
导读
本文将详细介绍如何通过 PingCAP 开源项目 AutoFlow 实现快速搭建基于 TiDB 的本地知识库问答机器人。如果提前准备好 Docker、TiDB 环境,整个搭建过程估计在 10 分钟左右即可完成,无须开发任何代码。
文中使用一篇 TiDB 文档作为本地数据源作为示例,在实际情况中,您可以基于自己的企业环境用同样的方法快速构造企业内部知识库问答机器人。
背景知识
AutoFlow 是 PingCAP 开源的一个基于 Graph RAG、使用 TiDB 向量存储和 LlamaIndex 构建的对话式知识库聊天助手。https://tidb.ai 也是 PingCAP 基于 AutoFlow 实现的一个 TiDB AI 智能问答系统,我们可以向 tidb.ai 咨询任何有关 TiDB 的问题,比如 "TiDB 对比 MySQL 有什么优势?"
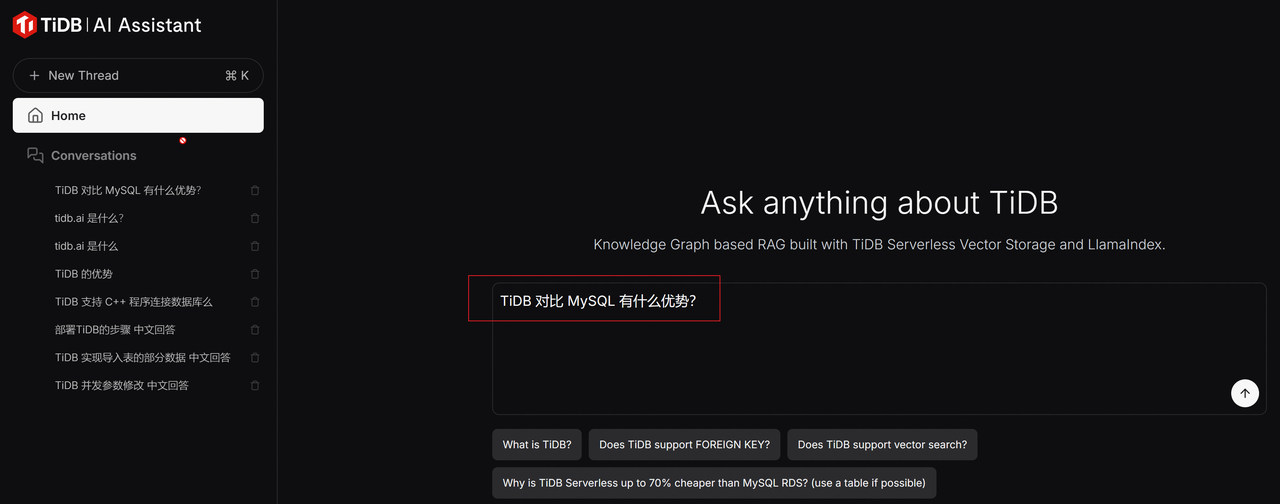
以下是 tidb.ai 的回答,从结果来说,tidb.ai 非常准确的理解了用户的问题并给出了相应的回答。它首先给出 TiDB 优势及 MySQL 限制的详细说明,然后给出一个结论性的总结,最后给出更多的参考链接。

基于 TiDB 实现问答系统的基本流程
相信通过前面的一些介绍,大家对 tidb.ai 的能力已经有了一个清楚的认识。TiDB 的使用人员很幸运,因为有了 tidb.ai,几乎任何有关 TiDB 的问题都可以在这个统一的平台得到相应的解答,一方面节省了自己人工去查找 TiDB 官方文档或 AskTUG 论坛的时间,另一方面 tidb.ai 拥有比普通大模型更专业的 TiDB 知识问答。
