

黄东旭解析 TiDB 的核心优势
794
2023-04-15
李振环,PingCAP 行业解决方案架构师,主要关注新经济行业和合作伙伴生态。有多年分布式数据库和大数据实战经验,之前在贝壳金服担任大数据平台技术负责人,负责贝壳金服大数据整体架构。
多业务融合即将多个业务系统部署在同一套 TiDB 集群中,能够有效地帮助企业降低架构复杂度、节约成本,在竞争激烈的市场中获得更大的市场份额。
如何提高资源隔离能力确保不同业务之间不相互影响是多业务融合方案设计要点。在 多业务融合方案 - 上篇 中介绍了基础多业务融合方案,在本文中继续介绍多业务融合方案以下能力:
多业务融合能力与 HTAP 结合 多业务融合在基础架构上通过修改 Leader 分布进一步提升整体隔离性 如何在线调整业务资源组多业务融合之后用户提出了一些新的需求:
基于订单和商品信息得到当日热卖商品,基于用户标签给用户推荐热卖商品(实时分析) 实时风控需要查询商品、订单、支付、用户等行为数据做风控 (统一视图) 订单详细页面:展示订单基础信息、订单支付状态和商品详情(统一视图)这些需求在传统架构中实现复杂度高,但是借助多业务融合与 TiDB HTAP 实时分析的能力,可以大幅度降低实现复杂度和成本。
需求 1 需要实现实时数据聚合分析,需求 2 和需求 3 需要实现统一视图(实时跨业务系统强一致性数据关联)。接下来分别看一下如何实现用户以上需求。
需求 1 是实现实时数据聚合分析,传统方案会将订单、商品、用户等业务系统数据同步到统一的大数据平台,然后执行聚合 SQL 得到最终推荐结果。此过程需要维护复杂数据同步链路,数据时效性一般为 T + 1 ,无法满足实时数据推荐需求。基于多业务融合方案数据已经存储在统一的 TiDB 集群中,只需要使用 SQL 查询 TiFlash 业务数据即可得到最终推荐结果。具体实现架构如下图所示:
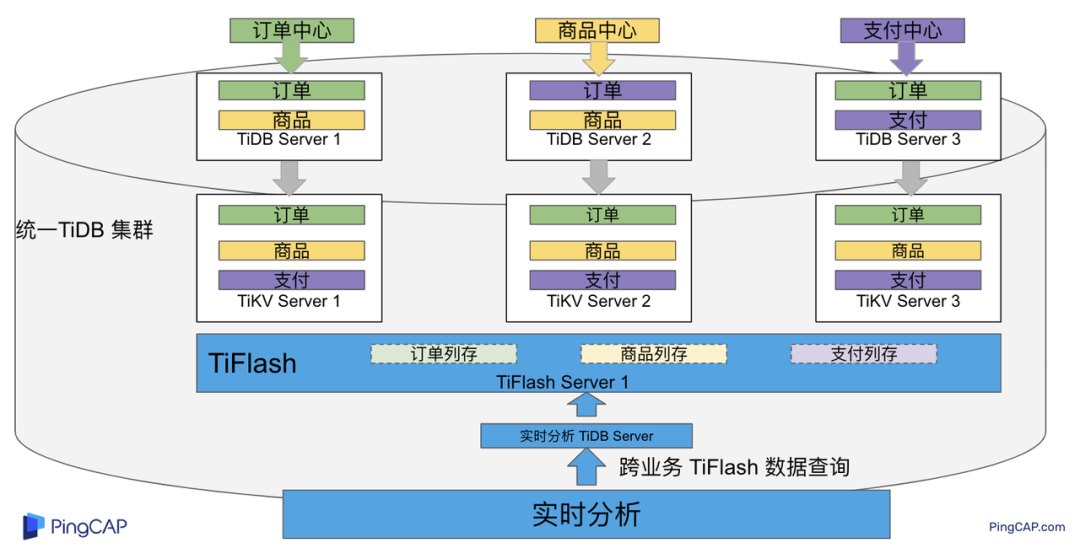
多业务融合之后支付、订单等数据已经统一存储在 TiDB 集群中,在此集群上扩展蓝色 TiFlash 实例和蓝色 TiDB 实例,并为分析相关的表创建 TiFlash 列存副本,设置新 TiDB 实例 session 级别变量:tidb_isolation_read_engines = tiflash ,强制所有数据分析 SQL 查询 TiFlash 数据副本。综上实现数据分析只使用蓝色 TiFlash 和 TiDB 资源,保持与业务系统隔离。与传统方案对比此方案具备以下优势:
无数据同步链路:内置实时数据同步功能,减少用户运维成本 强一致性数据分析:实现跨业务强一致性数据分析 强大的 TiFlash 列存 MPP 分析能力:提升数据分析效率需要注意以上能力需要使用 TiDB 6.1.2 或者 6.3 以上版本。
需求 2 和需求 3 是实现统一视图的需求,并且请求 QPS 比较高。传统方案一般会通过各个业务系统开发 API 获取数据,然后在客户请求系统中统一聚合得到结果。此方案需要多个业务系统联合开发,并且客户端聚合数据复杂度高,在返回数据量较多时很容易 OOM 稳定性差。基于多业务融合加 TiDB 自带读写分离的能力实现跨业务系统实时统一视图查询,并且实现统一视图业务与在线交易业务资源隔离。具体实现架构如下图所示:
