

黄东旭解析 TiDB 的核心优势
730
2023-04-16
在前面的源码分析中对 TiFlash 的计算层和存储层都进行了深入的分析,其中 TiFlash DeltaTree 存储引擎设计及实现分析 (Part 1) 、 TiFlash DeltaTree 存储引擎设计及实现分析 (Part 2) 对 TiFlash 存储层的读写流程进行了完整的梳理,如果读者没有阅读过这两篇文章,建议阅读后再继续本文的阅读。
这里简单回顾一下,TiFlash 存储层的数据是按表分开存储的,每张表的数据会根据 Handle Range 切分为多个 Segment,每个 Segment 包含 Stable 层和 Delta 层,其中 Segment 的大部分数据存储在 Stable 层,Delta 层只负责处理少部分新写入的数据,并且在写入数据达到一定阈值后会将 Delta 层的数据合并到 Stable 层。在读取时需要通过 DeltaTree Index 这个数据结构将 Stable 层和 Delta 层合并成一个有序的数据流,本文会对 DeltaTree Index 在读取时的作用以及如何维护 DeltaTree Index 进行讲解。
Stable 层的数据是按照 DTFile 的形式存储的,并且数据是按照 Handle 列和 Version 列全局有序的。Delta 层的数据分为磁盘和内存两部分,并且都是按照 ColumnFile 的形式组织的,但是 ColumnFile 内部不保证完全有序。
对于 Stable 层和 Delta 层合并这个问题,一个比较传统的做法是先对 Delta 层的不同 ColumnFile 进行内部排序,再通过多路归并的方式将 Stable 层和 Delta 层的数据合并成一个有序的数据流。但是这种方式需要涉及大量的比较操作以及入堆出堆操作等,因此性能比较差,所以我们希望能在这个基础上进一步优化性能。
我们考虑到既然多路归并比较耗时,那是否可以避免每次读都要重新做一次归并呢?答案是可以的。事实上有一些内存数据库已经实践了类似的思路。具体的思路是,第一次读取操作完成后,我们把多路归并算法产生的信息想办法存下来,从而使后续的读取可以重复利用这部分信息,对于新写入的数据可以通过增量更新的方式更新这部分信息即可。
那么现在的问题是如何存储多路归并算法产生的信息?一个比较朴素的想法是直接记录多路归并的操作顺序,在下一次读取时按照这个顺序读取即可。