在技术实现上,tidb.ai 背后主要使用到 TiDB 的 Graph RAG 技术、TiDB 向量检索功能以及 LLM 大模型的使用。实际上,在 AutoFlow 出来之前,我们也可以通过 python 编程开发的方式基于 LLM+RAG+TiDB 实现一套问答系统。主要的开发流程如下:
- 准备私域文本数据
- 对文本进行切分
- 通过 Embedding 将文本转为向量数据
- 把向量数据保存到 TiDB
- 获得用户输入问题并进行向量化,然后从 TiDB 中进行相似度搜索
- 将上述片段和历史问答作为上下文,与用户问题一起传入大模型,最后输出结果
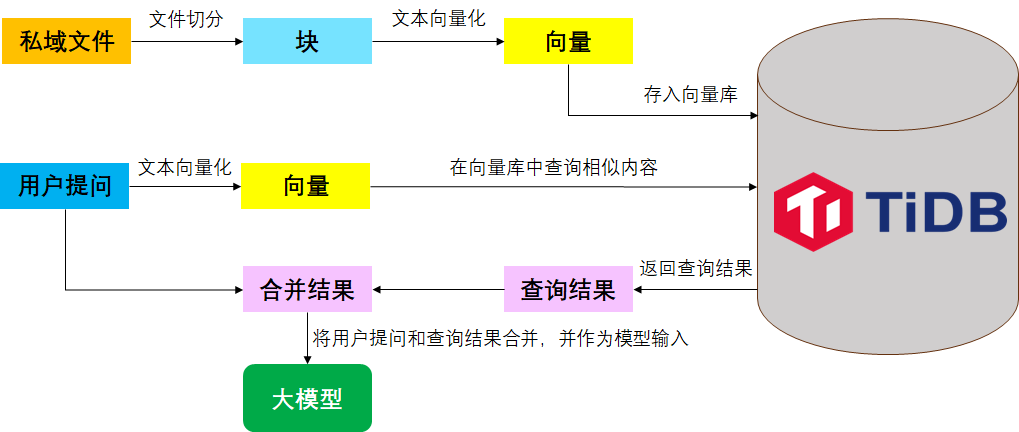
基于 AutoFlow 搭建本地知识库问答系统
基于 python 开发这样一套问答系统,一般要结合大模型常用开发框架如 Langchain,Langchain 集成了多种文件格式或 URL 网址的导入功能。如果希望给这个系统增加 Web 界面的能力,还需要引入前端可视化工具,如 Gradio 或 Steamlit。但是如果使用开源的 AutoFlow,即使对于没有任何开发背景的同学来说,搭建一套这样的问答系统也是一件轻而易举的事情,以下我们具体演示整个搭建的过程。
环境准备
在环境准备阶段,我们主要需要准备以下几项内容:
