
黄东旭解析 TiDB 的核心优势
623
2023-04-14
本文基于 TiDB Cloud 生态服务团队负责人张翔在 PingCAP DevCon 2022 的演讲内容整理而成。
数据库不是单一软件,而是一个生态体系。成为一款好用的数据库,除了产品自身的能力外,繁荣的技术生态体系也至关重要,既可以提升使用体验,又可以降低使用门槛。
PingCAP 在 2022 年 11 月 1 日正式发布了 TiDB Cloud Serverless Tier,本次分享在介绍 Serverless Tier 的技术细节之余,全面解析 TiDB 的技术生态全景和在生态构建中所做的努力。阅读本文,了解有关 Serverless 的更多信息,以及 PingCAP 在技术领域的最新进展。
现在云已经不再是一个新鲜的事物,我们已经处在云的时代,与之前相比,云时代的开发者面临着与之前不同的机遇和挑战。在云时代,我们有着新的技术设施,我这里举几个例子,每个云厂商都会提供块存储服务、对象存储服务和弹性计算服务。块存储服务有高吞吐、低时延和高持久的特性。对象存储服务,比如 AWS 的 S3、国内***的 OSS,提供了低成本的海量存储空间,并且这些存储还有着超高的可用性,甚至可以跨地域复制来进行容灾。而弹性计算服务,可以给我们提供多种规格的计算实力,而且还提供了不同的计费模式,当然,根据用户的诉求进行弹性伸缩,也是一个基本的能力。
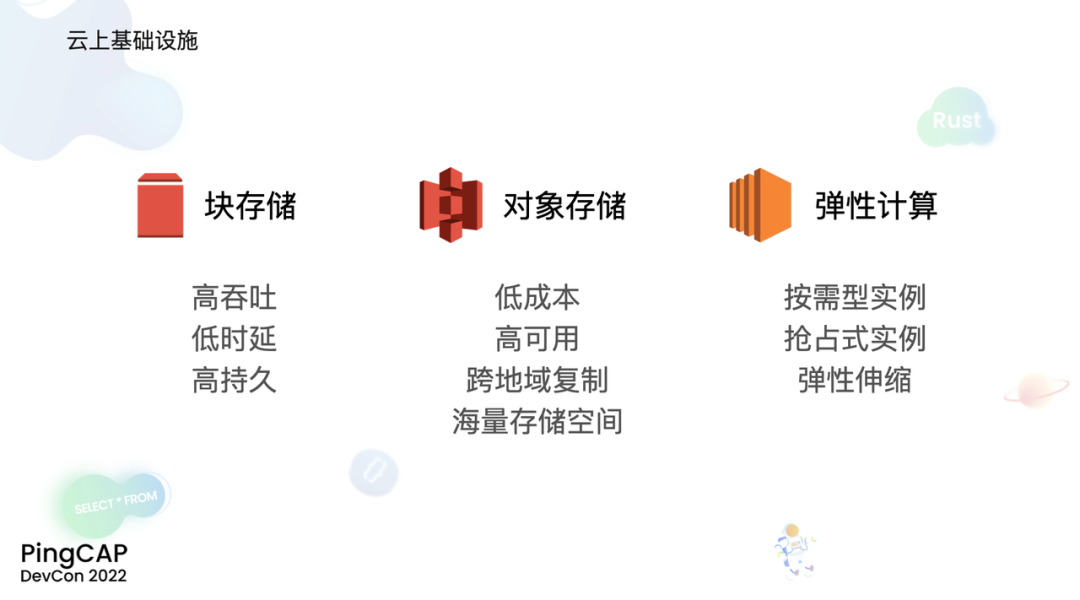
有了新的基础设施,当然也有新的挑战。云厂商给我们提供了许多的云服务,并且云的初衷之一,就是让使用者可以减少很多的运维工作。但是如果你现在深度地使用云,仍然需要运维大量的云上基础设施。这些运维工作使得我们开发者的精力被分散,没法完全专注于业务本身。除了运维工作之外,如何使用好云也是一门学问,前不久我刚刚参加了 AWS 的架构师培训,其实如何多快好省地用好云,不是一件简单的事儿。云服务的使用者,很容易就会造成云上资源的浪费,产生不必要的高额费用,特别是在现在许多的云服务,仍然是按时间来收费的情况下。对于有多套环境需求的场景,比如说公司内部有多个团队,不同的业务有各自的环境诉求,或者在 CICD 的场景下,我们可能会有 preview、stage、product 的多套环境需求,购买多套的云服务会产生高额的费用,但是共享一套云服务则可能会产生资源的竞争,甚至出现测试环境影响生产业务的情况。云上的服务,比如说云上的数据库服务,现在的使用方式仍然是提前规划容量,然后始终按照购买的时候的容量进行工作和计费,如果后期需要调整,仍然需要人工介入,手动去进行扩缩容。

这个是我们目前在使用云的时候,遇到的一些挑战。那么为了解决这些挑战,PingCAP 推出了 TiDB Cloud Serverless Tier。Serverless Tier 是世界上首款的 Serverless HTAP 数据库,PingCAP 推出它,希望能够帮助开发者解决刚才所说的那些挑战,成为云时代的新的 HTAP 数据库解决方案。TiDB Cloud Serverless Tier 目前是一个 Beta 的状态。下面,我就给大家介绍一下 TiDB Cloud Serverless Tier。
