
黄东旭解析 TiDB 的核心优势
742
2023-03-31
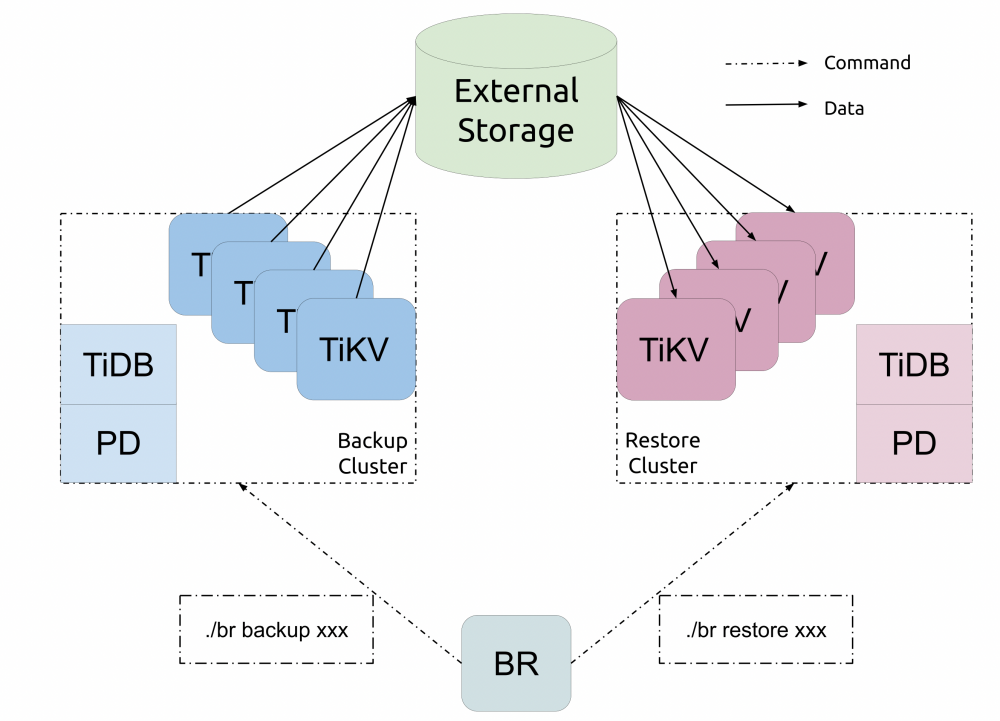
BR 选择了在 Transaction KV 层面进行扫描来实现备份。这样,备份的核心便是分布在多个 TiKV 节点上的 MVCC Scan:简单,粗暴,但是有效,它生来就继承了 TiKV 的诸多优势:分布式、利于横向拓展、灵活(可以备份任意范围、未 GC 的任意版本的数据)等等优点。
相较于从前只能使用 mydumper 进行 SQL 层的备份,BR 能够更加高效地备份和恢复:它取消了 SQL 层的开销,同时支持备份索引,而且所有备份都是已经排序的 SST 文件,以此大大加速了恢复。
本文将会详细描述 BR 备份侧的具体实现。简单来讲,BR 就是备份的“算子下推”:通过 gRPC 接口,将任务下发给 TiKV,然后让 TiKV 自己将数据转储到外部存储中。
为了区别于一般的 MVCC Scan 请求,TiKV 提供一个叫做 Backup的接口,这个接口与一般的读请求不同——它不会返回数据给客户端,而是直接将读到的数据存储到指定的存储器(External Stroage)中:
service Backup { // 收到 backup 的 TiKV,将会将 Request 指定范围中,所有自身为 leader
// 的 region 备份,并流式地返回给客户端(每个 region 对应流中的一个 item)。
rpc backup(BackupRequest) returns (stream BackupResponse) {}
}// NOTE:隐藏了一些不重要的 field 。message BackupRequest { // 备份的范围,[start_key, end_key)。
bytes start_key = 2; bytes end_key = 3; // 备份的 MVCC 版本。
uint64 start_version = 4; uint64 end_version = 5;
// 限流接口,为了确保和恢复时候的一致性,限流限制保存备份文件的阶段的速度。
uint64 rate_limit = 7;
// 备份的目标存储。
StorageBackend storage_backend = 9; // 备份的压缩 -- 这是一个用 CPU 资源换取 I/O 带宽的优化。
CompressionType compression_type = 12; int32 compression_level = 13; // 备份支持加密。
CipherInfo cipher_info = 14;
}message BackupResponse {
Error error = 1; // 备份的请求将会返回多次,每次都会返回一个已经完成的子范围。
// 利用这些信息可以统计备份进度。
bytes start_key = 2; bytes end_key = 3; // 返回该范围备份文件的列表,用于恢复的时候追踪。
repeated File files = 4;
}BR 客户端会借助 TiDB 的接口,根据用户指定需要备份的库和表,计算出来需要备份的范围(“ranges”)。计算的依据是:
依据每个 table 的所有 data key 生成 range。(所有带有 t{table_id}_r前缀的 Key)
依据每个 index 的所有 index key 生成 range。(所有带有 t{table_id}_i{index_id}前缀的 Key)
如果 table 存在 partition(这意味着,它可能有多个 table ID),对于每个 partition,按照上述规则生成 range。
为了获得最大的并行度,BR 客户端会并行地向所有 TiKV 发送这些 Range 上的备份请求。
当然,备份不可能一帆风顺。我们在备份的时候不可避免地会遇到问题:例如网络错误,或者触发了 TiKV 的限流措施(Server is Busy),或者 Key is Locked,这时候,我们必须缩小这些 range,重新发送请求(否则,我们就要重复一遍之前已经做过的工作……)。