- Docker 环境
需要确保 AutoFlow 运行的机器上具备 Docker 运行环境,因为 AutoFlow 项目中的应用是基于 docker 容器环境运行的。有关 Docker 运行环境的准备工作本文不作说明,安装完成后可使用 docker run hello-world 命令验证安装成功。
- AutoFlow 项目
AutoFlow 是一个开源的 github 项目,地址为 https://github.com/pingcap/autoflow。下载之后需要在 AutoFlow 根目录下配置相关信息,包括 TiDB 数据库连接信息、EMBEDDING 维度等。
cat > .env <<'EOF'
ENVIRONMENT=production
# 可使用 python3 -c "import secrets; print(secrets.token_urlsafe(32))" 生成密钥
SECRET_KEY="some_secret_key_that_is_at_least_32_characters_long"
TIDB_HOST=<ip>
TIDB_PORT=<port>
TIDB_USER=<username>
TIDB_PASSWORD=<password>
TIDB_DATABASE=tidbai_test
# 非 TiDB serverless 环境需要将 TIDB_SSL 设置为 false
TIDB_SSL=false
EMBEDDING_DIMS=1024
EMBEDDING_MAX_TOKENS=4096
EOF- 带向量功能的 TiDB 环境
TiDB 最新发布的 v8.4 版本,支持向量搜索功能(实验特性)。向量搜索是一种基于数据语义的搜索方法,可以提供更相关的搜索结果。有关 TiDB 向量搜索功能,参考 https://docs.pingcap.com/zh/tidb/v8.4/vector-search-overview
需要确保 TiDB 8.4 集群正常运行,且已经创建有 AutoFlow 配置中指定的 TIDB_DATABASE 数据库(必须为空库)。
mysql> select version();
+--------------------+
| version() |
+--------------------+
| 8.0.11-TiDB-v8.4.0 |
+--------------------+
1 row in set (0.00 sec)
mysql> create database tidbai_test;
Query OK, 0 rows affected (0.52 sec)- 智谱 AI API Key
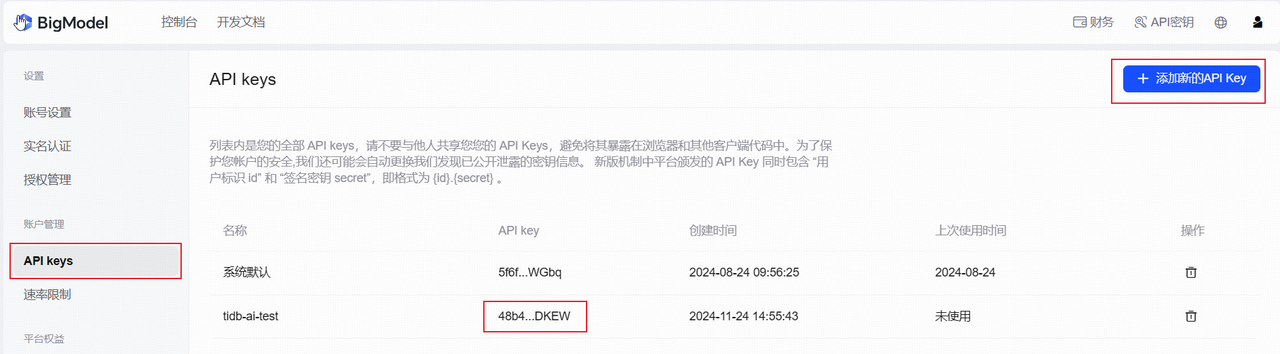
注册并登录智谱 AI 平台 https://bigmodel.cn/, 在个人中心->API kys 添加新的 API Key 并复制保存。注意,如果免费创建的用户已经超过一定的时效期限,API Key 将是无效的。
