
黄东旭解析 TiDB 的核心优势
1164
2023-06-27
本文讲了万能数据库,你了解多少?面试必备!!!全能数据库管理工具。
前言:
今天主要跟大家分享一下几个点(主要分享关系型数据库mysql,非关系型数据库redis我后面也有分享):
1,如何设计一个好的数据库?
2,项目中是如何应用的?
3,数据库一些高级使用?
4,数据库如何优化?
一、设计数据问题:
1,首先要根据项目中的需求来确定数据库方案,今天就以我的两张微博图片为例,进行分析,有以下几个注意点:
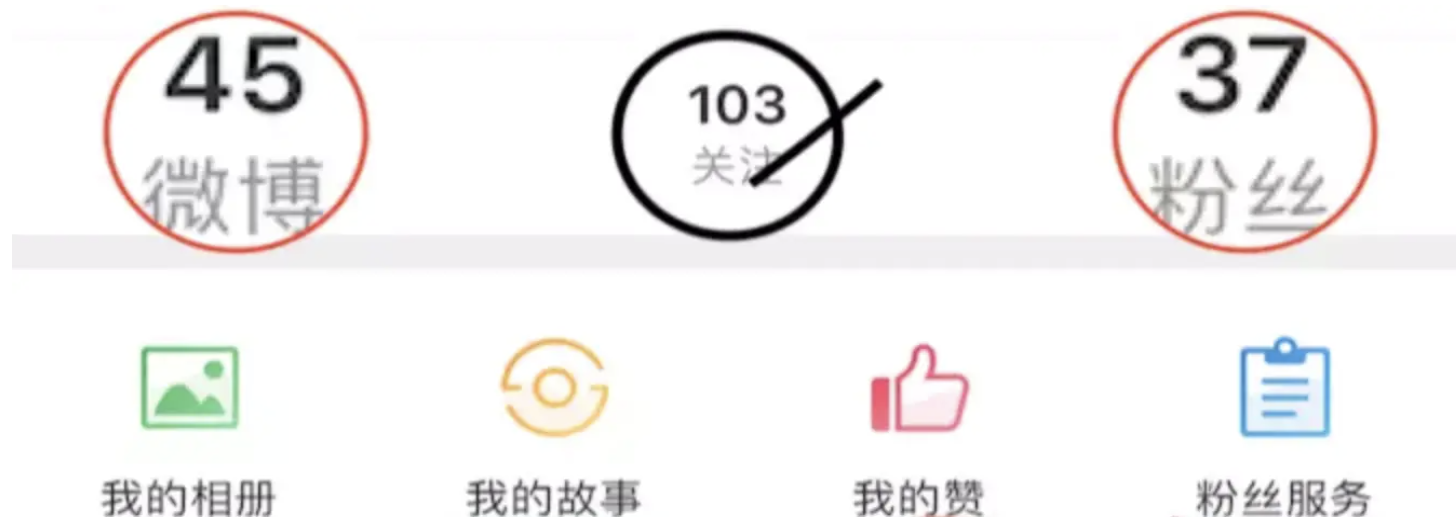
微博个人页面.png
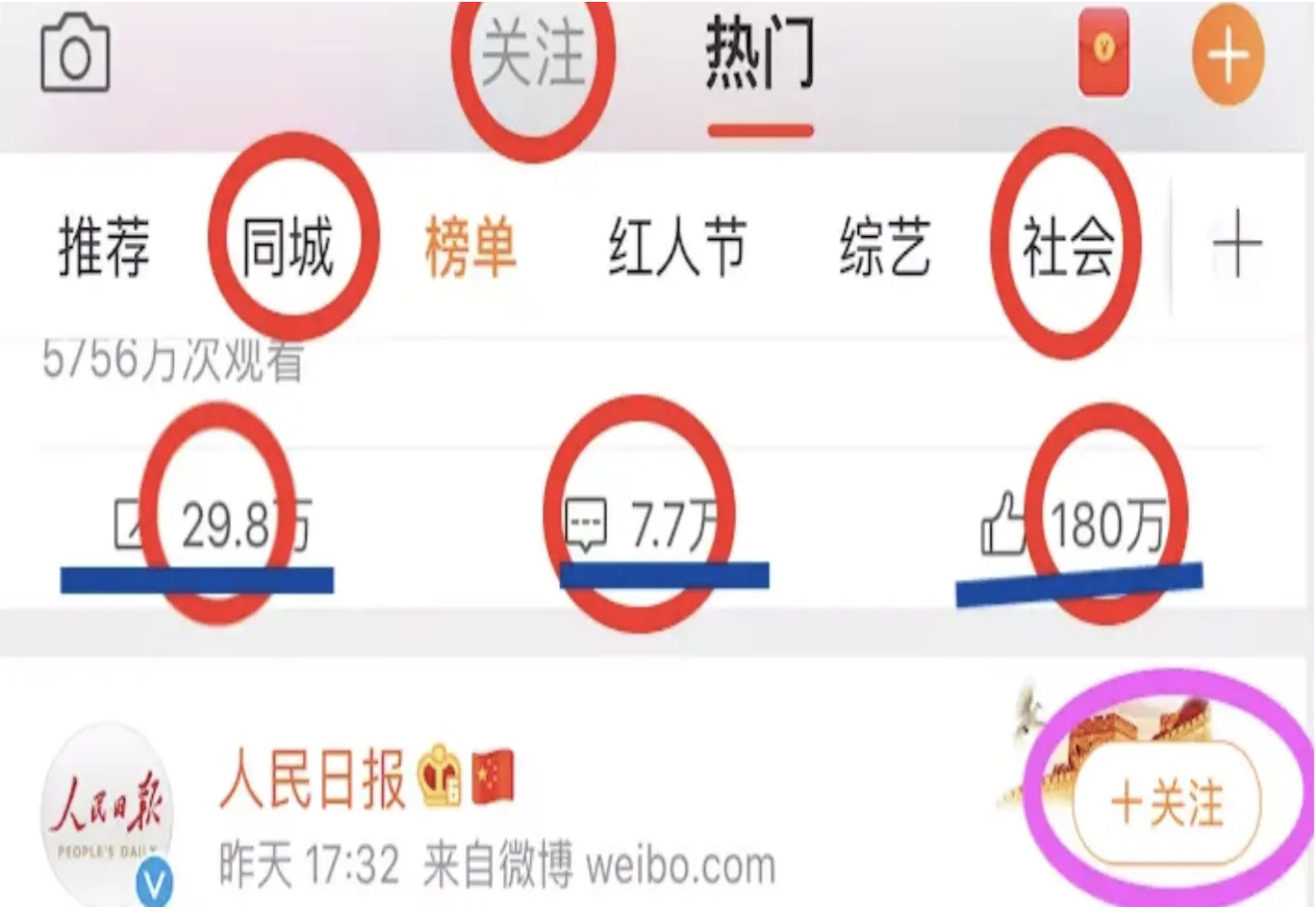
看过上面两张图片后,大致心里就要有个方向,看到什么数据,就要想到创建什么表。等到你随便看到一个网页,就能说出它有哪些表,有哪些字段的时候,你就是大神的级别了。
接下来我就说一下 上面两张图片给我的信息,以及设计数据库的思路:
1,首先要有一个用户表(User),必备!用户的id,name,mobile等等等,然后确定主键,一般主键我们都会选择变动不大的字段,所以选择id为用户表主键。
2,频道分析(Channel):可以考虑量两张表,一个总的频道表(channel),一个用户频道表(user_channel)