当然在之前,我们还是先来看一下传统的TiDB集群。这是一个经典的 TiDB 集群架构,可以看到这是一个非常典型的分层架构,计算层是 TiDB Server,每个 TiDB Server 都是一个无状态的计算节点,可以非常容易的进行横向扩容,存储层是 TiKV 和 TiFlash。TiKV 是我们的分布式行存储引擎,TiFlash 是列存储引擎,整个存储层通过分布式协议实现了一致分布式存储。在计算层和存储层之外,我们还有一个调度单元 PD,这里存储了整个 TiDB 集群的元信息。在这样的一个架构下面, TiDB 已经有了很好的表现。比如 TiDB 有着非常好的扩展性,无论是计算还是存储,能力都可以随节点数线性扩展。
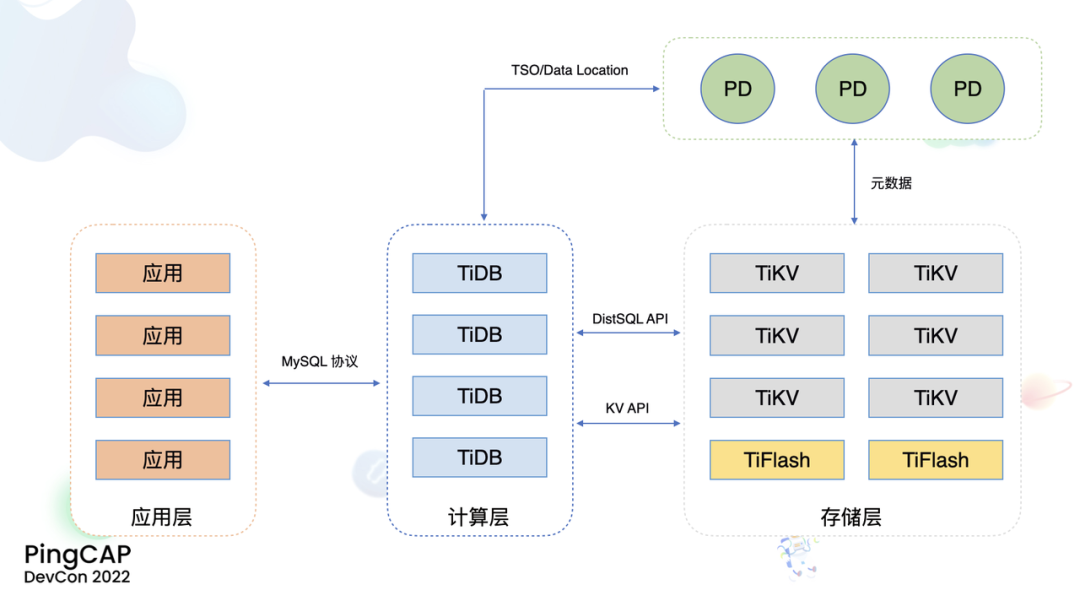
TiDB 已经在生产场景经历了数百 TB 规模的数据和百万级 QPS 的流量的考验。TiDB 还有着非常好的弹性,系统规模可以随着业务的需求进行伸缩。而且伸缩是完全在线进行的,不会影响已有的数据和请求。同时,对于系统中的热点,TiDB 也有能力自动发现,自动调度。TiDB 也有着非常好的容灾和高可用的能力,如果节点出现故障,上面的数据可以自动的进行转移,并且配合 PingCAP 推出的 TiCDC 工具,还能够做到实时的 CDC 同步,实现异地容灾。

但是这样的一个经典架构在云的时代,面对着完全不同的基础设施,存在一些问题。第一,share-nothing,刚才我们提到云厂商提供的基础设施,无论是块存储,还是对象存储,天然就有着高可用,高持久的特性,云厂商已经帮我们做了数据复制,但是 TiKV,TiDB 的存储层,仍然做的自己的数据复制。这在云上其实是多余的,数据的复制不仅仅是存储资源的浪费,同时还需要消耗大量的带宽,在云上,网络也是会造成非常高额的费用。第二,存储层状态重。这是因为每个存储节点,其实都存储着一些数据的副本,扩容转移一个故障节点都需要对这些副本进行同步,导致横向扩展的速度仍然不够快,也进一步导致难以利用云厂商提供的竞价实例,从而能够进一步的去降低成本。第三,TiDB 之前是一个非常经典的计算、存储、调度分离的架构。但是在云时代,这样划分的颗粒度仍然过大,每一个节点承担的责任过多,导致 TiDB 整体的弹性仍然不够,其实我们可以在云上,将更多的功能拆分出来形成单独的微服务,这些微服务可以独立的去进行扩容和部署,甚至这些微服务可以被多个集群去共享。如果拆分出更多的微服务,TiDB 集群整体的弹性会进一步上升。

基于这些问题,其实 PingCAP 做了很多的努力,也都做了相应的改进,大家可以看到这是现在 TiDB Cloud Serverless Tier 的一个新架构。首先在存储层开发了 Cloud Storage Engine 一个新的存储引擎,图中 Shared Storage Layer 和 Shared Storage Pool 这两层组合起来就是新的 Cloud Storage Engine。现在新的存储引擎融合使用了云上的块存储和对象存储,并且消除了原来存储层冗余的数据复制,彻底的解决了之前所说的 share-nothing 和状态重的问题。这样的改造使得存储层的节点扩展非常容易,而且非常迅速,而且大幅度地降低了成本。
