

黄东旭解析 TiDB 的核心优势
849
2023-04-14
本文作者为 Moka 数据架构师张晓辉
Moka 是一家 HR SaaS 服务提供商,致力于通过一流技术和服务赋能企业的人才战略。Moka 的 BI 系统通过数据统计和实时报表等方式,实现了企业招聘和人力资源管理系统的智能化。文章重点介绍了 Moka BI 对其数据库架构的革新,分享了其系统现状及对选型的思考。在综合考虑兼容性、稳定性、简洁性、易用性、高可用等因素后,Moka BI 选择了 TiDB 作为支撑新架构的数据库,解决了数据壁垒,降低业务复杂度,实现了全面的性能提升。
Moka 是一家致力于为全员带来更好体验的 HR SaaS 服务商,从 2015 年成立到现在已累计获得数十亿元的融资,先后服务小米、万科、太平洋保险等各领域的头部企业,累计服务超 2000 家客户,核心产品智能化招聘管理系统和人力资源管理系统,为中大型企业提供从招聘、入职、薪酬、假勤、绩效等人力资源全模块管理,为企业提供极致体验、数据驱动的 HR SaaS 产品,致力于通过一流技术和服务赋能企业的人才战略。
Moka BI 则通过全方位的数据统计和可灵活配置的实时报表,赋能智能化招聘管理系统和人力资源管理系统,通过 PC 端和移动端的多样报表展示,从而改善招聘业务、提供数据支持、提升招聘竞争力,从而助力科学决策。
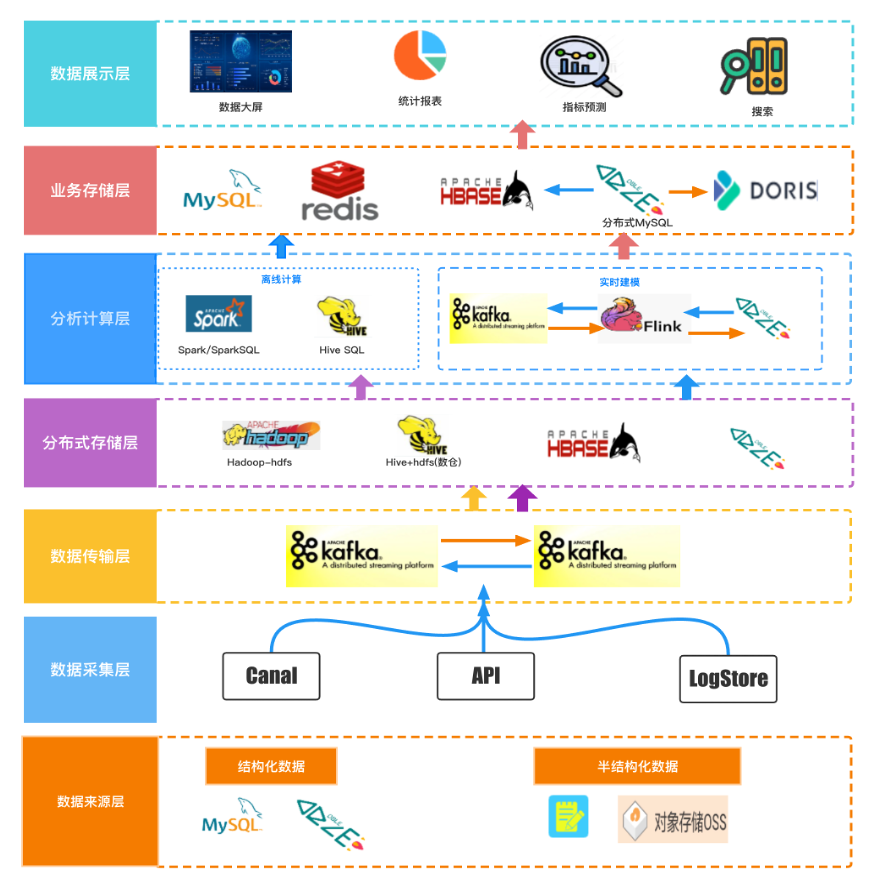