而User与Channel两者属于多对多的关系,主要通过外键连接。
3,文章评论条数分析、时间、状态等(Article):可以创建两个表,一个文章表,一个评论表
文章表Article:art_id 、title 、 user_id(作者) 、create_time 、 status 、review_time、 update_time、 is_top 、comment_counts等字段
评论表Comment:com_id 、 comment 、art_id 、user_id 、create_time等字段
注意:在Article表中,我们多设置了一个comment_counts
,采用以空间来换时间的思想。反范式,增加冗余字段,到数据库优化的时候,也会讲到这个思想。
4,关注表(Relation):可以设置id、 user_id 、target_user_id(被关注用户) 等字段,如果要查询关注的用户可以用以下命令:
select target_user_id from 关注表 where user_id = 1; # 查关注的用户select user_id from 关注表 where target_user_id = 2; # 查粉丝
5,类型和参数说明:
数据库整型存储大小与显示大小的区别:
存储大小靠类型区分: TINYINT、 SMALLINT、 MEDIUMINT、 INT、 BIGINT
显示大小: BIGINT(20) BIGINT(6)
看下面例子:
CREATE TABLE `test` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`i1` int(3) unsigned zerofill DEFAULT NULL,
`i2` int(6) unsigned zerofill DEFAULT NULL,
PRIMARY KEY (`id`)) ENGINE=MyISAM DEFAULT CHARSET=utf8
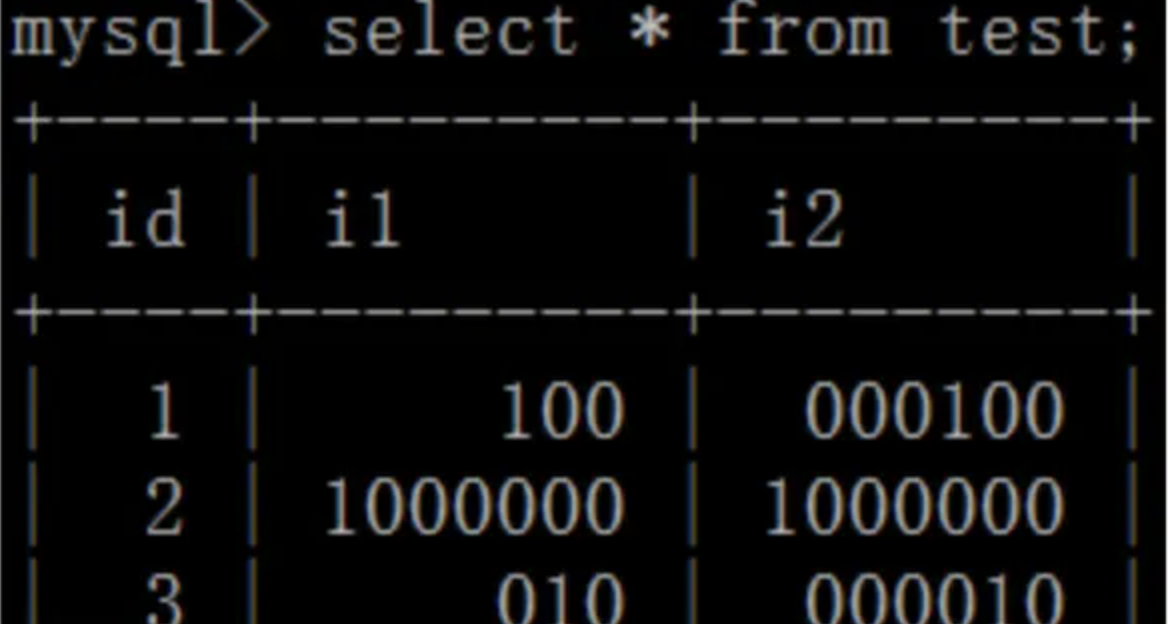
int存储大小和显示大小区别。.png
发现,无论是int(3), int(6), 都可以显示6位以上的整数。但是,当数字不足3位或6位时,前面会用0补齐。
也就是说,int的长度并不影响数据的存储精度,长度只和显示有关,为了让大家看的更清楚,我们在上面例子的建表语句中,使用了zerofill。
对比数据库char类型与varchar类型
char 不可变,查询效率高,可能造成存储浪费。例如手机号位数不可变,可设为char。
varchar 可变,查询效率不如char,节省空间
6,索引:主键 Primary Key 、外键 Foreign Key
作用:保证数据的完整性
到底用不用外键?
