

黄东旭解析 TiDB 的核心优势
878
2023-06-27
本文讲了窥探TiDB架构,如何做到Real-time HTAP,Real-time HTAP。
架构图组件
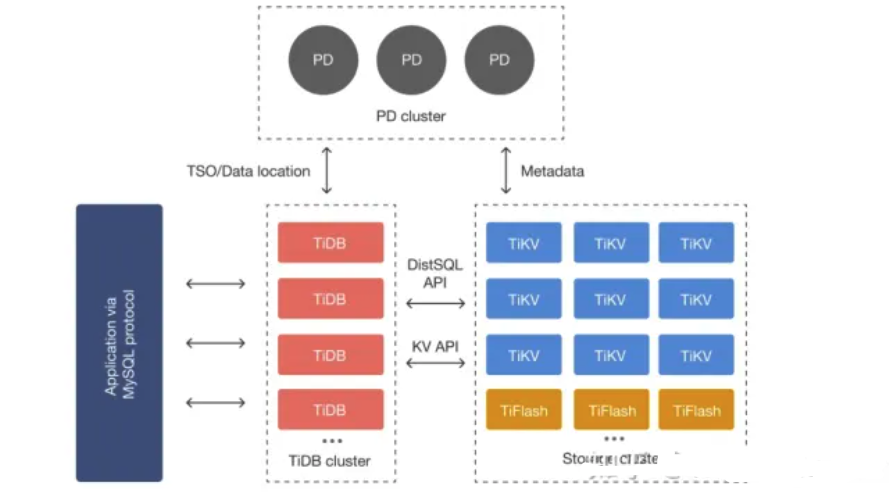
TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
存储节点
TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
PD(Placement Driver) Server
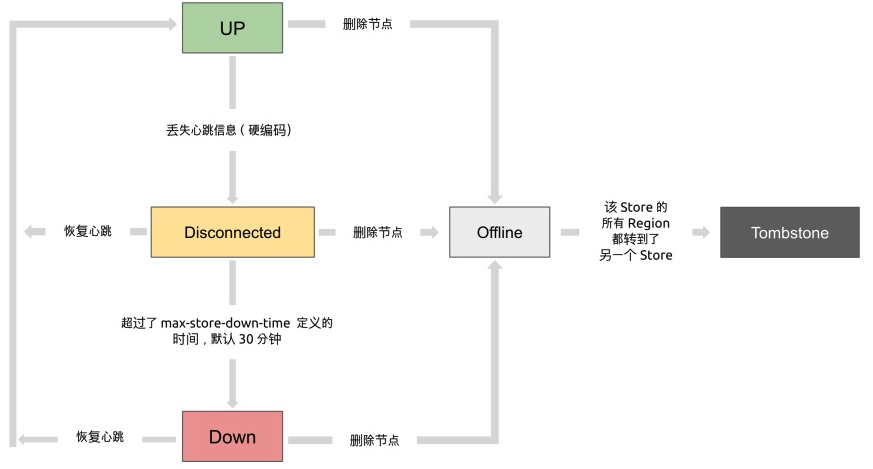
个人笔记
PD 承担着核心调度功能,负载节点的上下线、收集region信息以及负载均衡数据
个人经验
个人在生产遇到过,因为Raid盘发生损坏,节点置于offline状态,数据需要均衡到其他节点,这个数据量很大的时候,数据均衡很慢,同时生产集群读写性能下降明显,大概均衡了一晚上数据,才恢复整体性能,所以TIDB数据容量规划,冗余存储和日常巡检时也要关注这方便,如果文件过多,后续如果出现节点故障,数据均衡,性能恢复也是很大开销。
TIDB Server
用户的 SQL 请求会直接或者通过 Load Balancer 发送到 TiDB Server,TiDB Server 会解析 MySQL Protocol Packet,获取请求内容,对 SQL 进行语法解析和语义分析,制定和优化查询计划,执行查询计划并获取和处理数据。数据全部存储在 TiKV 集群中,所以在这个过程中 TiDB Server 需要和 TiKV 交互,获取数据。最后 TiDB Server 需要将查询结果返回给用户。
优化器的工作
优化器 个人有个留意点,如果在使用tidb 引入了TiFlash ,优化器的好坏决定了 上游的一个SQL 请求 是否采用TiKV 还是TiFlash ,如果本应该是分析查询,落在TiKV 上 会很影响整个集群性能,这个感觉很考验Tidb 优化器的功底
当然 TIDB也支持 手动指定和hint方式来人工干预 使用哪种引擎来查询
TiKV Server

key 的设计
根据文档中描述,tidb的key的设计,来满足主键以及索引需求,个人感觉和phoenix至于hbase 有些类似的思想在里面。

个人笔记
底层采用RocksDB , 数据 key value 存储
Region 为数据存储单位,
使用Raft 算法保证Region数据复制,一致性
key 的设计逻辑 ,见图片
MVCC 事务基于 Percolator 论文 实现
事务
这块不算架构图中的组件,但是我觉得很有必要去深入了解下,以及TIDB对MVCC(多版本并发控制)的实现。
乐观事务模型下,将修改冲突视为事务提交的一部分。因此并发事务不常修改同一行时,可以跳过获取行锁的过程进而提升性能。但是并发事务频繁修改同一行(冲突)时,乐观事务的性能可能低于悲观事务。
乐观事务流程

悲观事务流程
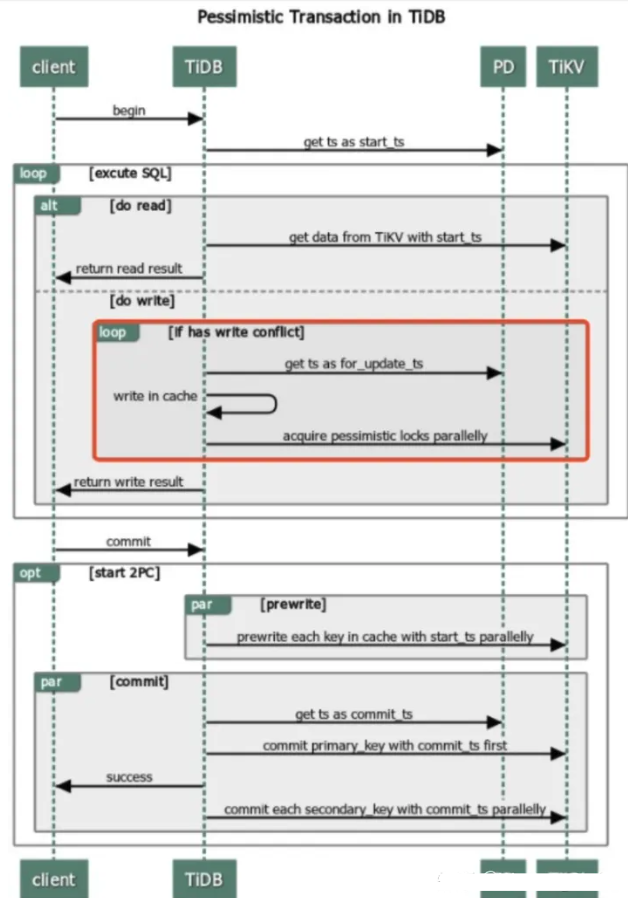
个人笔记
v3.0.8之前默认是乐观事务,当前默认是悲观事务, 乐观事务,程序要能够自身正确处理因commit返回的错误
如果同一行数据,频繁更新,不建议使用乐观事务,性能可能低于悲观事务
悲观事务,为了提高吞吐降低延迟,存在内存悲观锁,默认开启,集群特殊异常情况下,会丢失锁,如果介意,可以考虑关闭