Moka BI 的架构主要是类似于 Lambda 架构,实时处理和离线处理并存,实时数据主要来源为结构化的数据,Canal 采集 MySQL 或者 DBLE(基于 MySQL 的分布式中间件) 的 binlog,输出是 Kafka,未建模的数据按照公司进行分片,存储在业务的 DBLE 中,通过 Flink 进行实时建模,将计算后的数据写入 BI DBLE。Doris 定时同步 BI DBLE 的数据,支持数据大屏和实时报表统计,离线部分则涵盖了实时部分的数据,其结构化的数据来源于建模后的 BI DBLE 数据,明细数据存储在 *** 中,并进行实时更新,映射成 Hive 表,非结构化的数据通过 ETL 流程存储至 Hive 中,并通过 Spark 进行计算、建模,离线数仓 ADS 层的数据,最终输出至 MySQL Redis 中,支撑离线报表统计,明细数据又支持招聘预测和搜索等外部应用。
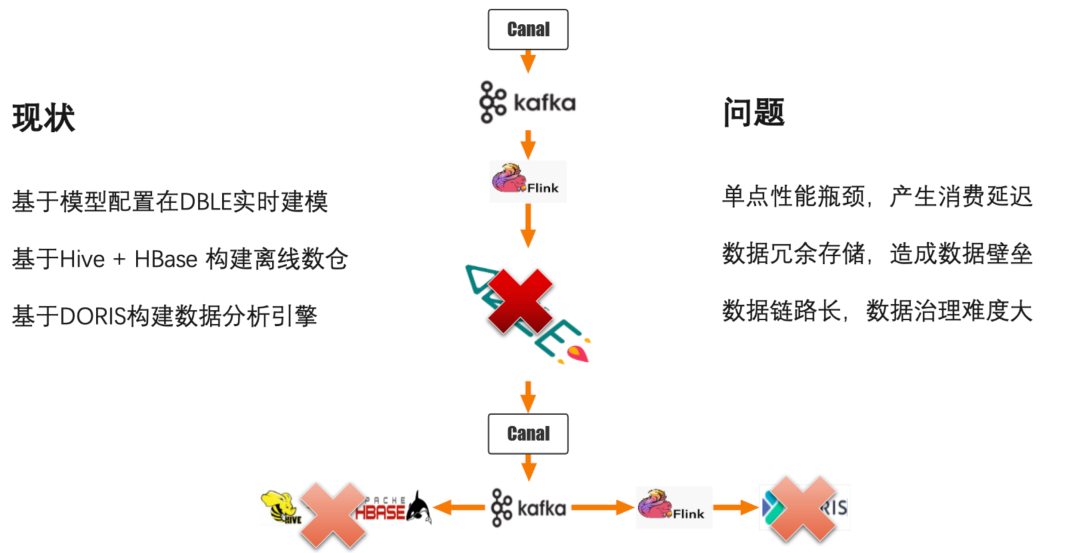
基于 BI 整体架构,接下来看实时数据的走向和现状。首先实时数仓都是基于模型配置在 BI DBLE 中进行实时建模,BI DBLE 中的数据也是按照公司 ID 进行分库,建模后的数据通过 Canal 再次写入 Kafka,此时会有两个 Flink 程序消费该 Kafka 的数据,考虑到 Doris 的实时写入性能,Flink 会进行窗口数据合并,然后 VP 将数据写入到 Doris 中,同时另一个 Flink 程序也会将数据合并,微批写入到 *** 中。
