

黄东旭解析 TiDB 的核心优势
822
2023-04-16
本文是 pingcap 联合创始人兼 CTO 黄东旭对论文 Amazon ***: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service 的解读,同时也对比了 TiDB 的一些设计。
很久没看到这么平铺直叙的论文了,可能是最近几年对于大规模分布式系统最具实操意义的论文之一,全文并没有任何一条公式,除了为数不多的 Micro Benchmark 图以外,就是一个简单的架构图(对于分布式数据库开发者来说,也是一张非常“没有”意外的图),甚至都没有解释太多架构设计(因为不需要,全世界 Shared Nothing 的系统都长得差不多),文字虽然多,但是基本都是大白话。毕竟 *** 已经不用试图“证明”什么,它在过去的 10 年已经充分证明了自己,不管是规模还是稳定性,这篇论文如果不出意外的话,大概会成为接下来很多云数据库厂商在构建各自的云服务的一个很重要的参考,因为论文比较新,我发现在网上也没有什么解读的文章,于是趁今天有空稍微斗胆解读一下,也会对比一下 TiDB 的一些设计,也许对于其它的读者有所启发。
这点我放在第一条,也是这几年做 TiDB 的云服务,让我感触最深的一点,我经常在不同的场合提到过:稳定的慢比不稳定的快更好,.99 Latency 比 Avg Latency 更加体现系统的设计功力。不知道是否有意为之,在 *** 2022 这篇论文中也是在第一个章节提出,可以见重要性。
可预测的性能意味着首先要可衡,我常常面对一些有点哭笑不得的场景,经常有人问我:TiDB 能支持多少 QPS/TPS?这个问题实在没办法回答,因为不谈 Workload 的前提下,这个问题是没办法回答的。
所以 *** 如果要做到提供可预测的性能,第一步是对 Workload 本身进行抽象,这就引入了 RCU,WCU 的概念,其实 RCU 和 WCU 和传统意义的 QPS 很接近,只是增加了操作的对象的大小,这样一来就可以做相对精准的 Workload 规划,例如:1 WCU = 1KB 对象 1 OPS,那么如果你操作的对象大小是 10K,那么在一个的能提供 1000 WCU 的机器上,你的总 OPS 就是 100。当业务能够使用 RCU 和 WCU 描述自己的 Workload 的时候,可预测性的第一步就完成了,至少 *** 的调度器可以做很多 Pre-partitioning 和预分配机器之类的事情,因为对于不同机型的硬件能力也可能简单的抽象成 WCU 和 RCU 的组合。
当你知道的每个 Partition 的配额后,对于调度系统来说,这大概就是一个背包问题。值得注意的是 *** 在分配 Partioin 的配额时候会考虑同一台机器的 Partition 的配额的总和要小于这台机器的能提供的极限 RCU/WCU ,从论文给的例子来看,大概是 20%~30% 左右余量。设计过大系统的同学看到这里肯定会心一笑了,没有经验的系统设计者或者系统管理员,通常会为了追求‘极致’的性能(或者成本),通常会榨干机器的最后一点 CPU 和 IO,非要看到 100% 的 CPU Usage 才满意,但是这种情况下,机器其实已经处于非常不健康的状态,体现是请求的长尾延迟会变得很高,即使可能吞吐能有提升,但是因为这个不稳定的长尾对于客户端来说就是“不可预期”。在生产环境中,我们通常推荐超配 30% 左右的机器,是同样的道理。
