

黄东旭解析 TiDB 的核心优势
806
2023-03-31
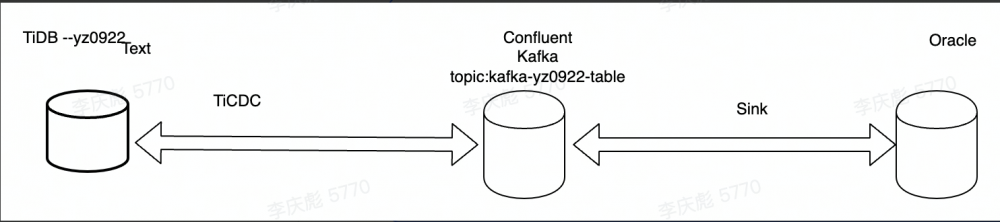
使用 TiCDC 将 TiDB test 数据库多张表以 AVRO 格式发送到 Kafka 多个 Topic ,然后使用 Confluent 自带开源 connect 将 Kafka 多个 topic 数据实时写入到 *** 数据库,此链路支持实时数据 insert/delete/update/create table ddl/add column ddl 等。理论上此链路还可以支持下游为其它异构数据库。
登陆 Confluent 官网: https://www.confluent.io/get-started/?product=software
下载 confluent-7.2.1.tar ,将下载的文件传输到服务器,解压缩为/root/software/confluent-7.2.1
[root@172-16-6-132 kafka]# ll total 1952776 -rw-r--r-- 1 root root 104 Sep 21 13:50 c.conf drwxr-xr-x 8 centos centos 92 Jul 14 12:07 confluent-7.2.1 -rw-r--r-- 1 root root 1999633201 Sep 21 10:33 confluent-7.2.1.tar.gz -rw-r--r-- 1 root root 672 Sep 21 18:08 kafka.conf [root@172-16-6-132 kafka]# du -sh * 4.0K c.conf 2.3G confluent-7.2.1 1.9G confluent-7.2.1.tar.gz 4.0K kafka.conf
Connect 是本文后续使用的组件,它支持从kafka消费数据写入到下游组件,下游组件可以通过插件支持各种异构存储系统如:***、MySQL、***、ES等
Control Center 是 Web 控制页面,用户可以在页面上管理 Kafka 集群和数据,管理 connect 任务和插件
Kafka 消息组件,不做介绍
ksqlDB Server 可以将 Kafka topic 映射为一张表,然后执行 SQL 做数据处理,此处不需要使用不过多介绍
Schema Registry 是 AVRO Schema 管理组件, Kafka 中消息 schema 变化时会往 schema registry 发送变更消息,数据同步组件发现 schema 变化之后会从 schema registry 获取最新的 schema 以便同步新 schema 数据到下游数据库