在失败之后,选择合适的 range 来重发请求的过程,在 BR 中被称为 “细粒度备份(fine-grained backup)”,具体而言:
1.在之前的 “粗粒度备份” 中,BR 客户端每收到一个 BackupResponse就会将其中的 [start_key, end_key)作为一个 range 存入一颗区间树中(你可以把它想象成一个简单的 BTreeSet<(Vec<u8>, Vec<u8>)>)。
2.“粗粒度备份” 遇到任何可重试错误都会忽略掉,只是相应的 range 不会存入这颗区间树中,因此树中会留下一个 “空洞”,这两步的伪代码如下。
func Backup(tree RangeTree) { // ...
for _, resp := range responses { if resp.Success {
tree.Insert(resp.StartKey, resp.EndKey)
}
}
}// An example:
// When backing up the ange [1, 5).// [1, 2), [3, 4) and [4, 5) successed, and [2, 3) failed:// The Tree would be like: { [1, 2), [3, 4), [4, 5) },
// and the range [2, 3) became a "hole" in it.// // Given the range tree is sorted, it would be easy to
// find all holes in O(n) time, where n is the number of ranges.3.在 “粗粒度备份” 结束之后,我们遍历这颗区间树,找到其中所有 “空洞”,并行地进行 “细粒度备份”:
找到包含该空洞的所有 region。
对他们的 leader 发起 region 相应范围的 Backup RPC。
成功之后,将对应的 range 放入区间树中。
4.在一轮 “细粒度备份” 结束后,如果区间树中还有空洞,则回到 (3),在超过一定次数的重试失败之后,报错并退出。
在上述 “备份”流程完成之后,BR 会利用 Coprocessor 的接口,向 TiKV 请求执行用户所指定表的 checksum。
这个 checksum 会在恢复的时候用作参考,同时也会和 TiKV 在备份期间生成的逐文件的 checksum 进行对比,这个比对的过程叫做 “fast checksum”。
在 “备份” 的过程中,BR 会通过 TiDB 的接口收集备份的表结构、备份的时间戳、生成的备份文件等信息,储存到一个 “backupmeta”中。这个是恢复时候的重要参考。
为了实现资源隔离,减少资源抢占,Backup 相关的任务都运行在一个单独的线程池里面。这个线程池中的线程叫做 “bkwkr”(“backup worker” 极其抽象的缩写)。
在收到 gRPC 备份的请求之后,这个 BackupRequest会被转化为一个 Task。
而后,TiKV 会利用 Task中的 start_key和 end_key生成一个叫做 “Progress”的结构:它将会把 Task中庞大的范围划分为多个子范围,通过:
扫描范围内的 Region。
对于其中当前 TiKV 角色为 Leader的 Region,将该 Region 的范围作为 Backup 的子任务下发。
Progress提供的接口是一个使用 “拉模型” 的接口:forward。随后,TiKV 创建的各个 Backup Worker 将会去并行地调用这个接口,获得一组待备份的 Region,然后执行以下三个步骤:
对于这些 Region,Backup Worker 将会通过 RaftKV接口,进行一次 Raft 的读流程,最终获得对应 Region 在 Backup TS 的一个 Snapshot。(“Get Snapshot”)
