新的,所以会先从 L0 文件中查找数据。且 L0 的 SST 都是从 memtable 直接转化为 SST 的文件数据范围是全局的,极端情况下需要从所有这类 SST 文件挨个寻找一遍。
Compaction 提升读取性能
从上面读流程可以看出,如果我们只有 L0 层的 SST 数据,随着 L0 层的文件越来越多,rocksdb 的读取性能也会越来越差。为了提升读性能,rocksdb 会对 L0 的 SST 文件进行归并排序,这个过程我们叫 compaction, rocksdb compaction 主要做的事情为:
- 对若干个 SST 文件进行归并排序。
- 只保留 rocksdb 视角的最新 MVCC 版本(GC)。
- 压缩下层到 level1~level6。
从上面流程我们可以看到,rocksdb 的 compaction 工作,包含了类似我们 GC 的一个工作,所以我们是否可以将 TiKV 的 GC 工作合并到 rocksdb 的 compaction 中呢?当然可以。
合并 TiKV GC 与 compaction 工作
Rocksdb 提供了 compaction-fitler 的接口,顾名思义,就是在 rocksdb compaction 的过程中,可以对每个正在处理的 key , 根据我们提供的 compaction-fitler 定义的过滤规则,决定是否需要将这个 key 在这个阶段直接过滤抛弃掉。
实现原理
下面,我们以 TiKV 的 GC 为例,看看在打开了 compaction filter 之后,rocksdb 的 compaction 过程中,我们是怎么回收数据的。
TiKV 中 Compaction-filter 只对 write-cf 生效
首先,TiKV 的 compaction-filter 只对 write-cf 生效,为什么呢?因为 write-cf 存的是 mvcc, 而 data cf 存的是具体数据。至于 lock cf 我们在 TiDB 侧已经介绍过,在 TiDB gc-safepoint 更新到 PD 后,lock cf 中是没有 gc safepoint 之前的 lock 了的。
Compaction 中直接过滤不需要的 mvcc key
接下来,我们来学习一个 mvcc key a 在一次 compaction 过程中是如何表现的:
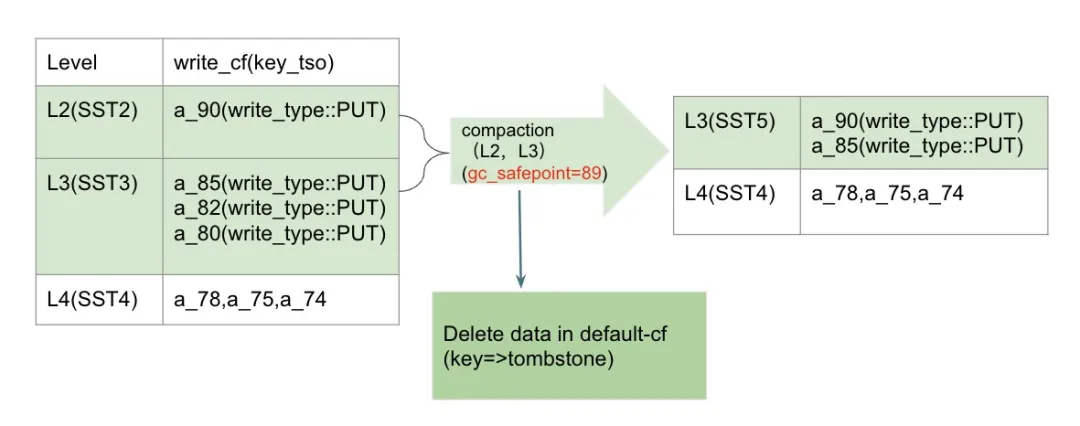
- a 这个 TiKV 的 mvcc key, 在 write_cf 里面对应的 key 是有 commit_ts 后缀的。初始化状态下,假设我们要 compact 左边两个绿色文件的 SST 文件,这两个文件分别在 L2 和 L3,compact 过后会存到 L3 这一层。