TIDB 悲观锁 不支持间隙锁
TiFlash
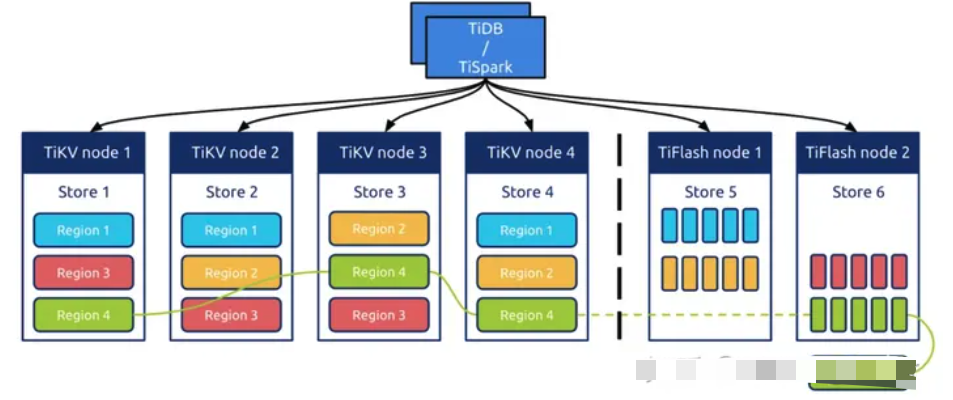
异步复制
TiFlash 中的副本以特殊角色 (Raft Learner) 进行异步的数据复制。这表示当 TiFlash 节点宕机或者网络高延迟等状况发生时,TiKV 的业务仍然能确保正常进行。 这套复制机制也继承了 TiKV 体系的自动负载均衡和高可用:并不用依赖附加的复制管道,而是直接以多对多方式接收 TiKV 的数据传输;且只要 TiKV 中数据不丢失,就可以随时恢复 TiFlash 的副本。
一致性
TiFlash 提供与 TiKV 一样的快照隔离支持,且保证读取数据最新(确保之前写入的数据能被读取)。这个一致性是通过对数据进行复制进度校验做到的。 每次收到读取请求,TiFlash 中的 Region 副本会向 Leader 副本发起进度校对(一个非常轻的 RPC 请求),只有当进度确保至少所包含读取请求时间戳所覆盖的数据之后才响应读取。
智能选择
TiDB 可以自动选择使用 TiFlash 列存或者 TiKV 行存,甚至在同一查询内混合使用提供最佳查询速度。这个选择机制与 TiDB 选取不同索引提供查询类似:根据统计信息判断读取代价并作出合理选择。
计算加速
TiFlash 对 TiDB 的计算加速分为两部分:列存本身的读取效率提升以及为 TiDB 分担计算。其中分担计算的原理和 TiKV 的协处理器一致:TiDB 会将可以由存储层分担的计算下推。能否下推取决于 TiFlash 是否可以支持相关下推。
个人笔记
基于Raft 算,增加Raft Learner 角色,进行TiFlash 数据异步复制,保证副本的一致性和高可用,具体逻辑可以看最上面,tidb 的那边论文。
列式存储,TiFlash 是构建在 *** 之上,所以OLAP的特性 可以参考***
感受篇
开源生态:个人主观上的感受,TIDB 属于国内技术文档写的很棒的,事无巨细,同时开源社区也维护的很好,相当活跃。整体核心组件都有放在github上开源,真正践行了用开源驱动商业的案例。
同时TIDB的本身也还是借鉴了Google经典论文F1和Spanner思想,同时基础组件上也使用了很多优秀的开源组件,比如RocksDB, ***, gRpc等,这里面每个组件,都值得我们花时间去了解,学习。
这个报告主体上分为5个章节,分别是:
背景介绍。
HTAP Databases:分享最新的 HTAP 数据库技术,总结它们主要的应用场景与优缺点,并根据存储架构对它们进行分类。
HTAP Tecniques:介绍主流的 HTAP 数据库关键技术,包括事务处理技术、查询分析技术、数据组织技术、数据同步技术、查询优化技术以及资源调度技术等。
HTAP Benchmarks:介绍目前现有的主流 HTAP 基准测试。
Challenges and Open Problems:讨论 HTAP 技术未来的研究方向与挑战。
本文仅作精选分享,会省略一些非必要内容,如想了解更多,请阅读原报告。
背景介绍
1Motivation
开头还是一个老生常谈的 HTAP 起源动机问题,这个其实大家看过我们之前的文章 《什么是真正的HTAP?背景篇》 ,也就很清楚了:HTAP(Hybrid Transactional/Analytical Processing)的概念和定义是 Gartner 在 2014 年第一次给出的,注意,这里特别提到了 in-memory技术,在其定义中,HTAP 是通过 内存计算技术在 同一份内存数据上同时支持事务和分析的处理。
