

黄东旭解析 TiDB 的核心优势
1753
2023-07-06
本文关于(如何使用TTL(Time to Live)定期删除过期数据-平凯星辰)。
Time to Live (TTL) 提供了行级别的生命周期控制策略。通过为表设置 TTL 属性,TiDB 可以周期性地自动检查并清理表中的过期数据。此功能在一些场景可以有效节省存储空间、提升性能。
TTL 常见的使用场景:
定期删除验证码、短网址记录
定期删除不需要的历史订单
自动删除计算的中间结果
TTL 设计的目标是在不影响在线读写负载的前提下,帮助用户周期性且及时地清理不需要的数据。TTL 会以表为单位,并发地分发不同的任务到不同的 TiDB Server 节点上,进行并行删除处理。TTL 并不保证所有过期数据立即被删除,也就是说即使数据过期了,客户端仍然有可能在这之后的一段时间内读到过期的数据,直到其真正的被后台处理任务删除。
你可以通过 CREATE TABLE 或 ALTER TABLE 语句来配置表的 TTL 功能。
创建一个具有 TTL 属性的表:
CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP) TTL = `created_at` + INTERVAL 3 MONTH;
上面的例子创建了一张表 t1,并指定了 created_at 为 TTL 的时间列,表示数据的创建时间。同时,它还通过 INTERVAL 3 MONTH 设置了表中行的最长存活时间为 3 个月。超过了此时长的过期数据会在之后被删除。
设置 TTL_ENABLE 属性来开启或关闭清理过期数据的功能:
CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP) TTL = `created_at` + INTERVAL 3 MONTH TTL_ENABLE = 'OFF';
如果 TTL_ENABLE 被设置成了 OFF,则即使设置了其他 TTL 选项,当前表也不会自动清理过期数据。对于一个设置了 TTL 属性的表,TTL_ENABLE 在缺省条件下默认为 ON。
为了与 MySQL 兼容,你也可以使用注释语法来设置 TTL:
CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP) /*T![ttl] TTL = `created_at` + INTERVAL 3 MONTH TTL_ENABLE = 'OFF'*/;
在 TiDB 环境中,使用表的 TTL 属性和注释语法来配置 TTL 是等价的。在 MySQL 环境中,会自动忽略注释中的内容,并创建普通的表。
修改表的 TTL 属性:
ALTER TABLE t1 TTL = `created_at` + INTERVAL 1 MONTH;
上面的语句既支持修改已配置 TTL 属性的表,也支持为一张非 TTL 的表添加 TTL 属性。
单独修改 TTL 表的 TTL_ENABLE 值:
ALTER TABLE t1 TTL_ENABLE = 'OFF';
清除一张表的所有 TTL 属性:
ALTER TABLE t1 REMOVE TTL;
TTL 可以和数据类型的默认值一起使用。以下是两种常见的用法示例:
使用 DEFAULT CURRENT_TIMESTAMP 来指定某一列的默认值为该行的创建时间,并用这一列作为 TTL 的时间列,创建时间超过 3 个月的数据将被标记为过期:
CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP) TTL = `created_at` + INTERVAL 3 MONTH;
指定某一列的默认值为该行的创建时间或更新时间,并用这一列作为 TTL 的时间列,创建时间或更新时间超过 3 个月的数据将被标记为过期:
CREATE TABLE t1 ( id int PRIMARY KEY, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP) TTL = `created_at` + INTERVAL 3 MONTH;
TTL 可以和生成列一起使用,用来表达更加复杂的过期规则。例如:
CREATE TABLE message ( id int PRIMARY KEY, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, image bool, expire_at TIMESTAMP AS (IF(image, created_at + INTERVAL 5 DAY, created_at + INTERVAL 30 DAY ))) TTL = `expire_at` + INTERVAL 0 DAY;
上述语句的消息以 expire_at 列来作为过期时间,并按照消息类型来设定。如果是图片,则 5 天后过期,不然就 30 天后过期。
TTL 还可以和 JSON 类型 一起使用。例如:
CREATE TABLE orders ( id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, order_info JSON, created_at DATE AS (JSON_EXTRACT(order_info, '$.created_at')) VIRTUAL) TTL = `created_at` + INTERVAL 3 month;
对于每张设置了 TTL 属性的表,TiDB 内部会定期调度后台任务来清理过期的数据。你可以通过给表设置 TTL_JOB_INTERVAL 属性来自定义任务的执行周期,比如通过下面的语句将后台清理任务设置为每 24 小时执行一次:
ALTER TABLE orders TTL_JOB_INTERVAL = '24h';
TTL_JOB_INTERVAL 的默认值是 1h。
在执行 TTL 任务时,TiDB 会基于 Region 的数量将表拆分为最多 64 个子任务。这些子任务会被分发到不同的 TiDB 节点中执行。你可以通过设置系统变量 tidb_ttl_running_tasks 来限制整个集群中同时执行的 TTL 子任务数量。然而,并非所有表的 TTL 任务都可以被拆分为子任务。请参考使用限制以了解哪些表的 TTL 任务不能被拆分平凯星辰。
如果想禁止 TTL 任务的执行,除了可以设置表属性 TTL_ENABLE='OFF' 外,也可以通过设置全局变量 tidb_ttl_job_enable 关闭整个集群的 TTL 任务的执行。
SET @@global.tidb_ttl_job_enable = OFF;
在某些场景下,你可能希望只允许在每天的某个时间段内调度后台的 TTL 任务,此时可以设置全局变量 tidb_ttl_job_schedule_window_start_time 和 tidb_ttl_job_schedule_window_end_time 来指定时间窗口,比如:
SET @@global.tidb_ttl_job_schedule_window_start_time = '01:00 +0000';SET @@global.tidb_ttl_job_schedule_window_end_time = '05:00 +0000';
上述语句只允许在 UTC 时间的凌晨 1 点到 5 点调度 TTL 任务。默认情况下的时间窗口设置为 00:00 +0000 到 23:59 +0000,即允许所有时段的任务调度。
TiDB 会定时采集 TTL 的运行时信息,并在 Grafana 中提供了相关指标的可视化图表。你可以在 TiDB -> TTL 的面板下看到这些信息。指标详情见 TiDB 重要监控指标详解 中的 TTL 部分平凯星辰。
同时,可以通过以下三个系统表获得 TTL 任务执行的更多信息:
mysql.tidb_ttl_table_status 表中包含了所有 TTL 表的上一次执行与正在执行的 TTL 任务的信息。以其中一行为例:
MySQL [(none)]> SELECT * FROM mysql.tidb_ttl_table_status LIMIT 1\G;*************************** 1. row *************************** table_id: 85 parent_table_id: 85 table_statistics: NULL last_job_id: 0b4a6d50-3041-4664-9516-5525ee6d9f90 last_job_start_time: 2023-02-15 20:43:46 last_job_finish_time: 2023-02-15 20:44:46 last_job_ttl_expire: 2023-02-15 19:43:46 last_job_summary: {"total_rows":4369519,"success_rows":4369519,"error_rows":0,"total_scan_task":64,"scheduled_scan_task":64,"finished_scan_task":64} current_job_id: NULL current_job_owner_id: NULL current_job_owner_addr: NULL current_job_owner_hb_time: NULL current_job_start_time: NULL current_job_ttl_expire: NULL current_job_state: NULL current_job_status: NULLcurrent_job_status_update_time: NULL1 row in set (0.040 sec)其中列 table_id 为分区表 ID,而 parent_table_id 为表的 ID,与 infomation_schema.tables 表中的 ID 对应。如果表不是分区表,则 table_id 与 parent_table_id 总是相等。
列 {last, current}_job_{start_time, finish_time, ttl_expire} 分别描述了过去和当前 TTL 任务的开始时间、结束时间和过期时间。last_job_summary 列描述了上一次 TTL 任务的执行情况,包括总行数、成功行数、失败行数。
mysql.tidb_ttl_task 表中包含了正在执行的 TTL 子任务。单个 TTL 任务会被拆分为多个子任务,该表中记录了正在执行的这些子任务的信息。
mysql.tidb_ttl_job_history 表中记录了 TTL 任务的执行历史。TTL 任务的历史记录将被保存 90 天。以一行为例:
MySQL [(none)]> SELECT * FROM mysql.tidb_ttl_job_history LIMIT 1\G;*************************** 1. row *************************** job_id: f221620c-ab84-4a28-9d24-b47ca2b5a301 table_id: 85 parent_table_id: 85 table_schema: test_schema table_name: TestTable partition_name: NULL create_time: 2023-02-15 17:43:46 finish_time: 2023-02-15 17:45:46 ttl_expire: 2023-02-15 16:43:46 summary_text: {"total_rows":9588419,"success_rows":9588419,"error_rows":0,"total_scan_task":63,"scheduled_scan_task":63,"finished_scan_task":63} expired_rows: 9588419 deleted_rows: 9588419error_delete_rows: 0 status: finished其中列 table_id 为分区表 ID,而 parent_table_id 为表的 ID,与 infomation_schema.tables 表中的 ID 对应。table_schema、table_name、partition_name 分别对应表示数据库、表名、分区名。create_time、finish_time、ttl_expire 分别表示 TTL 任务的创建时间、结束时间和过期时间。expired_rows 与 deleted_rows 表示过期行数与成功删除的行数。
TTL 功能能够与 TiDB 的迁移、备份、恢复工具一同使用。
| 工具名称 | 最低兼容版本 | 说明 |
Backup & Restore (BR) | v6.6.0 | 恢复时会自动将表的 |
TiDB Lightning | v6.6.0 | 导入后如果表中有 TTL 属性,会自动将表的 |
TiCDC | v7.0.0 | 上游的 TTL 删除将会同步至下游。因此,为了防止重复删除,下游表的 |
| 特性名称 | 说明 |
|
|
|
|
|
|
目前,TTL 特性具有以下限制:
不允许在临时表上设置 TTL 属性,包括本地临时表和全局临时表。
具有 TTL 属性的表不支持作为外键约束的主表被其他表引用。
不保证所有过期数据立即被删除,过期数据被删除的时间取决于后台清理任务的调度周期和调度窗口。
对于使用聚簇索引的表,如果主键的类型不是整数类型或二进制字符串类型,TTL 任务将无法被拆分成多个子任务。这将导致 TTL 任务只能在一个 TiDB 节点上按顺序执行。如果表中的数据量较大,TTL 任务的执行可能会变得缓慢。
TTL 无法在 TiDB Serverless 集群上使用。
如何判断删除的速度是否够快,能够保持数据总量相对稳定?