对于这个 Snapshot,Backup Worker 会通过 MVCC Read 的流程去扫描 backup_ts的一致版本。这里我们会扫描出 Percolator 的事务,为了恢复方便,我们会准备 “default” 和 “write” 两个临时缓冲区,分别对应 TiKV Percolator 实现中的 Default CF 和 Write CF。(“Scan”)
然后,我们会先将扫描出来的事务中两个 CF 的 Raw Key 刷入对应缓冲区中,在整个 Region 备份完成(或者有些 Region 实在过大,那么会在途中切分备份文件)之后,再将这两个文件存储到外部存储中,记录它们对应的范围和大小等等,最后返回一个 BackupResponse给 BR。(“Save”)
为了保证文件名的唯一性,备份的文件名会包括当前 TiKV 的 store ID、备份的 region ID、start key 的哈希、CF 名称。
备份文件使用 RocksDB 的 Block Based SST 格式:它的优势是,原生支持文件级别的 checksum 和压缩,同时可以在恢复的时候快速被 ingest 的潜力。
外部存储是为了适配多种备份目标而存在的通用储存抽象:有些类似于 Linux 中的 VFS,不过简化了非常多:仅仅支持简单的保存和下载整个文件的操作。它目前对主流的云盘都做了适配,并且支持以 URL 的形式序列化和反序列化。例如,使用 s3://some-bucket/some-folder,可以指定备份到 S3 云盘上的 some-bucket之下的 some-folder目录中。
通过以上的基本流程,BR 的基本链路已经可以跑通了:类似于算子下推,BR 将备份任务下推到了 TiKV,这样可以合理利用 TiKV 的资源,实现分布式备份的效果。
在这个过程中,我们遇到了许多挑战,在这一节,我们来谈谈这些挑战。
前文中提到,BackupMeta 储存了备份的所有元信息:包括表结构、所有备份文件的索引等等。想象一下你有一个足够大的集群:比如说,十万张表,总共可能有数十 TB 的数据,每张表可能还有若干索引。
如此最终可能产生数百万的文件:在这个时候,BackupMeta 可能会达到数 GB 之大;另一方面,由于 protocol buffer 的特性,我们可能不得不读出整个文件才能将其序列化为 Go 语言的对象,由此峰值内存占用又多一倍。在一些极端环境下,会存在 OOM 的可能性。
为了缓解这个问题,我们设计了一种分层的 BackupMeta 格式,简单来讲,就是将 BackupMeta 拆分成索引文件和数据文件两部分,类似于 B+ 树的结构:
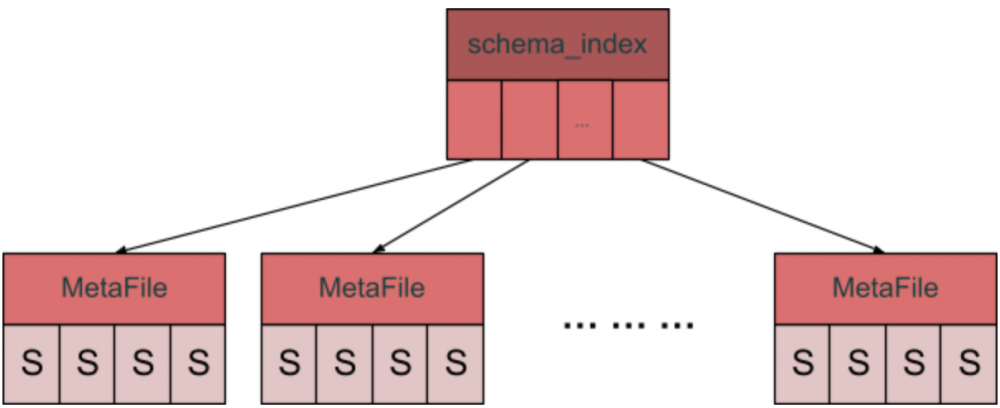
具体来讲,我们会在 BackupMeta 中加上这些 Fields,分别指向对应的 “B+ 树” 的根节点:
message BackupMeta { // Some fields omitted...
// An index to files contains data files.
MetaFile file_index = 13; // An index to files contains Schemas.
MetaFile schema_index = 14; // An index to files contains RawRanges.
MetaFile raw_range_index = 15; // An index to files contains DDLs.
MetaFile ddl_indexes = 16;
}MetaFile 就是这颗 “B+ 树” 的节点:
// MetaFile describes a multi-level index of data used in backup.message MetaFile { // A set of files that contains a MetaFile.