在开始创建项目的时候,可以让mysql外键来帮助维护这个完整性,但是数据量大的时候不建议用外键,原因是在删除和修改的时候,mysql有额外的开销来查看从表中是否有额外的数据。自己通过代码的方式,来修改其他表的数据,来保证数据完整。
7,引擎的选择:
常用的存储引擎有:InnoDB 、MYISAM
InnoDB存储引擎:
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,InnoDB是默认的MySQL引擎。
1,InnoDB给MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。
2,InnoDB是为处理巨大数据量的最大性能设计。它的CPU效率可能是任何其他基于磁盘的关系型数据库引擎锁不能匹敌的
3,InnoDB支持外键完整性约束
4,存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
5,InnoDB被用在众多需要高性能的大型数据库站点上
6,InnoDB不创建目录,使用InnoDB时,MySQL将在MySQL数据目录下创建一个名为ibdata1的10MB大小的自动扩展数据文件,以及两个名为ib_logfile0和ib_logfile1的5MB大小的日志文件
MyISAM存储引擎:
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物。
1、大文件(达到63位文件长度)在支持大文件的文件系统和操作系统上被支持
2、当把删除和更新及插入操作混合使用的时候,动态尺寸的行产生更少碎片。这要通过合并相邻被删除的块,以及若下一个块被删除,就扩展到下一块自动完成
3、每个MyISAM表最大索引数是64,这可以通过重新编译来改变。每个索引最大的列数是16
4、最大的键长度是1000字节,这也可以通过编译来改变,对于键长度超过250字节的情况,一个超过1024字节的键将被用上