数据初始化
运行数据迁移以创建所需的表并创建初始管理员用户
cd autoflow
docker compose -f docker-compose-cn.yml run backend /bin/sh -c "alembic upgrade head"
docker compose -f docker-compose-cn.yml run backend /bin/sh -c "python bootstrap.py"
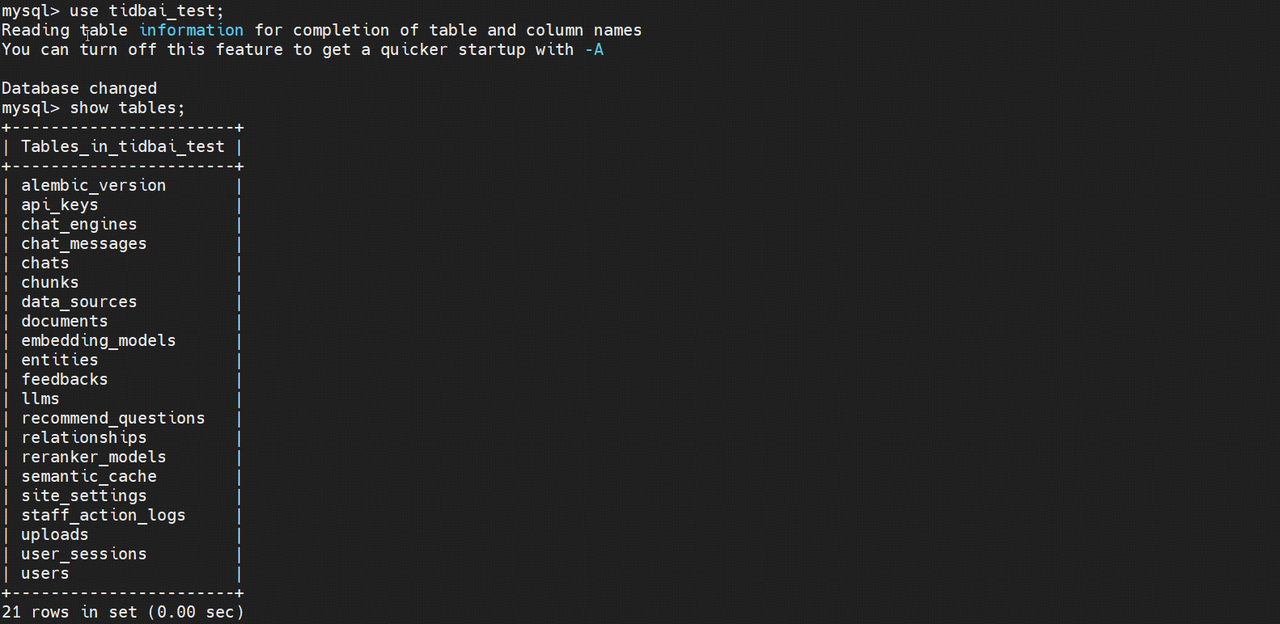
当看到如上输出结果时,说明初始化这一步已经成功(注意保存好红色字体中的密码以备后面使用)。这时我们去 TiDB 数据库中查看,发现 tidbai_test 这个库中已经自动创建出了相应的表并有一些初始化数据,符合预期。
启动知识库应用
运行以下 docker compose 命令启动知识库应用程序
cd autoflow
docker compose -f docker-compose-cn.yml up -d --force-recreate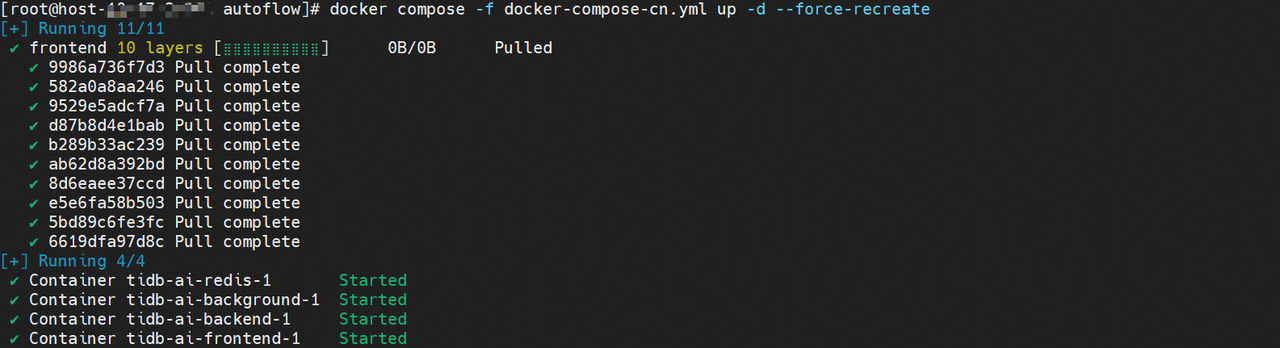
网页访问和配置知识库应用
应用启动成功后,我们可以直接通过默认的 3000 端口访问相应的界面进行下一步操作了。使用默认管理员用户 admin@example.com 以及上述应用启动打印的密码进行登录。
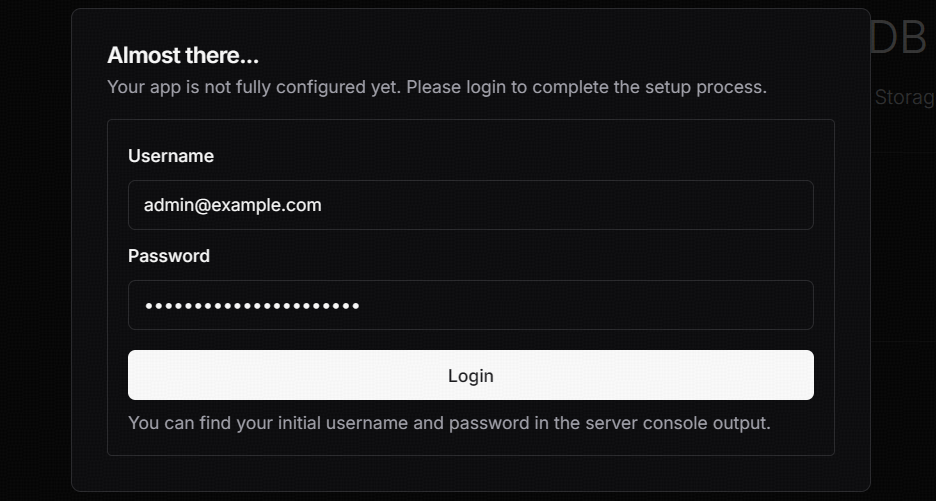