但是这样简单强行的限流确实有点粗暴,*** 引入了 Burst 和自适应配额(Adaptive Capacity)的概念。Burst 思路很简单,在分配配额的时候, *** 会给各个 Partition 预留一部分 Capacity,就是在短期流量 spike 的时候,用这些预留的 Capacity 扛一扛;Adaptive Capacity 就是在用户的 Workload 在其 Partitions 上出现倾斜后,动态的调整不同 Partition 的配额(但是总量不能超过原来的总配额)。
要注意到,上述提到的方案都是基于一个假设:用户的 Workload 不怎么变化,而且假设一估就准,而且流控的手段都集中在 Partition 级别(也就是几乎在 Storage Node 的级别),也就是局部调度。
在大规模存储系统上,流量控制其实就是一个全局的问题,用 TiDB 举例子,TiDB 的 SQL 层是一层入无状态的计算层,实际数据的请求会转发给 TiKV,按照 *** 这篇论文的说法,TiDB SQL 层就是某种意义上的“Request Router”,想象一下如果有多个 TiDB SQL 节点部署,但是只把流控做到 TiKV(存储层)的话,在极端情况下,不明真相的 TiDB SQL 节点仍然会不停的将请求打到过载的 TiKV Node 上,为了解决的这个问题,其实在 TiDB 层就需要做流控,直接返回错误给上层,不要穿透到 TiKV Node 上。
*** 的论文中关于这部分的描述有点模糊,我个人的理解的策略大致是 Request Router 定期向 GAC 申请请求配额,GAC 会维护一个全局分配策略,如果某些 Partition 已经过载了,相应的 Request Router 就可以直接对客户拒绝服务,以保护系统,另外在 Node 级别也保留了 Partition 级别的流控作为最后防线。
对于 Shared Nothing 的存储系统来说,Scale-out 的关键是分片的切分策略(分库分表就是一种最简单的静态切分),*** 很显然是选择动态切分的策略,就和 TiKV 一样,也是使用 Range Split,不一样的是 TiKV 的 Region (类似 *** 的 Partition 的概念)默认是按照 Size 作为切分阈值,后在 TiDB 6.0 引入了 Load-based Split 的策略,*** 直接采用的是 Load-based Split,首先 Partition 会有一个默认吞吐阈值,超过这个值后就会触发分裂(Split),现在想想,使用 Load 或者吞吐作为分裂的阈值,可能是一个更接近本质的选择🤔。而且当开始监控 Load 在 Key Range 上的分布状态后,很容易得到最优的分裂点(并非永远是中点)。另外关于 Split 的一个有意思的事情是,什么情况下 Split 是无效的,论文提到:1. 单行热点,这个很好理解。2. 按照 Key 的顺序访问的 Pattern,我猜想是类似顺序扫描的模式(类似 Key 上的迭代器),这种情况下 *** 会拒绝 Split。
总结一下,*** 的可预测性能的核心在于:
对 Workload 准确抽象(WCU/RCU) 对 Partition 预分配配额,并严格限流 在 Node 上留出余量作为应对突发场景的临时资源池(Burst) 使用全局信息进行流量调度,在各个层面上都流控关于 WAL 的处理,*** 和 TiKV 一样,也是通过 Distributed Consensus 算法(*** 是 Multi-Paxos,TiKV 是 Raft),同步到多个副本中(论文中暗示默认是 3),但是 *** 为了追求更高的 Durability,还会周期性的将 WAL (注意不仅仅是 DB Snapshot)同步到 S3,我理解这也不仅仅是为了更高的可靠性,同时也是 PITR(Point-in-time-recovery)必要动作。