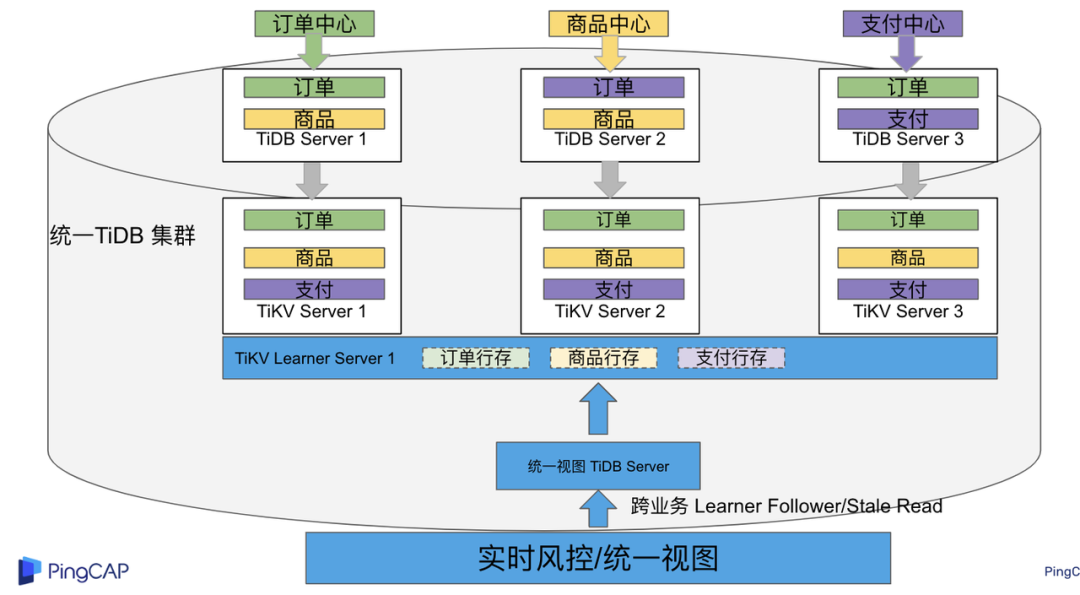
多业务融合之后数据已经在统一 TiDB 集群中,为 TiDB 集群添加蓝色新 TiKV Learner 实例和 TiDB 实例。然后通过蓝色 TiDB 跨业务系统关联查询数据,统一视图 QPS 请求比较高,关联 SQL 比较复杂, 关联 SQL 默认会查询 TiKV leader ,为了降低关联 SQL 对集群业务的影响,通过简单配置,指定关联 SQL 使用蓝色 TikV Learner 副本,确保上图蓝色业务只使用蓝色计算和存储资源。综上通过 TiDB 行存读写分离的能力实现统一视图查询与业务读写资源隔离。具体实现方式如下:
TiKV Learner 副本配置给新增 TiKV Learner 服务器上的 TiKV 实例打上 label 为 region : order_learner 。具体 tiup 配置文件内容如下:
tidb_servers: - host: 172.0.0.8 config: labels: region: order_learner通过 Placement Rules in SQL 为统一视图需求中查询的表添加 TiKV Learner 角色,具体 SQL 为:
# 此 SQL 创建规则,将 leader 和 follower 放置在 label 为 region:order 的 TiKV 实例中,并且创建一个 learner 角色,其数据放置在 region: learner 的 TiKV 实例中 Create placement policy p_order_learner LEADER_CONSTRAINTS="[+region=order]" FOLLOWER_CONSTRAINTS="{+region=order: 2}" LEARNER_CONSTRAINTS="{+region=order_learner: 1}"; # 此 SQL 将 order 表绑定到上面创建的规则上 alter table `order`.`order` PLACEMENT POLICY=p_order_learner;为统一视图所有表应用新规则之后,这些表在蓝色 TiKV 节点上都拥有一份 Learner 角色行存数据,此时一共有 4 个副本数据。
配置 TiDB 读取 TiKV Learner数据固定储存在 TiKV Learner 之后还需要配置蓝色 TiDB 固定从蓝色 TiKV Learner 读取数据,具体配置方式如下:设置新增蓝色 TiDB 实例 Label 为 region : order_learner ,确保 TiDB Label 与 TiKV Label 相同。具体 tiup 配置文件内容如下:
tidb_servers: - host: 172.0.0.8 config: labels: region: order_learner并设置 TiDB SQL 变量 tidb_replica_read 为 closest-replicas (就近读),设置此变量之后 TiDB 会优先就近读取与 TiDB Label 相同的 TiKV 副本数据。