- a 在 L2 的这个 SST 文件中有 a_90
- a 在 L3 的这个 SST 文件中有 a_85 , a_82 , a_80
- 当前 gc_safepoint 是 89, 根据我们第一章 gc_key 的处理规则我们知道,此时我们需要保留老的旧版本为 a_85,即 a_85 之前的数据都可以删除。
- 从右边我们看到,新的 SST 文件中,只有 a_85 和 a_90 两个版本了。其他的版本及对应 default-cf 里面的具体数据,在 compaction 过程中一起删除掉了。
综上,通过 compaction-filter 的方式 GC 看到,与传统 GC 方式比:
- 省去了读 rocksdb 的过程。
- 删除(写入) rocksdb 的过程。
虽然对 compaction 产生了一些压力,但直接干掉了 GC 对 rocksdb 读写的影响,整体上性能是有大幅度优化的。
compaction 非 L6 的 SST 文件时,遇到 write_type::DEL
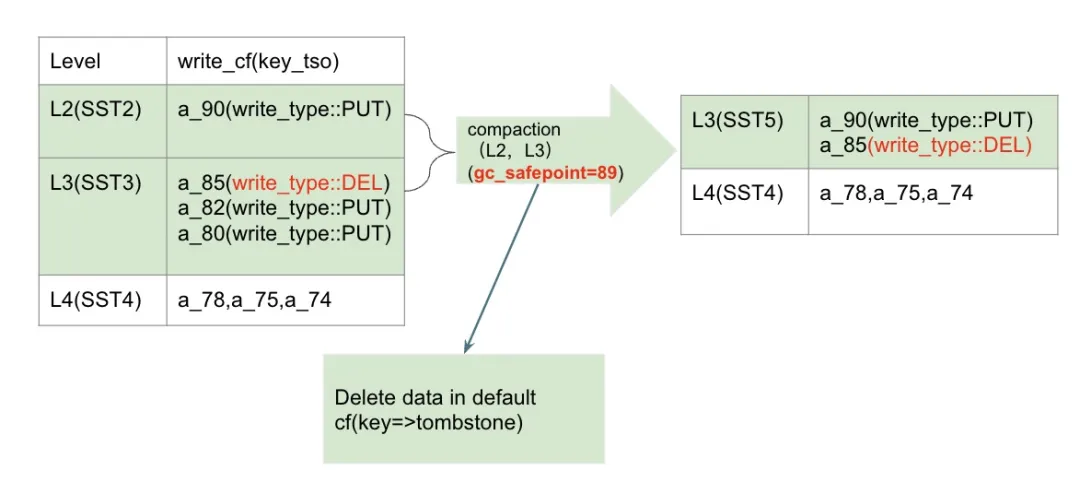
在第一章我们提到, 如果 GC 时,遇到 safepoint 对应 snapshot 的 mvcc 数据状态为 DEL 时,我们可以直接将这对 MVCC 在内的数据全部删除。但是在 compaction 时我们遇到 safepoint 前最新版本数据为 write_type::DEL 时,我们是否可以直接删除呢?
当然不可以。区别于 gc_keys 接口会将当前 GC 的那个 key 的所有版本都扫描出来,compaction 的时候只会扫描到当前 compaction 相关的若干 SST 文件中的版本,因此,如果我们直接将当前 level 的 write_type::DEL 删除,在更底层可能还有当前 key 的更旧版本。像上文例子中,如果我们将 a_85=>write_type::DEL 在本次 compaction 工作中直接删除,那么当用户读 gc_safepoint=89 这个快照时,因为 a_85 不见了,符合条件的最新版本是 a_78, 这个时候,咱们这个 safepoint=89 数据正确性就遭到了破坏。
Compaction filter 处理 write_type::DEL
从 gc_keys 这一章节我们知道,write_type::DEL 是一个特殊的存在,那在 compaction filter 开启时,这类 key 的处理是否也很特殊呢?是的。首先我们要考虑的是,我们什么时候才能删除 write_type::DEL 这种类型的数据呢?