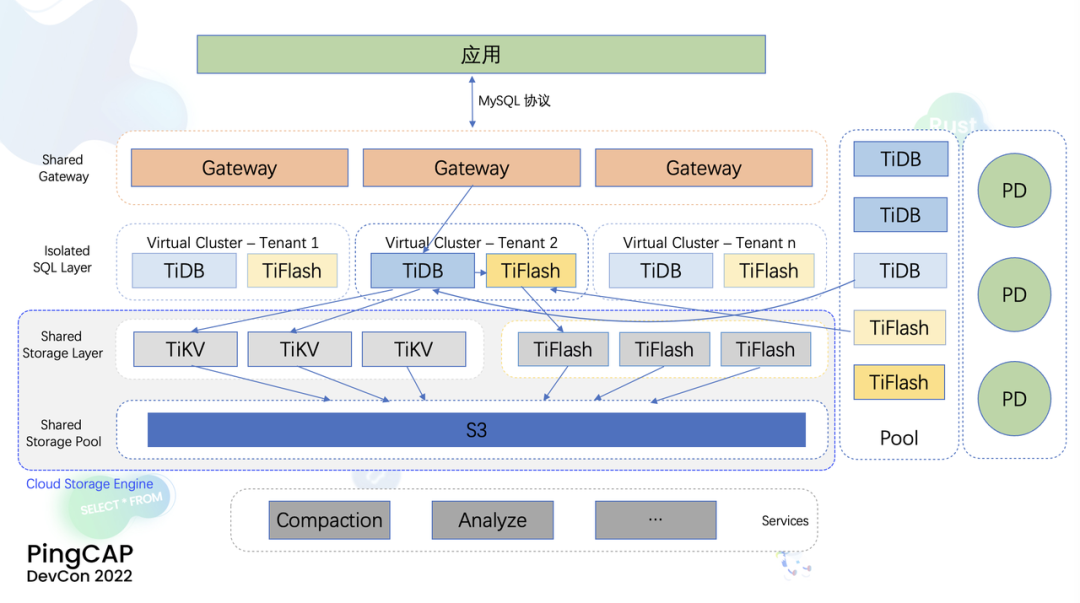
在计算层我们进一步地拆分了 TiFlash,TiFlash 现在它的计算存储已经可以去分离,TiFlash 的计算部分可以像 TiDB Server 一样,作为一个独立的组件去进行管理,去扩容。第二,我们引入了新的一层,叫做 Gateway。Gateway 代替了 TiDB Server 与用户去进行交互,它负责诸如连接管理、唤醒节点,这样的功能。它的出现使得我们所说的多租户成为一个可能。第三,我们池化了计算节点,在图上右边的部分,有多个 TiDB 和 TiFlash。我们将计算节点进行了池化,这样的设计进一步降低了计算层的成本,以及提升了计算节点唤醒的速度。计算层和存储层的改动,使得 TiDB Cloud Serverless Tier 支持了多租户。现在一套 TiDB Cloud Serverless Tier 集群,可以支持多个租户,每个租户都是完全隔离的。在用户看来,他们拥有的就是一套独立的 TiDB 集群。
最后,我们还拆分了一些相对独立的功能,做成微服务,比如数据压缩服务,降低了计算节点以及存储节点的复杂性,提升了 TiDB Cloud Serverless Tier 的整体的弹性,后续我们还会继续对更多的微服务进行拆分。

做完相应的改进,新的架构解决了之前所说的传统架构在云上的问题,更好地适应了云上的基础设施。这边总结一下,一是推出了 Cloud Storage Engine,可以融合地使用块存储和对象存储,并且消除了多余的复制,解决了两类问题,一是冗余的复制,二是高额的网络费用。第二,拆分出了更多的微服务,更好地使用了云上的弹性算力。整体的改动使得 TiDB Cloud 可以支持多租户。
技术上的努力使得 TiDB Cloud Serverless Tier 拥有了非常新颖的能力。TiDB Cloud Serverless Tier 拥有全部的 TiDB 的 HTAP 能力,是世界上第一款 Serverless HTAP 数据库。我们优化了 TiFlash 的架构,使其更好地适应了云上多租户的场景。从刚才介绍的 TiDB Cloud Serverless Tier 的架构上可以看到,我们对计算节点进行了池化,多租户也共享了存储。所以,TiDB Cloud Serverless Tier 目前可以做到秒级创建一个 TiDB 集群,并且如果你长时间不使用,再次连接的时候也仅需数百毫秒的时间就可以恢复完整的集群。这个操作对于用户来说,是完全透明的,用户甚至感知不到。未来,我们会进一步优化这个时间,集群创建时间会持续缩短,唤醒时间也会从数百毫秒缩短到数十毫秒。
作为一款真正的 Serverless 云数据库,当然,TiDB Cloud Serverless Tier 是完全无需用户去运维的。在使用方式上,不需要像传统的云数据库那样,提前去规划容量,在需要的时候进行扩缩容,TiDB Cloud Serverless Tier 会根据流量自动地进行伸缩,无需任何手动的操作。具备了这么强大的能力,TiDB Cloud Serverless Tier 的计费方式也是真正的按使用量付费,用户只需要为自己真正使用的资源进行付费,不使用,即使这些集群仍然在运行当中,你也无需支付任何的费用,这也是 TiDB Cloud Serverless Tier 区别于传统云数据库甚至于其他 Serverless 数据库的不同之处,这些数据库即使你不使用,但只要集群被创建出来,仍然会按照创建时的规格进行收费,这其实会造成极大的资源浪费。