set @@tidb_replica_read=closest-replicas ; select o.id ,p.amount from order.order o left join pay.pay on p.order_id = o.id limit 10综上统一视图需求查询蓝色 TiDB 计算节点,基于就近读和 Learner 设置规则此 TiDB 会优先读取蓝色 TiKV 行存副本,读取过程支持强一致性读取,此时每次读取 Learner 时会与 Leader 做 ReadIndex 操作(此操作为轻量级操作),确保读取到最新的数据;也支持弱一致性读(stale read),此过程会跳过 ReadIndex 操作,并读取最近几秒内最新的统一 TSO 的数据,对于可以接受非最新强一致性业务可以使用弱读,进一步提升查询响应速度与 Leader 隔离性。
配置 TiDB 读取 TiKV Follower上述过程使用 TiKV Learner 副本实现读写分离,此时一共需要 4 个数据副本,也可以使用 3 副本实现读写分离。通过创建 Placement Rules in SQL 规则,将蓝色 TiKV 实例固定为 TiKV Follower 角色,确保与 Leader 角色隔离。创建规则具体 SQL 如下:
# 此 SQL 创建规则,将 leader 和 follower 放置在 label 为 region:order 的 TiKV 实例中,另外一个 follower 角色其数据放置在 region: learner 的 TiKV 实例中 create placement policy p_order_follower LEADER_CONSTRAINTS="[+region=order]" FOLLOWER_CONSTRAINTS="{+region=order: 1,+region=order_learner: 1}"; # 此 SQL 将 order 表绑定到上面创建的规则上 alter table `order`.`order` PLACEMENT POLICY=p_order_follower通过以上 SQL 将两个数据副本放置在 label 为 region : order 的 TiKV 实例中,另外一个 follower 角色其数据放置在 region: order_learner 的 TiKV 实例中。
如上节内容所述,为 TiDB 也设置相同 label region: order_learner 并使用 SQL 开启就近读即可实现新增 TiDB 实例只读取新增蓝色 TiKV 实例数据,实现查询业务与 OLTP 业务资源隔离。
多业务融合时可以使用 TiDB 本身分布式事务实现跨业务分布式事务,比如下单和支付需要在一个事务中提交或回滚,可以使用 TiDB 大权限用户执行以下 SQL :
begin; insert into `order`.`order` values(....); insert into `pay`.`pay` values(....); commit;对比使用 seata 等分布式中间件,TiDB 只需要使用以上简单 SQL 和内置 Percolater 事务即可实现并确保跨业务分布式事务正确性。大大提高了跨业务分布式性能和正确性,并降低了开发复杂度。