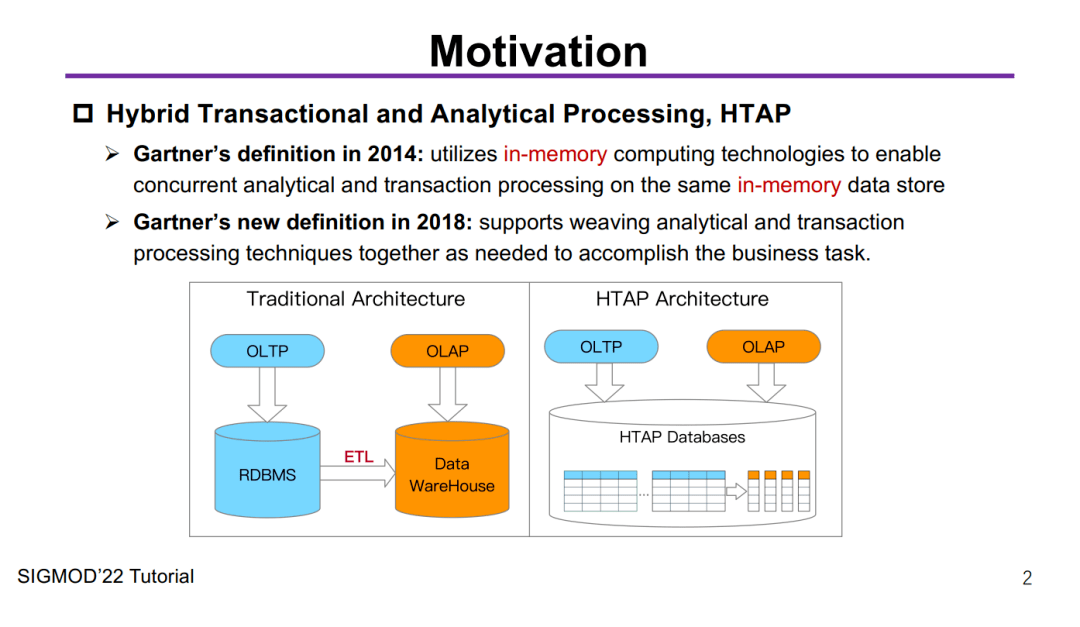
Motivation
如上图所示,左边是传统架构,要做OLAP必须先得把OLTP的数据通过ETL导过去,很麻烦,复杂度高、延迟高、运维难度大,总之一系列水深问题,一般人把握不住。
但是右边的HTAP架构就很酷了,我一个数据库采用行列共存的方式,同时进行事务和分析的处理,So easy,老板再也不用担心我做个BI报表需要“ T+1”甚至“ T+N”了 ,数据一进来就能做到实时地分析,没错,这就是我们常说的 Real-Time。

Gartner envisioned that, HTAP techniques will be widely adopted in the business applications with real-time data analytics by 2024.
Gartner 预计 HTAP 这个技术将会在 2024 年被需要实时分析的商业应用广泛采用,因为它在很多行业都有应用场景,包括电商、财务、银行和风控等等。这里举两个栗子:
在购物节这种高并发的情形下,如果电商卖家能够实时地分析用户行为数据,并根据分析结果针对性地投放品类广告,这无疑会给卖家带来更多的收益。
银行在线上处理用户事务时还能实时地分析数据,从而检测判断该用户及其行为是否异常或者存在风险,这会让风控系统更加智能化。
实现上述的应用,HTAP 技术就是不可或缺的基础设施底座。
可以看到,过去10年里,HTAP数据库不断涌现,本篇报告作者这里根据 HTAP 数据库发展时间线梳理成三个阶段:
第一阶段(2010-2014):HTAP 数据库主要是采用主列存(primary column store)的方式。如SAP HANA、HyPer、***和BLU等。
第二阶段(2014-2020):HTAP 数据库主要是扩展了以前主行存的技术,在行存上加上了列存。如***,***和L-store等。
第三阶段(2020-present):HTAP 数据库主要是开启了分布式的架构实现,满足高并发的请求。如SingleStore、MySQL Heatwave和Greenplum等。
PS:StoneDB 属于第三阶段,是具有分布式架构、内存计算和行列混存的HTAP数据库。
在数据库领域,有两个公认的经验法则:
行存(Row Store):比较适合OLTP。
Row-wise,update-heavy(重更新),short-lived transactions(短时延事务)
列存(Column Store):比较适合OLAP。
column-wise,read-heavy,bandwidth-intensive queries(带宽敏感查询)
在本篇报告主要研究采用行列共存的HTAP数据库。
2A trade-off for HTAP databases
HTAP 数据库也有需要解决的问题,正所谓鱼和熊掌不可兼得,很多时候我们需要找到一个权衡点,既然是权衡,就有天平的两端,在HTAP数据库领域里,主要讨论的是 工作负载隔离(Workload isolation)和 数据新鲜度(Data freshness)这两个重要特性的权衡。
工作负载隔离,就是指OLTP和OLAP之间的负载隔离程度;数据新鲜度,就是指OLAP到底能读到多新的事务性数据。