Zookeeper 元数据管理工具,支持 Kafka 选主等
tiup ctl:v6.1.0 cdc changefeed create --pd="http://172.16.5.146:2399" --sink-uri="kafka://172.16.6.132:9092/tidb-kafka-3?protocol=avro&partition-num=1&max-message-bytes=67108864&replication-factor=1" --changefeed-id="kafka-2" --config="/home/kafka/kafka.conf" --schema-registry="http://172.16.6.132:8081"
[root@172-16-5-146 kafka]# tiup ctl:v6.1.0 cdc changefeed create --pd="http://172.16.5.146:2399" --sink-uri="kafka://172.16.6.132:9092/tidb-kafka-3?protocol=avro&partition-num=1&max-message-bytes=67108864&replication-factor=1" --changefeed-id="kafka-2" --config="/home/kafka/kafka.conf" --schema-registry="http://172.16.6.132:8081" Starting component `ctl`: /root/.tiup/components/ctl/v6.1.0/ctl cdc changefeed create --pd=http://172.16.5.146:2399 --sink-uri=kafka://172.16.6.132:9092/tidb-kafka-3?protocol=avro&partition-num=1&max-message-bytes=67108864&replication-factor=1 --changefeed-id=kafka-2 --config=/home/kafka/kafka.conf --schema-registry=http://172.16.6.132:8081 [WARN] This index-value distribution mode does not guarantee row-level orderliness when switching on the old value, so please use caution! dispatch-rules: &config.DispatchRule{Matcher:[]string{"yz0920.