登录成功后,会弹出如下图所示的提示框,后面我们只要按照提示框一步步进行相应配置即可。
注意:3000 这个端口是 TiDB 数据库默认的 Grafana 端口号,如果把 AutoFlow 部署在和 Grafana 相同的节点,需要考虑端口冲突问题。
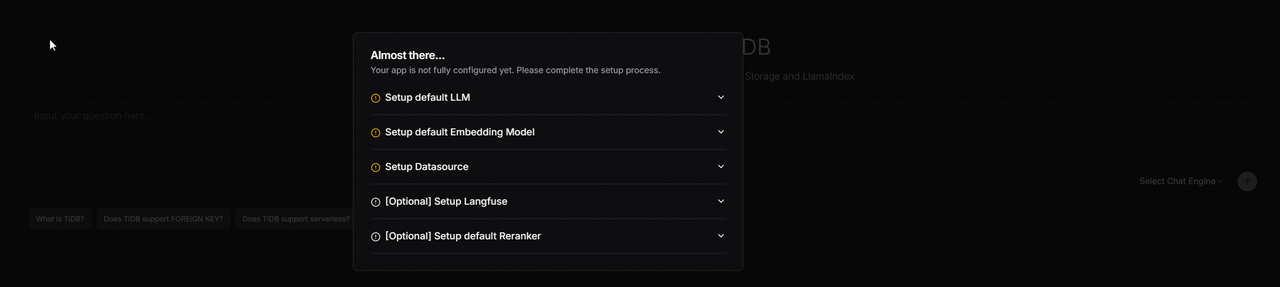
1.配置 LLM
此步骤需要配置的内容包括:
- 模型名称
- 模型提供商(选择 OpenAI Like)
- 模型型号(如 glm-4-0520)
- 智谱AI API KEY(见环境准备阶段)
- 高级选项-> api_base 路径(需与 LLM 对应)
- 是否默认 LLM(是或否)
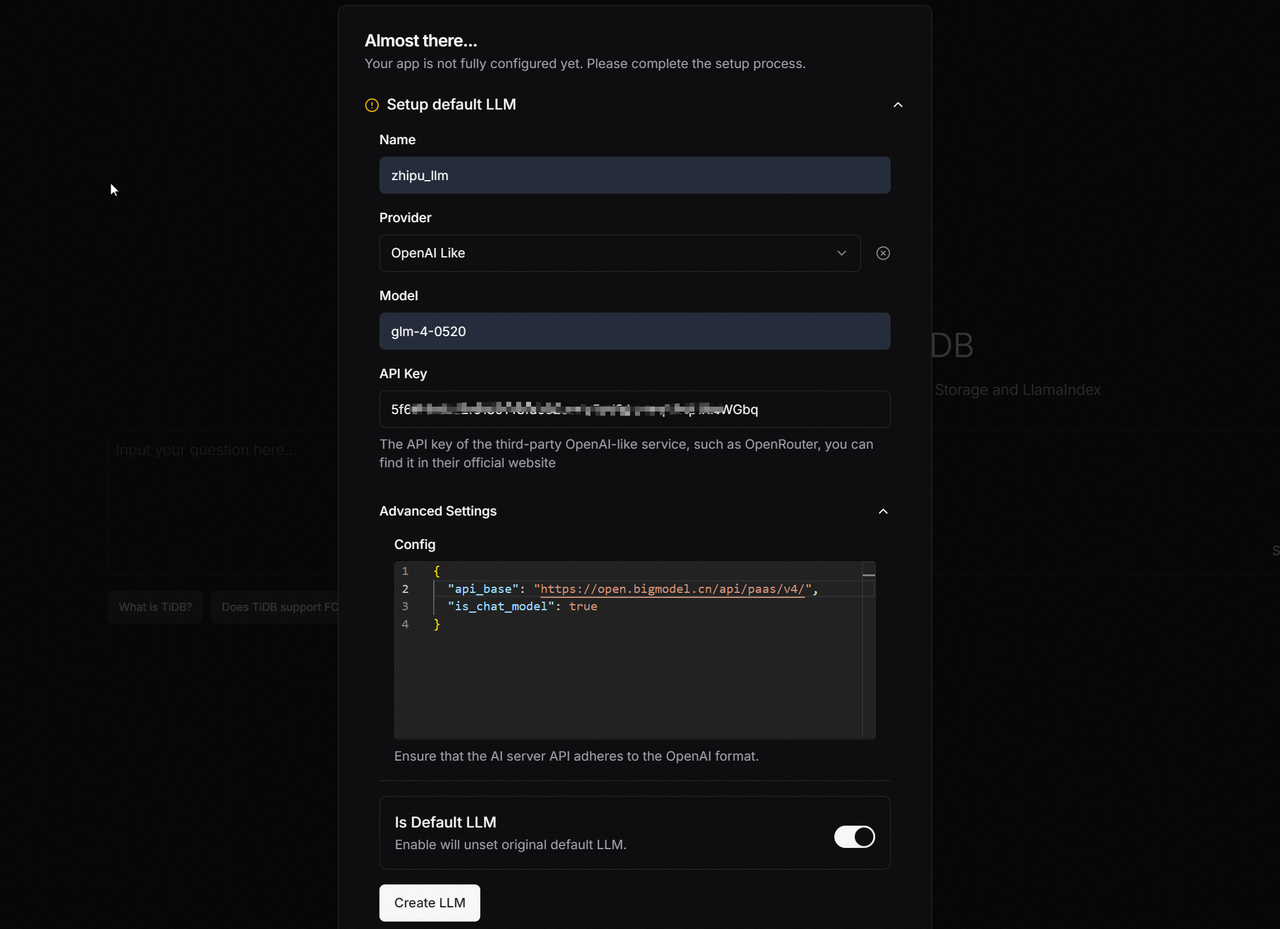
配置完成后,点击 Create LLM 创建 LLM 关联。需要注意的是,这里提供的 API Key 必须是一个有效的 Key,如果创建 API Key 的账户本身就过时,创建 LLM 时可能就会遇到以下报错。如果只是为了测试用途,可以重新注册一个账号并取得一个新的 API Key 试用。
Failed to create LLM
Error code: 429 - {'error': {'code': '1113', 'message': '您的账户已欠费,请充值后重试。'}}2.配置 Embedding 模型
此步骤需要配置的内容包括:
- embedding名称