在多业务融合场景中,利用 TiFlash 列存的扩展实现多业务实时分析,利用 TiKV Learner 的扩展实现多业务的统一视图,且保证业务之间的隔离互不影响。具体架构图如下:
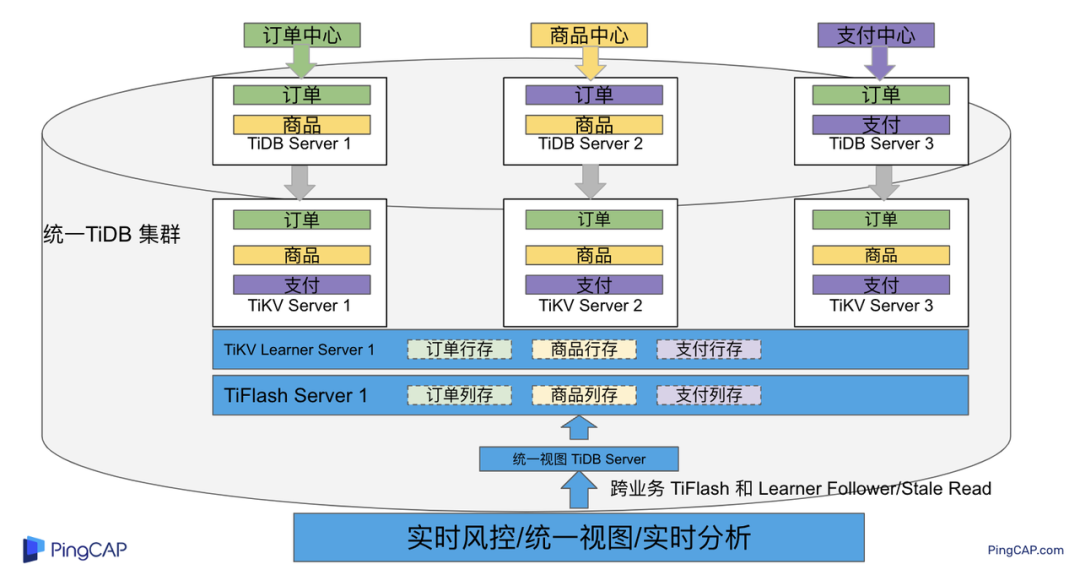
在 多业务融合方案 - 上篇 中介绍了基础多业务融合形态。本节介绍动态调整 Leader 分布技术,满足部分客户更强单机多实例隔离性需求。
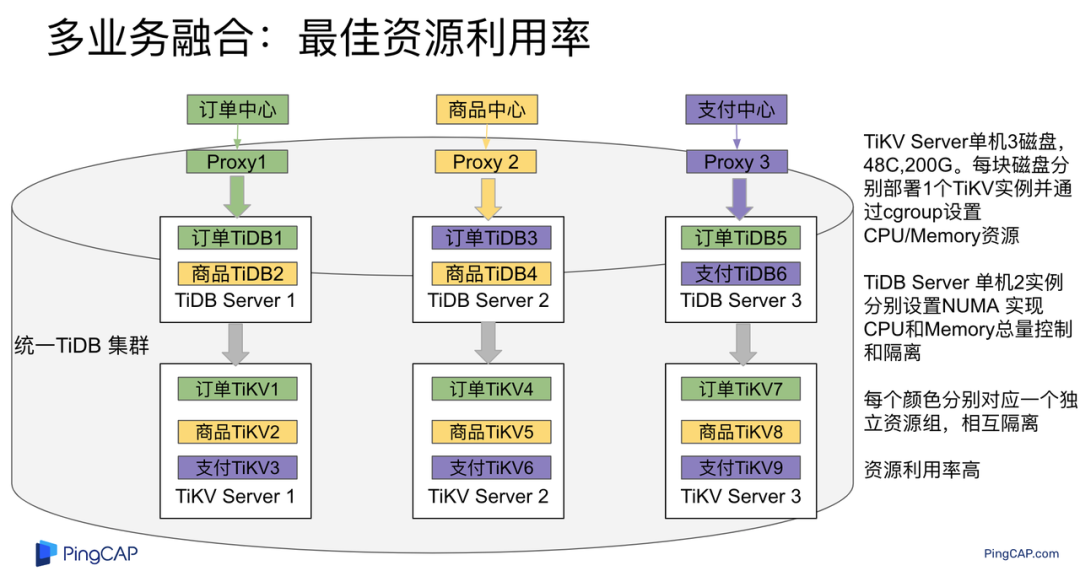
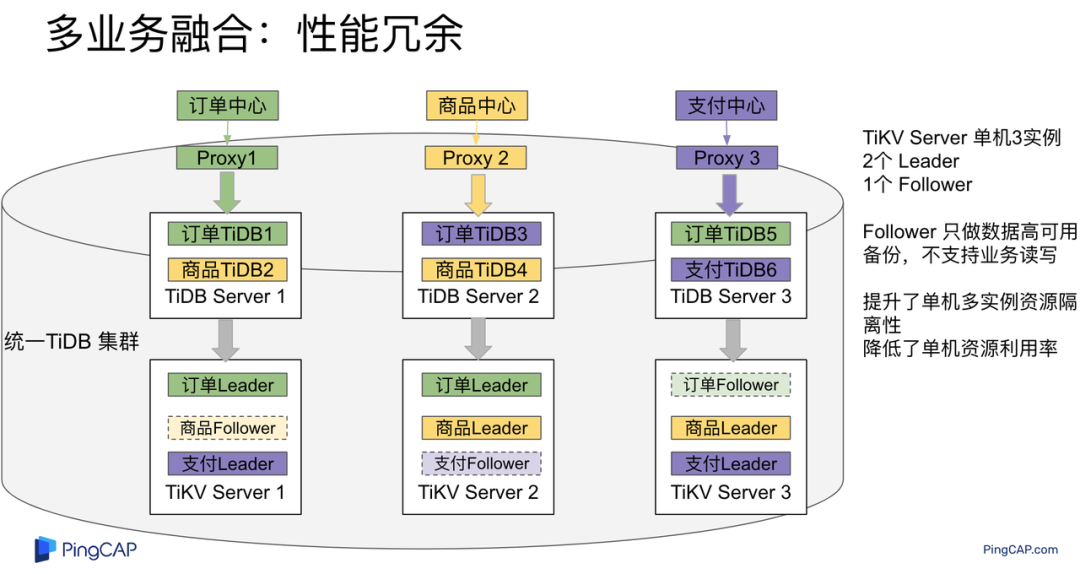
架构说明:各实例部署模式与图 2.1 相同,使用 Placement Rules in SQL 控制单台 TiKV Server 中 3 个 TiKV 实例只有 2 个 TiKV 实例承担 Leader 角色支持业务读写。通过减少单台 TiKV Server 在线服务 TiKV 实例个数,降低了单机 TiKV Server 资源利用率,减少了 TiKV Leader 实例资源争抢概率,提升 TiKV Leader 实例可用性。具体 Placement Rules in SQL 规则参考 2.1.3 部分说明。
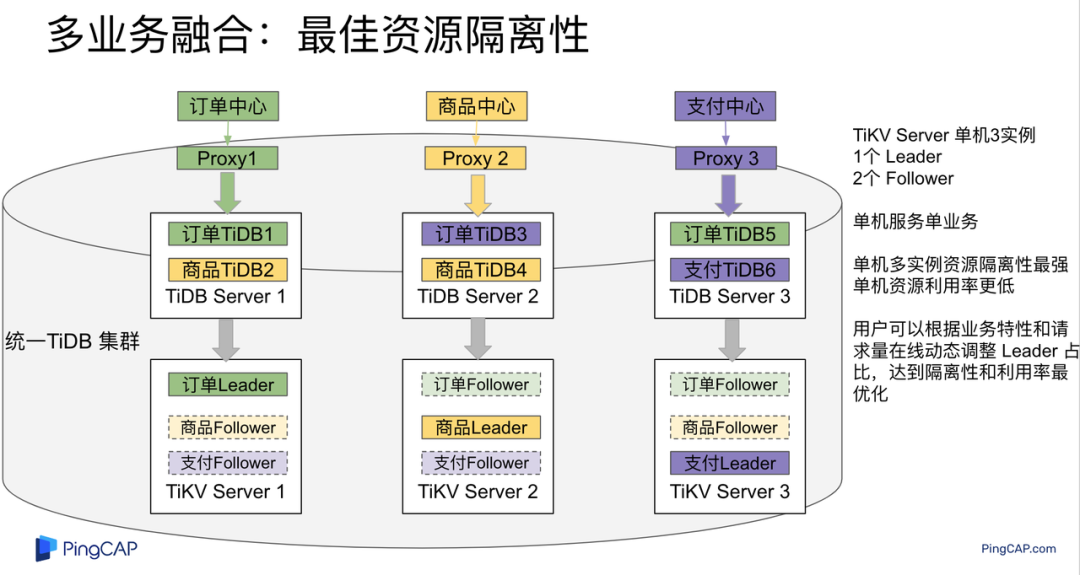
架构说明:
各实例部署模式与图 4.1 相同,使用 Placement Rules in SQL 控制单台 TiKV Server 中 3 个 TiKV 实例只有 1 个 TiKV 实例承担 Leader 角色支持业务读写,此时可以保证 TiKV Server 只为单个业务服务,达到最佳隔离性。用户可以基于业务特征在线动态调整多业务部署架构实现最佳资源利用率与最佳隔离性平衡。
部分业务有大促需求,修改 Proxy 配置,让大促业务使用更多原本比较空闲的 TiDB 计算资源,提升业务数据计算能力。同时提前修改 Placement Rules in SQL 规则让大促相关的业务表分布在更多原本比较空闲的 TiKV 节点,以便提升大促表存储资源。等待大促结束再重新调整配置将计算和存储资源还给其它业务,让各业务资源重新保持隔离。
加上基础多业务融合架构,以上三种架构分别代表最佳资源利用率、性能冗余、最佳隔离性三种选择。推荐用户可以直接选择第一种部署模式,因为此部署模式简单易用资源利用率最高。接下来介绍如果配置 Placement Rules in SQL 实现 Leader 在线调整,实现不同业务资源利用率和隔离性动态平衡。具体实现方式如下:
设置 TiKV Label :
server_configs: pd: replication.location-labels: [one_leader,two_leader,’region’] tikv_servers: - host: 172.0.0.1 config: server.labels: one_leader: order_leader two_leader: order_leader region: order - host: 172.0.0.2 config: server.labels: one_leader: order_follower