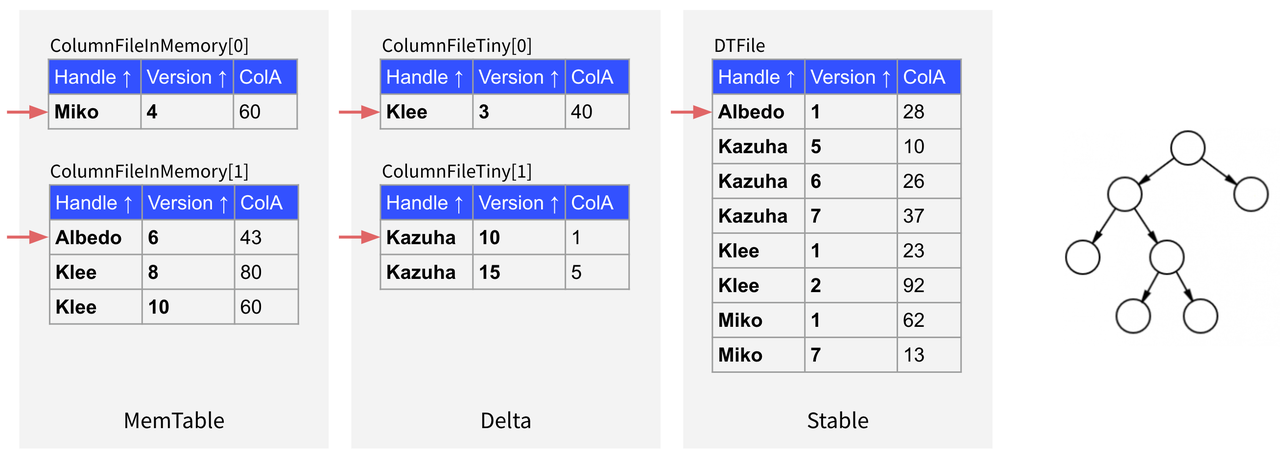
如下图所示,我们可以记录 Delta 层和 Stable 层合并后的有序数据流中的第一行来自 Stable 层的第一行数据,第二行来自 ColumnFileInMemory[1] 的第一行数据,第三行来自 Stable 层的第二行数据,并以此类推记录完整的操作顺序,这样在下一次读取时直接按照这个顺序读取就可以省略多路归并的过程,从而提高读取性能。但是这个方案的缺点也比较明显,就是我们需要为每一行数据记录相关的操作信息,因此会消耗大量的内存,而且这种记录方式不易进行增量更新,因此不太可行。
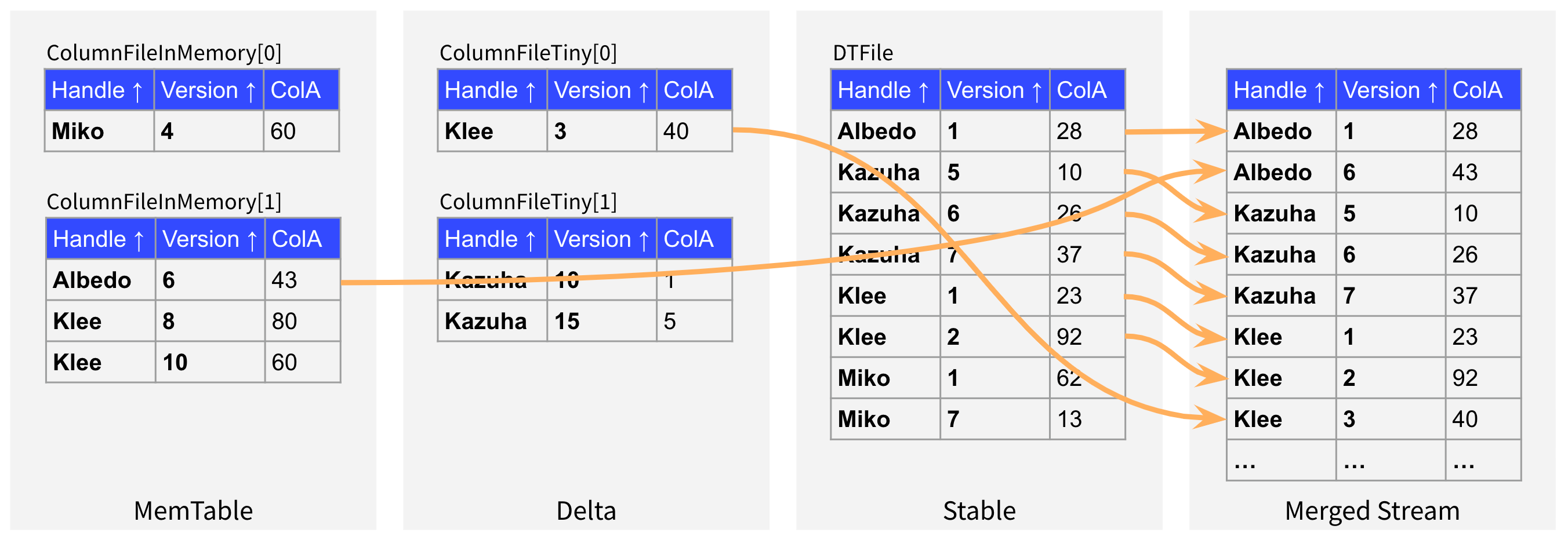
此时我们注意到 Stable 层的数据是全局有序的,所以 Stable 层数据在合并的过程中一定是按顺序读取的。因此我们不需要再记录最终的有序数据流和 Stable 层数据的对应关系,只需要记录每条 Delta 层数据的读取顺序,然后再记录一下两次 Delta 层读取操作之间需要读取的 Stable 数据的行数,就可以完整记录整个多路归并算法产生的信息。
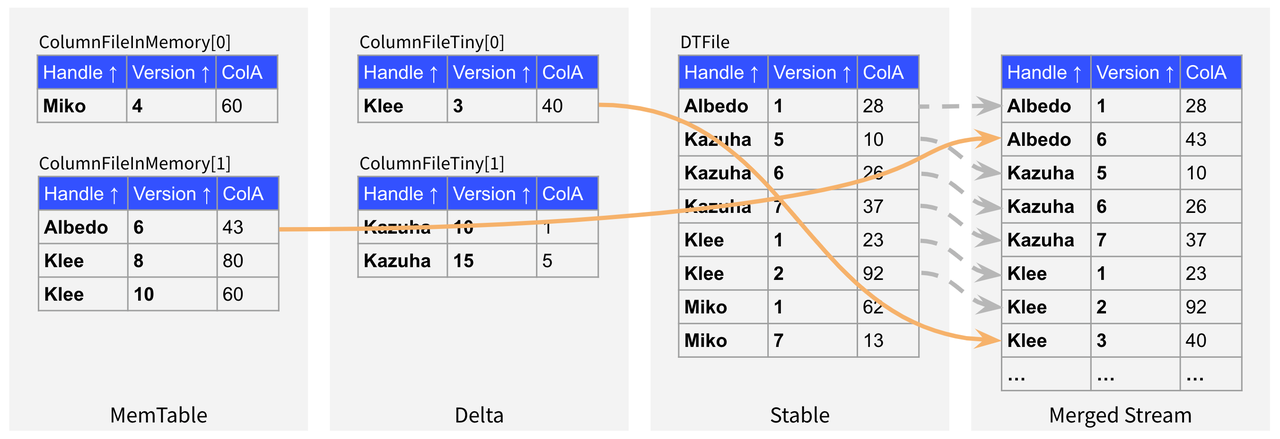
如下图所示,我们可以只记录在第一次 Delta 层读取操作之前需要先从 Stable 层读取一行数据,在第二次 Delta 层读取操作之前需要再从 Stable 层读取五行数据,同时记录每次 Delta 层读取操作的具体内容,并以此类推即可记录完整的操作顺序。考虑到 Delta 层数据只占整个 Segment 数据的极小部分,所以这种记录方式的内存消耗非常小,因此这种方案比较可行。那么最后剩下的问题就是如何通过增量更新的方式维护这部分信息,为此我们也进行了多次设计迭代,并参考了许多现有的数据库的方案,最终形成的设计方案就是本文要介绍的 DeltaTree Index。