- 模型提供商(选择 OpenAI Like)
- 模型型号(如 embedding-2)
- 智谱AI API KEY(与上述相同)
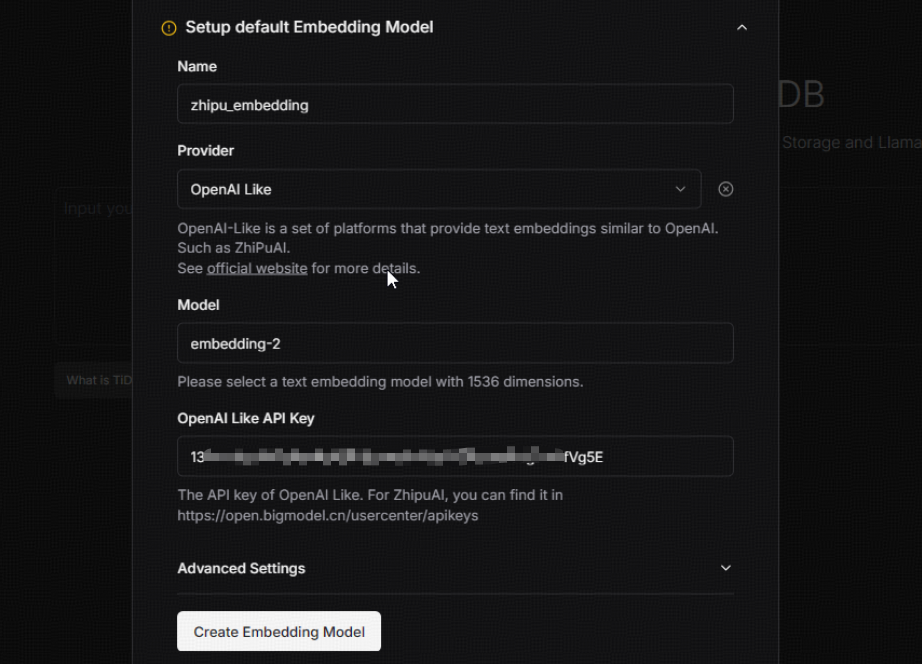
配置完成后,点击 Create Embedding Model 创建 Embedding 模型。需要注意的是,这里的 Model 必须要与环境变量中的 EMBEDDING_DIMS 对应,否则可能会出现以下类似报错。
Failed to create Embedding Model
Currently we only support 1536 dims embedding, got 1024 dims.3.配置数据来源
这里的数据来源可以是本地文件,也可以是具体的网址。这里我们配置具体有关 TiDB 和 MySQL 兼容性的网页 https://docs.pingcap.com/zh/tidb/stable/mysql-compatibility 为数据来源。具体配置内容包括:
- 数据源名称
- 数据源描述
- 网页 URL(可以配置一个或多个)
- 是否 build 知识图谱 Index(是或否)
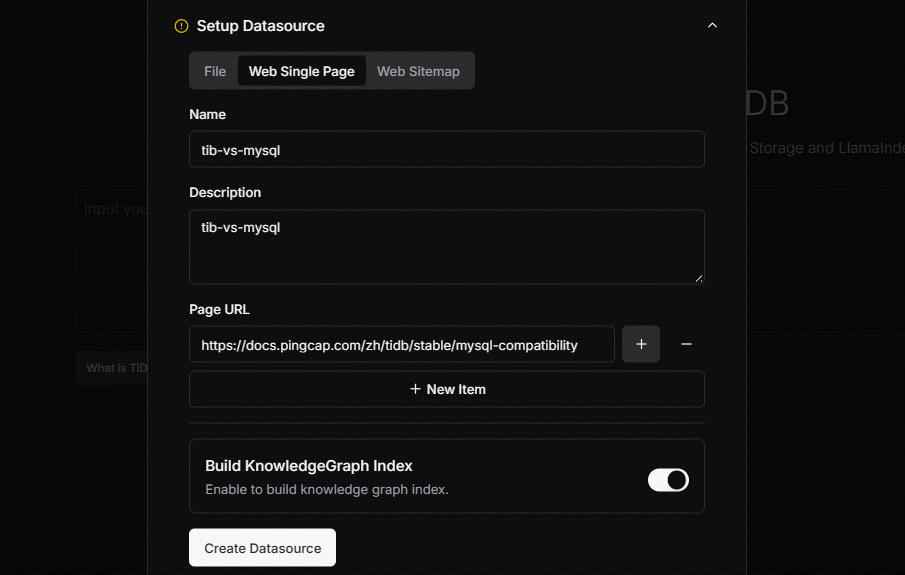
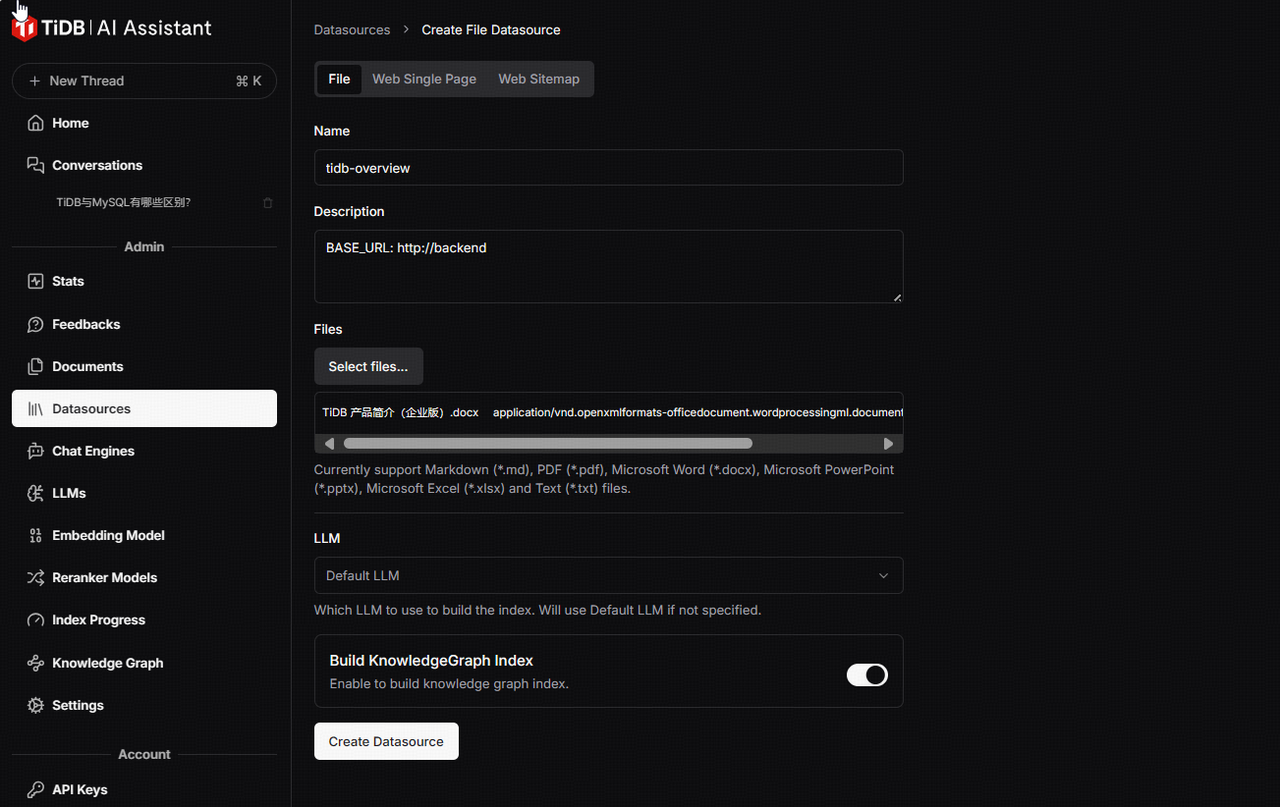
配置完成后,点击 Create Datasource 创建数据来源。当然,如果有本地文件,也可以直接导入本地文件并创建数据源。另外如果不是在初始化时配置数据源,我们也可以在后续的过程中手动添加更多的数据源,下图显示将一个本地的文档导入为数据源。