two_leader: order_leader region: order - host: 172.0.0.3 config: server.labels: one_leader: order_follower two_leader: order_follower region: orderLabel 说明:Label one_leader 只有一个值为 order_leader , Label tow_leader 有两个值为 order_leader , Label region 有三个值为 order,基于以上规则再配合 Placement Rules in SQL 可以实现 Leader 在线分布调整,实现三个 TiKV 分别有 1 2 3 个 Leader。
创建三个 Placement Rules in SQL 规则,分别实现最佳资源利用率、性能冗余、最佳隔离性部署架构
#最佳资源利用率规则:3 Leader CREATE PLACEMENT POLICY `p_order_three_leader` PRIMARY_REGION="order" REGIONS="order"; alter table `order`.`order` PLACEMENT POLICY=p_order_three_leader; #性能冗余规则: 2 Leader CREATE PLACEMENT POLICY `p_order_two_leader` LEADER_CONSTRAINTS="[+two_leader=order_leader]" FOLLOWER_CONSTRAINTS="{+two_leader=order_leader: 1,+two_leader=order_follower: 1}"; alter table `order`.`order` PLACEMENT POLICY=p_order_two_leader; #最佳隔离性规则: 1 Leader CREATE PLACEMENT POLICY `p_order_one_leader` LEADER_CONSTRAINTS="[+one_leader=order_leader]" FOLLOWER_CONSTRAINTS="{+one_leader=order_follower: 2}"; alter table `order`.`order` PLACEMENT POLICY=p_order_one_leader; #资源借用:此处以删除 Placement Rules in SQL 规则为例,删除之后数据默认分布到所有 TiKV 实例 alter table `order`.`order` PLACEMENT POLICY default;分别为业务数据库表应用以上规则,可以实现 3 个 TiKV 实例只有一个、两个、三个 Leader 。并且可以为某个业务实现动态在线调整最佳隔离性、性能冗余、最佳资源利用率和资源借用。以便满足不同业务在线资源隔离性调整需求。推荐一般用户使用最佳资源利用率部署架构。
在 多业务融合方案 - 上篇 中提到中小库归集时如果某些业务流量发生变化,可以实现动态调整资源组资源,具体实现说明如下。