同时 TiDB Cloud 是支持多云厂商的,Serverless Tier 也将会继承这一点。目前 TiDB Cloud Serverless Tier 仅支持在 AWS 上创建,但未来一定会支持更多的云厂商,同时 Serverless Tier 还支持多个区域,满足用户时延和数据存储区域选择的诉求。
讲了这么多,接下来我们来展示一个 Demo,这个 Demo 就是我们从无到有来创建一个 TiDB Cloud Serverless Tier 集群,这个其实也是基本上是所有用户唯一需要与 TiDB Cloud Serverless Tier 打交道的一个动作,因为刚才我们说了,一旦创建之后其实你不需要去运维,你也不需要去进行手动扩缩容,TiDB Cloud Serverless Tier 会根据你的流量自动进行扩缩容,我们开始看一下集群创建的过程。
Demo 视频我们只需要点击创建,如果你需要可以选择名字以及供应商以及 region,这里我们都是使用默认的。然后就进入了创建的一个过程,可以看到大概在 20 秒的时候整个集群其实就已经从 creating 的状态变成了 avaliable 的状态,TiDB Cloud Serverless Tier 现在整个创建时间大概就是在 20 秒左右,可能会上下有一定波动,基本是在这样一个量级。只需要 20 秒你就可以拥有一个完全工作的 HTAP 云数据库,并且后续不需要你进行任何操作以及与它有任何运维上的交互。
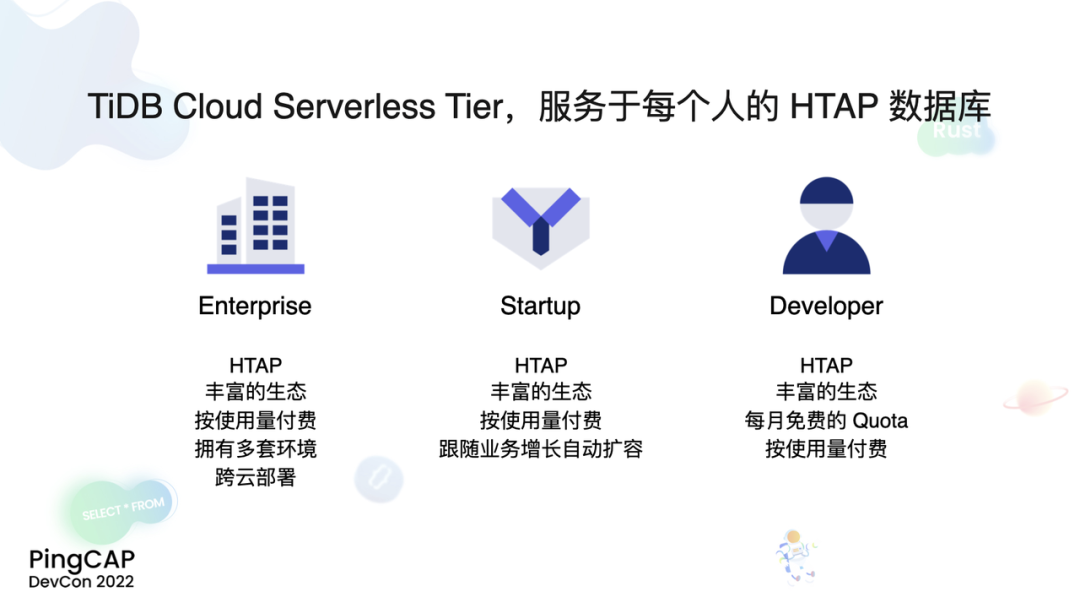
希望经过我们的努力,TiDB Cloud Serverless Tier 可以成为一个服务于每个人的 HTAP 数据库,TiDB Cloud Serverless Tier 现在拥有了完整的 HTAP 能力,可以处理复杂的工作负载,并且真正地按使用量付费,对于任何人都只需要为自己使用的计算资源和存储资源付费,不存在资源浪费的情况,具有非常高的性价比。对于个人开发者,TiDB Cloud Serverless Tier 每个月其实都提供了一定量免费的 Quota,只要不超过这个 Quota,对于个人开发者而言,TiDB Cloud Serverless Tier 就是一个完全免费的触手可及的 HTAP 数据库,对于 Startup 来说,TiDB Cloud Serverless Tier 可以跟随业务增长自动进行扩容,而且这个扩容完全是自动的,不需要手动介入。Startup 可以专注于他的业务本身去发展自己的业务,不需要为数据基础设施去操心。对于大公司而言,因为 TiDB Cloud Serverless Tier 超高的性价比以及非常迅速的创建恢复时间,使得云上资源不再成为一个限制,每个部门、每个环境都可以拥有自己独立的数据库,未来我们还会推出 data branching 更好地帮助企业客户,当然如果公司有跨云部署的诉求,TiDB Cloud Serverless Tier 也是一个非常完美的选择。