// It is used as a multi-level index.
repeated File meta_files = 1;
// A set of files that contains user data.
repeated File data_files = 2; // A set of files that contains Schemas.
repeated Schema schemas = 3; // A set of files that contains RawRanges.
repeated RawRange raw_ranges = 4; // A set of files that contains DDLs.
repeated bytes ddls = 5;
}它可能有两种形态:一是承载着对应数据的 “叶子节点”(后四个 field 被填上相应的数据),也可以通过 meta_files将自身指向下一个节点:File是一个到外部存储中其他文件的引用,包含文件名等等基础信息。
目前的实现中,为了回避真正实现类似 B 树的分裂、合并操作的复杂性,我们仅仅使用了一级索引,将的表结构和文件的元数据分别存储到一个个 128M 的小文件中,如此已经足够回避 BackupMeta 带来的 OOM 问题了。
在备份扫描的整个过程中,因为时间跨度较长,必然会受到 GC 的影响。 不仅仅是 BR,别的生态工具也会遇到 GC 的问题:例如,TiCDC 需要增量扫描,如果初始版本已经被 GC 掉,那么就无法同步一致的数据。
过去我们的解决方案一般是让用户手动调大 GC Lifetime,但是这往往会造成 “初见杀” 的效果:用户开开心心备份,然后去做其他事情,几个小时后发现备份因为 GC 而失败了……
这会非常影响用户的心情:为了让用户能更加开心地使用各种生态工具,PD 提供了一个叫做 “Service GC Safepoint” 的功能。各个服务可以通过 PD 上的接口,设置一个 “Safepoint”,TiDB 会保证,在 Safepoint 指定的时间点之后,所有历史版本都不会被 GC。为了防止 BR 在意外退出之后导致集群无法正常 GC,这个 Safepoint 还会存在一个 TTL:在指定时间之后若是没有刷新,则 PD 会移除这个 Service Safe Point。
对于 BR 而言,只需要将这个 Safepoint 设置为 Backup TS 即可,作为参考,这个 Safepoint 会被命名为 “br-
在全速备份的时候,备份的流量可能相当大:具体可以看看开头“秀肌肉”文章相关的部分。
如果你愿意使用足够多的核心去备份,那么可能很快就会到达网卡的瓶颈(例如,如果不经压缩,千兆网卡大约只需要 4 个核心就会被满。),为了避免网卡成为瓶颈,我们在备份的时候引入了压缩。
我们复用了 RocksDB Block Based Table Format 中提供的压缩功能:默认会使用 zstd 压缩。压缩会增大 CPU 的占用率,但是可以减少网卡的负载,在网卡成为瓶颈的时候,可以显著提升备份的速度。
为了减少对其他任务的影响,如前文所说,所有的备份请求都会在单独的线程池中执行。
但是即便如此,如果备份消耗了太多的 CPU,不可避免地会对集群中其它负载造成影响:主要的原因是 BR 会占用大量 CPU,影响其它任务的调度;另一方面则是 BR 会大量读盘,影响写任务刷盘的速度。
为了减少资源的使用,BR 提供了一个限流机制。当用户带有 --ratelimit 参数启动 BR 的时候,TiKV 侧的第三步“Save”,将会被限流,与此同时也会限制之前步骤的流量。
这里需要注意一个点:备份数据的大小往往会远远小于集群的实际空间占用。原因是备份只会备份单副本、单 MVCC 版本的数据。通 ratelimit 限流施加于 Save 阶段,因此是限制写备份数据的速度。
在 “服务端” 侧,也可以通过调节线程池的大小来限流,这个参数叫做 backup.num-threads,考虑到我们允许用户侧限流,它的默认值非常高:是全部 CPU 的 75%。如果需要在服务侧进行更加彻底的限流,可以修改这个参数。作为参考,一块 Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz CPU 每个核心大概每秒能生成 10M 经 zstd 压缩的 SST 文件。
通过 Service Safe Point,我们解决了手动调节 GC 带来的“难用”的问题。
通过新设计的 BackupMeta,我们解决了海量表场景的 OOM 问题。 通过备份压缩、限流等措施,我们让 BR 对集群影响更小、速度更快(即便二者可能无法兼得)。
总体上而言,BR 是在 “物理备份” 和 “逻辑备份” 之间的 “第三条路”:相对于 mydumper 或者 dumpling 等工具,它消解了 SQL 层的额外代价;相对于在分布式系统中寻找物理层的一致性快照,它易于实现且更加灵巧。对于目前阶段而言,是适宜于 TiDB 的容灾备份解决方案。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

