

黄东旭解析 TiDB 的核心优势
725
2023-03-31
TiFlash 初期存在一个棘手的问题:对于复杂的小查询,无论增加多少并发,TiFlash 的整机 CPU 使用率都远远不能打满。如下图:
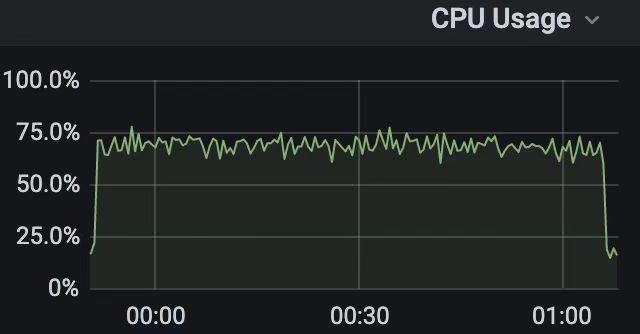
对 TiFlash 和问题本身经过一段时间的了解后,认为方向应该在“公共组件”(全局锁、底层存储、上层服务等)上。在这个方向上做“地毯式”排查后, 终于定位到问题的一个重要原因:高并发下频繁的线程创建和释放, 这会引发线程在创建/释放过程出现排队和阻塞现象。
由于 TiFlash 的工作模式依赖于启动大量临时新线程去做一些局部计算或者其他的事情, 大量线程创建/释放过程出现了排队和阻塞现象,导致应用的计算工作也被阻塞了。而且并发越多, 这个问题越严重, 所以 CPU 使用率不再随着并发增加而增加。 具体的排查过程, 因为篇幅有限, 本篇就不多赘述了。首先我们可以构造个简单实验来复现这个问题:
首先定义三种工作模式: wait、 work 、 workOnNewThread
wait: while 循环,等待 condition_variable
work: while 循环,每次 memcpy20次(每次 memcpycopy 1000000 bytes)。
workOnNewThread: while循环,每次申请新的 thread,新 thread 内 memcpy20次, join等待线程结束,重复这个过程。
接下来按不同的工作模式组合去做实验。
实验 1:40 个 work 线程
实验 2:1000 个 wait 线程, 40 个 work 线程
实验 3:40 个 workOnNewThread 线程
实验 4:120 个 workOnNewThread 线程
实验 5:500 个 workOnNewThread 线程
各实验 CPU 使用率如下:
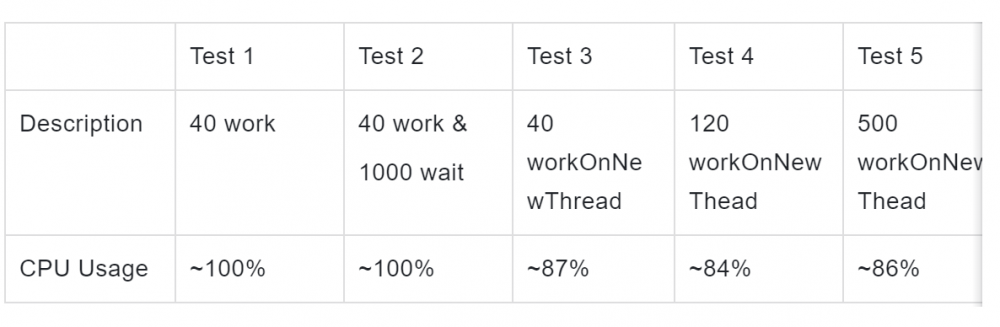
实验 1 和 2 表明, 即使实验 2 比实验 1 多了 1000 个 wait 线程,并不会因为 wait 线程数非常多而导致 CPU 打不满。过多的 wait 线程数并不会让 CPU 打不满。从原因上来讲,wait 类型的线程不参与调度,后面会讲到。另外,linux 采用的是 cfs 调度器,时间复杂度是 O(lgn),所以理论上大规模可调度线程数目也并不会给调度增加明显的压力。
实验 3、4、5 表明, 如果大量工作线程的工作模式是频繁申请和释放线程, 可以导致cpu打不满的情况。
接下来带大家一起分析下, 为什么线程的频繁创建和释放会带来排队和阻塞现象,代价如此之高?