*** 实现 PITR 的当时也没啥特别的,就是定期将 DB Snapshot 传到 S3,然后配合 WAL 让用户恢复到指定时间,我发现这个不就是我在去年 TiDB Hackathon 上实现的项目吗!这里让我有点感慨,在过去如果我们是按照做云下的数据库软件的思路来设计类似的功能时,我们会倾向把这些和运维相关的能力做在数据库内核外围,然后通过额外的工具来提供相关的能力,因为从传统意义上讲,数据库内核对于外部环境的依赖越少越好(例如:在云下我们可没有 S3 用),但很显然云改变了这个假设。
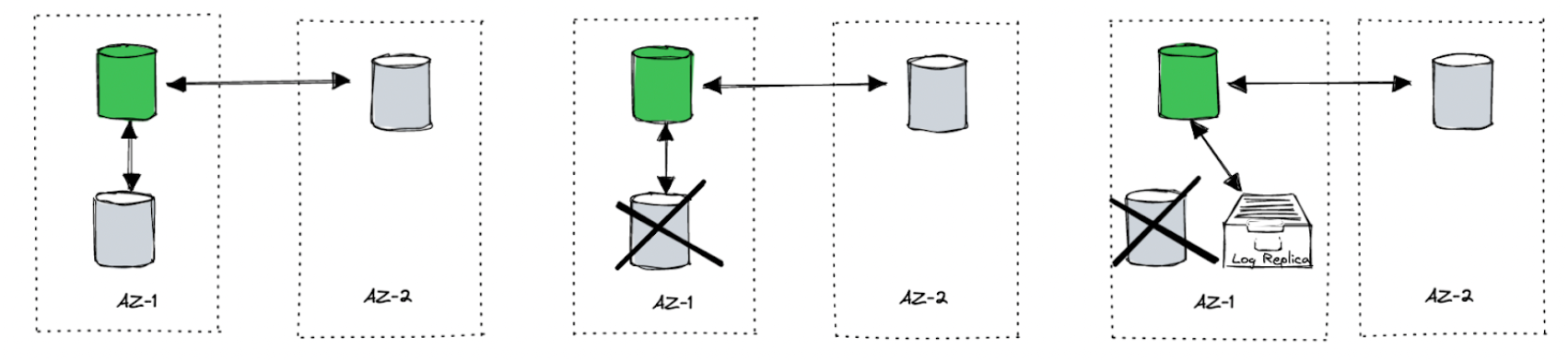
另外关于 Failover 的一个有意思的细节,当 *** 的 Replication Group 有节点故障的时候,例如 3 副本中有一个副本挂了,Group Leader 会马上添加一个 Log Replica 到复制组中,Log Replica 其实就是我们常说的 Witness(我下面也会用 Witness 来代替 Log Replica),也就是只存储日志,不提供服务的节点。其实这个做法非常聪明,对于 3 缺 1 的情况,虽然也满足多数派,但是这个时候的系统是很脆弱的,而要完整恢复一个新的成员的时间通常是比较长的(先拷贝 Snapshot 然后 Apply 最新的日志),尤其是 Partition Snapshot 比较大的情况,而且拷贝副本的过程可能会对本就不健康的 Group member 造成更多的压力,所以这个时候以很低的代价(论文中提到的时间是秒级)先添加一个 Witeness,至少保证恢复数据的过程中日志的安全性,而且对于跨中心部署的场景,这个优化还能降低异常状态下的写延迟,我们思考一个场景:假设我们有两个数据中心,其中一个主数据中心 A 承载主要写入流量,B 中心在远端承载一部分本地 stale read 的流量或灾备什么的,TiDB 跨两个中心部署,并让 Leader 和多数派集中在 A 中心(2 副本),另一个副本在 B 中心。这个时候 A 中心的某个节点挂掉了,这个节点负责的数据的 Raft Group 虽然不会停止写入,但是如果按照经典的 Raft,为了满足多数派的要求,这个时候必须需要要求 B 中心的副本写入成功才能返回客户端成功,这就意味着从客户端观察到了性能抖动(直到 A 中心的副本修复完成),如果在 A 中心的这个 Node 挂掉的时候,马上在 A 中心找台健康的 Node 作为 witness,添加到这个不健康的组中,这时候对于写入来说,只需要完成 A 中心的副本(Leader) + A 中心的 Witness,即可达到多数派,就省去了同步到 B 中心走一圈的延迟,从客户端的观察来说,系统并不会出现明显的抖动。
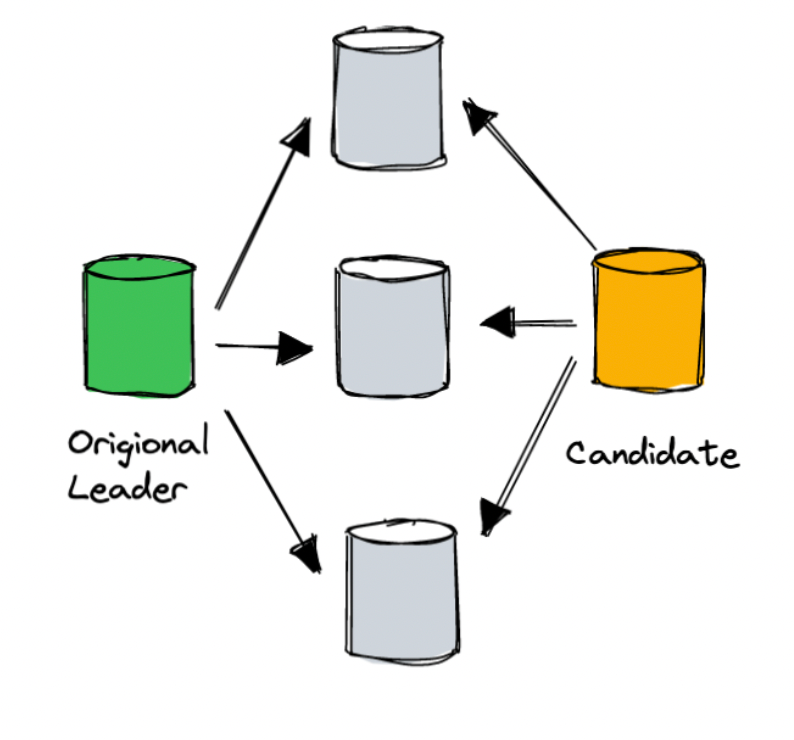
为了降低在 Failover 时候的用户可见抖动,*** 还对复制组的 Leader Election 做了改进,对于大规模系统来说,网络抖动和局部的网络分区基本是家常便饭,假设一种情况:某个 Peer X 联系不上 Leader 但是仍然能和其它 Peer 通信,另一方面,Leader 此时和其它的 Peer 仍然能正常通信,这个时候如果这个 Peer X 按照传统的 Election 协议,会贸然发起一次 Term 更大的选举,然后其它的 Peer 会停下来给它投票,这个过程中,其实老 Leader 并没有问题,然后从用户侧观察到就是这部分数据的短暂不可用(选举期间不会对外提供服务)。