当然,对于任何一个数据库的使用者不可能仅仅与数据库软件本身打交道,同时需要使用大量的数据库生态软件,TiDB Cloud Serverless Tier 拥有非常丰富的生态,接下来我们就来看一下 TiDB 的生态。数据库不是单一软件,而是一个生态体系,除了产品自身的能力,繁荣的技术生态体系也至关重要。TiDB 从出生起就非常重视生态,所以选择了与 MySQL 兼容,并且在这个上面做了许多努力。
因为 TiDB 是 100% 兼容 MySQL 协议的,所以 TiDB 与所有的主流语言都是兼容的,比如 Go、Ruby、Java 、Python、JavaScript 等等,还有更多。TiDB 兼容的远远不只这些语言,这里列了一些比较流行的语言,只要一个语言拥有 MySQL driver,它就可以使用 TiDB,使用 TiDB Cloud Serverless Tier,不管这个语言多么小众。

在语言之上,TiDB 还与基本上所有的流行的 ORM 框架兼容,与语言的 driver 不同,除了协议层的兼容之外,ORM 往往在功能上对 MySQL 的兼容性有着更高的要求,TiDB 的一些扩展能力也需要去进行补齐。TiDB 在这个方面做了很多努力,首先针对一些 ORM 开发了自己的插件,比如对于 django 和HIBERNATE,我们开发了django-tidb 和 hibernate-tidb 插件。TiDB 也在产品本身的 MySQL 兼容性的能力上做了很多增强,比如,可能在应用中我们可以不用,但是对于许多 ORM 框架都非常重要的两个功能 savepoint 和外键。这两个功能对于很多的 ORM 框架来说都非常重要,很多 ORM 框架对他的依赖都非常重。在最近两个 TiDB 的版本中发布了savepoint 功能和实验版本的外键功能,这使得 TiDB 进一步提升了与许多 ORM 框架的兼容性。

除了语言的 driver 和 ORM 框架之外,TiDB 以及 TiDB Cloud 还可以集成许多流行的平台,我们这里罗列了一些主要的,比如在数据处理领域,TiDB 可以与 Spark、Flink、Databricks 这些流行的大数据处理框架以及平台结合使用,来构建企业的 ETL pipeline,形成统一的数据处理平台。同时除了传统的 ELT 平台,TiDB 还可以与海外非常流行的 modern data stack 体系进行集成,我们给 Airbyte 贡献了 tidb-source-connector 和 tidb-destination-connector,开发了 dbt-tidb adapter,使得 TiDB、TiDB cloud 可以完美地与 Airbyte、dbt 进行集成。
当然 TiDB 还支持类似于 Metabase 这样的 BI 平台,分析 TiDB 中存储的数据。在 CDC 的领域 TiCDC 支持了 avro 格式以及 kafka sink,使得 TiCDC 可以支持将数据导出到 confluent 平台,同时我们还测试了与 arcion 平台的兼容性,可以使用 arcion 平台来做 TiDB 或者 TiDB Cloud 的 CDC。