使用 GDB 查看线程的频繁创建和释放场景下的程序,可以看到线程创建和释放过程被 lll_lock_wait_private的锁阻塞掉。如图:
#0 _lll_lock_wait_private () at ../nptl/sysdeps/unix/sysv/linux/x86_64/lowlevellock.S:95#1 0x00007fbc55f60d80 in _L_lock_3443 () from /lib64/libpthread.so.0#2 0x00007fbc55f60200 in get_cached_stack (memp=<synthetic pointer>, sizep=<synthetic pointer>) at allocatestack.c:175#3 allocate_stack (stack=<synthetic pointer>, pdp=<synthetic pointer>, attr=0x7fbc56173400 <__default_pthread_attr>) at allocatestack.c:474#4 __pthread_create_2_1 (newthread=0x7fb8f6c234a8, attr=0x0, start_routine=0x88835a0 <std::execute_native_thread_routine(void*)>, arg=0x7fbb8bd10cc0) at pthread_create.c:447#5 0x0000000008883865 in __gthread_create (__args=<optimized out> __func=0x88835a0 <std::execute_native_thread_routine(void*)>, __threadid=_threadid@entry=0x7fb8f6c234a8) at /root/XXX/gcc-7.3.0/x86_64-pc-linux-gnu/libstdc++-v3/include/x86_64-pc-linux-gnu/b...#6 std::thread::_M_start_thread (this=this@entry=0x7fb8f6c234a8,state=...) at ../../../../-/libstdc++-v3/src/c++11/thread.cc:163
#0 _lll_lock_wait_private () at ../nptl/sysdeps/unix/sysv/linux/x86_64/lowlevellock.S:95#1 0x00007fbc55f60e59 in _L_lock_4600 () from /lib64/libpthread.so.0#2 0x00007fbc55f6089f in allocate_stack (stack=<synthetic pointer>, pdp=<synthetic pointer> attr=0x7fbc56173400 <__default_pthread_attr>) at allocatestack.c:552#3 __pthread_create_2_1 (newthread=0x7fb5f1a5e8b0, attr=0x0, start_routine=0x88835a0 <std::execute_native_thread_routine(void*)>, arg=0x7fbb8bcd6500) at pthread_create.c:447#4 0x0000000008883865 in __gthread_create (__args=<optimized out>, __func=0x88835a0 <std::execute_native_thread_routine(void*)>, __threadid=__threadid@entry=0x7fb5f1a5e8b0) at /root/XXX/gcc-7.3.0/x86_64-pc-linux-gnu/libstdc++-v3/include/...#5 std::thread::_M_start_thread (this=this@entry=0x7fb5f1a5e8b0, state=...) at ../../../.././libstdc++-v3/src/c++11/thread.cc:163
#0 __lll_lock_wait_private () at ../nptl/sysdeps/unix/sysv/linux/x86_64/lowlevellock.S:95#1 0x00007fbc55f60b71 in _L_lock_244 () from /lib64/libpthread.so.0#2 0x00007fbc55f5ef3c in _deallocate_stack (pd=0x7fbc56173320 <stack_cache_lock>, pd@entry=0x7fb378912700) at allocatestack.c:704#3 0x00007fbc55f60109 in __free_tcb (pd=pd@entry=0x7fb378912700) at pthread_create.c:223#4 0x00007fbc55f61053 in pthread_join (threadid=140408798652160, thread_return=0x0) at pthread_join.c:111#5 0x0000000008883803 in __gthread_join (__value_ptr=0x0, __threadid=<optimized out>) at /root/XXX/gcc-7.3.0/x86_64-pc-linux-gnu/libstdc++-v3/include/x86_64-pc-linux-gnu/bits/gthr-default.h:668#6 std::thread::join (this=this@entry=0x7fbbc2005668) at ../../../.././libstdc++-v3/src/c++11/thread.cc:136
从图中堆栈可以看到,线程创建时会调用allocate_stack和 __deallocate_stack,而线程释放时会调用 __deallocate_stack,这几个函数会因为触发了名为 lll_lock_wait_private的锁争抢而发生阻塞。
为了解释这个情况,需要对 thread 的创建释放过程进行了解。
我们日常用到的线程,是通过 NPTL 实现的 pthread。NPTL(native posix thread library), 俗称原生 pthread 库,本身集成在 glibc 里面。在分析了 glibc 的相关源码后,可以了解到 pthread 创建和释放的工作过程。
线程创建工作会给线程分配 stack,析构工作会释放 stack,这期间会用到stack_used和stack_cache两个链表:stack_used维护的是正在被线程使用 stack,而stack_cache维护的是的之前线程释放后回收可利用的 stack。线程申请 stack 时,并不是直接去申请新的 stack,而是先尝试从stack_cache里获取。
__lll_lock_wait_private是private形态的__lll_lock_wait,实际是一种基于 futex 实现的互斥锁,后面会讲到,private 是指在这个锁只在进程内部使用,而不会跨进程。 这个锁争抢就是在线程调用allocate_stack(线程申请时)、deallocate_stack(线程释放时)过程中对这两个链表进行操作时发生的。
allocate_stack过程:
Returns a usable stack for a new thread either by allocating a new stack or reusing a cached stack of sufficient size.
