

黄东旭解析 TiDB 的核心优势
778
2023-04-16
PingCAP Clinic 服务源于 TiDB Cloud,以智能诊断提升 TiDB Cloud SLA ,以 AIOPS 方式降低 TiDB Cloud 运维成本。
2022 年 7 月 15 日,为本地部署集群提供诊断的 Clinic 服务正式 GA ,它将 TiDB Cloud 中积累的智能诊断能力以诊断服务方式提供给本地部署的集群,为所有 TiDB 集群打开智能诊断之门,开启 TiDB 性能和稳定性的新篇章。
本篇以数据库管理员的视角,讲述在典型的集群运维场景中,Clinic 如何帮助管理员更清晰地了解集群健康状态,如何以智能的方式提前发现问题、快速解决问题,提升 TiDB 集群的性能和稳定性。
小宇是 TiDB 数据库集群的管理员,他使用 Clinic 诊断服务已有两个多月,当问到对于 Clinic 的评价,小宇说, “用了 Clinic 以后,每周的例行数据库巡检可以少花 2 小时,新业务接入的时候也能游刃有余地应对,现在已经离不开它了”。
根据业务要求,需要把目前系统中的 MySQL 大表迁移到 TiDB,小宇新部署了一套 6.1 版本的 TiDB 数据库集群。数据库集群部署完成后,小宇根据官方文档的建议,基于业务情况、节点资源做了相关的配置调整,调整完后进行了一系列的测试,测试很顺利,但是在生产业务接入前几天,小宇失眠了,他做了很多的配置调整,担心其中会有一些潜在风险。
为了不再失眠,小宇决定再找一些建议,他在 AskTug 论坛上搜索相关内容,找到了一个 PingCAP Clinic 服务的介绍,这个服务针对 TiDB 提供了量身定做的配置检查工具。这不就是雪中送炭?小宇激动地照着 Clinic 使用说明,用 TiUP 运行了两条命令,得到了配置检查的结果。配置检查指出小宇的 PD schedule 调度相关配置项有风险,给出了详细的说明和修复建议链接;还指出未设置日志最大保留的天数,可能有爆盘风险。