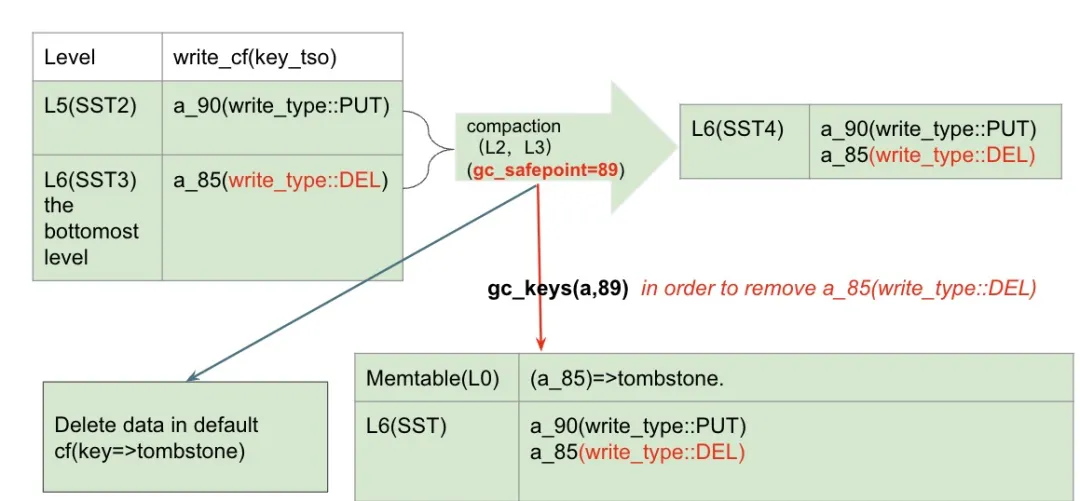
当我们 compact 最底层的 SST 文件时,当发现当前 key 符合以下条件时,我们可以通过 gc_keys(a,89) 的方式将该版本安全的回收:
- 当前 key 为 gc_safepoint 89 之前最新的版本
- 当前 key 在 L6 这一层,且当前 key 只剩下这一个版本了。意味着没有比 85 更早的历史版本了(确保 gc_keys 时不会产生额外的写入)
在这次 compaction 之后:
- 新的 SST 文件中依旧会包含一个 write_type::DEL 的版本。
- gc_keys 会向 rocksdb 写入一次 (DELETE,a_85),这是 write_cf 在 compaction filter 打开情况下,生成 tombstone 的唯一方式。
相关配置
从上文我们知道,在 compaction filter 打开的情况,大部份的物理数据回收是在 rocksdb write CF compaction 的时候完成的。对于每个 key:
- 对于 tso > gc safepoint 的,保留并跳过
- 对于 tso <= gc safepoint 的:根据类型确认是否保留最新一个版本,过滤旧版本
接下来,问题就变成,既然我们 GC 工作(物理空间回收)主要依赖 rocksdb 的 compaction,那么如何才能刺激 rocksdb 的 compaction 工作呢?
Rocksdb 的 compaction 除了自身会触发以外,TiKV 内部还放了一个线程去定期巡检每个 region 的状态,根据 region 内旧版本数据的情况来决定是否发起 compaction 工作。目前我们提供了 以下参数 ( https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file )用来控制这一步 region 检查的速度及判断一个 region 是否需要发起 compaction:
- region-compact-check-interval: 一般情况下不需要调整
- region-compact-check-step: 一般情况下不需要调整
region-compact-min-tombstones触发 RocksDB compaction 需要的 tombstone 个数。默认值:10000region-compact-tombstones-percent触发 RocksDB compaction 需要的 tombstone 所占比例。默认值:30region-compact-min-redundant-rows(从 v7.1.0 版本开始引入)触发 RocksDB compaction 需要的冗余的 MVCC 数据行所占比例。默认值:50000region-compact-redundant-rows-percent(从 v7.1.0 版本开始引入)触发 RocksDB compaction 需要的冗余的 MVCC 数据行所占比例。
特别注意的是,对于 7.1.0 之后的版本,因为我们引入了 mvcc 冗余版本的判断,大部份情况下我们都能处理掉。但是对于 v7.1.0 之前没有 mvcc 冗余版本检测的情况下,由于在 TiKV 内部, 但是对于 rocksdb 来说除了 lock cf 之外,其他 write-cf, data-cf 因为在 mvcc key 后面有一个 tso 作为后缀,也就是从 rocksdb 的视角来看,所有的 key 都是一次性写入的,而随着 GC 用 compaction-fitler 的方式,这样的 key 在 写入之后,就再也不会被删除,要等 GC。这里就产生了一个鸡生蛋的问题。对于这种情况下,我们需要通过手动 compact 对应 region 的方式,来刺激第一个鸡的生成。
相关监控
tikv-details->GC-> GC in Compaction-filter:
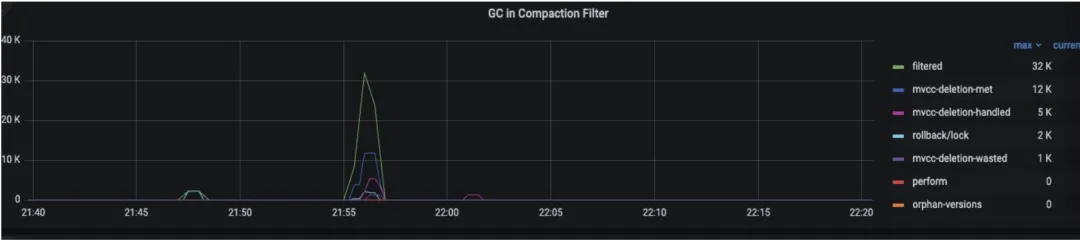
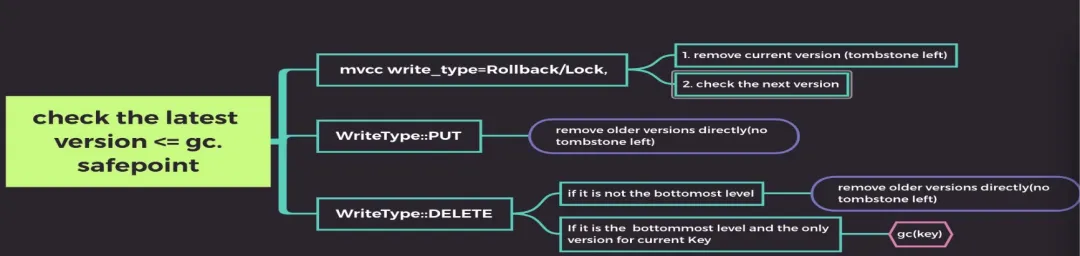
关键字段定义:在 compaction filter 过程中,遇到的 key-value 符合以下条件时:
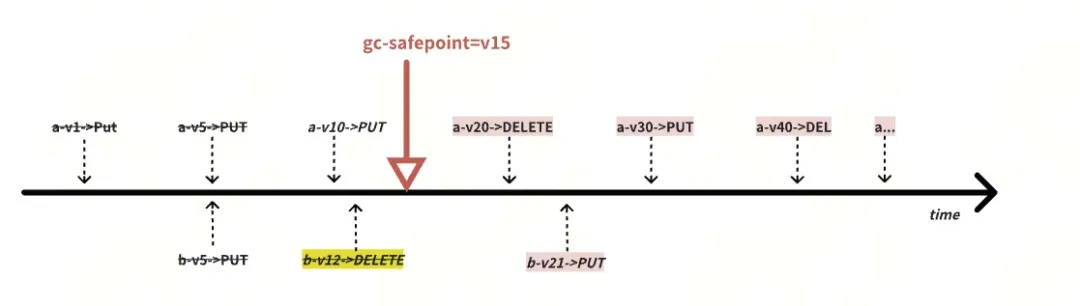
- 如果是 GC safepoint 之前,且不是最新版本的(a-v1,a-v5,b-v5):
- filtered: 被 compaction filter 直接过滤(物理删除,无任何新增写入)的旧版本数量,代表着 compaction-filter 真正有效回收的旧版本数据。这个指标如果没有值,意味着没有旧版本数据需要回收。
- Orphan-version: write_cf 里面的旧版本直接删除后,需要清理 default-cf 里面的数据,在删除 default cf 数据过程中失败了,此时会通过 GcTask::OrphanVersions 方式来清理 default-cf 里面的数据。这个有数据的话,可能是需要删除的数据过多导致 rocksdb 忙不过来。
- GC safepint 之前的最新版本(需要保留的最老版本 a-v10, b-v12 ):
- rollback/lock: 写入类型是 Rollback/Lock, 这种情况下,会有一个 tombstone 写入到 rocksdb 里面。
- mvcc_deletion_met: write_type=DELETE, 且是最底层的 SST 文件。
- mvcc_deletion_handled: 通过 gc_keys() 方式回收的 writetype=DELETE 的数据
- mvcc_deletion_wasted: 通过 gc_keys() 方式回收时,发现这个数据已经被清理掉了。
- mvcc_deletion_wasted+mvcc_deletion_handled = the number of keys that (type = delete,in the bottmost level, only have 1 version)
常见问题
Compaction-fitler 启用下,Delete 方式删除数据后,物理空间长期不释放的问题
Compaction filter 方式 GC 虽然能够直接在 compaction 阶段就把旧数据清理出局,能够大力缓解 GC 压力,但通过上面对原理的了解我们知道,正因为依赖 rocksdb 的 compaction 来回收数据,当 rocksdb 的 compaction 工作一直没有发生时,就会导致我们的数据在 GC safepoint 过了很久以后还是无法释放出物理空间。
因此在这种情况下,刺激 rocksdb 做 compaction 变得无比重要。
Workaround 1:通过参数调整 compaction 的频率
但是对于大量 Delete 的情况,因为这些数据在 Delete 之后,不再会有写入, 所以更加难以刺激 rocksdb 自动 compaction 。
在 v7.1.0 及之后版本,我们可以通过调节 mvcc 冗余版本行数相关参数,来刺激 rocksdb 的 compaction 工作,主要参数为:
region-compact-min-redundant-rows( 从 v7.1.0 版本开始引入) 触发 RocksDB compaction 需要的冗余的 MVCC 数据行数。默认值:50000region-compact-redundant-rows-percent( 从 v7.1.0 版本开始引入) 触发 RocksDB compaction 需要的冗余的 MVCC 数据行所占比例。
而在 v7.1.0 之前,我们没有这样的参数,所以这些版本我们只能通过手动 compact 来处理。
Workaround 2: 手动 compaction