TiDB 和 TiDB Cloud 很早就支持了使用 prometheus 和 grafana 作为监控平台,我们还支持将监控的 metrics 导出到 datadog 平台,还可以实现与 Serverless 部署平台 Vercel、Netlify 的集成,以及与 no-code workflow automation 平台,像 zapier、n8n 的集成,以及与 IaC 工具 Terraform 的集成等等。接下来深入到一些领域来仔细看下。
首先来看 modern data stack 领域也就是我们所说的 ELT pipeline,注意,这里不是传统的 ETL pipeline,是 ELT pipeline。首先介绍一下 Airbyte 和 dbt,Airbyte 是一个 data pipeline 平台,它可以连接数百种数据源和数据汇,将数据源中的数据导出到数据汇中,然后在数据汇中对数据进行整理。基于此,用户可以通过 Airbyte 实现任意的数据迁移,它的口号就是 data from any source to any destination。dbt 是一个 data transformation 工具,借助 dbt 用户可以非常灵活地在数据库或者数据仓库中操作数据,进行数据变换。结合使用 Airbyte、dbt 和 TiDB Cloud,用户可以将任意数据源中的数据,比如在 salesforce 中的 CRM 数据,google sheets 中的表格数据,甚至是像 Instagram 这样 2C 应用中的企业运营数据导入到 TiDB Cloud 中。有了数据,我们可以利用 BI 工具进行数据分析,因为 TiDB 以及 TiDB Cloud Serverless Tier 是一个 HTAP 数据库,在面对分析型负载的时候,有着更好的表现。甚至,如果说用户有数据归档的诉求,可以继续将 TiDB 作为 Airbyte 的数据源,将数据导入到像 Snowflake、Databricks、Google Big Query 这样的数据仓库或者说数据湖中去。
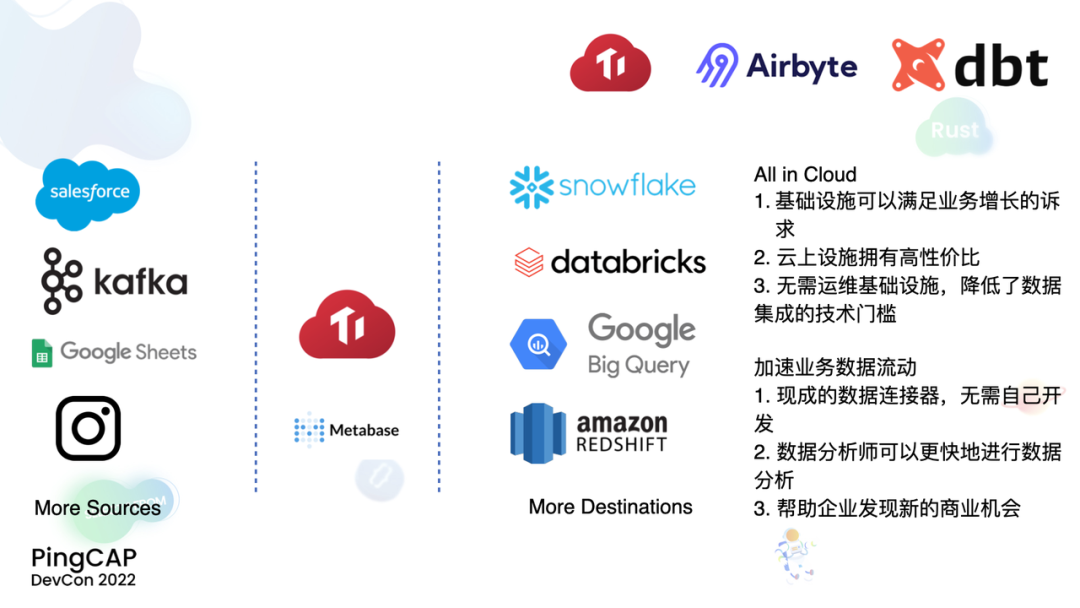
总的来说,用户如果结合使用 TiDB Cloud、Airbyte 和 dbt 建立一条 ELT data pipeline,一是可以使自己的数据设施 all in Cloud,整条流水线都可以拥有非常好的弹性,可以满足业务增长的诉求。同时云上的基础设施拥有很高的性价比,可以降低数据基础设施的成本,而且因为 all in Cloud,你无需运维,降低了数据集成的技术、费用门槛。二是可以加速企业内业务数据的流动,Airbyte 拥有上百种的数据连接器,用户可以直接去使用,无需自己设计、开发,从而企业内的数据分析师可以更快地进行数据分析,帮助企业发现新的商业机会,而不是把精力浪费在基础设施的重复建设当中。
接下来看 Vercel,Vercel 是海外领先的前端部署平台。使用 Vercel 开发者可以非常迅速地将自己的 web 应用进行部署、分发给全球的访问者,在这个过程当中 Vercel 还可以加入到开发者的 CICD 流程当中,使开发者可以轻松地预览效果。同时借助 Vercel 遍布全球的边端网络,访问者可以以极低的时延访问 web 应用,获得极佳的用户体验。