DeltaTree Index 是一个类似 B+ 树的结构,为了演示方便,这里假设每个内部节点只有两个子节点,每个叶子节点可以容纳两个 Entry,如下图所示,其中 sid 在叶子节点中代表在处理当前 Entry 之前需要处理的 Stable 的数据行数,在内部节点中代表右子树中最小的 sid;is_insert 只在叶子节点中存在,代表这个 Entry 对应的是插入操作还是删除操作,其中删除操作代表的是删除 Stable 层某个位置的数据;delta_id 也只在叶子节点中存在,代表的是这个 Entry 对应数据在 Delta 层的偏移;count 在内部节点中代表对应子树中插入的数据行数减去删除的数据行数的值,而在叶子节点中 count 并没有实际存储下来,而是在遍历过程中计算得到,代表的是当前 Entry 之前插入的数据行数减去删除的数据行数的值;row_id 也是一个遍历过程中计算得到的值,代表的是对应 Entry 在合并之后的有序数据流中的位置。注意这里只是对这些字段做一个基础的介绍,在后续的具体流程中会对这些字段有更深入的讲解。
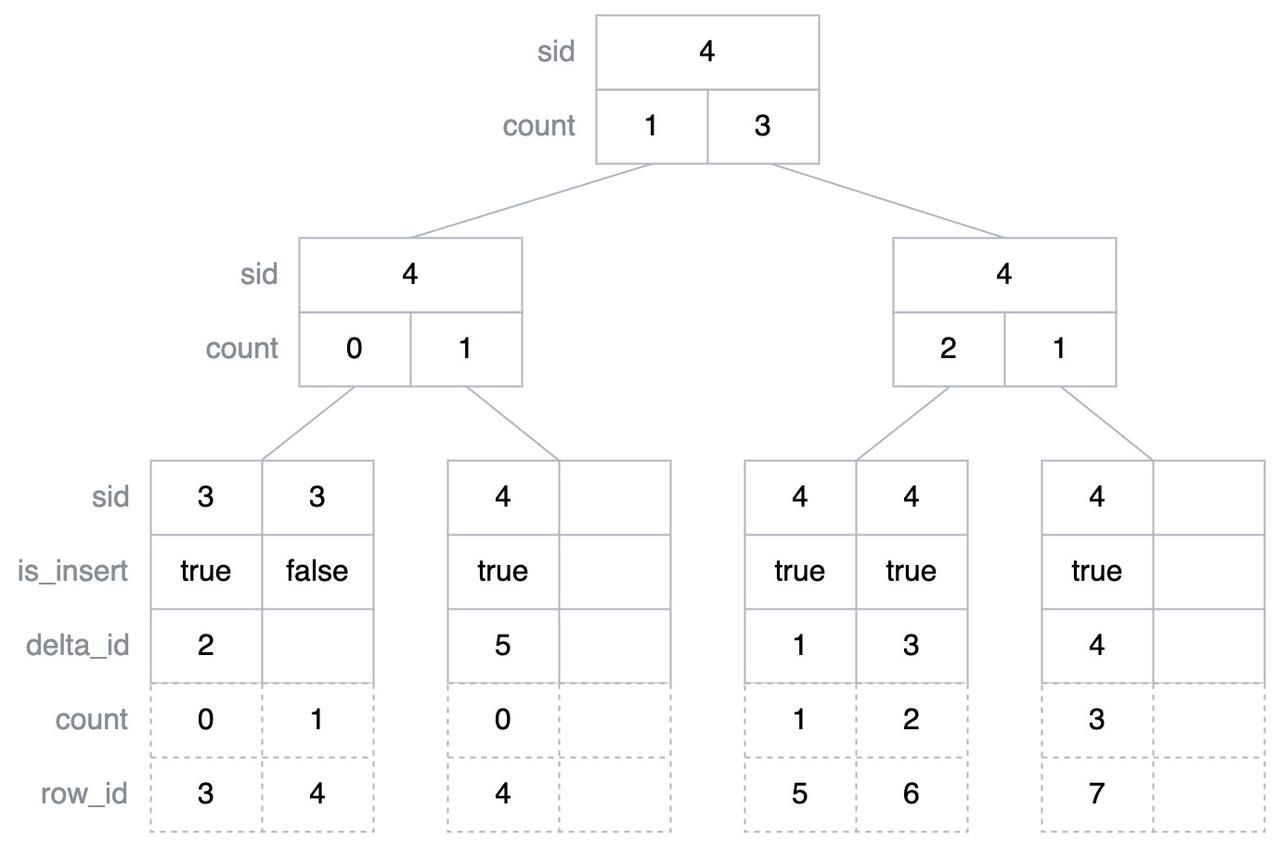
首先介绍一下 DeltaTree Index 的遍历操作,这个操作主要是根据 row_id 查找可能包含其对应 Entry 的最右侧的叶子节点,基本的思路是在遍历的过程中维护一个 count 变量,代表遍历过程中所有跳过的子树对应 count 字段值之和,由于内部节点中的 sid 代表的是其右子树中最小的 sid,因此内部节点的 sid 加上这里维护的 count 变量再加上其左子树的对应 count 值,就代表其右子树中最小的 row_id,将这个值与要查找的 row_id 比较即可以判断目标 row_id 是在左子树还是右子树中,然后继续向下遍历。
findRightLeafByRId(row_id) { node = root count = 0 while !isLeaf(node) { for i = 0; i < child; i++ { count = count + node[i].count if node[i].sid + count > row_id { count = count - node[i].count break } } node = node[i].child } return node }下面以查找 row_id = 7 所在的最右侧叶子节点为例演示一下上面的算法,首先从根节点开始遍历,此时 count 的初始值为 0,根节点的 sid 加上其左子树的 count 值小于要查找的 row_id,即右子树最小的 row_id 小于要查找的 row_id,因此接下来需要继续遍历右子树。