*"}, DispatcherRule:"", PartitionRule:"index-value", TopicRule:"tidb_{schema}_{table}"}[2022/09/22 15:14:20.498 +08:00] [WARN] [kafka.go:433] ["topics `max.message.bytes` less than the `max-message-bytes`,use topics `max.message.bytes` to initialize the Kafka producer"] [max.message.bytes=1048588] [max-message-bytes=67108864] [2022/09/22 15:14:20.498 +08:00] [WARN] [kafka.go:442] ["topic already exist, TiCDC will not create the topic"] [topic=tidb-kafka-3] [detail="{\"NumPartitions\":1,\"ReplicationFactor\":1,\"ReplicaAssignment\":{\"0\":[0]},\"ConfigEntries\":{\"segment.bytes\":\"1073741824\"}}"] [2022/09/22 15:14:20.560 +08:00] [WARN] [event_router.go:236] ["This index-value distribution mode does not guarantee row-level orderliness when switching on the old value, so please use caution!"] [2022/09/22 15:14:20.561 +08:00] [WARN] [mq_flush_worker.go:98] ["MQ sink flush worker channel closed"] [2022/09/22 15:14:20.561 +08:00] [WARN] [mq_flush_worker.go:98] ["MQ sink flush worker channel closed"] Create changefeed successfully! ID: kafka-2 