ATTR must be non-NULL and point to a valid pthread_attr.
PDP must be non-NULL. */static intallocate_stack (const struct pthread_attr *attr, struct pthread **pdp,
ALLOCATE_STACK_PARMS)
{
... // do something
/* Get memory for the stack. */
if (__glibc_unlikely (attr->flags & ATTR_FLAG_STACKADDR))
{
... // do something
} else
{ // main branch
/* Allocate some anonymous memory. If possible use the cache. */
... // do something
/* Try to get a stack from the cache. */
reqsize = size;
pd = get_cached_stack (&size, &mem); /*
If get_cached_stack() succeed, it will use cached_stack
to do rest work. Otherwise, it will call mmap() to allocate a stack.
*/
if (pd == NULL) // if pd == NULL, get_cached_stack() failed
{
... // do something
mem = mmap (NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);
... // do something
/* Prepare to modify global data. */
lll_lock (stack_cache_lock, LLL_PRIVATE); // global lock
/* And add to the list of stacks in use. */
stack_list_add (&pd->list, &stack_used); lll_unlock (stack_cache_lock, LLL_PRIVATE);
... // do something
}
... //do something
}
... //do something
return 0;
}/* Get a stack frame from the cache. We have to match by size since
some blocks might be too small or far too large. */static struct pthread *get_cached_stack (size_t *sizep, void **memp)
{ size_t size = *sizep; struct pthread *result = NULL; list_t *entry; lll_lock (stack_cache_lock, LLL_PRIVATE); // global lock
/* Search the cache for a matching entry. We search for the
smallest stack which has at least the required size. Note that
in normal situations the size of all allocated stacks is the
same. As the very least there are only a few different sizes.
Therefore this loop will exit early most of the time with an
exact match. */
list_for_each (entry, &stack_cache)
{
... // do something
}
... // do something
/* Dequeue the entry. */
stack_list_del (&result->list); /* And add to the list of stacks in use. */
stack_list_add (&result->list, &stack_used); /* And decrease the cache size. */
stack_cache_actsize -= result->stackblock_size; /* Release the lock early. */
lll_unlock (stack_cache_lock, LLL_PRIVATE);
... // do something
return result;
}结合堆栈和源码可知,pthread_create最开始会调用allocate_stack来进行线程堆栈的分配。具体过程如上图: 首先检查用户是否自己提供了 stack 空间,如果是,那么直接用用户提供的空间进行分配。不过这种情况很少见。默认情况下,用户是不提供的,而是系统自己去分配。这种情况下会先调用 get_cached_stack,尝试从已经分配过的 stack 列表中重新利用。如果获取 stack 失败,那么会调用 syscall mmap进行 stack 的分配,获取 stack 后,会尝试获取全局锁lll_lock将 stack 添加到stack_used列表中。这个过程中, get_cached_stack内部也会尝试获取相同的全局锁lll_lock,首先扫描stack_cache列表,将可用的 stack 找到,然后将该stack 从stack_cache列表中删除,再加入到stack_used列表中。
deallocate_stack过程:
void
internal_function
__deallocate_stack (struct pthread *pd)
{
lll_lock (stack_cache_lock, LLL_PRIVATE); //global lock
/* Remove the thread from the list of threads with user defined
stacks. */
stack_list_del (&pd->list);
/* Not much to do. Just free the mmap()ed memory. Note that we do