在 Grafana TiDB 面板中,监控项 TTL Insert Rows Per Hour 记录了前一小时总共插入数据的数量。相应的 TTL Delete Rows Per Hour 记录了前一小时 TTL 任务总共删除的数据总量。如果 TTL Insert Rows Per Hour 长期高于 TTL Delete Rows Per Hour, 说明插入的速度高于删除的速度,数据总量将会上升。例如:

值得注意的是,由于 TTL 并不能保证数据立即被删除,且当前插入的数据将会在将来的 TTL 任务中才会被删除,哪怕短时间内 TTL 删除的速度低于插入的速度,也不能说明 TTL 的效率一定过慢。需要结合具体情况分析。
如何判断 TTL 任务的瓶颈在扫描还是删除?
观察面板中 TTL Scan Worker Time By Phase 与 TTL Delete Worker Time By Phase 监控项。如果 scan worker 处于 dispatch 状态的时间有很大占比,且 delete worker 很少处于 idle 状态,那么说明 scan worker 在等待 delete worker 完成删除工作,如果此时集群资源仍然较为宽松,可以考虑提高 tidb_ttl_delete_worker_count 来提高删除的 worker 数量。例如:
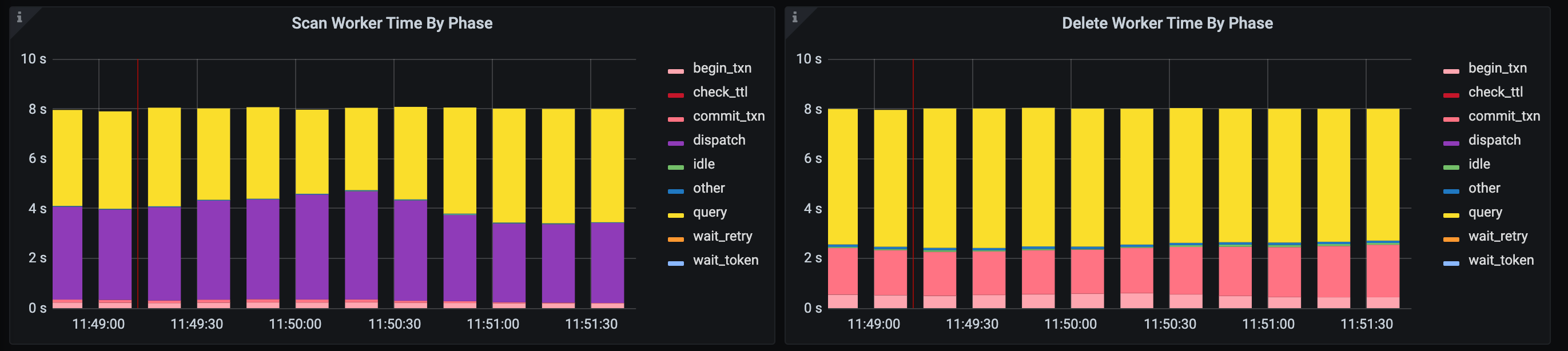
与之相对,如果 scan worker 很少处于 dispatch 的状态,且 delete worker 长期处于 idle 阶段,那么说明 delete worker 闲置,且 scan worker 较为忙碌。例如:

TTL 任务中扫描与删除的占比与机器配置、数据分布都有关系,所以每一时刻的数据只能代表正在执行的 TTL Job 的情况。用户可以通过查询表 mysql.tidb_ttl_job_history 来判断某一时刻运行的 TTL Job 对应哪一张表。
如何合理配置 tidb_ttl_scan_worker_count 和 tidb_ttl_delete_worker_count?
可以参考问题 "如何判断 TTL 任务的瓶颈在扫描还是删除?" 来考虑提升 tidb_ttl_scan_worker_count 还是 tidb_ttl_delete_worker_count。
如果 TiKV 节点数量较多,提升 tidb_ttl_scan_worker_count 能够使 TTL 任务负载更加均匀。
由于过高的 TTL worker 数量将会造成较大的压力,所以需要综合观察 TiDB 的 CPU 水平与 TiKV 的磁盘与 CPU 使用量。根据不同场景和需求(需要尽量加速 TTL,或是需要减少 TTL 对其他请求的影响)来调整 tidb_ttl_scan_worker_count 与 tidb_ttl_delete_worker_count,从而提升 TTL 扫描和删除数据的速度,或降低 TTL 任务对性能的影响。
上述就是小编为大家整理的(如何使用TTL(Time to Live)定期删除过期数据-平凯星辰)
***
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