Info: {"upstream-id":0,"sink-uri":"kafka://172.16.6.132:9092/tidb-kafka-3?protocol=avro\u0026partition-num=1\u0026max-message-bytes=67108864\u0026replication-factor=1","opts":{},"create-time":"2022-09-22T15:14:20.42496876+08:00","start-ts":436163277049823233,"target-ts":0,"admin-job-type":0,"sort-engine":"unified","sort-dir":"","config":{"case-sensitive":true,"enable-old-value":true,"force-replicate":false,"check-gc-safe-point":true,"filter":{"rules":["yz0920.*"],"ignore-txn-start-ts":null},"mounter":{"worker-num":16},"sink":{"dispatchers":[{"matcher":["yz0920.*"],"dispatcher":"","partition":"index-value","topic":"tidb_{schema}_{table}"}],"protocol":"avro","column-selectors":null,"schema-registry":"http://172.16.6.132:8081"},"cyclic-replication":{"enable":false,"replica-id":0,"filter-replica-ids":null,"id-buckets":0,"sync-ddl":false},"consistent":{"level":"none","max-log-size":64,"flush-interval":1000,"storage":""}},"state":"normal","error":null,"sync-point-enabled":false,"sync-point-interval":600000000000,"creator-version":"v6.1.0"}特别说明:
--sink-uri="kafka://172.16.6.132:9092" 设置为之前 Confluent 启动的kafka 地址。