not reset the 'used' flag in the 'tid' field. This is done by
the kernel. If no thread has been created yet this field is
still zero. */
if (__glibc_likely (! pd->user_stack))
(void) queue_stack (pd);
else /* Free the memory associated with the ELF TLS. */
_dl_deallocate_tls (TLS_TPADJ (pd), false);
lll_unlock (stack_cache_lock, LLL_PRIVATE);
}/* Add a stack frame which is not used anymore to the stack. Must be
called with the cache lock held. */static inline void__attribute ((always_inline))queue_stack (struct pthread *stack)
{ /* We unconditionally add the stack to the list. The memory may
still be in use but it will not be reused until the kernel marks
the stack as not used anymore. */
stack_list_add (&stack->list, &stack_cache);
stack_cache_actsize += stack->stackblock_size; if (__glibc_unlikely (stack_cache_actsize > stack_cache_maxsize)) //if stack_cache is full, release some stacks
__free_stacks (stack_cache_maxsize);
}/* Free stacks until cache size is lower than LIMIT. */void__free_stacks (size_t limit)
{ /* We reduce the size of the cache. Remove the last entries until
the size is below the limit. */
list_t *entry; list_t *prev; /* Search from the end of the list. */
list_for_each_prev_safe (entry, prev, &stack_cache)
{ struct pthread *curr;
curr = list_entry (entry, struct pthread, list); if (FREE_P (curr))
{
... // do something
/* Remove this block. This should never fail. If it does
something is really wrong. */
if (munmap (curr->stackblock, curr->stackblock_size) != 0) abort (); /* Maybe we have freed enough. */
if (stack_cache_actsize <= limit) break;
}
}
}//file path: nptl/allocatestack.c/* Maximum size in kB of cache. */static size_t stack_cache_maxsize = 40 * 1024 * 1024; /* 40MiBi by default. */static size_t stack_cache_actsize;
结合堆栈和源码可知,线程在结束时,会调用__free_tcb来先将线程的 TCB(Thread Control Block,线程的元数据)释放,然后调用deallocate_stack将 stack 回收。这个过程中,主要的瓶颈点在deallocate_stack上。deallocate_stack会尝试持有跟allocate_stack里面相同的lll_lock全局锁,将stack从stack_used列表中删除。然后判断 stack 是否是系统分配的,如果是,那么将其加入到stack_cache列表中。加入后,会检查stack_cache列表的大小是否超出阈值stack_cache_maxsize,如果是,那么会调用__free_stacks函数释放一些 stack 直到小于阈值stack_cache_maxsize。值得注意的是,__free_stacks函数里面会调用syscall munmap来释放内存。对于阈值stack_cache_maxsize,如上图,从源码上看,它的默认值是 4010241024, 结合代码中的注释,似乎单位是 kB。但是后来实测后发现,这个注释是有问题,实际上stack_cache_maxsize的单位是 Byte,也就是默认 40MB。而 thread 默认 stack 大小一般为 810 MB,也就是说 glibc 默认情况下大概可以帮用户 cache 45 个线程 stack。
由此可见,线程在创建和释放过程中,都会抢同一把全局互斥锁lll_lock,从而在高并发线程创建/释放时,这些线程会发生排队、阻塞的情况。由于这个过程中同一时间只能一个线程在工作,假设线程创建/释放的代价是 c,那么可以大致推算出 n 个线程创建/释放的平均延迟 avg_rt = (1+2+…+n)c/n = n(n+1)/2c/n=(n+1)*c/2。也就是创建/释放的平均延迟随并发数线性增加。在 TiFlash 上对线程创建做打点监控后发现,40 个嵌套查询(max_threads=4,注:此为TiFlash的并发度参数)下,线程创建/释放的线程数规模达到了 3500 左右,线程创建平均延迟居然达到了 30ms! 这是延迟是非常恐怖的,线程创建/释放已经不像想象中那么“轻量”了。单次操作的延迟已经如此之高,对于像 TiFlash 这种嵌套型的线程创建场景,可想而知会更严重。
讲到这里,大家已经了解到线程创建和释放过程会尝试获取全局互斥锁而发生排队阻塞的行为, 不过可能还对lll_lock一头雾水。什么是lll_lock呢?