当前架构的问题也很明显,首先就是在实时建模的过程中,因为单一公司都在一个 shard 上,在大流量下会触发单点瓶颈,从而导致消费延迟。其次在 DBLE、Doris、Hive 数据是大量冗余存储的,造成了数据壁垒。此外,整个数据链路很长,要保证 DBLE、Doris、Hive 的数据都是一致的,数据治理难度非常大,针对上述问题,我们进行了数据库的调研选型。
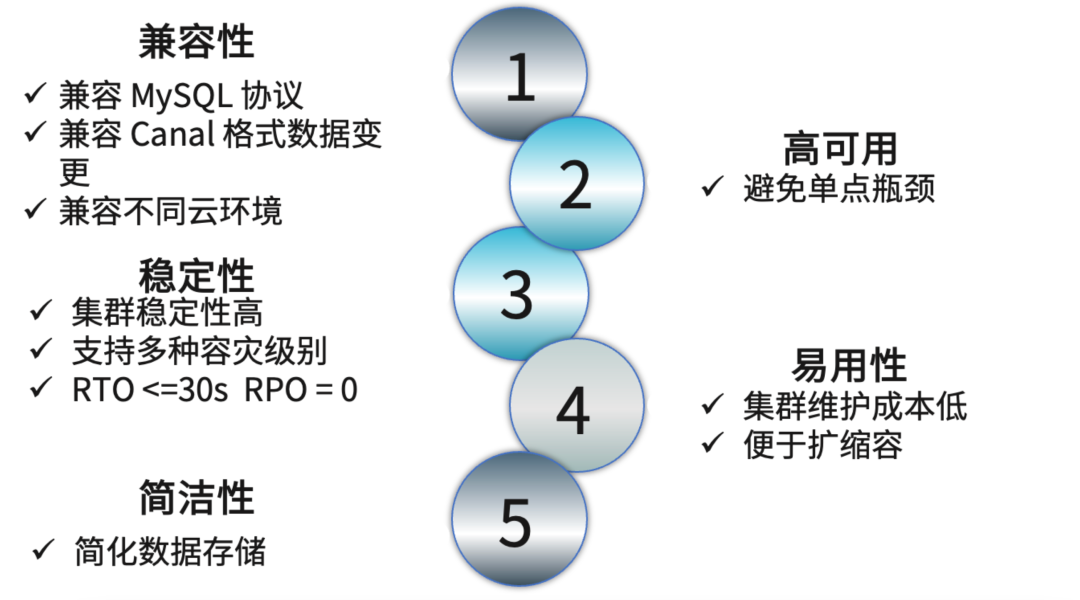
我们制定了五个方向的调研目标,一期需要满足一到三项。第一个目标是兼容性,数据库要兼容 MySQL 的协议和生态,其次要兼容 Canal 格式的数据变更,还要兼容不同的云环境。第二是离散性,数据库要尽可能避免单点性能瓶颈。第三是服务的稳定性,首先是集群稳定性要高,并且支持多种容灾级别,在发生灾难时,故障响应时间要小于 30 秒,且在故障恢复后不能有数据延迟或者数据丢失。第四是易用性,我们希望数据库集群的维护成本低,并且便于扩缩容。最后的目标是简洁性,首先要简化数据存储,更进一步是最好能简化整个数据架构。
针对上述目标我们进行了一系列的调研选型,首先想到的就是 Phoenix on ***,它的优势很明确,不需要引入额外的存储引擎,所以不涉及到数据的导入导出。它的劣势是在实时领域下,复杂的查询要基于大量的二级索引,索引维护成本比较大,且数据变更要基于协处理器,成本很高。接着,我们又调研了比较流行的 Hudi,它的优势就是整体的架构不需要大的变化,并且实时的数据能够实时入仓入湖,但是在实时存查的情况下会存在写延迟或者读延迟,且数据变更没有办法捕获到下游。
紧接着我们又调研了 ***,它的优势就是对 MySQL 的兼容性比较好,完美兼容 MySQL 的生态和协议,且迁移成本很低,支持一体化的 HTAP,且没有单点性能,看似很满足我们的调研需求,实际上它有一个很大的劣势就是没办法满足不同的云环境运行,因此也不符合本次的调研目标。