protocol=avro 使用 avro 格式,avro 格式支持 schema 演化,支持自动部分 DDL 同步,对比其它格式有优势
--changefeed-id="kafka-2" 表示此 ticdc 同步任务id
--config="c.conf" 表示 ticdc 任务使用 3.1 中创建的配置文件,实现多表多 topic
--schema-registry=http://172.16.6.132:8081 配合 avro 实现 schema 演化,当 TiDB DDL 变更时会发送消息给 schema-registry ,以便消息组件更新 schema
具体请参考:
https://docs.pingcap.com/zh/tidb/stable/manage-ticdc#sink-uri-%E9%85%8D%E7%BD%AE-kafka
tiup ctl:v6.1.0 cdc changefeed list --pd=http://172.16.5.146:2399
[root@172-16-5-146 kafka]# tiup ctl:v6.1.0 cdc changefeed list --pd=http://172.16.5.146:2399 Starting component `ctl`: /root/.tiup/components/ctl/v6.1.0/ctl cdc changefeed list --pd=http://172.16.5.146:2399 [ { "id": "kafka-1", "summary": { "state": "normal", "tso": 436163342428536833, "checkpoint": "2022-09-22 15:18:29.728", "error": null } }, { "id": "kafka-2", "summary": { "state": "normal", "tso": 436163342428536833, "checkpoint": "2022-09-22 15:18:29.728", "error": null } } ] 状态 normal 表示数据正常同步备注,如果发现有问题可以删除,命令如下
[root@172-16-5-146 kafka]# tiup ctl:v6.1.0 cdc changefeed remove --pd=http://172.16.5.146:2399 -c kafka-2 Starting component `ctl`: /root/.tiup/components/ctl/v6.1.0/ctl cdc changefeed remove --pd=http://172.16.5.146:2399 -c kafka-2