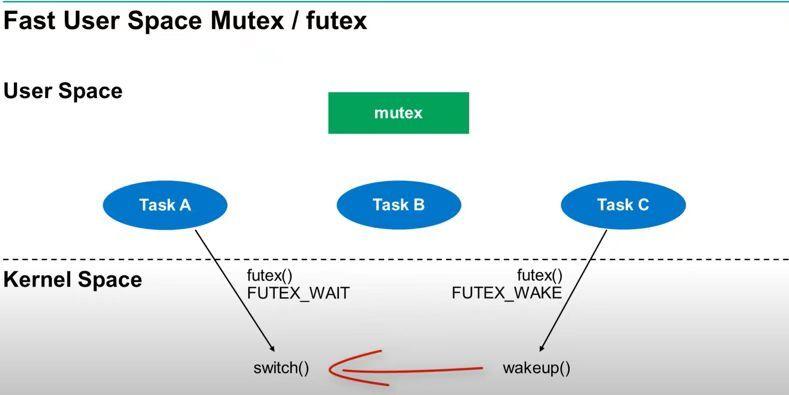
lll是 low level lock的缩写,俗称底层锁,实际是基于 Futex 实现的互斥锁。Futex,全称 fast userspace mutex,是一个非 vDSO 的system call。高版本 linux 的 mutex 也是基于 futex 实现的。futex 的设计思路认为大部分情况锁争抢是不会发生的,这时候可以直接在用户态完成锁操作。而当发生锁争抢时,lll_lock通过非vDSO 的系统调用 sys_futex(FUTEX_WAIT)陷入内核态等待被唤醒。成功抢到锁的线程,干完活后,通过lll_unlock来唤醒 val 个线程(val 一般设为1),lll_unlock实际通过非vDSO 的系统调用sys_futex(FUTEX_WAIT)来完成唤醒操作。
从上面对 lll_lock、futex 的原理中可以了解到,如果是非争抢情况下,这个操作是比较轻量的,也不会陷入内核态。但是在争抢情况下,不但发生了排队阻塞,还会触发用户态和内核态的切换,线程的创建/释放效率雪上加霜。内核态和用户态的切换之所以慢,主要因为非 vDSO 的系统调用。下面不妨讲讲系统调用的代价。
现代 linux 系统中,一般会将部分的 syscall 集合用 vDSO 的方式暴露给进程,进程以 vDSO 的方式对 syscall 进行调用其实是很高效的,因为不涉及到用户态和内核态的切换。 而非 vDSO 的 syscall 就不那么幸运了,不幸的是 Futex 就属于非 vDSO 类的。
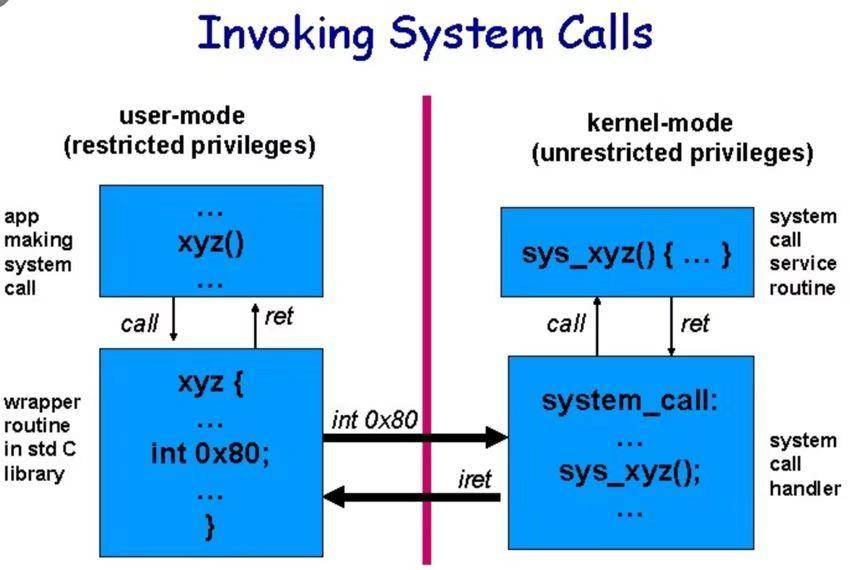
传统的 syscall 通过 int 0x80 中断的方式进行,CPU 把控制权交给 OS,OS 会检查传入的参数,例如SYS_gettimeofday,然后利根据寄存器中的系统调用号查找系统调用表,获得调用号对应的服务函数并执行比如: gettimeofday。中断会强制 CPU 保存中断前的执行状态,为了在中断结束后可以把状态恢复。除了中断本身, kernel 还会做更多的事情。Linux 被分为用户空间和内核空间,内核空间的权限等级最高,可以直接对硬件做操作。为了防止用户程序的恶意行为,用户应用无法直接访问内核空间,要想做用户态无法完成的工作,便需要 syscall 来间接完成,kernel 必须在用户和内核这两个内存段之间切换来完成这个操作。这种内存地址的切换,需要 CPU 寄存器内容的“大换血”,因为需要保存和恢复之前寄存器的现场。此外还要对用户传入的内容做额外的权限检查,所以对性能的冲击是比较大的。现代的 CPU 提供了 syscall 指令,因此高版本的 linux 实际通过 syscall 指令来代替原来的 int 0x80 中断方式,但是代价依然很高。
从之前 futex 介绍中讲到, mutex 实际也是基于 futex 实现的。同样都是基于 futex 实现,为啥线程创建/析构就会变慢呢?