从现有的观测数据来看:
高的工作负载隔离会导致较低的数据新鲜度
低的工作负载隔离会获得较高的数据新鲜度

Trade-off for workload isolation and data freshness
这里关于Trade-off的相关思考我们之前在对外的分享会上也屡次提及,感兴趣的同学可以前往B站观看我们最近一期的线上Meetup视频:
视频地址:https://m.bilibili.com/video/BV1jB4y1577G
3Challenges for HTAP databases
作者这里提出了HTAP数据库面临的四大挑战,这里也和我们的第二篇文章 《什么是真正的HTAP?挑战篇》 里的观点不谋而合,可以说完全在我们提出的8点挑战范围之内:
挑战一: 数据组织(Data Organization)
挑战二: 数据同步(Data Synchronization)
挑战三: 查询优化(Query Optimization)
挑战四: 资源调度(Resource Scheduling)

Challenges for HTAP databases
HTAP 数据库
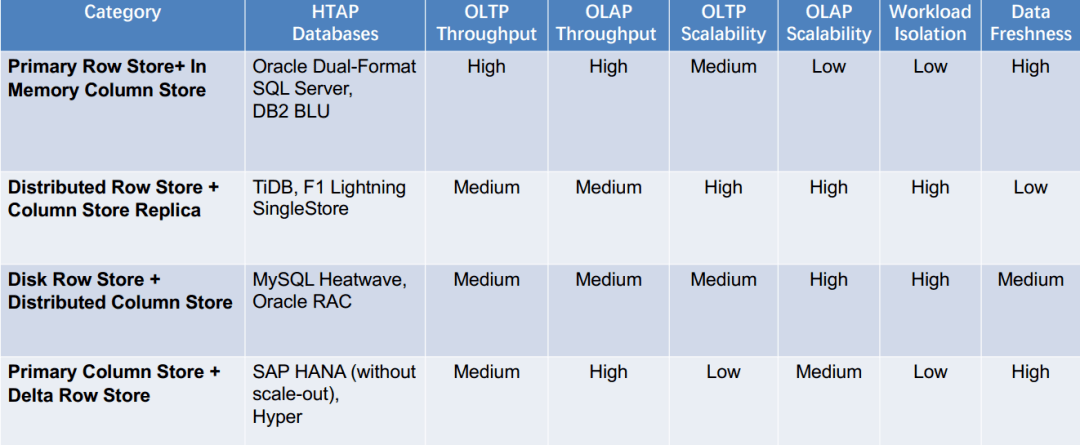
这一章节主要调研现有 HTAP 数据库的主要架构,作者这里分成了四大架构:
主行存储+内存中列存储(Primary Row Store + InMemory Column Store)
分布式行存储+列存储副本(Distributed Row Store + Column Store Replica)
磁盘行存储+分布式列存储(Disk Row Store + Distributed Column Store)
主列存储+增量行存储(Primary Column Store + Delta Row Store)
1 主行存储+内存中列存储
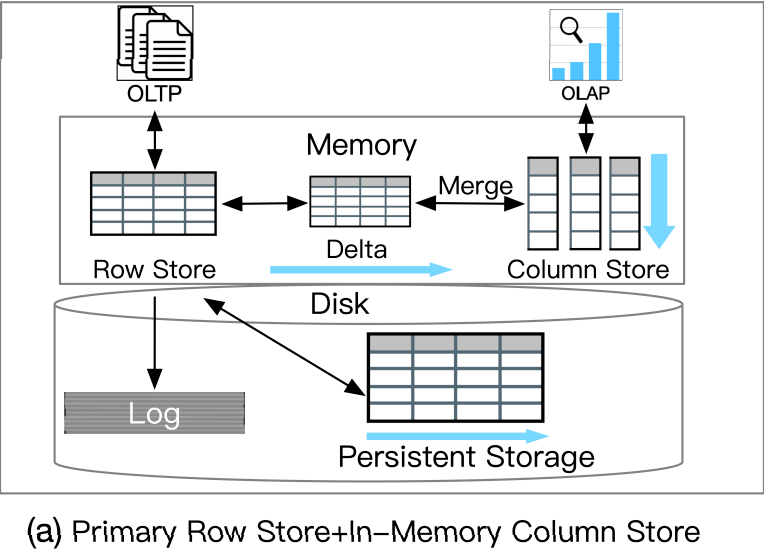
主行存储+内存中列存储
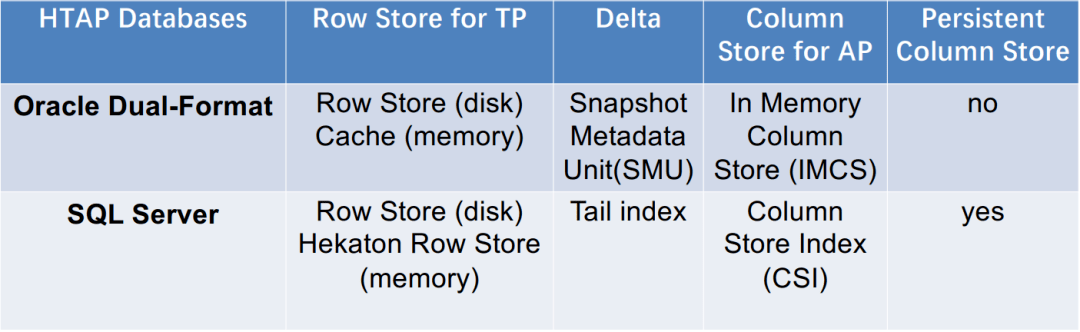
这类 HTAP 数据库利用主行存储作为 OLTP 工作负载的基础,并使用内存列存储处理 OLAP 工作负载。所有数据都保存在主行存储中。行存储也是内存优化的,因此可以有效地处理数据更新。更新也会附加到增量存储中,增量存储将合并到列存储中。例如,*** 内存双格式数据库结合了基于行的缓冲区和基于列的内存压缩单元 (IMCU) 来一起处理 OLTP 和 OLAP 工作负载。文件和更改缓存在快照元数据单元 (SMU) 中。另一个例子是 ***,它在 Hekaton 行引擎中的内存表上开发了列存储索引 (CSI),以实现实时分析处理。这种类型的 HTAP 数据库具有高吞吐量,因为所有工作负载都在内存中处理。
优势:
TP 吞吐量高
AP 吞吐量高
数据新鲜度高
劣势:
AP 扩展能力低
负载隔离性低
应用:
高吞吐、低扩展(比如需要实时分析的银行系统)
案例研究1:*** Dual-Format
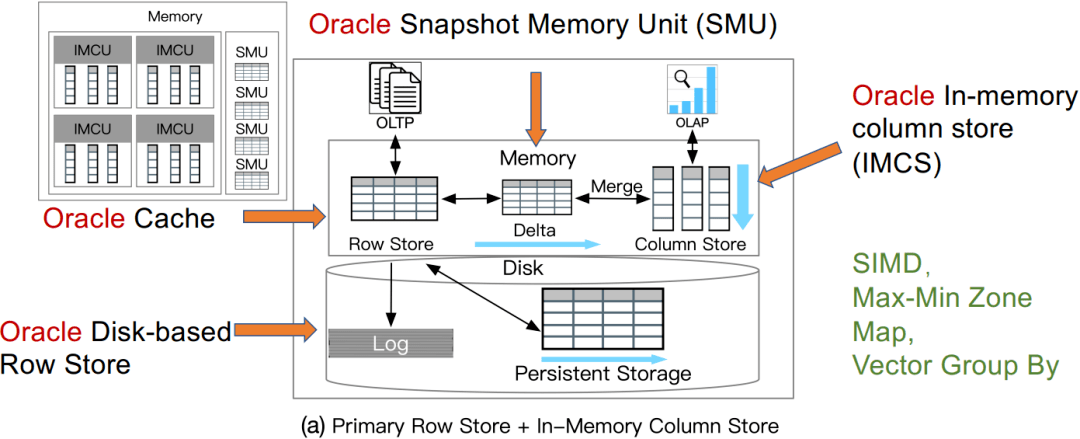
Lahiri, Tirthankar, et al. "*** database in-memory: A dual format in-memory database." In ICDE, 2015.