执行以下命令安装 kafka-connect-jdbc 插件,安装之后重启connect组件,(可能还需要重启 control center)
confluent-hub install confluentinc/kafka-connect-jdbc:latesthttp://172.16.6.132:9021/clusters
5.2.2、选择 JdbcSinkConnector 插件配置好 connect 插件之后登陆 control center ,进入主页面之后点击 connect ,再点击 connect-default ,可以看到之前已经安装的 connect 插件。
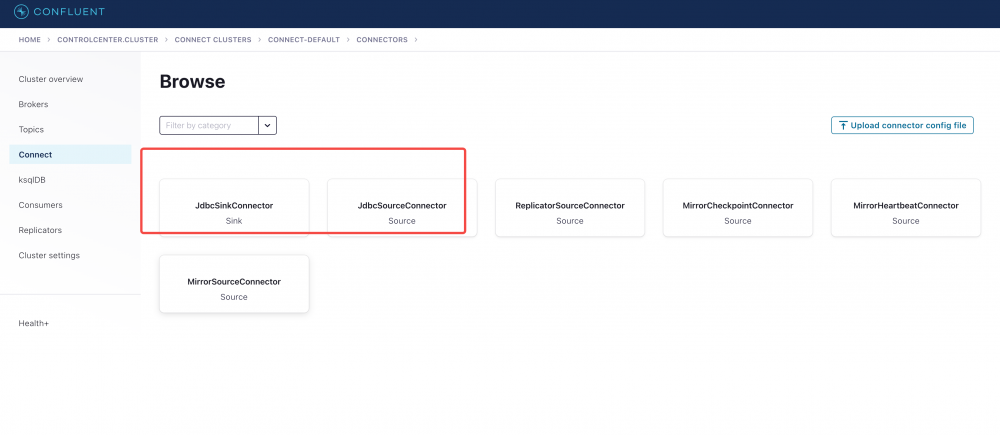
点击 JdbcSinkConnector 之后输入,配置 Topic ,此处使用正则表达式: tidb_.* 表示匹配所以 TiCDC 任务创建出来的 Kafka Topic
创建kafka的topic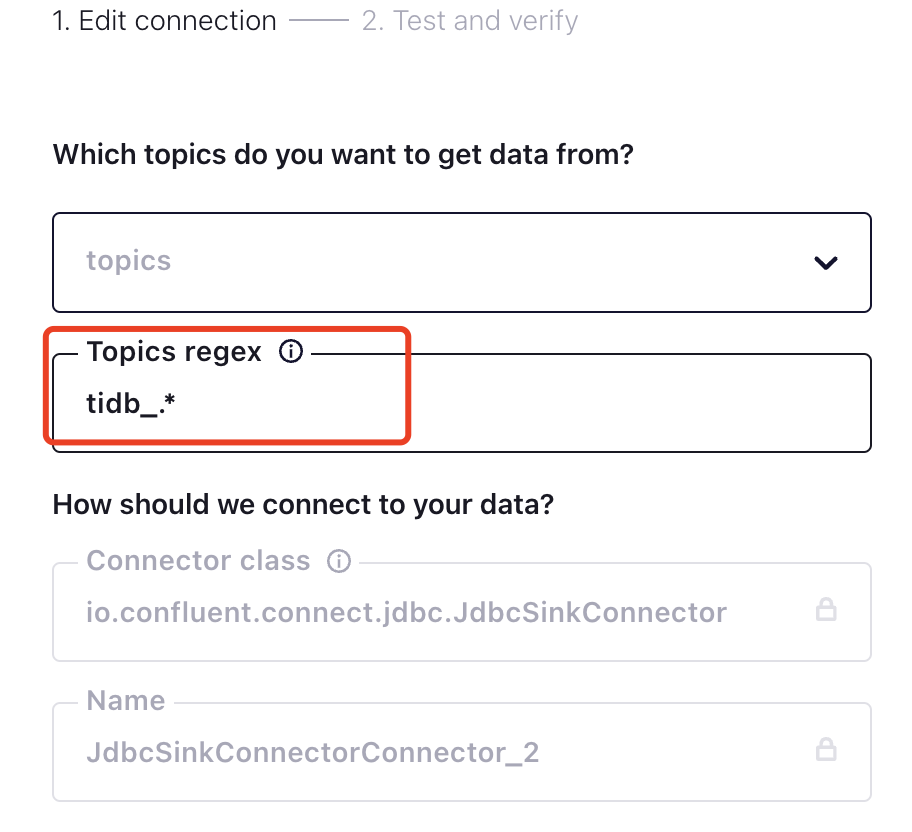
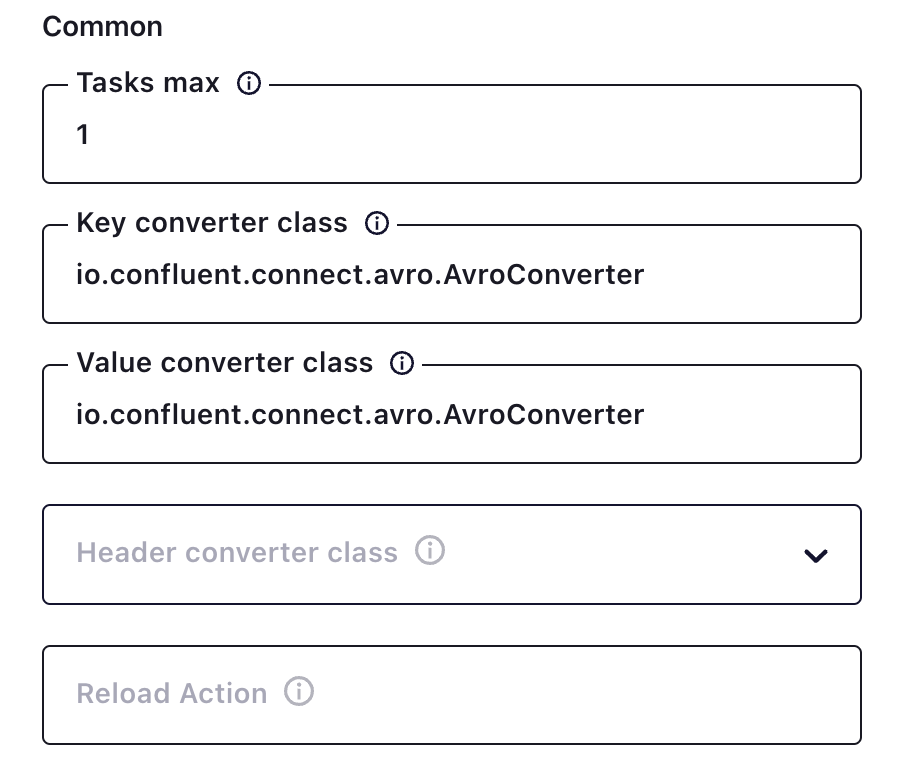
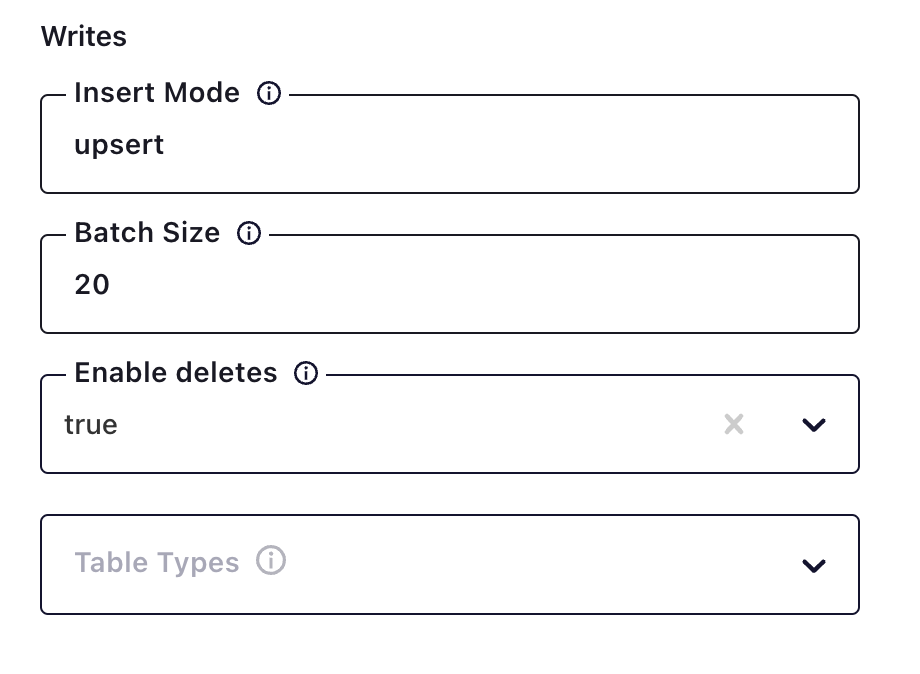
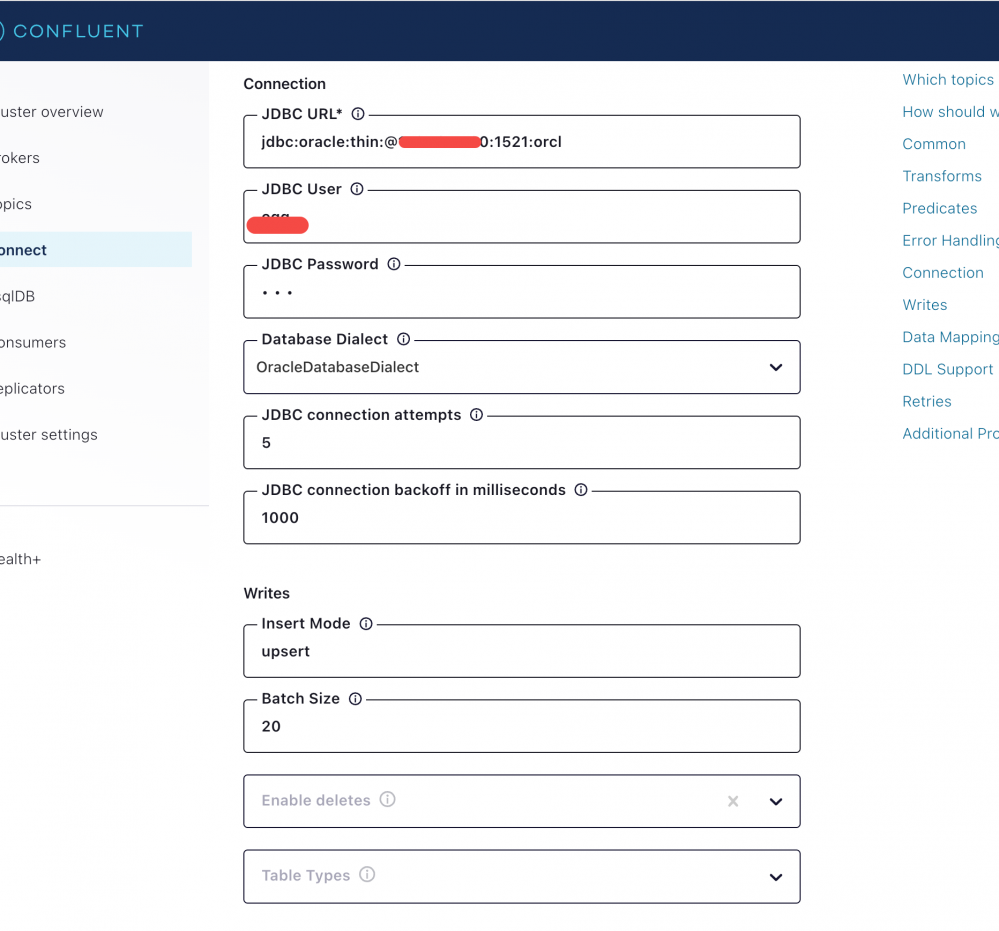
需要特别注意 Insert Mode 需要选择 upsert,它可以支持 update 和 delete,通过报错再次编辑的方式将 Enable deletes 修改为 true,以便支持 delete DML
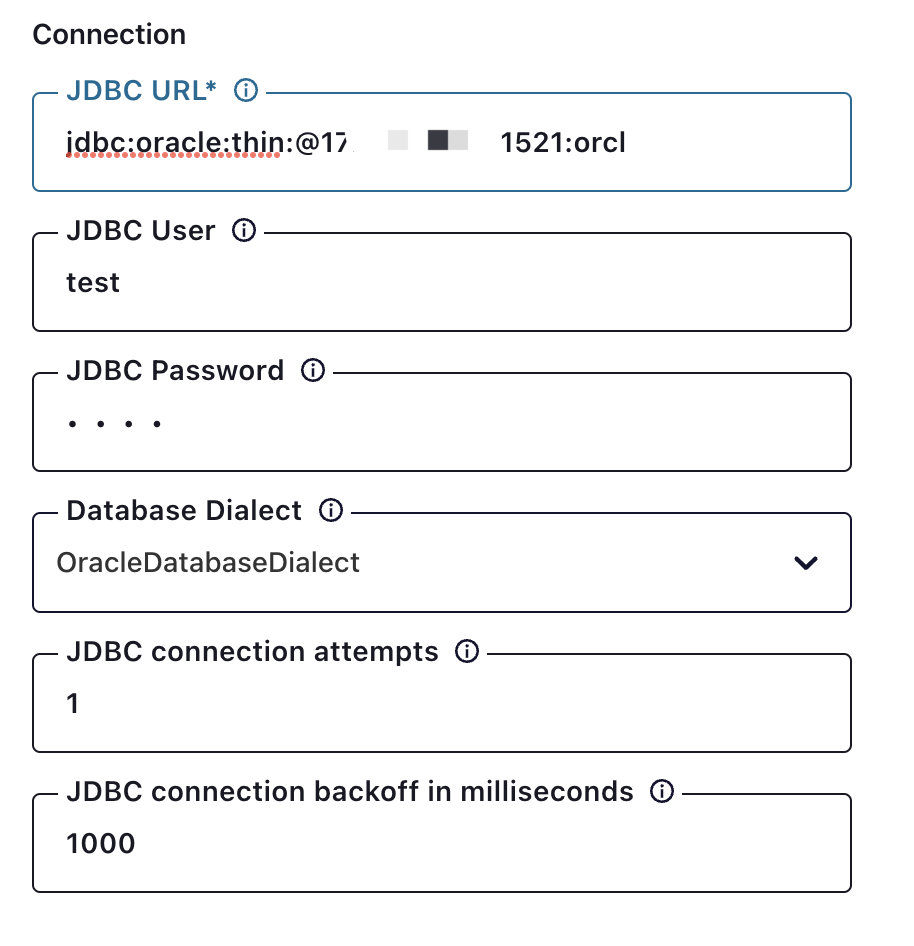
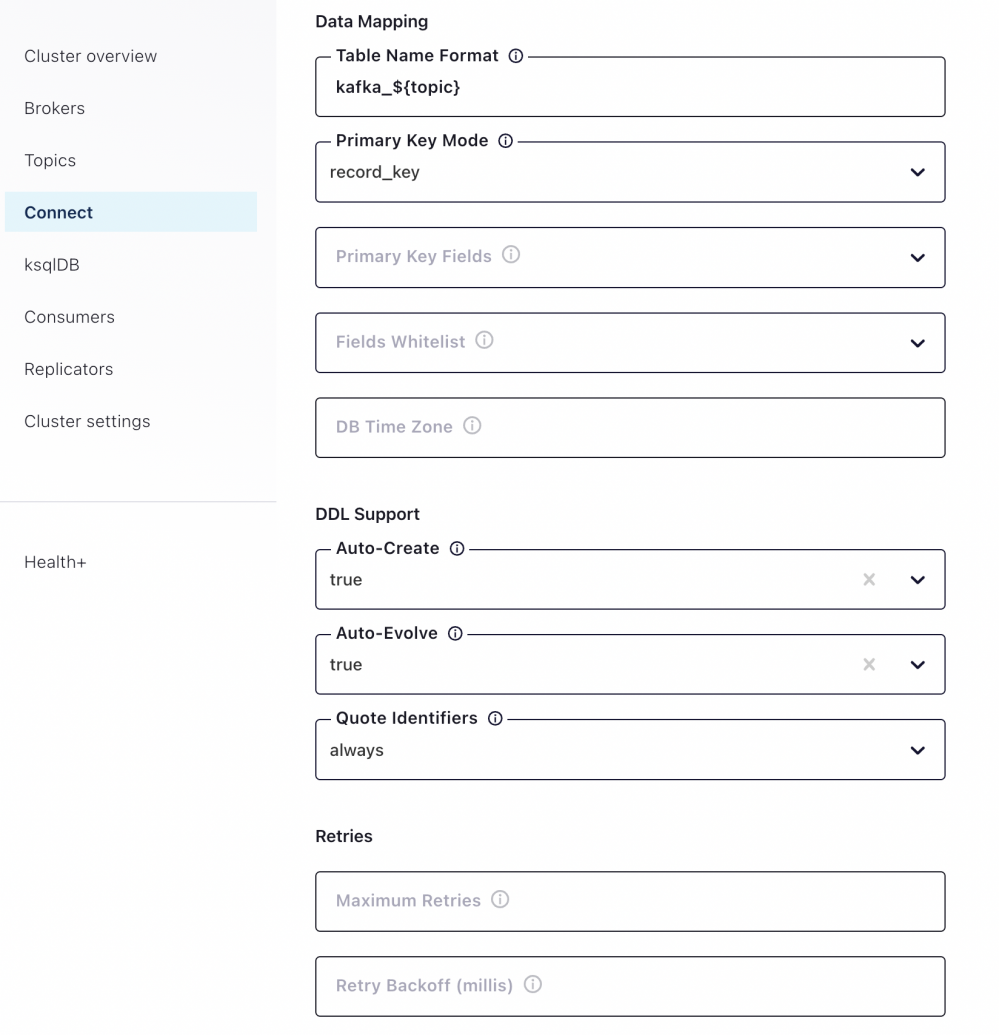
此处 Table Name Format 配置效果会将tidb 中 test.t9 写入到 *** 的 kafka_tidb_test_t9 中国, Primary Key Mode 选择 record_key 以便支持 delete 操作
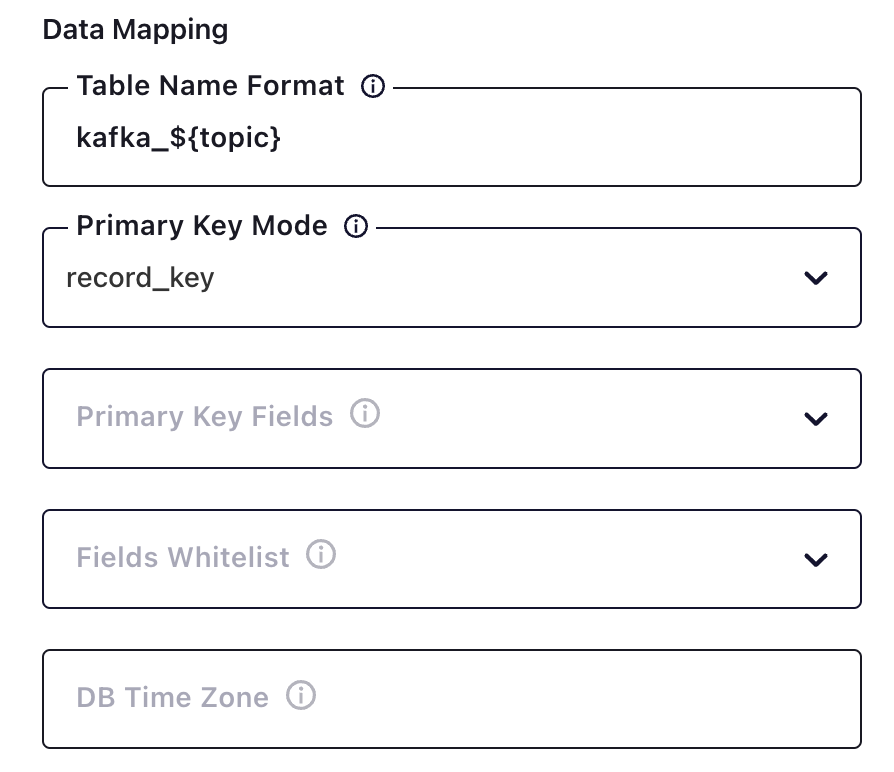
按下图配置支持自动创建 Table;自动 DDL 落地:目前验证支持 add column ,不支持 Drop Column,不支持 Rename Column; Quote Identifiers 需要设置为 always 它会在创建表时给表名添加双引号,否则 *** 会无法创建表

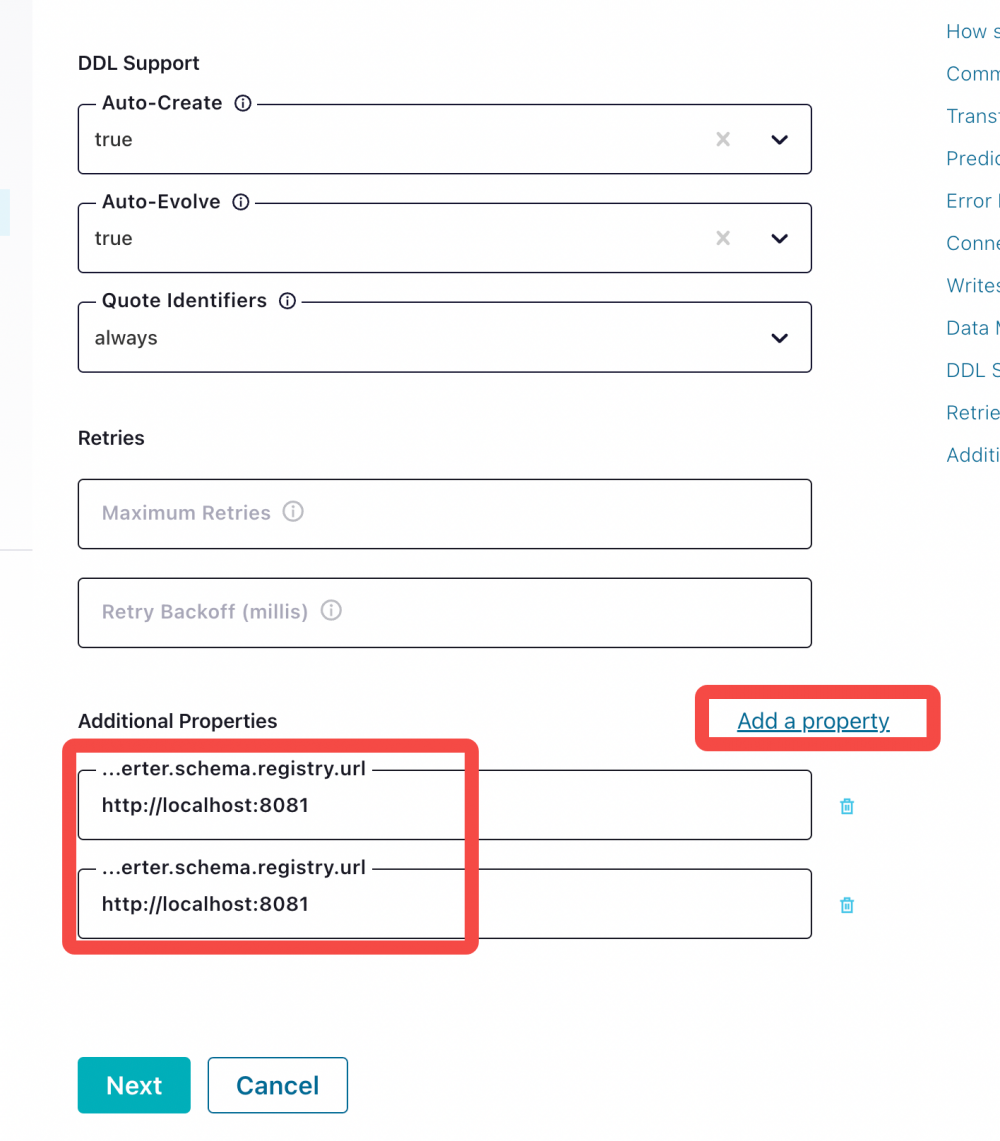