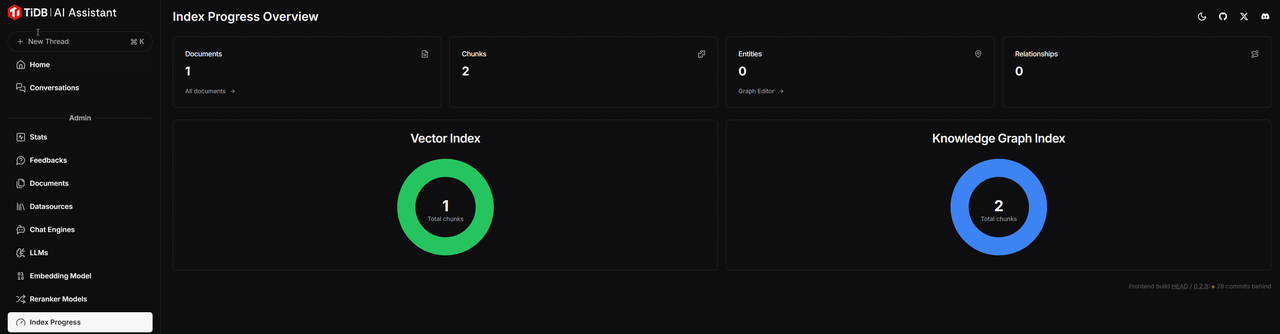
4.查看索引创建进度
上述步骤配置完成后,应用将基于配置的数据源进行向量化并创建索引,这需要一定的时间,具体耗时跟数据源的多少以及机器的配置都有关。通过页面左侧菜单栏-> Index Progress 查看索引创建进度,绿色代表索引创建成功,蓝色代表正在创建,红色代表创建失败。下图表示 Vector Index 已经创建成功,Knowlege Graph Index 正在创建中。当两个图表都变成绿色时,代表全部创建成功。
体验智能问答
至此,我们已经完成了配置数据源并完成了向量化存储及向量索引的创建。在网页的左侧菜单栏中,我们可以点击 Datasources 查看当前数据源, LLMs 查看当前 LLM,Embedding Model 查看 Embedding 模型。
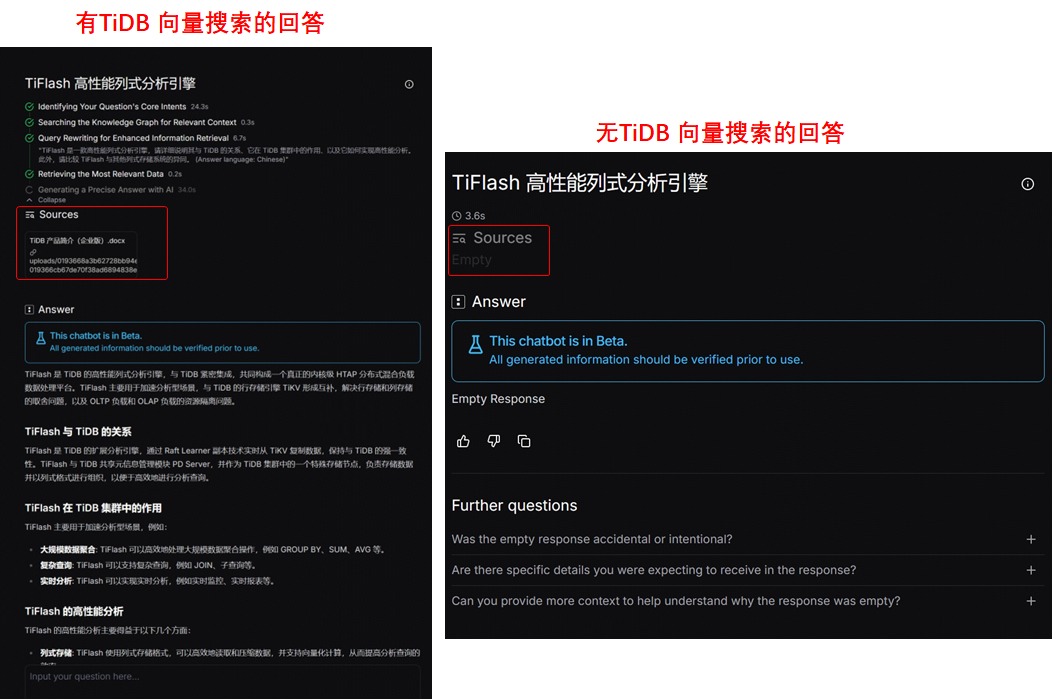
我们现在也可以开始向自己搭建的 tidb.ai 咨询有关 TiDB 的问题了,比如提问 "TiFlash 高性能列式分析引擎"。从结果可以看出,本地知识库问答机器人引用导入的文档并作出了相似回答,而假如我们删除数据源之后再提出相同的问题,它的回答是 Empty Response。下图对比充分说明了 TiDB 向量搜索在基础 LLM 大模型的增强能力。
目录