这个是一个老生常谈的问题,在 TiKV 2.1 就引入了一个叫 Pre-Vote 的优化:新 Peer 想要发起选举的时候会先的问一下其它 Peer 是否会投票给自己,同时通过这个机制确认老的 Leader 的状态,确保大家都认为老 Leader 失联,同时会把票投给自己的前提下,才会发起投票,这个是避免在选举阶段死锁的一个常规优化。在 *** 中,论文中也提到了类似的机制:在 Peer 发起投票前,先问问其它 Peer 是否也觉得老 Leader 挂掉了,如果没有(或者多数派 Peer 联系不上),那就说明是自己的问题,就不影响正常的节点了,以减小客户端观察的系统抖动时间。
另外,对于大型系统来说,最可怕的故障就是雪崩(级联故障),例如 2015 年 *** 的故障( https://aws.amazon.com/message/5467D2/ )就是一个典型的因为对元信息(Metadata Service)服务查询过多(路由信息),然后挂了,导致更多的客户端重试让情况更加恶化。在这篇论文里面提到对于元信息服务的改进让我想起了那次故障(我猜想很可能就是因为那次故障做的改进),解决的思路也很有智慧,我稍微解读一下。
*** 观察到造成级联故障的根源之一在于:流量突变,而造成流量突变的常见因素之一就是缓存失效,虽然我们大多数时候认为缓存命中率越高越好(论文中大概提到路由表的缓存命中率大概是 99.75%)但是这么高的缓存命中率意味着:当出现缓存异常的情况(或者大量新节点加入时的缓存预热阶段),元信息服务要能承载 400 倍(最坏情况, 0.25% → 100%)的流量暴涨。*** 为解决这个问题使用了两个手段:
在 Request Router 和 Metadata Service 中间加了一级分布式内存缓存 MemDS,Router 的本地缓存失效后,并不直接访问 Meta Service,而是先访问 MemDS,然后 MemDS 在后台批量的访问 Metadata Service 填充数据。通过添加一层缓存进行削峰操作,相当于再加一层保险,属于常见的手段。
第二个手段比较巧妙,刚才提到 Router 事实上是通过 MemDS 获取元信息,当请求在 MemDS 的时候没命中的时候好理解,但是 MemDS 巧妙地方在于:即使缓存命中,MemDS 也会异步访问 Meta Service。这个操作我理解带来两个好处:
尽可能保证 MemDS 中已有缓存能被及时更新 给 MetaService 带来一个’稳定‘的流量(虽然可能更大)其中带来“稳定”但是更大的流量这个做法,举个例子:一直在演练,洪峰到来就不会措手不及。
另外基于总量限制的令牌的 GAC 在某些程度上也降低了级联故障的影响。
另外对于云上服务来说,一个优势是更新发布的节奏会比传统的企业软件快,而且微服务的架构能实现局部更新,但是部署更新通常是系统最脆弱的时候,而且像 *** 这么大规模的系统不太可能做全部停机更新,只能滚动更新,对于滚动更新来说,唯一要注意的点是:在更新过程中新老版本的 RPC 会共存,所以新的版本需要能够和运行老版本节点通信,然后在某个时刻(所有节点都部署新的节点后)切换新协议。
*** 的对于系统在脆弱环境下的稳定性的工作总结成一句话就是:尽可能降低客户端的可观察影响,我认为其实也是“可预测的”性能的一部分。
总的来说,*** 这篇论文和十多年前的 Dynamo 的论文相比,其实十几年前那篇论文更像个 DB,而这个 *** 其实是一个真正的 DBaaS (Database as a Service),你可能好奇这两者之间有啥区别,我认为构建一个 DBaaS 和构建一个数据库完全是两回事,并不是简单的将多个 DB 部署放到云上托管就叫做 Service 了,很有可能一个成熟的 DBaaS 服务,除了给用户的感觉通过 endpoint 连上去用着像个 DB,至于这个 endpoint 后边长成什么样子,用户不用关心,甚至都不需要长成个数据库模样。举个极端点的例子:如果一个提供 SQLite 服务的 DBaaS,我觉得大概率它不会真的每个用户上来都傻傻的创建一个新的容器,装好操作系统,然后真的启动一个 SQLite 进程暴露出来,很可能是一个共享的大型服务,只是对外的表现的行为和 SQLite 一致即可,这样能更好的利用资源,从用户角度大概也感觉不出来。