需要手工 Add Property,分别输入 key 为value.converter.schema.registry.url和key.converter.schema.registry.url ,然后为 key 添加对应的Value。

点击 Next ,检查配置是否正确,最终启动任务实现实时同步数据。可以在配置检查页面与以下配置文件进行对比。
{ "name": "JdbcSinkConnectorConnector_2", "config": { "value.converter.schema.registry.url": "http://localhost:8081", "key.converter.schema.registry.url": "http://localhost:8081", "name": "JdbcSinkConnectorConnector_2", "connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector", "tasks.max": "1", "key.converter": "io.confluent.connect.avro.AvroConverter", "value.converter": "io.confluent.connect.avro.AvroConverter", "topics.regex": "tidb_.*", "connection.url": "jdbc:***:thin:@172.1.1.1:1521:orcl", "connection.user": "test", "connection.password": "****", "dialect.name": "***DatabaseDialect", "connection.attempts": "1", "connection.backoff.ms": "1000", "insert.mode": "upsert", "batch.size": "20", "delete.enabled": "true", "table.name.format": "kafka_${topic}", "pk.mode": "record_key", "auto.create": "true", "auto.evolve": "true", "quote.sql.identifiers": "always", "max.retries": "1", "retry.backoff.ms": "1000" } }启动任务后可以在页面查看任务运行状态,如果失败则可以通过以下命令查看日志排查问题