通过修改 glibc 和 kernel 的源码,在里面加入 trace 代码, 定位到线程创建/析构在 futex 临界区内耗时主要是munmap这个 syscall 贡献的。之前的源码分析中讲到,当线程释放时,如果 stack_cache列表已经满了,会调用munmap来将 stack 释放掉。
munmap这个操作的耗时大概有几 us 甚至几十 us。几乎贡献了整个过程耗时的 90% 以上。又因为munmap是通过 futex 全局锁在完成的,导致这期间其他的线程创建/析构工作都必须阻塞。引发严重的性能降级。
所以,线程创建/析构慢的更深层原因是:线程析构时如果stack_cache满了,需要调用munmap来将 stack 释放,这个过程的 futex 临界区耗时过长!这样创建和析构在抢同一把 futex 锁的时候,都会发生阻塞现象。
可是同样都是操作内存,用于申请内存的 mmap 却非常快,基本不到 1us 就可以执行结束,为什么两者反差如此之大?接下来我们分析下 munmap为什么会这么慢。
首先简要讲下 munmap的工作过程:munmap会根据要释放的内存范围寻找对应的虚拟内存区VMA(virtual memory area),如果要释放的内存范围的首尾正好落在某个 VMA 的中间,那么需要对对应的 VMA 进行分裂。然后解映射 unmap、释放对应的 VMA、页表。并作废相关的 TLB。
通过在 kernel 的中加入的 trace 发现,耗时主要发生在tlb_flush_mmu中, 这个是驱逐TLB的过程。因为 munmap在释放内存后, 需要将过期失效的 TLB 作废掉, 所以会调用这个函数。
再深入下去,如果涉及的 TLB 在多个 CPU 核上都存在,tlb_flush_mmu会调用smp_call_function_many来在这些核上都做一遍 flush TLB,并且以同步的方式等待该过程执行完毕。单核 Flush TLB 的操作通过单核中断完成, 多核 Flush TLB 需要通过核间中断 IPI 来完成。
通过 trace 定位, 耗时主要是 IPI 贡献的, 光是 IPI 通讯的耗时就有几 us 甚至几十 us, 而flush TLB 本身却不到 1us。
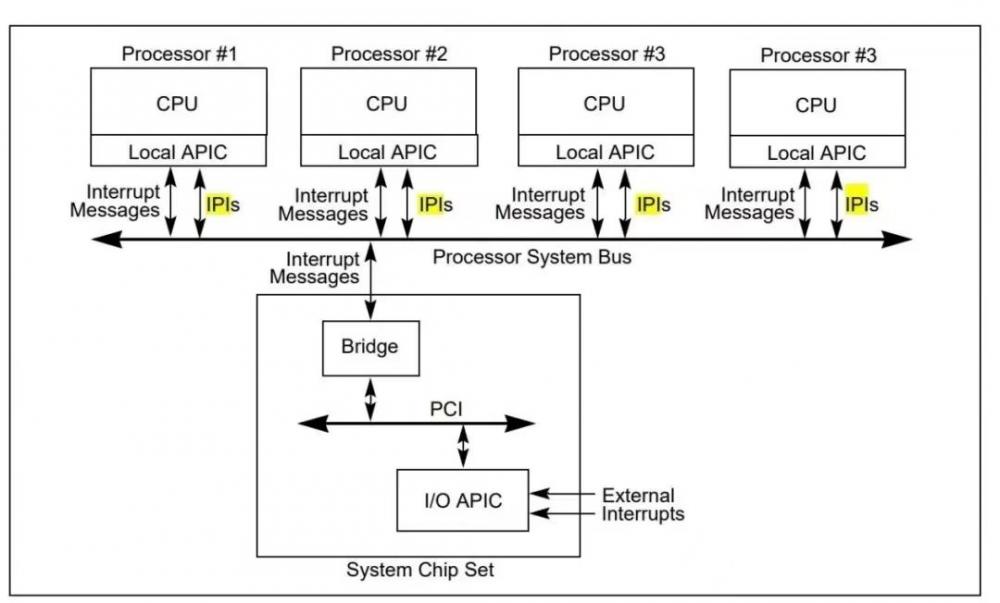
IPI 的具体工作方式如上图,多个 CPU 核心通过系统总线 System Bus 进行 IPI 消息的通讯, 当一个 CPU 核需要在多个 CPU 核心上做 IPI 工作时,该核心会发送 IPI 请求到 System Bus 并等待其他核心全部完成 IPI 操作,相关的 CPU 核心上收到 IPI 请求后处理自己的 Interrupt 任务,完成后通过 System Bus 通知发起方。因为这个过程需要通过 CPU 外部的 System Bus 来完成,并且发起方在发送 IPI 到等待其他核心完成中断操作的过程中只能傻等着,所以 overhead 非常高(几 us 甚至更高)。
翻看别人的研究成果, 更加验证了 IPI 是很重的操作。根据 18 年发表的论文<<Latr: Lazy Translation Coherence>>的研究表明,
“an IPI takes up to 6.6 µs for 120 cores with 8 sockets and 2.7 µs for 16 cores with 2 sockets.”