所以要构建一个 DBaaS,首先要考虑的是多租户,*** 之所以要重新设计,很重要原因就是老 Dynamo 不支持多租户,还是个传统的单租户 NoSQL 系统,这个对于云服务来说是不可接受的。这个在 TiDB 进行云原生转型的时候,我们深刻地体会到,所谓云原生并不是简单的将一个云下的数据库搬到云上自动部署就叫 DBaaS,而是需要从内核到管控平台针对云提供的能力和环境进行深层次的改造,否则一个直观的代价就是:在云上的成本降不下来。另外一个 DBaaS 和 DB 的显著区别就是 DBaaS 通常很难进行私有化部署,一个现代的 DBaaS 事实上充斥着大量的微服务,或者重度依赖了很多云厂商提供的特性(尤其是存储和安全相关的服务)。这点在 *** 的论文中体现的很明显:Request Router 是一个独立于所有租户前端的接入层(接入服务),全局流控 GAC 是一个服务,鉴权系统是个服务, 元信息是个服务,存储也是个服务,更不用说依赖的其它的服务如 S3/IAM 什么的…不过有意思的是:论文里面并没有提到任何的 EC2 和 EBS,让我不禁猜想 *** 的 Hardware Infra 很可能是自己维护的,也就是跑在 Bare metal 上。
对于 TiDB 来说,面临的问题比 *** 更加复杂,毕竟 TiDB Cloud 提供的是 SQL 的服务,例如用户来一个 SELECT * FROM table 就会让计算 RCU 变得很困难(尤其是 TiDB 有 Co-processor,进行计算下推),但是也并非没办法,未来有机会可以写写这个话题,而且对 Workload 的抽象也会成为在云上计价和 Serverless 化的关键。TiDB Cloud 最近已经完成了管控平台的服务化,以及最近正在拆分的 Session Management 服务(类似 *** 的 Request Router)等很重要的工作,所以对我来说, *** 这篇论文更加确定了我们对于拆分和微服务化改造这条道路的对于云数据库的重要性的判断。
最后下面是一点这篇论文的 Takeaways:
越了解 Workload 的抽象,越有利于构建出可预测系统,另外对 Workload 的衡量越精细,你能挣钱的空间越大。 从一开始,从全局考虑多租户,越早考虑越省事。 在云上,接入层的重要性很高,不要想 P2P 似的系统,直连存储节点是不靠谱的,Proxy 引入的一点点延迟对于带来的系统的可预测性提升来说,是可以接受的(流控,高可用,租户隔离,不停机更新…) 对调度进行抽象(将流控也考虑在调度模块里),层层流控,避免缓存失效带来的级联故障。 全局的微服务化构建的平台实现多租户,而不是在独立租户内拆分微服务。 利用云基础设施,将节省很多工作,例如 S3看完这篇论文后,其实有点意犹未尽的感觉,感觉还有很多东西没有写到,例如 Serverless 存储的 GC 策略 ,分布式事务等等,但是不妨碍这篇文章已经是一篇经典,想到这几年走的这些弯路,同行也是这么走过来的,竟然有一丝丝的共情,真是想互道一声不容易。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