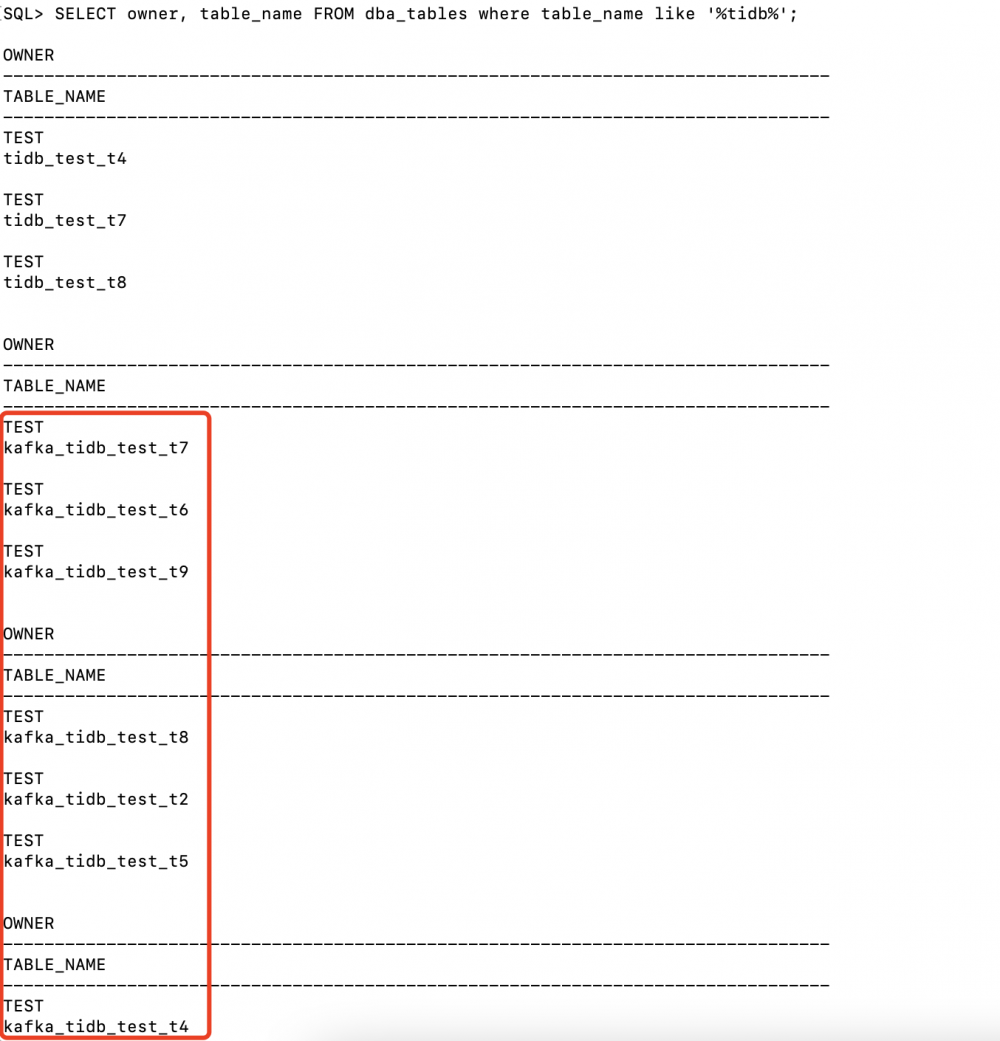
滚动查看日志 confluent local services connect log -f 查看全量日志 confluent local services connect log登陆 *** 数据库,可以看到 TiDB 中所有表已经自动在 *** 中映射创建。
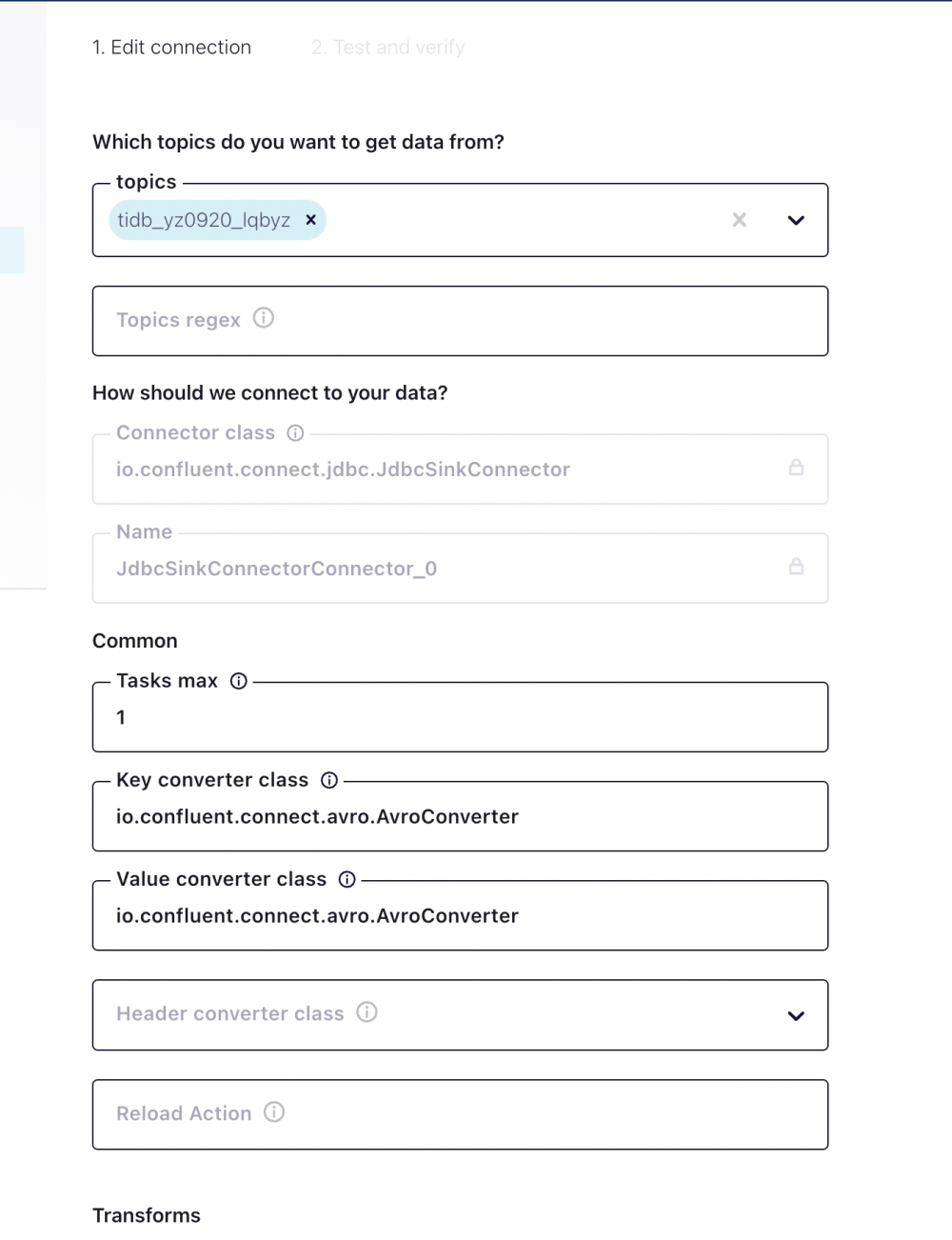
配置文件json
{ "name": "JdbcSinkConnectorConnector_0", "config": { "value.converter.schema.registry.url": "http://localhost:8081", "key.converter.schema.registry.url": "http://localhost:8081", "name": "JdbcSinkConnectorConnector_0", "connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector", "tasks.max": "1", "key.converter": "io.confluent.connect.avro.AvroConverter", "value.converter": "io.confluent.connect.avro.AvroConverter", "topics": "tidb_yz0920_lqbyz", "connection.url": "jdbc:***:thin:@172.16.11.60:1521:orcl", "connection.user": "ogg", "connection.password": "***", "dialect.name": "***DatabaseDialect", "connection.attempts": "5", "connection.backoff.ms": "1000", "insert.mode": "upsert", "batch.size": "20", "table.name.format": "kafka_${topic}", "pk.mode": "record_key", "auto.create": "true", "auto.evolve": "true", "quote.sql.identifiers": "always" } } Launch版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