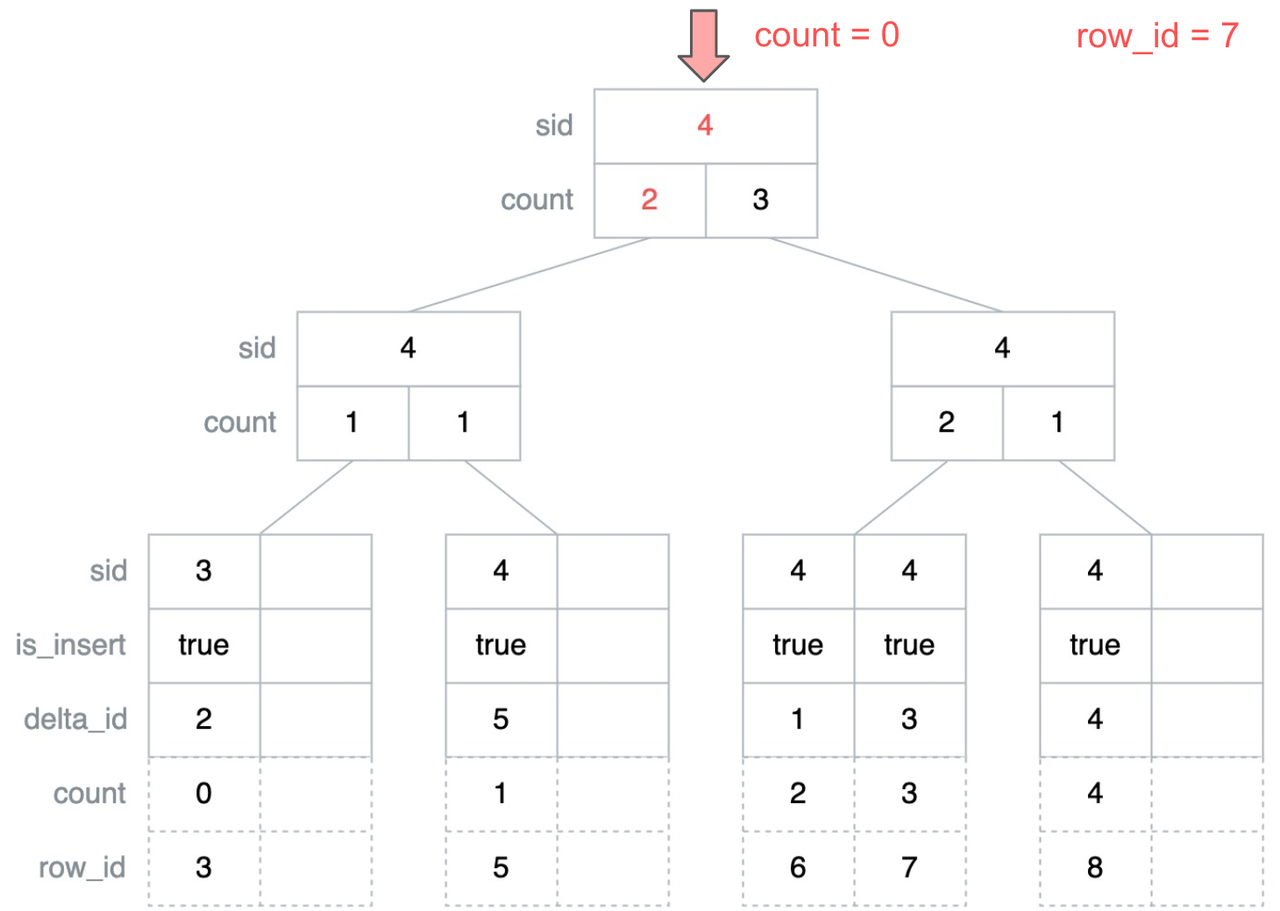
这里继续按照上述的方法比较,可以计算得到当前节点的右子树最小的 row_id 为 8,大于要查找的 row_id,因此接下来需要继续遍历当前节点的左子树。
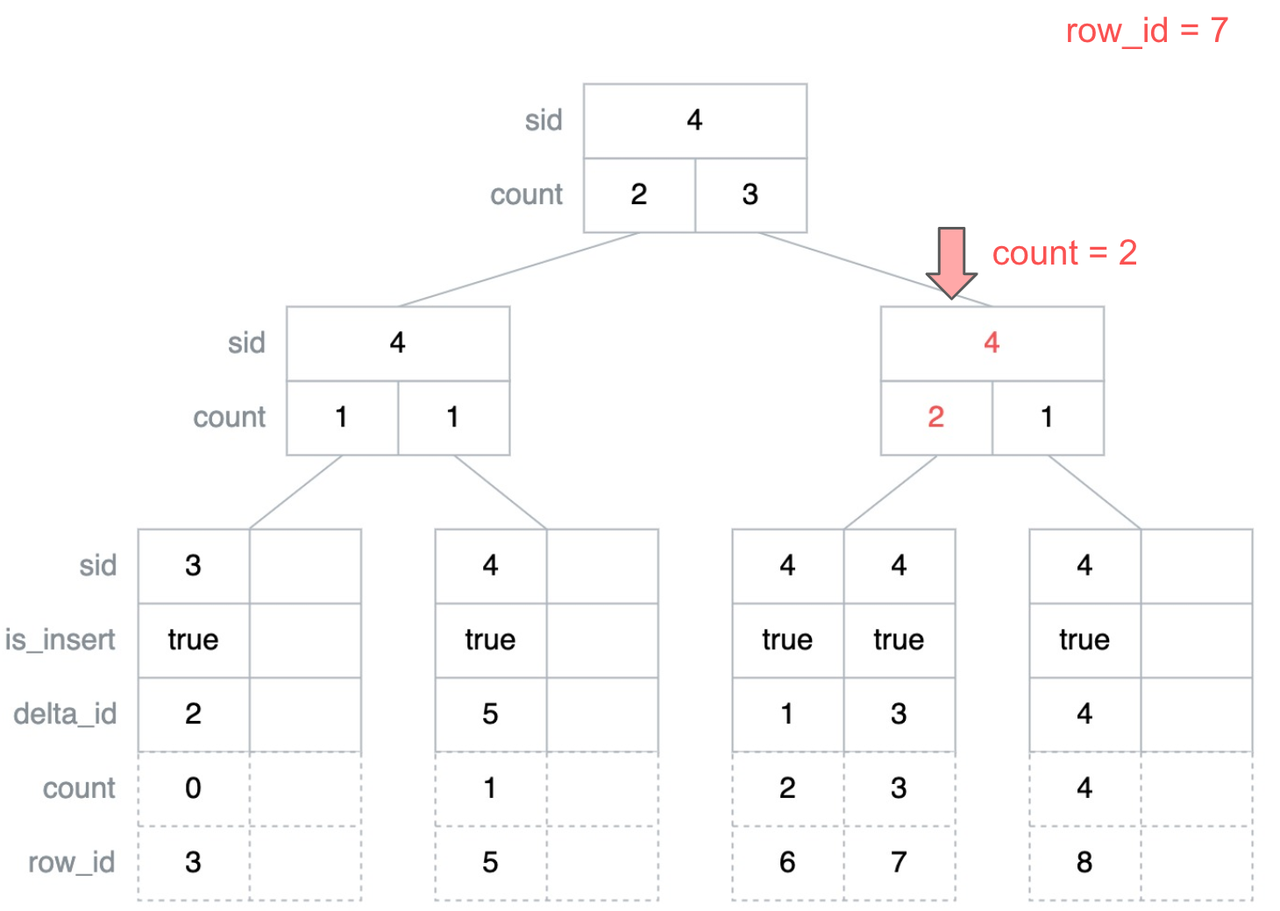
这里已经遍历到叶子节点,那么这个叶子节点就是我们要查找的可能包含 row_id 为 7 的最右侧的叶子节点。
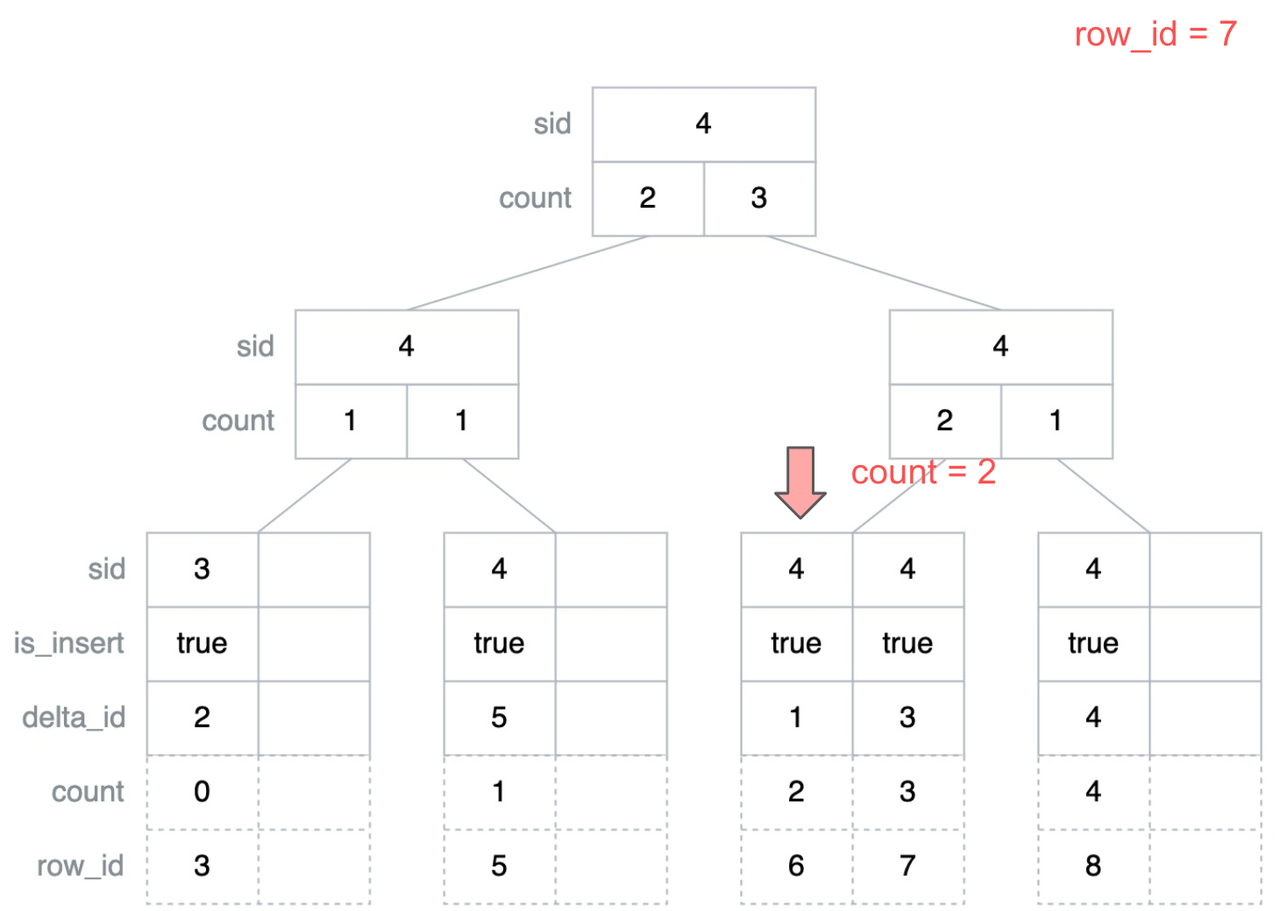
对于 Delta 层内写入的所有数据行,都需要在 DeltaTree Index 中添加一条对应的 Insert Entry,对应的操作即为 DeltaTree Index 的 Add Insert 操作。在添加 Insert Entry 之前需要先获得对应数据行的 row_id,也即这条数据在 Stable 层和 Delta 层合并后的有序数据流中的位置,具体这个 row_id 如何获取我们放在后面再讲,这里先假设我们已经拿到这条数据对应的 row_id,那么 Add Insert 操作对应的伪代码如下(注意这里为了更方便的展示核心逻辑,省略了更新 B+ 树结构的相关操作)。
leaf, count = findRightLeafByRId(row_id) pos, count = searchLeafForRId(leaf, row_id, count) shiftLeafEntries(leaf, pos, 1) leaf[pos].sid = row_id - count leaf[pos].delta_id = offset_in_delta_value_space基本的思路是先通过 findRightLeafByRId 操作找到可能包含这个 row_id 的最右侧的叶子节点,然后再通过 searchLeafForRId 操作(这个操作比较简单,这里就不展示了)在这个叶子节点上遍历找到这个 row_id 对应的 Entry 所在的位置,并将该位置原来的 Entry 向右移动一格(移动的过程可能会触发节点分裂等操作),最后把相关信息更新到这个 Entry 中即可。