5、每个MyISAM类型的表都有一个AUTO_INCREMENT的内部列,当INSERT和UPDATE操作的时候该列被更新,同时AUTO_INCREMENT列将被刷新。所以说,MyISAM类型表的AUTO_INCREMENT列更新比InnoDB类型的AUTO_INCREMENT更快
6、可以把数据文件和索引文件放在不同目录
使用MyISAM引擎创建数据库,将产生3个文件。文件的名字以表名字开始,扩展名之处文件类型:frm文件存储表定义、数据文件的扩展名为.MYD(MYData)、索引文件的扩展名时.MYI(MYIndex)
不同的存储引擎都有各自的特点,以适应不同的需求,如下表所示:
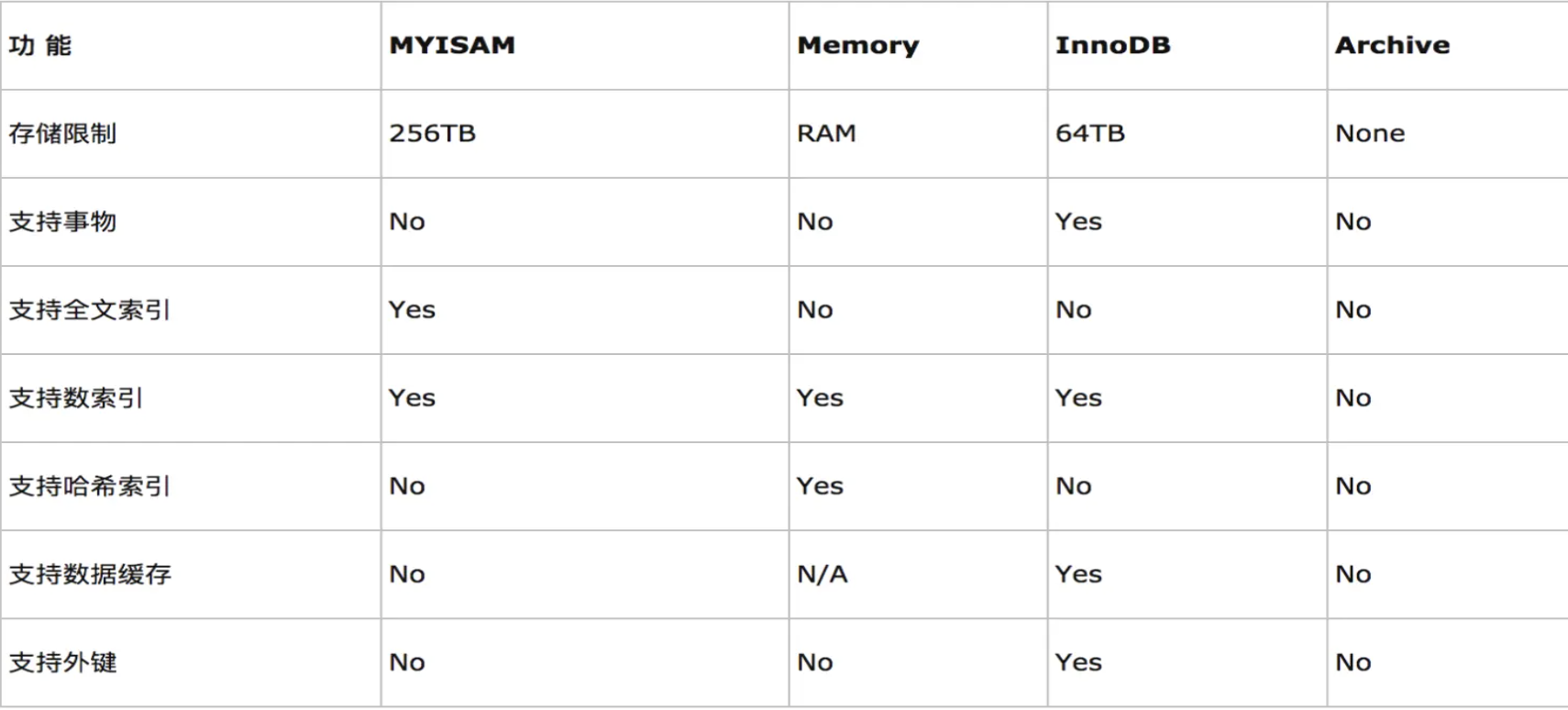
如果要提供提交、回滚、崩溃恢复能力的事物安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择。
如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率。
如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果。
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive。
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能
二:数据库高级使用:
1,复制集和分布式:
复制集(Replication):
数据库中数据相同,起到备份作用
高可用 High Available HA
分布式(Distribution):
数据库中数据不同,共同组成完整的数据集合
通常每个节点被称为一个分片(shard)
高吞吐 High Throughput
复制集与分布式可以单独使用,也可以组合使用(即每个分片都组建一个复制集)