Rule Name: tidb-max-days - RuleID: 100 - Variation: TidbConfig.log.file.max-days - For more information, please visit: https://s.tidb.io/msmo6awg - Check Result: TidbConfig_172.16.7.87:4000 TidbConfig.log.file.max-days:0 warning有了这份结果建议,他根据建议重新调整了配置值,小宇非常安心。在生产业务的正式接入前,再也没有失眠。
公司的业务接入非常顺利,大表单迁移到 TiDB 后,原有 MySQL 系统业务压力降低,TiDB 侧业务运行稳定。
作为一名资深的数据库管理员,小宇深知日常巡检的重要性,提前发现风险才能更好的规避大问题发生。在使用 Clinic 之前,小宇都是手动巡检,小宇打开 grafana 查看了各种数据,还把各个组件的日志进行了搜索检查,花了整整一下午的时间。使用 Clinic 之后,借助 “Benchmark 报告”和“对比报告”,整个巡检过程缩短到 30 分钟。
“Benchmark 报告”基于长期积累的 TiDB 集群运维经验,把已知风险检查点做成智能规则,可以对 metrics,log 进行巡检,列出风险点并提供优化建议。 “对比报告”可以对比两个时间周期的关键指标差异,小宇无需再手动挨个检查 40多个关键指标和搜索日志关键词,只需要直接从报告中查看数据。小宇每周都会使用几次 Benchmark 报告进行巡检,印象比较深的一次是接入了新业务,正在进行相关索引创建。在巡检中,小宇获得了以下的报告建议,没有相关资源使用过多、调度异常、存储异常的建议,说明集群完全能够支撑新业务的压力。发现了两个 Warning ,一个是节点不均衡,小宇分析后发现是因为索引操作引起的,只需要等待索引创建完成即可解决;另一个是建议配置 AsyncIO 参数,能够针对新业务进行优化。
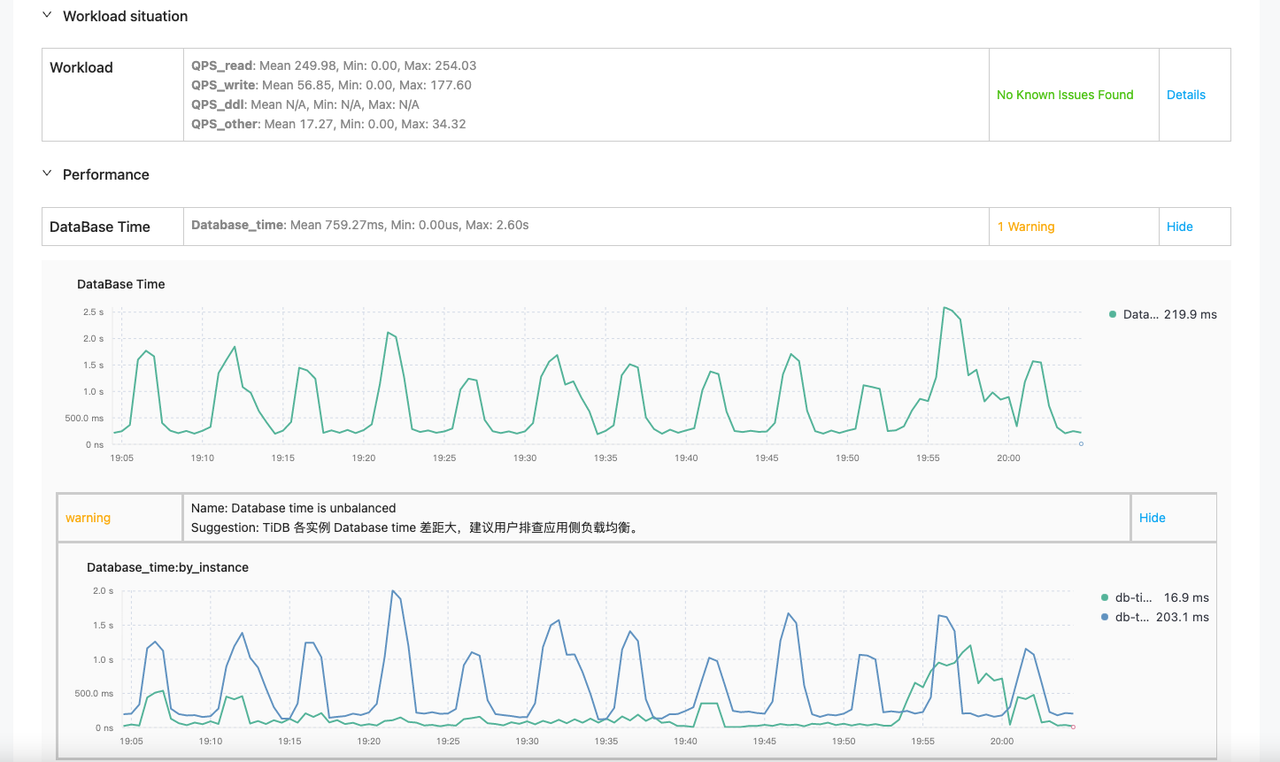
索引创建完成后,小宇在维护窗口修改配置,打开了 AsyncIO 功能。配置修改以后,小宇密切关注修改前后的变化,使用 Clinic 对比报告,再也不用挨个 metrics 查看对比了,可以直接获得下面的对比结果。小宇一眼就看出,集群 duration 下降,系统资源使用率也下降,这是一次快速且卓有成效的性能调优。