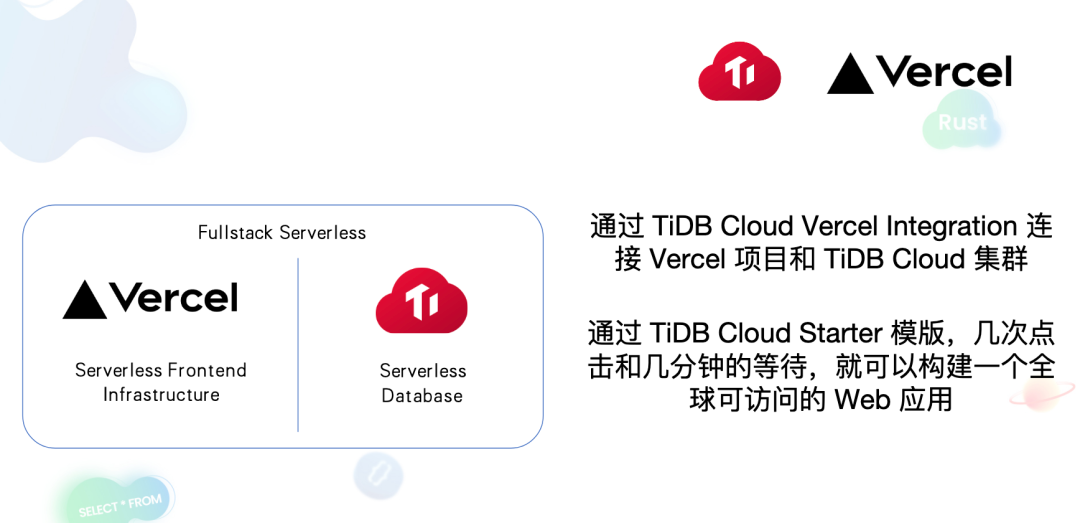
Vercel 本身作为一个 Serverless Frontend Infrastructure,它不具备持久化数据存储的能力,这也就意味着如果仅仅使用 Vercel 的能力,没办法去开发一个复杂的 web 应用。所以我们可以结合 Vercel 和TiDB Cloud Serverless Tier,从而获得一套完整的 web 开发的 Fullstack Serverless Infrastructure,和前面的 all in Cloud 的 data pipeline 一样,这套 Web App Develop Infrastructure 也是 all in Cloud,用户无需运维,基础设施可以自动扩展,并且具有很高的性价比。
为了让用户更好地使用 Vercel 和 TiDB Cloud Serverless Tier,我们开发了 TiDB Cloud Vercel Integration ,你可以在 Vercel 的 Integration 市场中找到它,通过这个 integration,只需要简单的几次点击就可以连接 TiDB Cloud Serverless Tier 集群和 Vercel 项目。同时我们还开发了 TiDB Cloud Starter 模板,这个模板可以让用户通过几次点击和几分钟的等待,就从无到有地构建一个全球可访问的 web 应用。以下是一个简单的 demo 让大家来体验这套 Fullstack Serverless Infrastructure。
Vercel Demo 视频这是 Vercel 的 template 列表,先找到我们的 TiDB Cloud Starter 模板,进入模板的详情页,点击 deploy 进到一个流程页。首先因为这是一个模板,所以我们要基于这个模板来创建一个我们自己应用的代码仓库,这里选择 starter,你只要简单的一次点击就可以。
在这个过程当中集成了 TiDB Cloud Vercel Integration,这个页面就是 integration 的页面。这里选择我们想要的 Vercel 项目以及想要的 TiDB Cloud Serverless Tier 的集群,选择之后点击 integrate,这个 integrate 的过程就结束了。到这里我们需要操作的过程已经完全结束了,现在处在等待 Vercel 帮你构建项目以及部署项目的一个阶段。大家可以看到,创建我们自己的代码仓库点击了一次,进行 integrate 点击了大概一到两次,我们就完成了所有的操作。
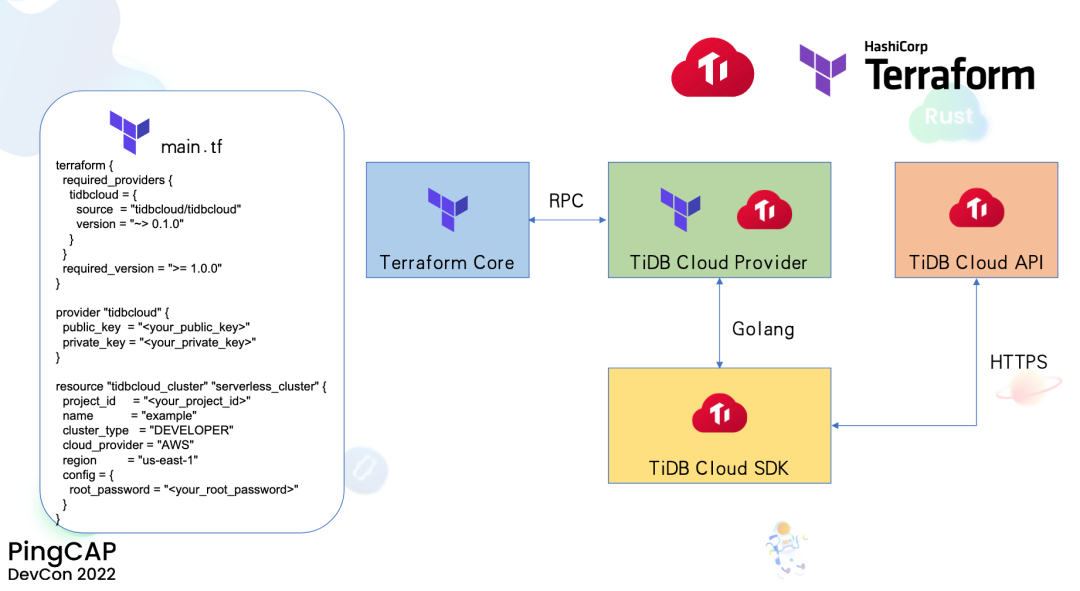