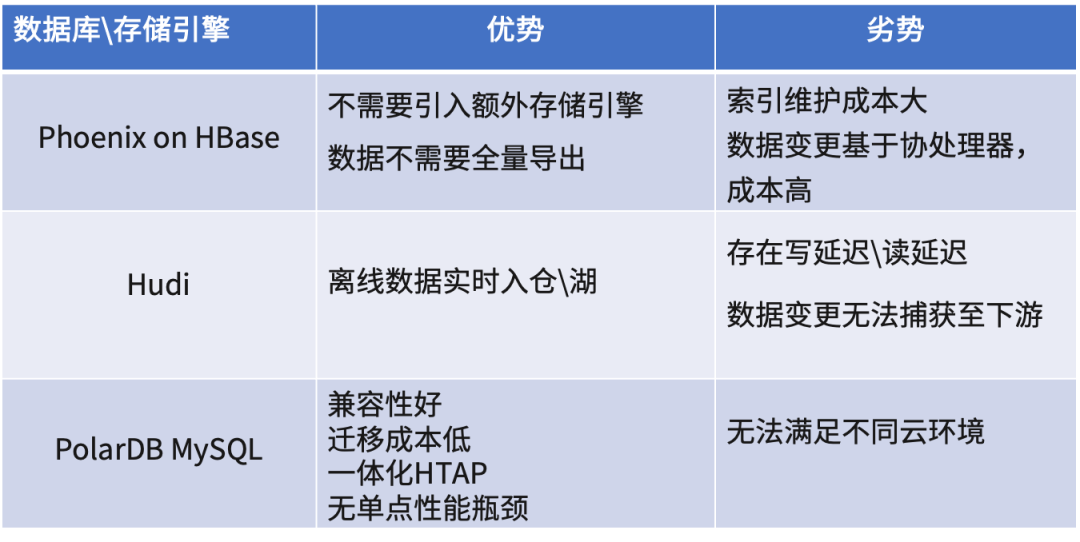
我们最终把目光瞄准了 TiDB,并进行了深度测试,为什么选择 TiDB ?TiDB 完美兼容 MySQL 协议和生态,并且 TiCDC 支持 Canal、Maxwell 等协议,无缝衔接了数据下游,并且支持在多云环境部署。其次,TiDB 带来了性能的提升,TiDB 是 Shared Nothing 架构设计,避免了数据热点,不会形成单点瓶颈,理论上性能会随着节点的无限扩展而没有上限。第三,TiDB 满足金融级高可用,多副本存储和 Multi-Raft 协议同步事务日志,支持多种容灾级别。第四,TiDB 的维护简单,基于 TiUP 一键扩缩容,且扩缩容的过程业务无感知,并且支持实时在线的 DDL。最后,TiDB 具备实时 HTAP 的能力,TiKV 行存支持 OLTP 场景的负载,TiFlash 列存与行存强一致,使用 TiFlash 和 TiSpark 可以满足大部分的 OLAP 场景需求。
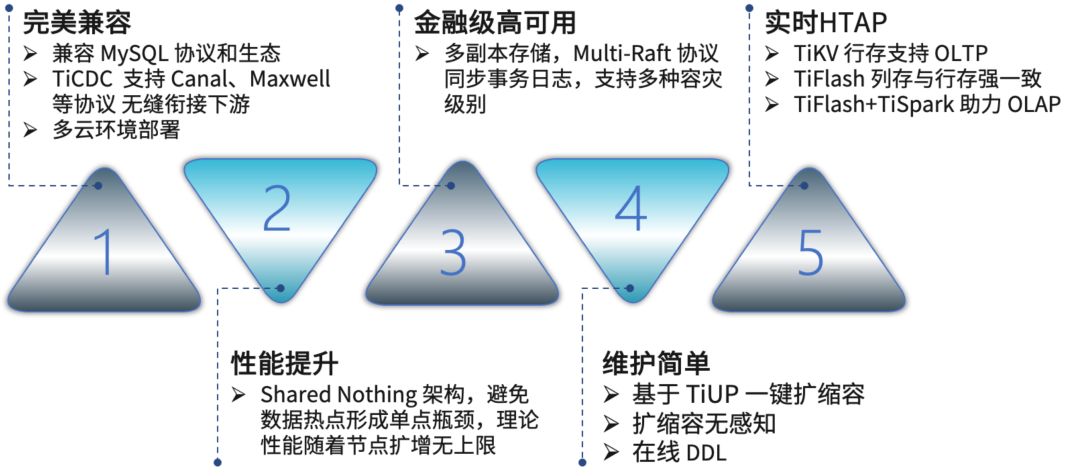
在理论上都满足之后我们进行了系统的可行性测试,安装部署了 5.4.0 版本的 TiDB 集群,集群安装部署完毕之后进行了数据导入。为了真实模拟线上的业务场景,我们同步了一个业务线的全部数据,大概有 200 多张表,有 50 张表数据超过一亿,单表最大数据量为 30 亿行。