在多业务融合方案中使用 Proxy 来实现 TiDB 节点路由,确保不同资源组使用 TiDB 节点不相同。在中小库归集场景中,假设某个小业务(用户中心)近期请求量慢慢增加可以通过 TiDB 在线扩缩容和调整 Proxy 方式将此业务由共享资源组调整到独立资源组。
参考 TiDB 集群扩缩容 文档,添加 TiDB scale-out.yaml 配置文件
tidb_servers: - host: 172.0.0.8 ssh_port: 22 port: 4000 status_port: 10080 deploy_dir: /data/deploy/install/deploy/tidb-4000 log_dir: /data/deploy/install/log/tidb-4000 - host: 172.0.0.9 ssh_port: 22 port: 4000 status_port: 10080 deploy_dir: /data/deploy/install/deploy/tidb-4000 log_dir: /data/deploy/install/log/tidb-4000执行扩容命令完成 TiDB 扩容
#1.检查集群存在的潜在风险: tiup cluster check <cluster-name> scale-out.yaml --cluster #2.自动修复集群存在的潜在风险: tiup cluster check <cluster-name> scale-out.yaml --cluster --apply #3.执行 scale-out 命令扩容 TiDB 集群: tiup cluster scale-out <cluster-name> scale-out.yaml #4.查看集群状态 tiup cluster display <cluster-name>参考官网 TiDB 与 HAProxy 最佳实践说明 ,添加新 HAProxy 实例,修改配置文件,监听新的 TiDB 实例。启动新 HAProxy 服务,修改应用连接地址为新 HAProxy 地址,即可完成应用从共享 TiDB 计算资源组迁移到独立 TiDB 计算资源组
listen tidb-cluster # 配置 database 负载均衡。 bind 0.0.0.0:4000 # 浮动 IP 和 监听端口。 mode tcp # HAProxy 要使用第 4 层的传输层。 balance leastconn # 连接数最少的服务器优先接收连接。`leastconn` 建议用于长会话服务,例如 LDAP、SQL、TSE 等,而不是短会话协议,如 HTTP。该算法是动态的,对于启动慢的服务器,服务器权重会在运行中作调整。 server tidb-1 172.0.0.8:4000 check inter 2000 rise 2 fall 3 # 检测 4000 端口,检测频率为每 2000 毫秒一次。如果 2 次检测为成功,则认为服务器可用;如果 3 次检测为失败,则认为服务器不可用。 server tidb-2 172.0.0.9:4000 check inter 2000 rise 2 fall 3参考 TiDB 集群扩缩容 文档,添加 tikv-scale.yaml 文件,注意需要设置 TiKV Label ,此文件以最简单的 TiKV Leader 均匀分布部署模式为说明