关于主(Master)从(Slave):
这个概念是从使用的角度来阐述问题的
主节点 -> 表示程序在这个节点上最先更新数据
从节点 -> 表示这个节点的数据是要通过复制主节点而来
复制集 可选 主从、主主、主主从从
分布式 每个分片都是主,组合使用复制集的时候,复制集的是从
2,Mysql主从复制:
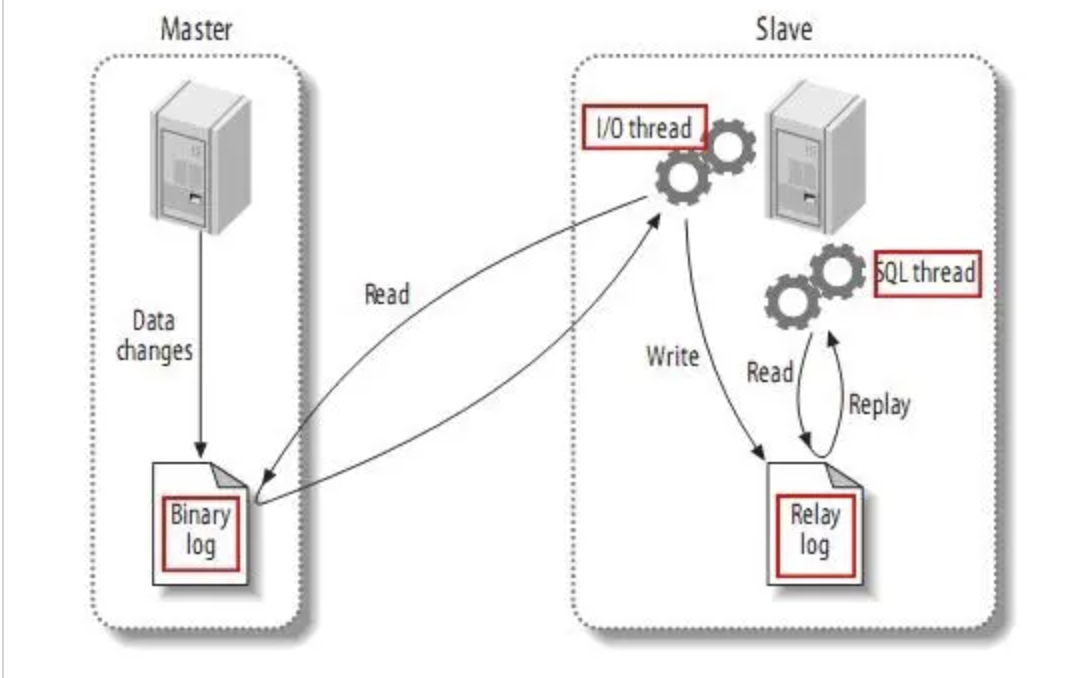
复制过程分为以下三步:也可以看图理解(重要)
master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
slave将master的binary log events拷贝到它的中继日志(relay log);
slave重做中继日志中的事件,将改变反映它自己的数据。
利用主从在达到高可用的同时,也可以通过读写分离提供吞吐量。
思考:读写分离对事务是否有影响?
对于写操作包括开启事务和提交或回滚要在一台机器上执行,分散到多台master执行后数据库原生的单机事务就失效了。
对于事务中同时包含读写操作,与事务隔离级别设置有关,如果事务隔离级别为read-uncommitted 或者 read-committed,读写分离没影响,如果隔离级别为repeatable-read、serializable,读写分离就有影响,因为在slave上会看到新数据,而正在事务中的master看不到新数据。
3,分库分表:
分库分表的顺序应该是先垂直分,后水平分。 因为垂直分更简单,更符合我们处理现实世界问题的方式。
为什么要进行分库分表?
用户请求量太大
单库太大
单表太大
分库分表面临的问题?
事务支持
分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
多库结果集合并(group by,order by)
跨库join
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