实时数据则根据 Flink 同步 binlog 实时读写 TiDB 进行建模。我们的测试主要分为三个用例,第一个用例是单 SQL 串行看平均的响应 RT。同样是用 100 万的 SQL,左边绿色的是 DBLE 的响应时间,右边蓝色的是 TiDB 的响应时间,在简单查询的用例下,DBLE 的平均响应时间为 1.2 毫秒,而 TiDB 为 2.4 毫秒,复杂查询场景下 DBLE 的平均响应时间为 8.7 毫秒,TiDB 为 5.2 毫秒。关联查询下 DBLE 的平均响应时间为 20 毫秒,而 TiDB 为 8.7 毫秒。
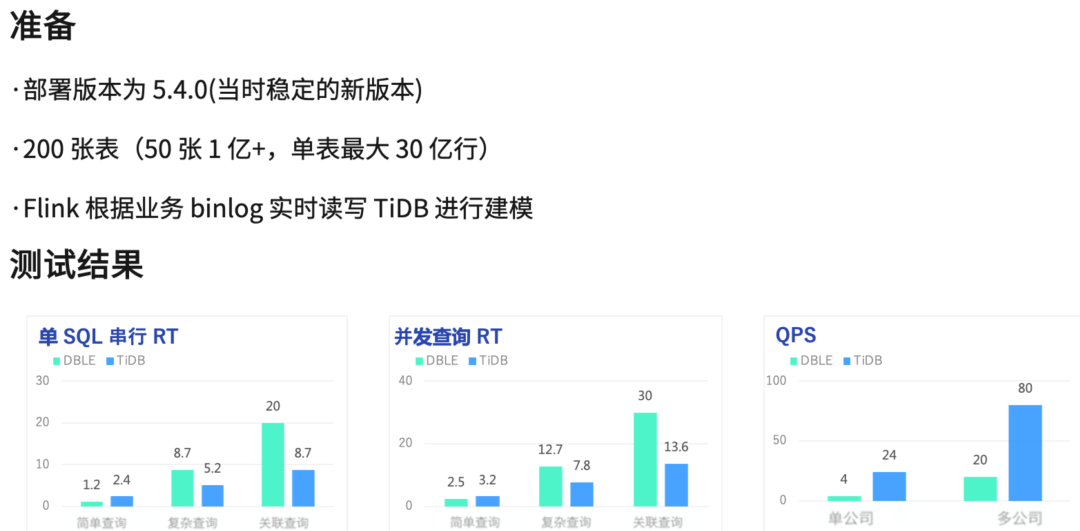
第二个用例是并发查询,我们用了 200 个并行度,同样是 100 万的 SQL,简单查询下 DBLE 的平均响应时间为 2.5 毫秒,TiDB 为 3.2 毫秒。复杂查询下 DBLE 的平均响应时间为 12.7 毫秒,TiDB 为 7.8 毫秒,关联查询下 DBLE 的平均响应时间为 30 毫秒,TiDB 则在 13.6 毫秒。可以看到单 SQL 串行和并发查询两个用例,在复杂查询和关联查询场景下 TiDB 的平均相应时间明显优于 DBLE。
第三个用例就是在 200 个并行度下看 QPS 的峰值,首先是单公司场景下,DBLE 的 QPS 峰值在 4K 左右,而 TiDB 达到了 24K,是 DBLE 的六倍之多。多公司场景下,DBLE 峰值为 20K,TiDB 为 80K,是 DBLE 的四倍之多。并且在以上两个场景中,TiDB 的负载未出现过高的现象,理论上未达到 QPS 峰值。在以上测试验证中,TiDB 的表现是完全符合预期的,因此我们决定使用 TiDB 替换 DBLE。
