

黄东旭解析 TiDB 的核心优势
1217
2023-06-30
本文讲了大数据套件带你玩转大数据,大数据处理套件是什么。
前言
人类每一次大的技术变革都是先在新兴产业生根发芽,再慢慢把触角伸到传统行业。在当前这股由IT(Information Technology)向DT(Data Technology)转变的技术浪潮中,互联网行业成为云计算、大数据等高新技术的试验田。经过近十年的发展,随着大数据技术的不断成熟以及互联网应用案例的普及,”数据驱动业务”的模式逐渐得到各行各业的广泛认同,“互联网+”战略的提出更是为大数据从互联网向其他行业的传播吹来一阵东风。
大数据平台面向数据开发人员,整合各种大数据基础系统,组合成特定的数据流水线;集群控制台面向运维人员,统一管理大数据平台的系统,提供集群部署与管控的功能。这两个平台将在后文详细介绍。不同的企业机构对大数据基础设施的要求不尽相同:有的需要自建数据中心,或者对数据安全有特殊需求;有的需要资源弹性伸缩,按需动态分配。 针对前者用户,大数据套件提供完整安装包,可以直接在私有的物理机上部署集群(称之为 On-premise模式);针对后者用户,大数据套件与云整合,按需动态分配云主机来部署集群(称之为 In-cloud模式)。
大数据套件总体架构大数据平台一条完整的数据处理流水线通常由 “接入-存储-计算-输出-展示”五个环节衔接而成。大数据技术经过阶段性地发展,各环节都涌现出一批 相互借鉴、相互补充的基础系统。大数据套件将常见的基础系统(包含社区版系统、社区改造版系统以及自研系统)集成封装,形成统一的大数据平台。数据开发人员可以从大数据平台自由选择不同的基础系统来构建数据流水线,以满足不同场景的数据处理需求。
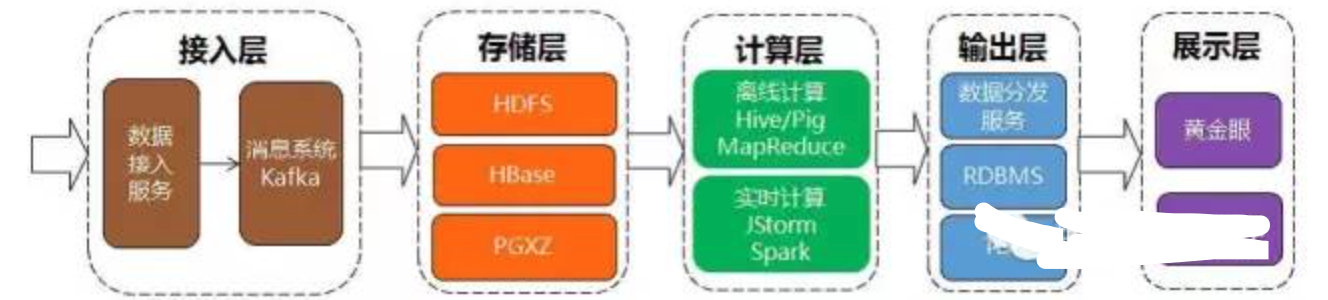
基于大数据平台构建完整的数据流水线基础系统
接入层
• 数据接入服务:支持通过FTP、SFTP、HTTP 协议从外部接入数据。
• Kafka:分布式消息系统,作为平台的数据中转站,负责将接入数据推送给若干下游系统。
存储层
• HDFS:Hadoop 分布式文件系统。
• ***:基于HDFS 的分布式列式数据库,提供高速的随机读写能力。
• PGXZ:分布式*** 数据库系统。通过数据库事务分流、数据分布式存储以及并行计算,提高数据库的性能和稳定性。PGXZ 基于社区版PGXC 做了大量性能优化。
• TPG:基于传统数据库*** 改造,主要承担小数据的处理(结果表、维度表),对大规模数据框架的补充。
计算层
• MapReduce:大规模数据集的并行计算框架,适合离线批量的数据处理。