也就是说一次 IPI 操作的 overhead 大概就是 us 级别的。
除了线程创建和释放的问题,线程数也是一个比较值得关注的问题。尤其是 running 线程数多了后,context switch 和调度的代价可能会对性能带来冲击。为什么这里刻意强调是 running 态线程呢? 因为处于阻塞态的线程(锁等待、nanosleep 等),实际并不参与调度也不会发生上下文切换。可能很多人都有这样的误解就是:线程数(无论是否处于阻塞态)多了,上下文切换、调度代价就一定高,实际上并不完全正确的。因为对于处于阻塞态的线程,调度器不会分配给他任何 CPU 时间,直到被唤醒为止。Linux 的调度器实现是 CFS(Completely Fair Scheduler),它实际上在每个 CPU core 上维护了一个基于红黑树的处于 runnable 态线程的 queue,也叫 runqueue。这个 runqueue 的调度代价为 log(n)(n 为该队列中 runnable 线程的数目)。由于 CFS 只对 running 态线程做调度,所以调度和 context switch 主要发生在 running 线程之间。刚才详细分析了调度器 CFS 的代价,接下来讲一下 context switch 的。
context switch 分为进程内和进程间,由于我们一般都是单进程下的多线程开发,所以这里的上下文切换主要是指进程内线程的切换代价。进程内线程切换相对于跨进程切换效率相对较高, 因为不发生 TLB(Translation lookaside buffer) flush。不过进程内线程切换的代价也不低,因为会发生寄存器现场、TCB(thread control block)的保存和恢复,还有 CPU cache的部分失效。
之前版本 TiFlash 在高并发查询下线程总数可以达到 5000 多,确实是一个比较恐怖的数目。但是 runnning 线程数一般不超过 100 个。假设在 40 个逻辑核的机器上运行, 这时候的调度代价最坏情况下不超过 lg(100) , 理想状态应该是 lg(100/40) , 代价相对较小。而上下文切换代价大概相当于几十个 running 线程的量级, 也属于比较可控的状态。
这里, 我也做了个实验来对比 5000 个 running 线程和 5000 个 blocked 线程的耗时对比。首先定义了 3 种线程状态:work 是从 0 到 50000000 做计数;Yield 是循环做sched_yeild, 让线程不做任何计算工作就让出 CPU 执行权并维持 runnable 状态,这样的目的是在增加 running 态线程数目的同时,不引入额外计算工作量。Wait 是做condition_variable.wait(lock, false)。耗时结果如下:

可以看到,因为锁等待是非 running 的线程,实验一和实验二的耗时相差不大,说明 5000 个阻塞态线程并没对性能造成明显冲击。而实验三,500 个只做上下文切换的线程(相当于不做计算工作的 running 态线程),数目上没有实验二的 wait 线程多,即使不做别的计算工作, 也给性能造成巨大的冲击。这带来的调度和上下文切换代价就相当明显了,耗时直接涨了近 10 倍多。这说明,调度和上下文切换代价主要跟非阻塞态的 running 线程数有关。这一点, 有助于我们以后在分析性能问题时得到更准确的判断。
我们在排查问题时, 在监控上其实踩了不少坑, 一个是系统监控工具 top 挖的。我们在 top 下看到 running threads 数目低于预期, 经常在个位数徘徊。让我们误以为问题出在了系统的上下文有关。但是, 主机的 CPU 使用率却能达到 80%。可是细想又觉得不对劲:如果大部分时间都是几个或者十几个线程在工作, 对于一台 40 逻辑核的主机来说, 是不可能达到这么高的 CPU 使用率的, 这是怎么回事呢?
//Entry Pointstatic void procs_refresh (void) {
... read_something = Thread_mode ? readeither : readproc; for (;;) {
... // on the way to n_alloc, the library will allocate the underlying
// proc_t storage whenever our private_ppt[] pointer is NULL...