我们在迁移过程中也进行了一些适配性的调优,首先是主键表,我们把主键表改为公司 ID+ID 联合主键,并增加了 SHARD ROW ID BITS 和 PRE SPLIT REGIONS 配置,避免了数据写热点的问题。其次 Flink 实时程序会增加雪花 ID 算法,兼容历史数据。为了和 TiCDC 适配,我们也升级了不同云环境下的 Kafka 版本。循环读写的场景在未关闭异步提交配置时,会频繁出现锁冲突的问题,在关闭后虽然会有 7% 的性能损失,但是能有效避免锁冲突的问题,所以我们把异步提交的配置关闭了。此外,TiDB 对大小写敏感,该配置只支持在集群初始化时配置,大家留意一下。
在适配以外,我们针对 TiDB 还做了一些优化工作,我们把 TiDB 的版本从 5.4.0 升级到 5.4.2,解决了 CDC 捕获特殊符号频繁重启的问题。我们把新增表的 ID 都改为 AUTO RANDOM,这样避免产生热点 ID。TiCDC 我们增加了对应 Kafka 的相关配置,保证了更新顺序及数据可靠性。在索引优化方面,所有的索引都添加了联合的索引,就是公司 ID 加原来的主键 ID。
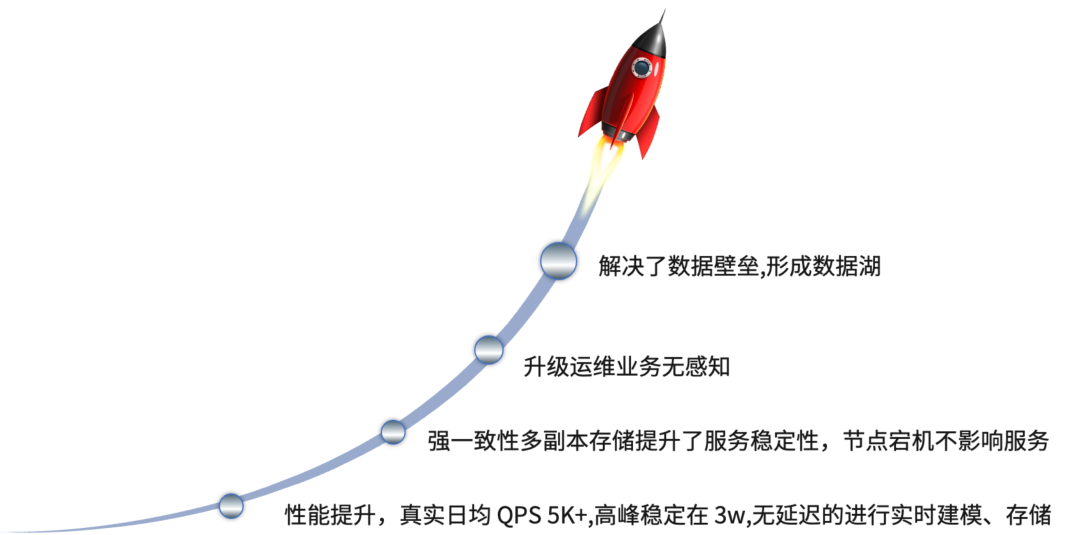
在做了上述适配性调优后,目前 TiDB 的性能得到一定的提升,真实日均 QPS 5K+,高峰稳定在 3w,读写比接近 1:1,性能的提升保证了无延迟的进行实时建模,并且强一致性的多副本提供了服务的稳定性。