SIMD:单指令多数据
Max-Min Zone Map
Vector Group By:向量化
案例研究2:***
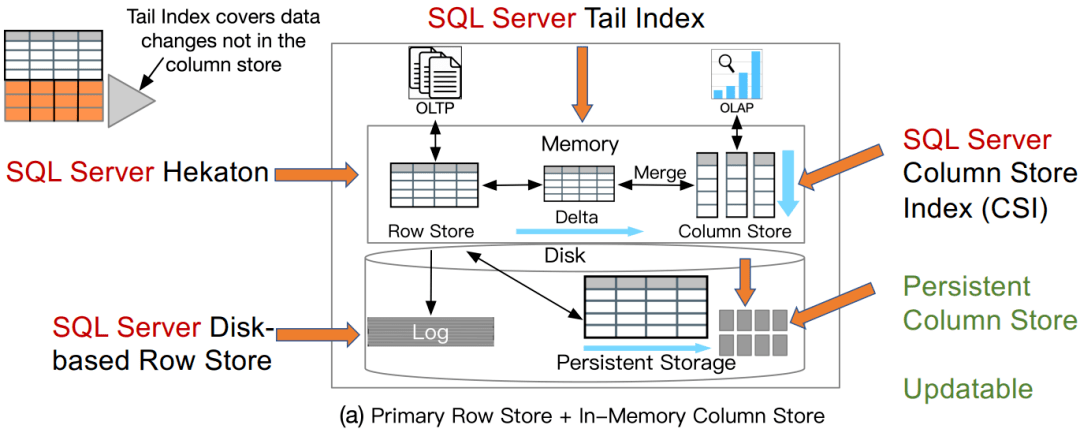
Larson, Per-Åke, et al. "Real-time analytical processing with SQL server.” PVLDB 8(12), 2015: 1740-1751.
Persistent Column Store:持久化列存
Updatable:可更新
总结
架构(a)的两个HTAP数据库对比 2分布式行存储+列存储副本
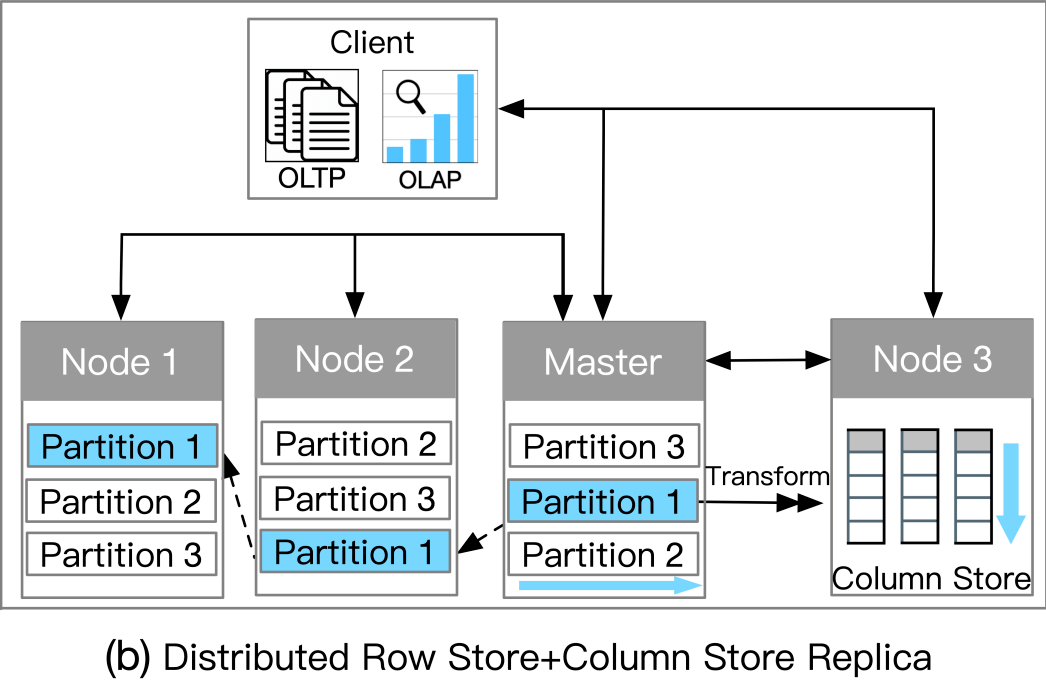
分布式行存储+列存储副本
此类别依赖于分布式架构来支持 HTAP。主节点在处理事务请求时将日志异步复制到从节点。主存储为行存储,选择一些从节点作为列存储服务器进行查询加速。事务以分布式方式处理以实现高可扩展性;复杂查询在具有列存储的服务器节点中执行。
优势:
负载隔离性高
扩展性高
劣势:
数据新鲜度低
应用:
对TP和AP扩展性要求比较高,同时能够容忍相对较低的数据新鲜度(比如需要实时分析的大规模电商系统)
案例研究:F1 Lightning
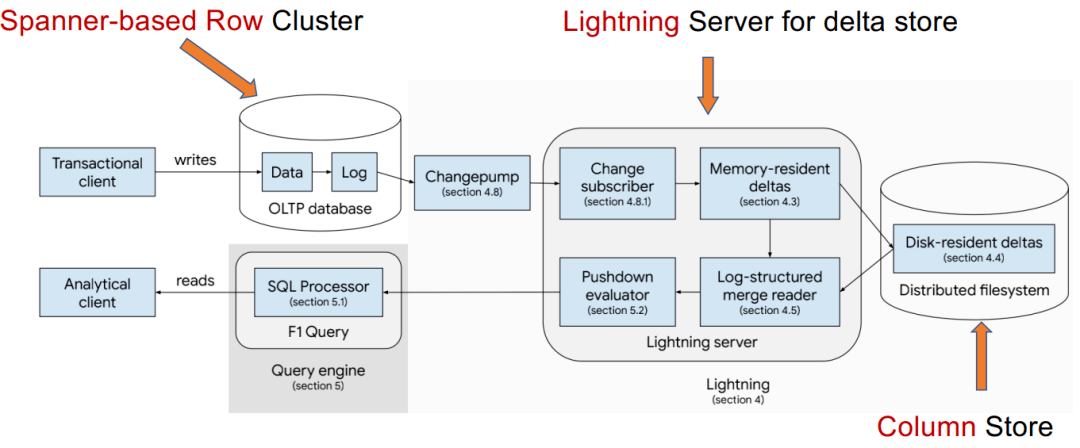
Yang, Jiacheng, et al. "F1 Lightning: HTAP as a Service." PVLDB 13(12), 2020: 3313-3325. 总结架构(b)的两个HTAP数据库对比 3磁盘行存储+分布式列存储