// read_something() is function readeither() in Thread_mode!
if (!(ptask = read_something(PT, private_ppt[n_used]))) break;
procs_hlp((private_ppt[n_used] = ptask)); // tally this proc_t
}
closeproc(PT);
...} // end: procs_refresh// readeither() is function pointer of read_something() in Thread_mode;// readeither: return a pointer to a proc_t filled with requested info about// the next unique process or task available. If no more are available,// return a null pointer (boolean false). Use the passed buffer instead// of allocating space if it is non-NULL.proc_t* readeither (PROCTAB *restrict const PT, proc_t *restrict x) {
...
next_proc:
...
next_task:
// fills in our path, plus x->tid and x->tgid
// find next thread
if ((!(PT->taskfinder(PT,&skel_p,x,path))) // simple_nexttid()
|| (!(ret = PT->taskreader(PT,new_p,x,path)))) { // simple_readtask
goto next_proc;
} if (!new_p) { new_p = ret;
canary = new_p->tid;
} return ret;
end_procs:
if (!saved_x) free(x); return NULL;
}// simple_nexttid() is function simple_nexttid() actually// This finds tasks in /proc/*/task/ in the traditional way.// Return non-zero on success.static int simple_nexttid(PROCTAB *restrict const PT, const proc_t *restrict const p, proc_t *restrict const t, char *restrict const path) { static struct dirent *ent; /* dirent handle */
if(PT->taskdir_user != p->tgid){ // init
if(PT->taskdir){
closedir(PT->taskdir);
} // use "path" as some tmp space
// get iterator of directory /proc/[PID]/task
snprintf(path, PROCPATHLEN, "/proc/%d/task", p->tgid);
PT->taskdir = opendir(path); if(!PT->taskdir) return 0;
PT->taskdir_user = p->tgid;
} for (;;) { // iterate files in current directory
ent = readdir(PT->taskdir); // read state file of a thread
if(unlikely(unlikely(!ent) || unlikely(!ent->d_name[0]))) return 0; if(likely(likely(*ent->d_name > '0') && likely(*ent->d_name <= '9'))) break;
}
... return 1;
}// how TOP statisticizes state of threads switch (this->state) { case 'R':
Frame_running++; break; case 't': // 't' (tracing stop)
case 'T':
Frame_stopped++; break; case 'Z':
Frame_zombied++; break; default: /* the following states are counted as sleeping state
currently: 'D' (disk sleep),
'I' (idle),
'P' (parked),
'S' (sleeping),
'X' (dead - actually 'dying' & probably never seen)
*/
Frame_sleepin++; break;
}分析了 top 的源码后,终于明白了原因。原来 top 显示的不是当时的"瞬时情况", 因为 top 不会把程序停掉。具体的工作过程如上图, top 会扫描一遍当时的线程列表, 然后一个一个去取状态, 这个过程中程序是继续运行的, 所以 top 扫完列表后, 之后新启动线程是没记录进去的, 而旧线程一部分已经结束了, 结束状态的线程会算到 sleeping 里。所以对于高并发线程频繁申请和释放的场景下, top 上看到的 running 数就是会偏少的。
所以 top 中的 running 线程数, 对于线程频繁创建和释放的程序来说, 这个指标是不准确的。
此外, 对于 pipeline 形式的 TiFlash, 数据在 pipeline 流动的过程中, 同一数据只会出现在 pipleline 的一个环节上, 算子有数据就处理, 没数据就等待(GDB 上看大部分线程都是这个状态)。pipeline 中大部分的环节都处于没数据等待, 有数据又很快结束的状况。监控工程中没有停掉整个 TiFlash, 所以对于每个线程了, 大概率会取到这个线程的等待状态。
在整个问题的排查过程中, 有一些方法是可以沉淀下来, 以后的开发、排查工作中, 依然可以用到:
多线程开发中, 应尽量采用线程池、协程等手段来避免频繁的线程创建和释放。
尽量在简单环境下复现问题, 以减少会对排查产生干扰的因素。
控制 running 态的线程数目, 大于 CPU 核数后会产生多余的上下文切换代价。
在线程等待资源的场景的开发中, 尽量使用 lock, cv 等。如果用 sleep, 睡眠间隔应尽量设得长一点, 以减少不必要的线程唤醒。
辩证地看待监控工具, 当分析结果和监控数据有矛盾时, 不能排除对监控工具本身的质疑。此外,要仔细阅读监控工具的文档和指标说明,避免对指标产生误读。
多线程 hang、slow、争抢问题排查:pstack、GDB 看各个线程的状态。
性能热点工具:perf 、flamegraph。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