接下来稍微等待一下,大家可以看到现在大概过了两分钟,整个部署和构建过程就完成了。我们到 Vercel 项目的详情页去点击 visit,可以看到这时候这里展示的页面就是通过模板构建出来的一个项目的主页,大家可以看到这上面的 URL 是一个所有人都可以访问的 URL,现在这个项目已经对全球可以访问了。任何人在地球上的任何角落现在都可以来访问 bookstore 这个项目,整个的耗时也就大概两三分钟。这个项目前端整个的代码应用逻辑是部署在 Vercel 的 Serverless 的架构上面,后端数据存储是存储在 TiDB Cloud Serverless Tier 集群中。我们进入下一个生态 Terraform,Terraform 是业界默认的跨云 IaC 工具,使用 Terraform 可以使用代码来管理云基础设施,将它集成到我们的 CICD 流程当中,我们在前不久开发了 TiDB Cloud Terraform Provider,使得用户可以通过 Terraform 来管理 TiDB Cloud 的资源。像图上展示的,我们可以通过这样的一个 Terraform 文件来创建一个 TiDB Cloud Serverless Tier 集群。Terraform Core 会解析这个文件,将 TiDB Cloud 资源的相关定义都发给我们开发的 TiDB Cloud Terraform Provider,TiDB Cloud Provider 会调用 TiDB Cloud Go SDK 来操作 TiDB Cloud 的资源。PingCAP 已经和 HashiCorp 成为了技术合作伙伴,TiDB Cloud Terraform Provider 也已经是 HashiCorp 认证的 Partner Provider,欢迎大家使用 Terraform 来操作 TiDB Cloud 的资源。
最后,我们一起展望一下未来,TiDB Cloud Serverless Tier 才刚刚发布,我们仍然有很长的路要走。
目前因为刚刚推出,Serverless Tier 还没有向用户开放诸如像备份、恢复、监控、报警这样的能力,我们很快就会添加这些能力并对用户进行开放。我们还会开发 PiTR 和 Branching 这些功能,方便用户进行数据共享,将数据库纳入CICD。我们还会进一步地去降低创建时间和成本,期望 Serverless Tier 集群的创建时间能从现在的 20 秒降低到 5 秒,唤醒时间从数百毫秒降低到数十毫秒。后续会推出 Data API,Data API 是通过 RESTful API 的形式提供数据库的 CRUD 能力,未来除了 RESTful 之外还可能推出 GraphQL API。通过 Data API 希望 Serverless Tier 可以更好地与 Serverless 生态结合,服务边缘请求。现在很多的 Serverless 的部署平台加速从中心化的托管能力向边缘进行扩张。当我们使用边缘的一些托管 runtime 是根本无法发出像传统的 TCP 请求的,所以 Data API 的推出可以让 Serverless Tier 更好地与这些平台进行结合。

在生态方面,我们会进一步提升 MySQL 兼容性,对接更多平台,给用户提供更多选择。PingCAP 始终坚持开源开放的路线,TiDB 社区从诞生开始就开放并包,我们期望大家加入,共建 TiDB 的繁荣生态。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