还有一些大公司的开源产品:

数据库对企业的重要性是毋庸置疑的,目前我国企业运用较多的是自行组建的数据库系统,但是随着企业业务量的增加和历史数据累积,自建数据库存储空间小、性能差、功能少、数据安全性低等问题日益凸显出来,已经不能满足企业用户对数据库的需求了。
如何解除传统自建数据库对企业发展的限制,便成了众多企业的当务之急。PingCAP专业研发团队通过对企业难点的深入了解,攻克技术难关,打造出一整套功能强大、性能全面的解决方案——PingCAP数据库。
行业挑战
数字化转型过程中数据价值变现的关键点:
多源应用的数据实时汇聚能力;
基于持续变化数据的管理模式;
持续/及时/高效获取“新鲜数据”;
多场景的灵活数据计算能力;
动态的数据加工与更新;
T + 0 实时数据服务化能力。
解决方案
TiDB 实时数据处理架构
支持多种数据采集方式,包括 CDC、消息中间件+流式计算框架的实时方式,及时、高效获得“新鲜数据”;
基于行、列混存的 HTAP 架构,提供实时数据服务,具备数字化转型中数据价值的实时变现能力。
TiDB + Flink 企业版(Ververica Platform)实时 HTAP 商业方案
数据处理速度有保障,TiBD 和 Flink 都可以通过水平扩展节点来增加算力 ;
用户可以单独使用 TiDB 构建实时分析业务,也可以与 Flink 生态一起构建实时的数仓体系 。 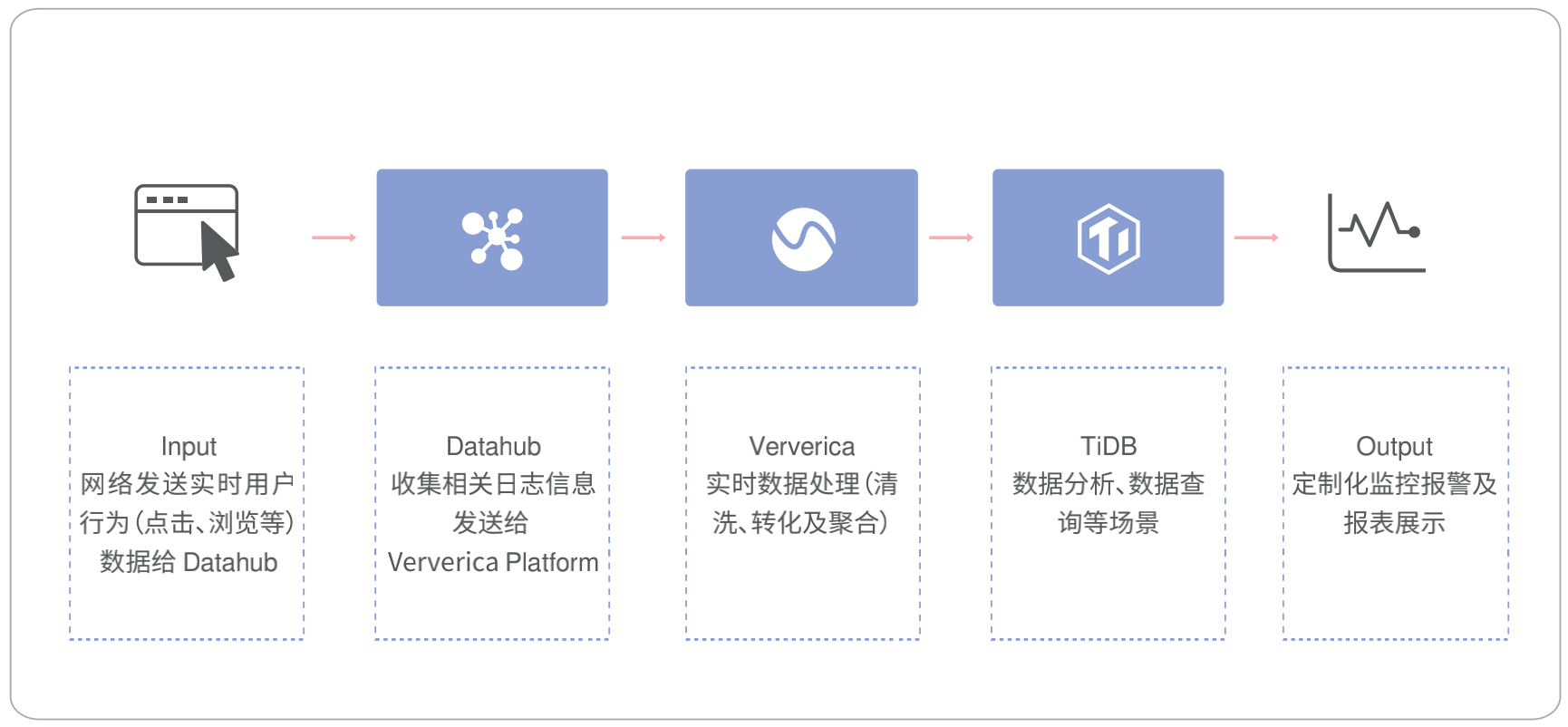
方案优势
一、灵活多样的准实时接入模式,简化中间集合,缩短传递链路,提高处理时效。
二、简化技术栈,实时 HTAP,流批一体化。
三、HTAP 架构兼顾实时分析领域的高并发访问和交互式分析诉求。
上文就是小编为大家整理的万能数据库,你了解多少?面试必备!!!全能数据库管理工具。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