在 TiDB 线上运行期间有一个节点出现了特殊问题导致宕机,TiDB 在 10 秒内会自动进行恢复,没有影响到线上业务。TiDB 的升级运维也是业务无感知的,我们在迁移人力资源管理系统时,扩容了三个 TiKV 存储节点,在扩容期间对线上业务没有任何影响的。其次,TiDB 还解决了数据壁垒问题,之前两个系统存储的数据是独立的,没办法做一体化的数据访问,目前我们基于 TiDB 的统一存储形成了初级数据湖的使用模式。
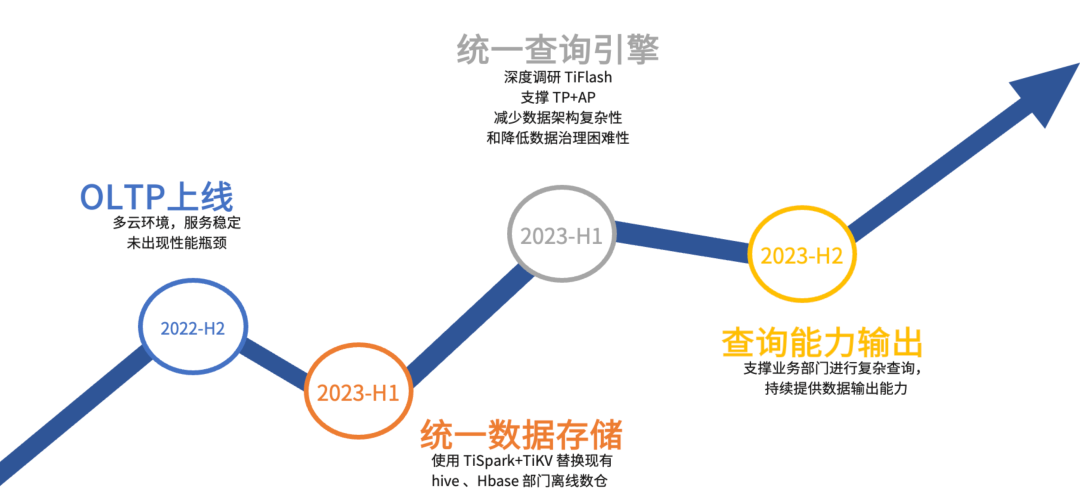
最后谈谈我们对 TiDB 的总结和展望,从 2022 年 7 月开始进行开发和测试,目前 TiDB 的 OLTP 部分已经完成了 Moka BI 全业务线的投产,在多云环境下替换了 DBLE,目前服务稳定可靠,未出现性能瓶颈,圆满达成了 2022 年下半年的目标。
随着对 TiDB 的使用深入,我们越发地认识到 TiDB 和我们的业务场景是高度匹配的,面向后续 TiDB 的使用我们制定了以下的计划:首先在 2023 年要做到两个统一,第一个统一就是统一数据存储,使用 TiSpark+TiKV 替换现有的 Hive、*** 和离线数仓;其次我们要深度调研 TiFlash,争取使用 TiDB HTAP 能力支撑 OLTP+OLAP 的统一查询场景,减少数据架构的复杂性,从而降低数据治理的困难性。在两个统一的基础上,我们要建立公司级统一的查询平台,支撑业务部门进行复杂查询,持续提供数据输出能力。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