tikv_servers: - host: 172.0.0.10 config: server.labels: region: user - host: 172.0.0.11 config: server.labels: region: user - host: 172.0.0.12 config: server.labels: region: user参考 TiDB 集群扩缩容 文档,使用 TiUP 扩展集群,将以上 TiKV 加入到原集群,再创建 Placement Rules in SQL 规则,将用户中心业务数据都存储在新的 TiKV 实例上。
CREATE PLACEMENT POLICY `p_user` CONSTRAINTS = "[+region=user]"; ALTER DATABASE `user` PLACEMENT POLICY=p_user; # 修改数据库规则之后还需要修改数据库下每张已经存在的表的规则 ALTER TABLE `user`.`user` PLACEMENT POLICY=p_user; # 查看表规则应用进度 SHOW PLACEMENT;等待所有表进度都为 scheduled 之后即表示表数据已经从老 TiKV 实例迁移到新的 TiKV 实例。也可以使用以下 SQL 检查 user 数据库数据具体存放位置
select distinct t2.db_name,t2.table_name,t2.region_id,t3.peer_id,t3.is_leader,t1.address,replace(replace(t1.label,, "value",),"key": ,) as label from information_schema.tikv_store_status t1,information_schema.tikv_region_status t2,information_schema.tikv_region_peers t3 where t2.db_name=user and t2.region_id=t3.region_id and t3.store_id=t1.store_id order by 1,2,3,4;通过以上说明实现了业务在线从共享资源组迁移到独立资源组,提升了业务资源隔离能力。也可以使用类似方式将某个业务从独立资源组迁移到共享资源组。
本文进一步介绍了多业务融合之后如何基于 TiDB 的能力实现用户扩展需求,充分体现了 TiDB HTAP 、架构灵活、弹性扩缩容能力。
TiDB 强大的 HTAP 能力:可以非常简单实现实时全域数据强一致性分析和统一视图的能力,充分释放和挖掘实时全域数据价值。 TiDB 灵活的架构:业务希望调整 Leader 分布进一步提升隔离能力,在多业务融合场景下实现最佳资源利用率和最佳隔离性的平衡。 TiDB 弹性扩缩容:可以在线实现业务从共享资源组调整到独立资源组,提高资源隔离性,也可以实现业务容独立资源组调整到共享资源组,提高资源利用率。版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