• Hive:基于Hadoop 的数据仓库工具,提供SQL 语言的数据处理接口。在社区版基础上实现了一套兼容商业数据仓库*** 功能的SQL语法和功能,并进行了稳定性和性能的优化。
• Pig:基于Hadoop 的大规模数据分析平台,提供脚本接口的数据处理。
• Tez:基于Hadoop 的查询处理框架。作为支撑Pig/Hive 的新一代计算引擎,可以将多个有依赖的作业转换为一个DAG 作业,从而大幅提高查询性能。
• Spark:新一代的大规模数据并行计算框架,充分利用集群内存资源来分布数据集,大幅提高计算性能。
• JStorm:实时流式计算框架,对Hadoop 批量计算的补充。
• EasyCount:基于JStorm 的流式计算平台,提供SQL语言的编程接口。
输出层
• 数据分发服务:支持通过FTP、SFTP、HTTP 协议将数据分发到外部。
• TDE:基于全内存的分布式KV 存储系统。提供高效的数据读写能力,使得流式计算引擎产生的结果能快速被外部系统使用。
展示层
•黄金眼:可视化运营报表工具,提供标准化的报表模块,通过灵活地拖拽布局,自助创建数据报表。 任务调度数据流水线完成某个数据处理任务,不仅需要单个环节的处理能力,更需要对各个环节整体的衔接调度能力。大数据平台集成了自研的Lhotse 系统,作为数据流水线的调度编排中心。
它主要具备如下特性:
• 调度周期多样化:支持月、周、天、小时、分钟及一次性任务。
• 调度任务多样化:支持数据接入任务(例如,从RDBMS、FTP 向HDFS导入数据),计算任务(如MapReduce、Hive),数据导出任务(例如,从HDFS 导出至RDBMS)等。覆盖了数据流水线的各个环节。
• 任务依赖多样化:不同周期/类型的任务间均可建立依赖,这是衔接数据流水线不同环节的核心能力。
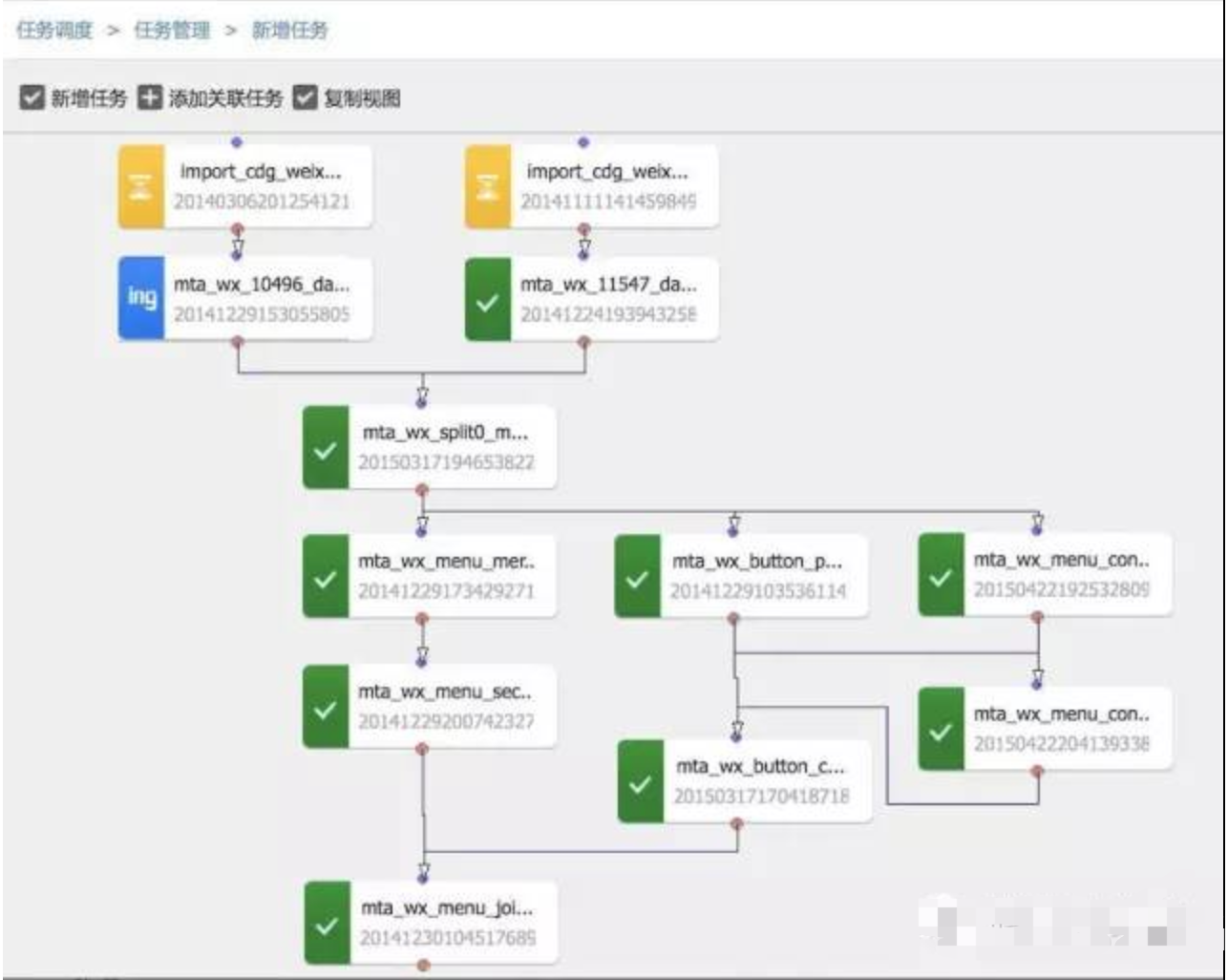
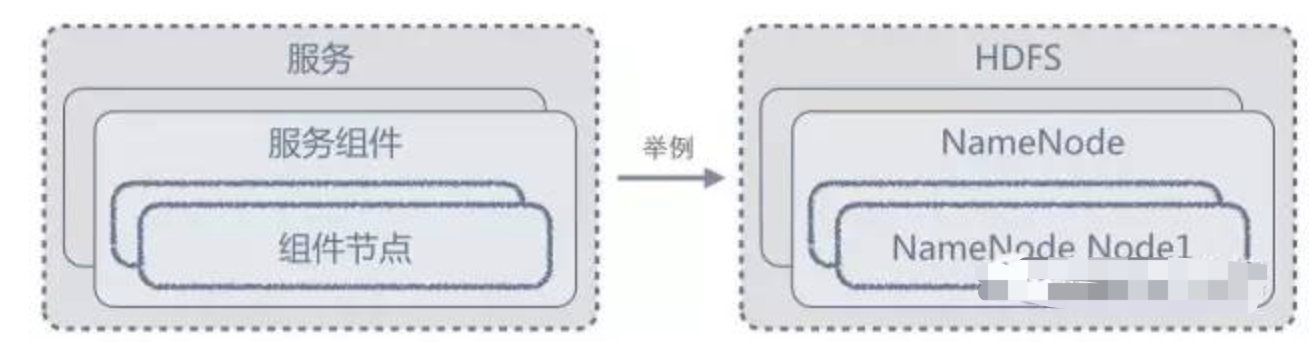
Lhotse 的任务依赖图集群控制台如前文所述,搭建大数据流水线需要组合各个环节的基础系统,每个系统都是分布式的,并且部署、配置、启停、监控方式都有所差异,这给运维人员带来极大的挑战。为了降低这种运维复杂度,大数据套件自带一个Web 控制台(简称控制台),提供统一的部署、管理及监控界面,只需简单点击即可完成基本的集群维护工作。抽象要统一管理各个不同的系统,必须定义通用的抽象来描述任意的系统。控制台以 “服务-服务组件-组件节点”三个概念实体来抽象系统:一个系统对应为一个服务,服务由多个服务组件构成,服务组件可以部署到多台机器节点上,每个节点上的组件实例称为组件节点。下图以HDFS 为例来对应抽象,更为直观。