假设我们用 Delete 的方式对一张表做了大量的数据删除。在删除时间过了 gc lifetime 之后,可以通过以下方式快速回收物理空间:
方法一:在业务低峰期,直接发起整表的 compaction
- 查询表的最小和最大 key (这个 key 是从 TiKV 计算而来的,已经转换成 memcomparable 了)
select min(START_KEY) as START_KEY,max(END_KEY) as END_KEY from information_schema.tikv_region_status where db_name='' and table_name=''-
使用 tikv-ctl 将最小和最大 key 转化为转化为 escaped 格式
tiup ctl:v7.5.0 tikv --to-escaped start_key tiup ctl:v7.5.0 tikv --to-escaped end_key -- example: -- tiup ctl:v7.5.0 tikv --to-escaped "7480000000000000FFB75F728000000000FF45431D0000000000FA" Starting component `ctl`: /home/tidb/.tiup/components/ctl/v7.5.0/ctl tikv --to-escaped 7480000000000000FFB75F728000000000FF45431D0000000000FA t\200\000\000\000\000\000\000\377\267_r\200\000\000\000\000\377EC\035\000\000\000\000\000\372 -
使用 tikv-ctl 进行 compact, 并在 转化后的字符串前面加上 z 前缀 ( https://github.com/pingcap/tidb/blob/master/docs/tidb_http_api.md ),依次 compact write cf 和 default cf(所有 TiKV 都需要):
----compact write cf----
tiup ctl:v7.5.0 tikv --host "127.0.0.1:20160" compact --bottommost force -c write --from "zt\200\000\000\000\000\000\000\377\267_r\200\000\000\000\000\377EC\035\000\000\000\000\000\372" --to "t\200\000\000\000\000\000\000\377\272\000\000\000\000\000\000\000\370"
Starting component `ctl`: /home/tidb/.tiup/components/ctl/v7.5.0/ctl tikv --host 127.0.0.1:20160 compact --bottommost force -c write --from zt\200\000\000\000\000\000\000\377\267_r\200\000\000\000\000\377EC\035\000\000\000\000\000\372 --to t\200\000\000\000\000\000\000\377\272\000\000\000\000\000\000\000\370
store:"127.0.0.1:20160" compact db:Kv cf:write range:[[122, 116, 128, 0, 0, 0, 0, 0, 0, 255, 183, 95, 114, 128, 0, 0, 0, 0, 255, 69, 67, 29, 0, 0, 0, 0, 0, 250], [116, 128, 0, 0, 0, 0, 0, 0, 255, 186, 0, 0, 0, 0, 0, 0, 0, 248]) success!