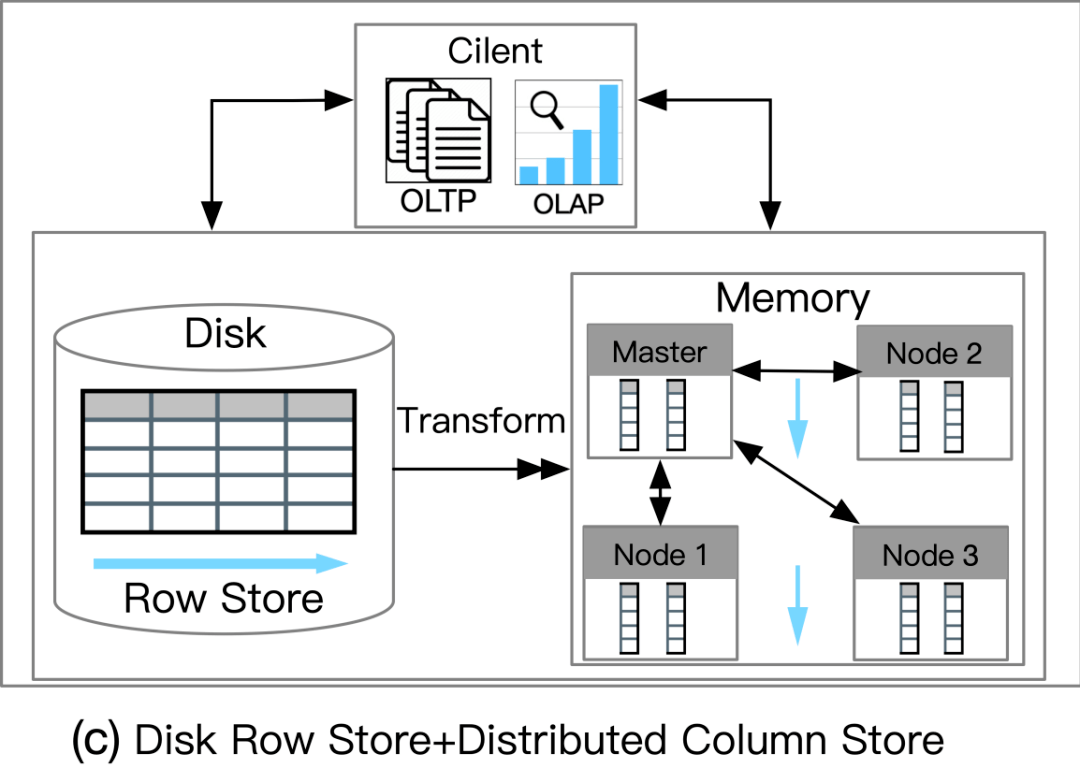
磁盘行存储 + 分布式列存储
这种数据库利用基于磁盘的 RDBMS 和分布式内存列存储 (IMCS) 来支持 HTAP。RDBMS 保留了 OLTP 工作负载的全部容量,并且深度集成了 IMCS 集群以加速查询处理。列数据从行存储中提取,热数据驻留在 IMCS 中,冷数据将被驱逐到磁盘。例如,MySQL Heatwave将 MySQL 数据库与称为 Heatwave 的分布式 IMCS 集群相结合,以实现实时分析。事务在 MySQL 数据库中完全执行。经常访问的列将被加载到 Heatwave。当复杂查询进来时,可以下推到IMCS引擎进行查询加速。
优势:
负载隔离性高
AP吞吐量和扩展性高
劣势:
数据新鲜度不高
Medium(On-premise):部署在本地,在不同机器上会有数据新鲜度的牺牲
Low(Cloud-based):部署在云端,网络延迟会影响数据新鲜度
应用:
对AP扩展性要求比较高,同时能够容忍相对较低的数据新鲜度(比如需要实时分析的IoT应用)
案例研究1:MySQL Heatwave
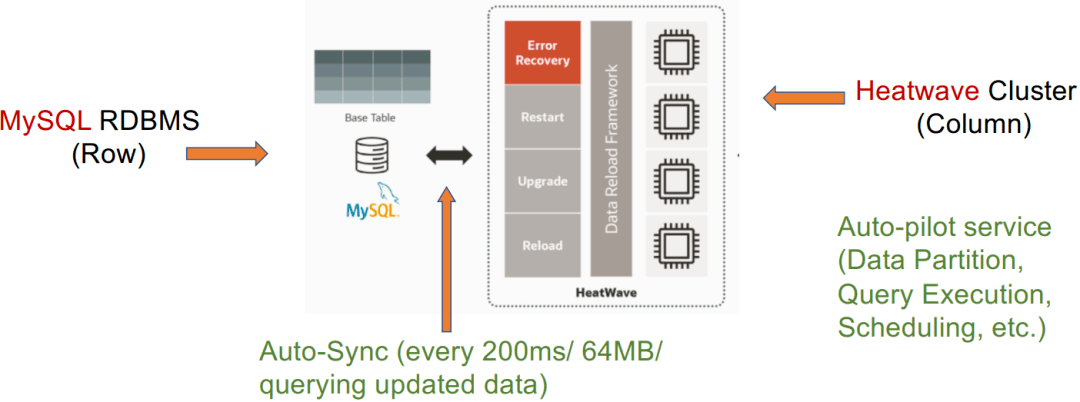
MySQL Heatwave. Real-time Analytics for MySQL Database Service, August 2021, Version 3.0
Auto-pilot service:自动调优(一些云服务,可以在系统中自动帮客户实现数据分区、查询优化和资源调度等等)
Auto-Sunc:自动同步(可实现定时定量同步数据)
案例研究2:*** RAC