集群控制台对系统的抽象化部署通过标准化的安装向导,数据流水线中的所有服务可以被一次性部署到集群。
安装过程涉及如下几个主要步骤,由集群控制台自动执行:
•选择服务:服务间可能存在依赖关系(例如,*** 依赖Zookeeper),控制台能够自动解析依赖,生成正确的安装顺序。
•规划机器:根据资源需求与集群规模,为不同的服务组件分配运行机器,以达到最优的资源利用率。用户也可以自定义机器规划,为某个服务组件选择特定的机器。
•创建账号:在安装机器上创建每个服务的特定账号,必要的时候设置SSH无密码登陆。
•配置服务:根据集群规模和机器参数,生成推荐的默认配置。
用户也可自定义配置,修改某些配置项(所有服务配置均以KV键值对的形式展示)。
• 分发部署包:支持两种部署包分发方式——YUM RPM 包和Docker 镜像(大数据套件提供额外的安装包来搭建YUM 仓库或Docker Registry)
部署过程中的自定义配置步骤管理管理本质上是对集群的当前状态做变更操作,控制台允许用户对已部署的集群做以下变更:
• 启动/停止:启停的对象可以是服务/服务组件/组件节点。同时启停多个服务组件可能要求特定的操作顺序(例如,NameNode 必须在DataNode 之前启动),控制台将根据预设的顺序关系,自动生成操作DAG。
•变更配置:某个服务配置项的变更,将在服务重启时自动下发到对应的组件节点。同时,控制台维护配置的历史版本,可以在版本间任意切换。
• 扩缩容:扩缩容的对象是集群/服务组件。扩(缩)容集群意味着上架(下架)机器;扩(缩)容服务组件意味着从集群已有机器上安装(卸载)组件节点。
• 卸载/清理:卸载的对象是服务,用户可以选择是否清理历史数据。
•升级版本:有两种升级方式—— 全量升级与增量升级。全量升级必须先停止所有的组件节点,导致服务的暂不可用;增量升级(也称灰度升级)可选择部分组件节点先升级,前提是服务本身支持HA 特性(比如HDFS、YARN)。
集群服务的管理界面监控监控本质上是对集群的当前状态做健康检查与报告, 控制台从指标与告警两个方面来展开监控。指标由系统指标和服务指标两部分:系统指标反映了集群整体的CPU、内存、网络、磁盘的负载情况;而服务指标反映了业务级别的状态,如MapReduce任务个数、HDFS 总数据量、*** 平均查询时间等。
集群指标的展示界面 告警是在集群出现异常状态时被触发,控制台当前对如下几类状态做告警监控(一个服务可以指定多个告警类型):