---以上无效果的话,尝试compact default cf---
tiup ctl:v7.1.1 tikv --host IP:port compact --bottomost force -c default --from 'zr\000\000\001\000\000\000\000\373' --to 'zt\200\000\000\000\000\000\000\377[\000\000\000\000\000\000\000\370'注意:根据前面清理 writeType::DELETE 的步骤我们知道,在最新版本是 DELETE 时,这个版本会变成要删除的 key 的唯一版本,他需要 compact 到 rocksdb 的最底层才会被清理,所以一般的,我们至少需要通过两次手动 compact 才能将物理空间回收,也就是上面的命令需要执行至少两次。
特别注意:rocksdb compact 需要临时空间,如果 TiKV 实例的临时空间并不充裕的情况下,建议使用方法二拆分 compact 压力。
方法二:如果表内数据量比较大的话,为降低对集群业务的性能影响,可以将整表的 compact 变为按 region 为单位进行 compact:
-
查询当前表的所有 region 数据:
select * from information_schema.tikv_region_status where db_name='' and table_name='' -
对于当前表内的所有 region,对其副本所在的 TiKV,依次执行以下命令:
- Tikv-ctl 查询当前 region 的 mvcc properties ( https://docs.pingcap.com/zh/tidb/stable/tikv-control#打印-region-的-properties-信息 ),如果发现 mvcc.num_deletes 和 write_cf.num_deletes 都比较小,说明这个 region 已经处理完毕,跳过继续处理下一个 region。
tikv-ctl --host tikv-host:20160. region-properties -r {region-id}
-- example--
tiup ctl:v7.5.0 tikv --host "127.0.0.1:20160" region-properties -r 20026
Starting component `ctl`: /home/tidb/.tiup/components/ctl/v7.5.0/ctl tikv --host 127.0.0.1:20160 region-properties -r 20026
mvcc.min_ts: 440762314407804933
mvcc.max_ts: 447448067356491781
mvcc.num_rows: 2387047
mvcc.num_puts: 2454144
mvcc.num_deletes: 9688
mvcc.num_versions: 2464879
mvcc.max_row_versions: 952
writecf.num_entries: 2464879
writecf.num_deletes: 0
writecf.num_files: 3
writecf.sst_files: 053145.sst, 061055.sst, 057591.sst
defaultcf.num_entries: 154154
defaultcf.num_files: 1
defaultcf.sst_files: 058164.sst
region.start_key: 7480000000000000ff545f720380000000ff0000000403800000ff0000000004038000ff0000000006a80000fd
region.end_key: 7480000000000000ff545f720380000000ff0000000703800000ff0000000002038000ff0000000002300000fd
region.middle_key_by_approximate_size: 7480000000000000ff545f720380000000ff0000000503800000ff0000000009038000ff0000000005220000fdf9ca5f5c3067ffc1Tikv-ctl 手动 compact 当前 region ,执行完毕后,继续循环执行上一步检查 region 的 properties 是否发生变化。
tiup ctl:v7.5.0 tikv --pd IP:port compact --bottommost force -c write --region {region-id}
tiup ctl:v7.5.0 tikv --pd IP:port compact --bottommost force -c default --region {region-id}
--example--
tiup ctl:v7.5.0 tikv --host "127.0.0.1:20160" compact --bottommost force -c write -r 20026
Starting component `ctl`: /home/tidb/.tiup/components/ctl/v7.5.0/ctl tikv --host 127.0.0.1:20160 compact --bottommost force -c write -r 20026
store:"127.0.0.1:20160" compact_region db:Kv cf:write range:[[122, 116, 128, 0, 0, 0, 0, 0, 0, 255, 84, 95, 114, 3, 128, 0, 0, 0, 255, 0, 0, 0, 4, 3, 128, 0, 0, 255, 0, 0, 0, 0, 4, 3, 128, 0, 255, 0, 0, 0, 0, 6, 168, 0, 0, 253], [122, 116, 128, 0, 0, 0, 0, 0, 0, 255, 84, 95, 114, 3, 128, 0, 0, 0, 255, 0, 0, 0, 7, 3, 128, 0, 0, 255, 0, 0, 0, 0, 2, 3, 128, 0, 255, 0, 0, 0, 0, 2, 48, 0, 0, 253]) success!方法三:v7.1.0 之前,可以直接关闭 compaction-filter, 使用传统的 GC 方式。
这种方式在 GC 期间对系统的读写性能影响会非常大,慎用。
目录