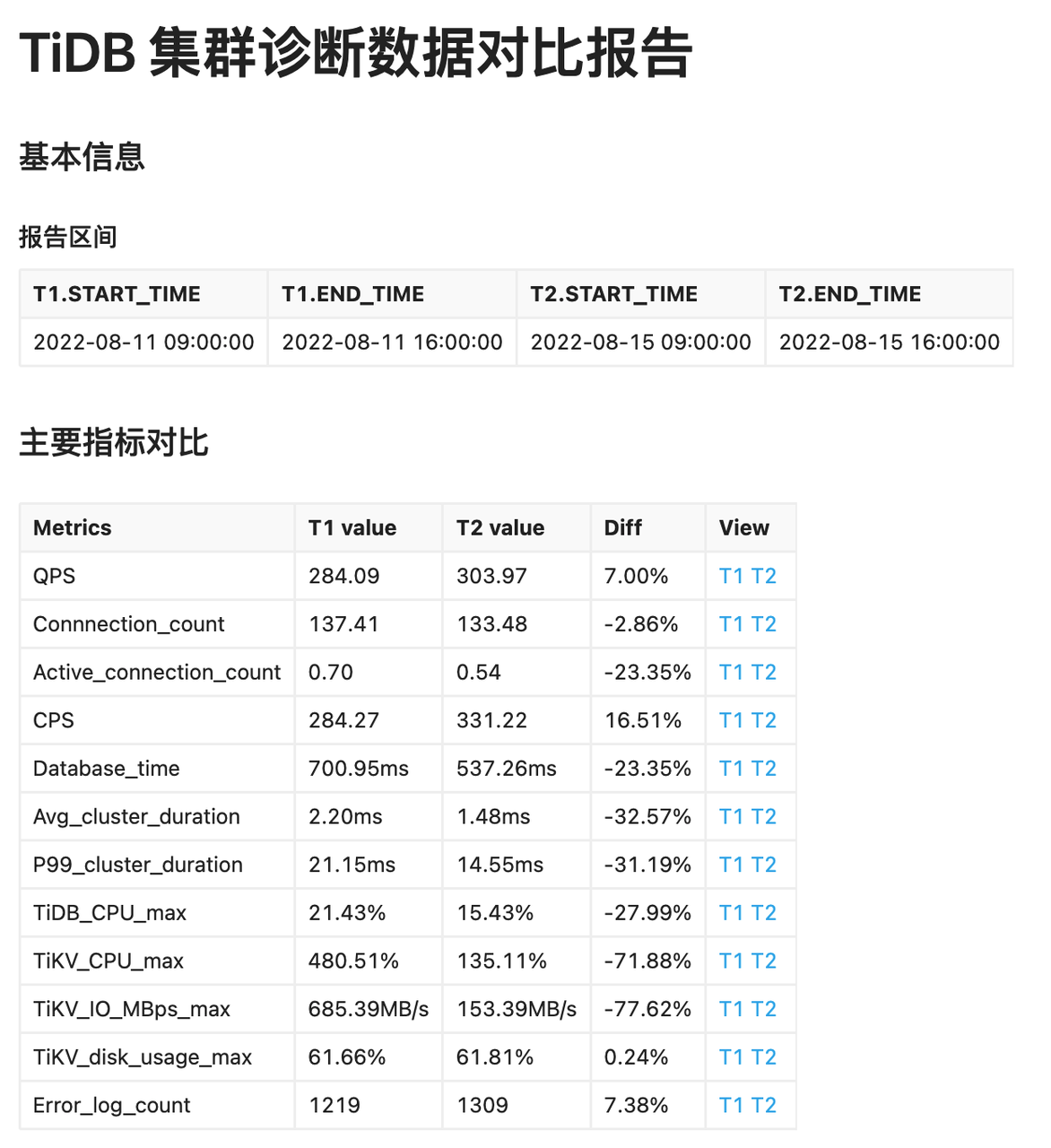
除了主要指标对比以外,该报告还会详细对比业务指标、性能指标、系统资源指标、配置差异和日志聚类差异。其中日志聚类可以智能地将日志进行分类统计,计算不同时间段的日志数量差异,对于日志的变化情况一目了然,快速发现潜在风险,无需再手动搜索相关日志。

一个新的大压力业务接入后,集群中的一台 TiDB 服务器发生了重启,小宇分析了各种指标,可以看到 TiDB 的压力比较大,但是无法分析重启的具体原因。
为了彻底找到问题根因,避免后续问题扩大,小宇找到 PingCAP 技术支持工程师求助,直接使用 Clinic 提供的 diag 工具采集了集群重启前后的监控数据和相关日志,只需要两条简单命令,就能完整采集数据并安全地上传到 Clinic Server。
运行采集命令,能采集最近 2 小时的集群各节点日志、metrics、配置项、硬件参数信息: tiup diag collect ${cluster-name} 采集完成后,直接上传至 Clinic 服务: tiup diag upload ${filepath}小宇将数据链接分享给 PingCAP 技术支持工程师后,技术支持工程师立即查看相关数据,并基于各项参数进行充分的分析,最后建议小宇对新业务中的某个查询语句进行优化,1 小时内解决了重启的问题。
小宇的故事很朴实,这就是每个 TiDB 数据库管理员都会经历的日常,Clinic 服务这个“智能小助手”,也会逐步深入到每个 TiDB 数据库管理员的工作中。
TiDB 一路走来,从最初的基础 Grafana dashboard,到提供各种深入指标和数据呈现的 TiDB Dashboard, 再到如今可以主动提供建议的 Clinic 服务,一步一个脚印,为每一位 TiDB 用户打开了智能诊断的大门。
在智能诊断、数据库自治这个领域,Clinic 将持续提升 AIOPS 的能力,当好 TiDB 用户排忧解难的助手,开启 TiDB 性能和稳定性的新篇章。
Clinic 使用文档:
快速上手 Clinic Clinic Report 使用方法版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