其中这个 Entry 的 sid 是通过计算 row_id - count 得到的,这里可以直观理解一下这个计算的含义,我们用 Stream 代表 Stable 层和 Delta 层合并之后的有序数据流,那么这里的 row_id 是新插入数据在 Stream 中的位置,而我们要计算的 sid 可以拆解为两部分,第一部分是 Stream 中排在目标数据之前的 Stable 数据的行数,第二部分是处理该 Entry 之前已经被删除的 Stable 数据行数,其中第一部分可以通过 row_id 减去 Stream 中排在目标数据之前的 Delta 数据的行数计算得到,而 count 刚好代表的是当前 Entry 之前插入的数据行数减去删除的数据行数,所以 sid 可以通过计算 row_id - count 得到。
另外值得注意的是在 TiDB 中的 Update 和 Delete 操作都是通过对相同主键写入更新版本的数据行完成的,因此在 SQL 层面的 Insert,Update 和 Delete 操作都是需要在 Delta 层写入新的数据,并在 DeltaTree Index 中添加新的 Insert Entry。
然后再看一下如何在 DeltaTree Index 中添加新的 Delete Entry,这里也要先获取删除的数据行的 row_id,具体的获取方式也放在后面解释。对应的伪代码如下,
leaf, count = findRightLeafByRId(row_id) pos, count = searchLeafForRId(leaf, row_id, count) // skip delete chain while leaf[pos].sid + count == row_id { if leaf[pos].is_insert { break } pos += 1 count -= 1 } if leaf[pos].sid + count == row_id { shiftLeafEntries(leaf, pos + 1, -1) } else { shiftLeafEntries(leaf, pos, 1) leaf[pos].sid = row_id - count leaf[pos].is_insert = false }删除数据有两种情况,分别是删除 Delta 层中的数据和删除 Stable 层中的数据。