• 进程:检查特定PID 的进程是否还在。
• 端口:检查特定的端口是否被监听。
• Web:检查某个HTTP URL 是否正常返回。
• 指标:检查某个指标是否大(小)于预设的阈值。
• 脚本:检查指定的脚本执行是否正常返回。
后话大数据套件作为大数据平台开放的重点产品,已经与多家企业机构展开合作。后续会持续地加大投入,在逐步完善 现有的两大平台(大数据平台与集群管理平台)的,同时,启动建设建立通用的数据分析平台(文本分析、OLAP 等、),帮助更多的企业机构认识大数据、玩转玩好大数据。
Hadoop
hdfs
分布式文件存储系统
namenode:作为master,负责整个系统的元数据的存储,管理整个集群数据的block分配和调度
datanode:数据节点,存放数据
block数据存储的最小粒度,默认128MB一个
数据副本:以block为粒度进行副本备份,可配置
MapReduce
计算系统
map:一段计算函数(代码),将一个任务拆分为多个map,放在不同的计算节点,分开执行,并将执行结果存储落盘
reduce:将多个map执行的结果从磁盘中读取,并进行聚合、汇总,再讲最终结果放入hdfs
Yarn
作为Hadoop的资源调度器,负责系统资源cpu等的资源调度工作
Hive
基于Hadoop的一种大数据管理框架,用来进行数据提取、转化、加载,将hadoop的一些文件语义操作通过类sql实现,并可通过类sql完成一些计算任务,计算任务可通过不同计算框架执行(原生mapreduce、spark、Tez);
hive可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转化为MapReduce任务进行运行
Spark
基于hadoop的MapReduce任务,做了一系列优化,将计算任务通过有向无环图进行重新整理,并将中间结果放入内存,提升了计算效率;
Sqoop
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库*(例如 : MySQL ,*** ,Postgres等)*中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Superset
可视化图标工具,类似于grafna
库中。
Superset
可视化图标工具,类似于grafna
上文就是小编为大家整理的大数据套件带你玩转大数据,大数据处理套件是什么。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