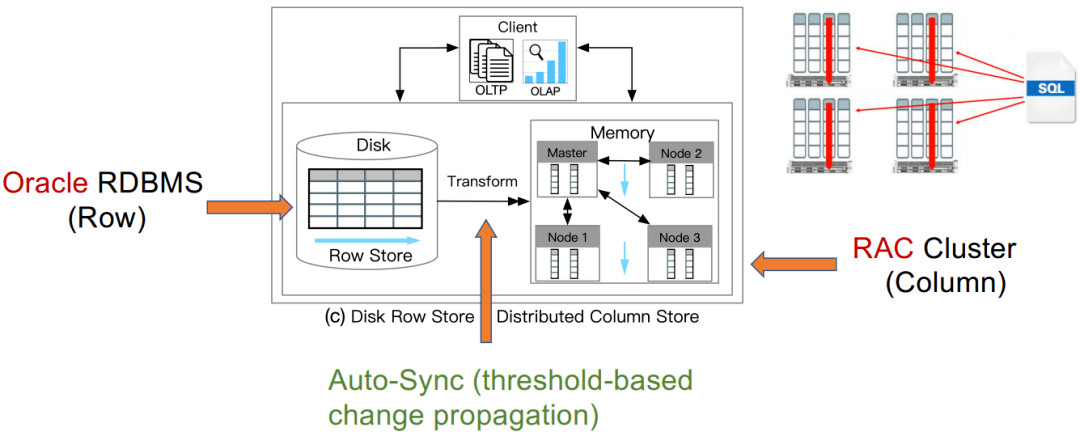
Lahiri, Tirthankar, et al. "*** database in-memory: A dual format in-memory database." In ICDE, 2015.
Auto-Sunc:自动同步(基于阈值的方式)
总结
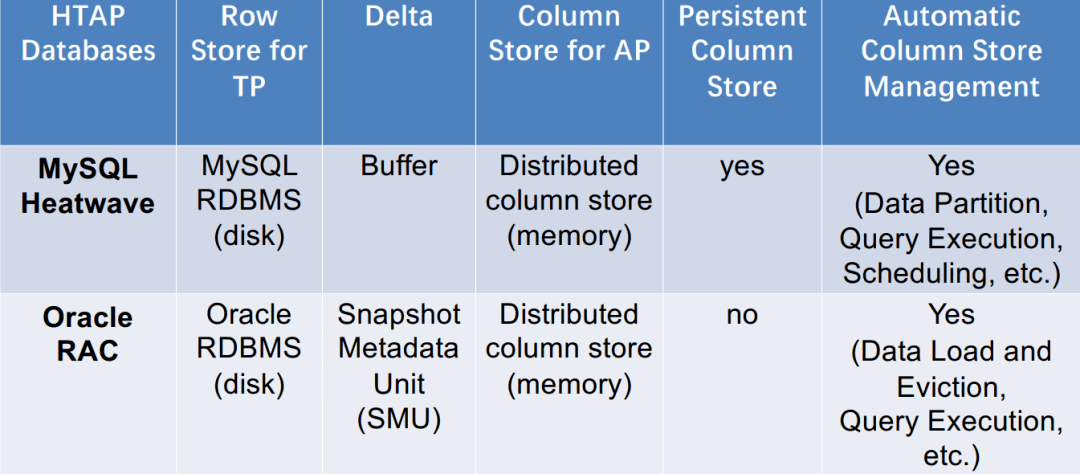
架构(c)的两个HTAP数据库对比 4主列存储+增量行存储

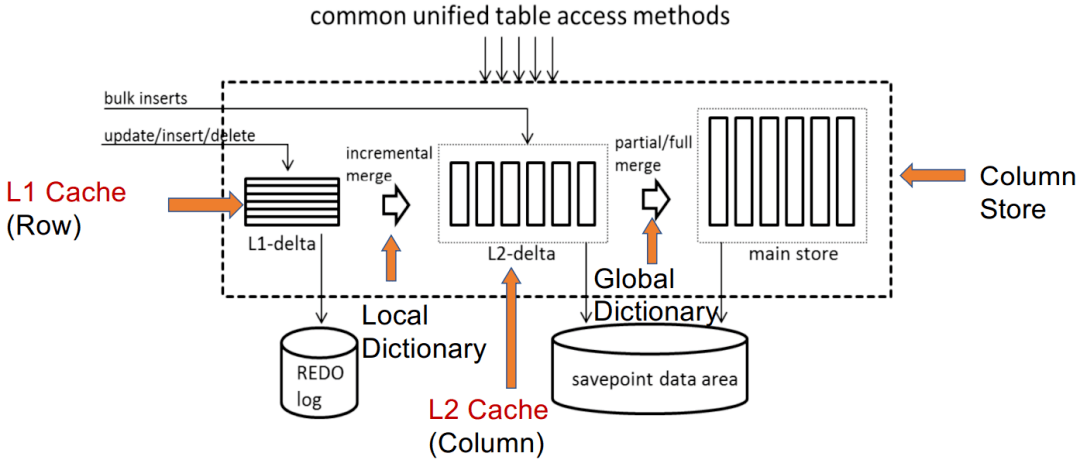
主列存储+增量行存储
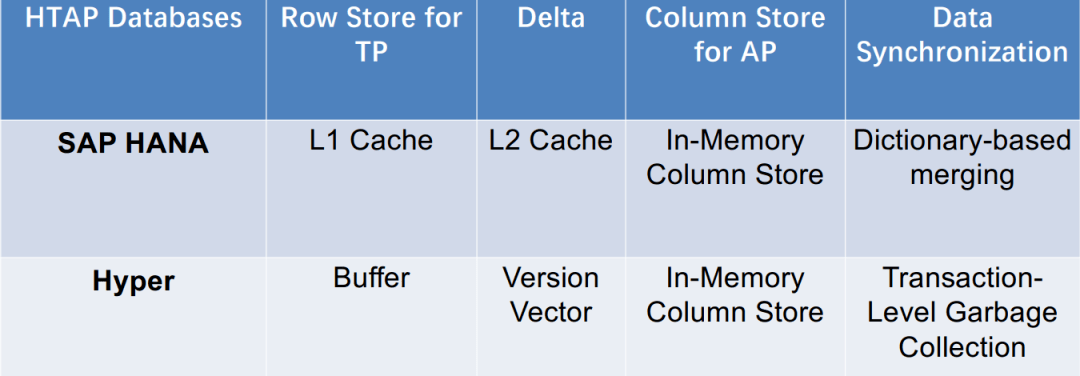
此类数据库利用主列存储作为 OLAP 的基础,并使用增量行存储处理 OLTP。内存中的 delta-main HTAP 数据库将整个数据存储在主列存储中。数据更新附加到基于行的增量存储。OLAP 性能很高,因为列存储是高度读取优化的。但是,由于 OLTP 工作负载只有一个增量行存储,因此 OLTP 的可伸缩性很低。一个代表是 SAPHANA 。它将内存中的数据存储分为三层:L1-delta、L2-delta 和 Main。L1-delta以逐行格式保持数据更新。当达到阈值时,将 L1-delta 中的数据附加到 L2-delta。L2-delta 将数据转换为列数据,然后将数据合并到主列存储中。最后,将列数据持久化到磁盘存储。
优势:
数据新鲜度高
AP吞吐量高
劣势:
TP可扩展性不高
负载隔离性不高
应用:
高AP吞吐量、高数据新鲜度(比如需要实时分析的风控系统)