其中删除 Delta 层的数据只需要删除 DeltaTree Index 中对应的 Insert Entry 即可,也就是如果在 DeltaTree Index 中查找到需要删除数据对应 row_id 的 Insert Entry 时,说明需要删除的数据在 Delta 层,此时直接将该 Insert Entry删除即可完成删除操作。但是对于 Stable 层数据的删除则相对复杂一点,需要在 DeltaTree Index 中写入一条 Delete Entry 来代表删除一条 Stable 层的数据,对应 Delete Entry 的 sid 计算逻辑和 Insert Entry 类似,这里不再赘述。
Add Delete 操作主要在 TiFlash 不同节点间 Region 发生迁移或者某张表的 TiFlash Replica 被删除时会触发,这些情况下某些 TiFlash 节点上的 Region 会被迁移走,因此需要删除该 Region 对应的数据,该删除操作通过向存储层写入一个 Delete Range 完成,这个 Delete Range 则会先写入 Delta 层,后续会扫描出该 Delete Range 覆盖的所有数据行,并依次对 DeltaTree Index 进行 Add Delete 操作。并且对于 Stable 层被删除的连续数据行,会将其对应的 Delete Entry 在 DeltaTree Index 中进行合并操作,即将这些连续删除数据行的 Delete Entry 合并为一个,并在其中记录连续删除的行数即可,这样可以大幅减小 Delete Range 操作对 DeltaTree Index 内存占用的影响。
上面介绍了 DeltaTree Index 的相关更新操作,接下来我们再看一下如何利用 DeltaTree Index 在读取时完成 Stable 层和 Delta 层的合并,相关的伪代码如下所示:
total_stable_rows = 0 iter = index.begin() while iter != index.end() { if iter->is_insert { rows = iter->sid - total_stable_rows read_stable_rows(rows) read_delta_row(delta_id) total_stable_rows += stable_rows } else { ignore_stable_rows(1) total_stable_rows += 1 } iter++ }基本思路是遍历所有的叶子节点,遍历过程中如果遇到 Insert Entry,根据当前 Entry 的 sid 和已经处理的 Stable 层数据行数计算出接下来需要读取的 Stable 数据行数,读取完之后再从 Delta 层读取当前 Entry 对应的数据行。如果遇到 Delete Entry,则从 Stable 层中读取一行数据并抛弃即可。
现在我们已经知道如何用 DeltaTree Index 完成 Stable 层和 Delta 层的合并,但是这个过程需要扫描 Delta 层和 Stable 层的所有数据,然而集群上的很多查询不需要扫描全表的数据,因此我们想要尽可能过滤无效数据,避免无效的 IO 操作,所以我们通过引入 MinMax 索引来实现这个目的。
由于 Stable 层数据是按照 DTFile 的形式存储的,且每个 DTFile 中包含多个 Pack,其中一个 Pack 中包含 8K 行或者更多的数据,因此我们可以记录每个 Pack 中不同列的最大值和最小值,如果查询中有涉及该列的相关条件时,可以根据该列的最大值和最小值判断对应 Pack 中是否可能包含需要扫描的数据,并过滤掉无效的 Pack 以减少 IO 操作的消耗,这就是 MinMax 索引的基本原理。
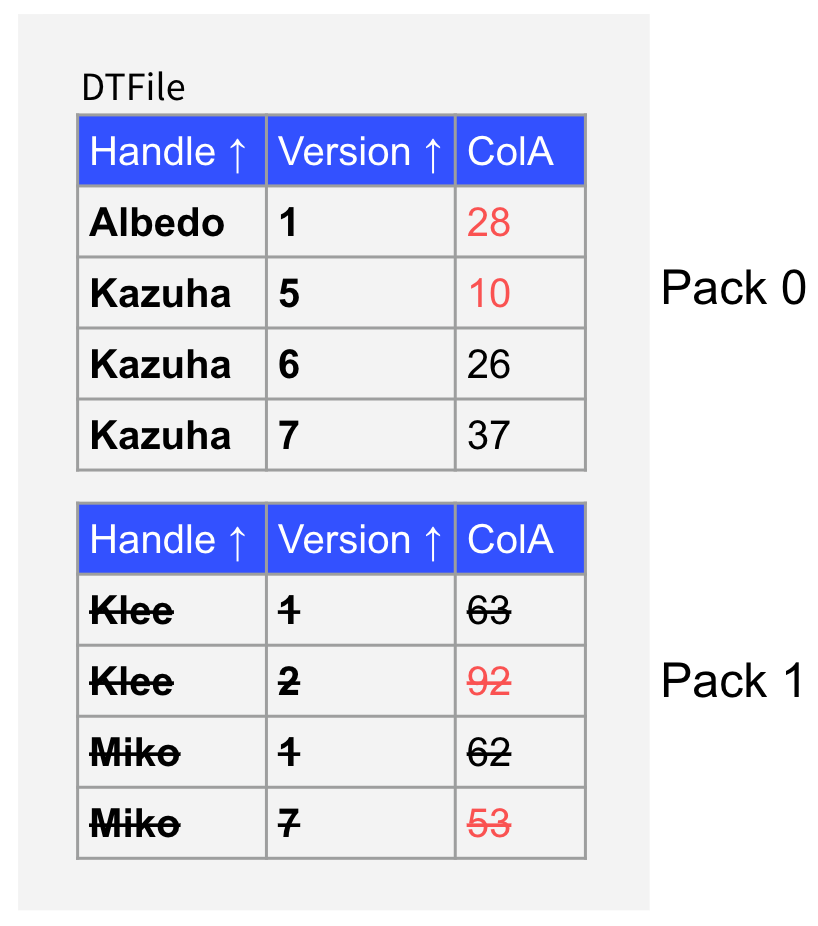
但是在 TiFlash 中实现 MinMax Index 还有一个需要注意的关键点,就是我们需要保证相同主键的数据在同一个 Pack 中。比如看下面的例子,其中 Handle 代表的是主键列,Version 代表的是版本列,ColA 是一个普通列,假设有一个查询上包含条件 ColA < 30,那么我们可以根据 MinMax 索引判断 Pack 1 中没有需要扫描的数据,因此我们可以只从磁盘上扫描 Pack 0。但是假如这个查询的时间戳为 7,那么按照上述流程经过 MVCC 过滤后 Pack 0 中的最后一条数据会作为查询结果集的一部分返回。但是 Pack 1 中有一条主键相同且版本更新的数据,因此 Pack 0 中的最后一条数据理论上在 MVCC 过滤后应该被覆盖,而不是作为查询结果集返回。