案例1:SAP HANA
Sikka, Vishal, et al. "Efficient transaction processing in SAP HANA database: the end of a column store myth.” In SIGMOD. 2012. 案例2:Hyper(Column)
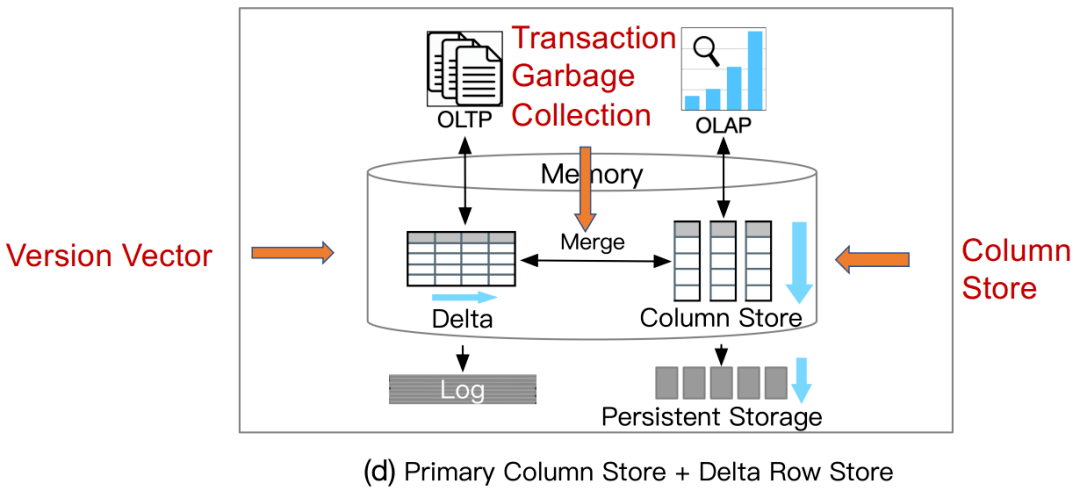
Neumann, Thomas, Tobias Mühlbauer, and Alfons Kemper. "Fast serializable multi-version concurrency control for main-memory database systems." In SIGMOD ,2015. 总结
架构(d)的两个HTAP数据库对比 5四种架构HTAP数据库的对比
HTAP 相关技术
HTAP的相关技术包括(1)事务处理;(2)分析处理;(3) 数据同步;(4) 查询优化;(5)资源调度。这些关键技术被最先进的 HTAP 数据库采用。然而,它们在各种指标上各有利弊,例如效率、可扩展性和新鲜度等等。
这个部分我们留到下一篇文章再做讨论。
中国人主导编程语言列表 Apache OpenOffice下载量超3.33亿 ,Windows平 台独占3亿 微软有史以来最大的软件产品:超36斤的C/C++编译器
上文就是小编为大家整理的窥探TIDB架构,如何做到Real-time HTAP,Real-time HTAP。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