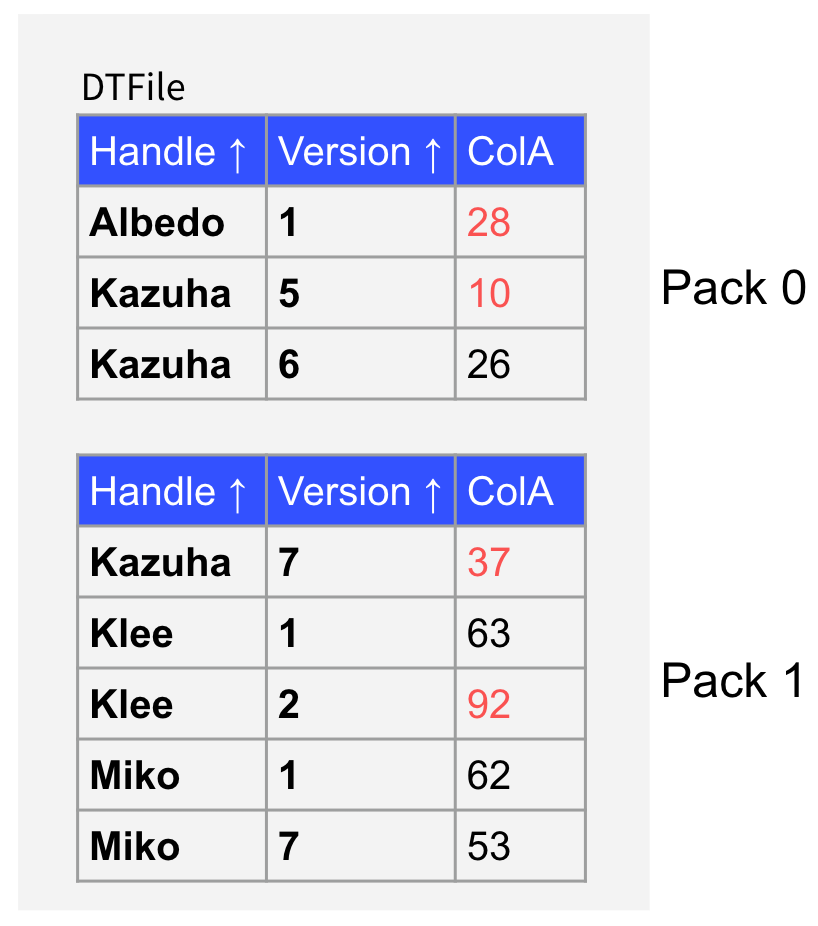
所以我们在写入 DTFile 时必须保证相同主键的数据会写入同一个 Pack,这样在经过 MinMax 索引过滤后才不会发生上述例子的异常情况。
到目前为止如何更新 DeltaTree Index 以及如何利用 DeltaTree Index 完成读取操作已经全部介绍完成。但是前面还遗留了一个问题,就是如何获取需要插入或者删除的数据行的 row_id?其实这个问题的答案也非常简单,就是将当前的 Delta 层和 Stable 层进行合并之后,然后在其中找到需要插入或者删除数据行的 row_id 即可。
当然如果每条数据的更新都要进行 Delta 层和 Stable 层的合并会带来非常大的开销,所以为了减少这个开销,我们采取了两种优化。第一个优化是对数据进行攒批,当写入的数据达到一定阈值后会在后台更新 DeltaTree Index,以此来均摊更新 DeltaTree Index 的开销。另一个优化就是采用 Skippable Place,由于 Stable 层的数据是全局主键有序的,所以可以通过主键上的 MinMax 索引跳过 Stable 层中与待更新数据范围没有重叠的 Pack,并且由于在获取所有待更新数据的 row_id 后也不会再继续读取后面的 Pack,所以通过这种优化可以使得在通常情况下只需要读取 Stable 层中和待更新数据有重叠的少部分 Pack 即可获取所有待更新数据的 row_id,因此可以大幅降低更新 DeltaTree Index 的开销。
TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件,因此 TiFlash 需要同时支持高频小批量写入以及优秀的读取性能。DeltaTree Index 结构的设计就是为了完成这个目的,更好地平衡 TiFlash 的读取和写入性能。本文只介绍了 DeltaTree Index 主要流程的基本原理,欢迎大家通过阅读 TiFlash 源码进一步了解更多的实现细节。
体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,在线申请 PoC 并获得专业技术支持。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

