

黄东旭解析 TiDB 的核心优势
1657
2023-06-27
本文讲述了什么是 MultiRaft,multiraft 数据摆放。
什么是 MultiRaft
这里引用 Cockroach ( MultiRaft 的先驱,出来的比 TiDB 早 )对 MultiRaft 的定义:
In CockroachDB, we use the Raft consensus algorithm to ensure that your data remains consistent even when machines fail. In most systems that use Raft, such as etcd and Consul, the entire system is one Raft consensus group. In CockroachDB, however, the data is divided into ranges, each with its own consensus group. This means that each node may be participating in hundreds of thousands of consensus groups. This presents some unique challenges, which we have addressed by introducing a layer on top of Raft that we call MultiRaft.
在 CockroachDB 中,我们使用 Raft 一致性算法来确保在机器发生故障时数据也能保持一致。在大多数使用 Raft 的系统中,如 etcd 和 Consul,整个系统只有一个 Raft 共识组。然而,在 CockroachDB 中,数据被分成不同的范围,每个范围都有自己的共识组。这意味着每个节点都可能参与成千上万个共识组。这就提出了一些独特的挑战,我们通过在 Raft 之上引入一层 MultiRaft 来解决这些问题。
简单来说,MultiRaft 是在整个系统中,把所管理的数据按照一定的方式切片,每一个切片的数据都有自己的副本,这些副本之间的数据使用 Raft 来保证数据的一致性,在全局来看整个系统中同时存在多个 Raft-Group,就像这个样子:
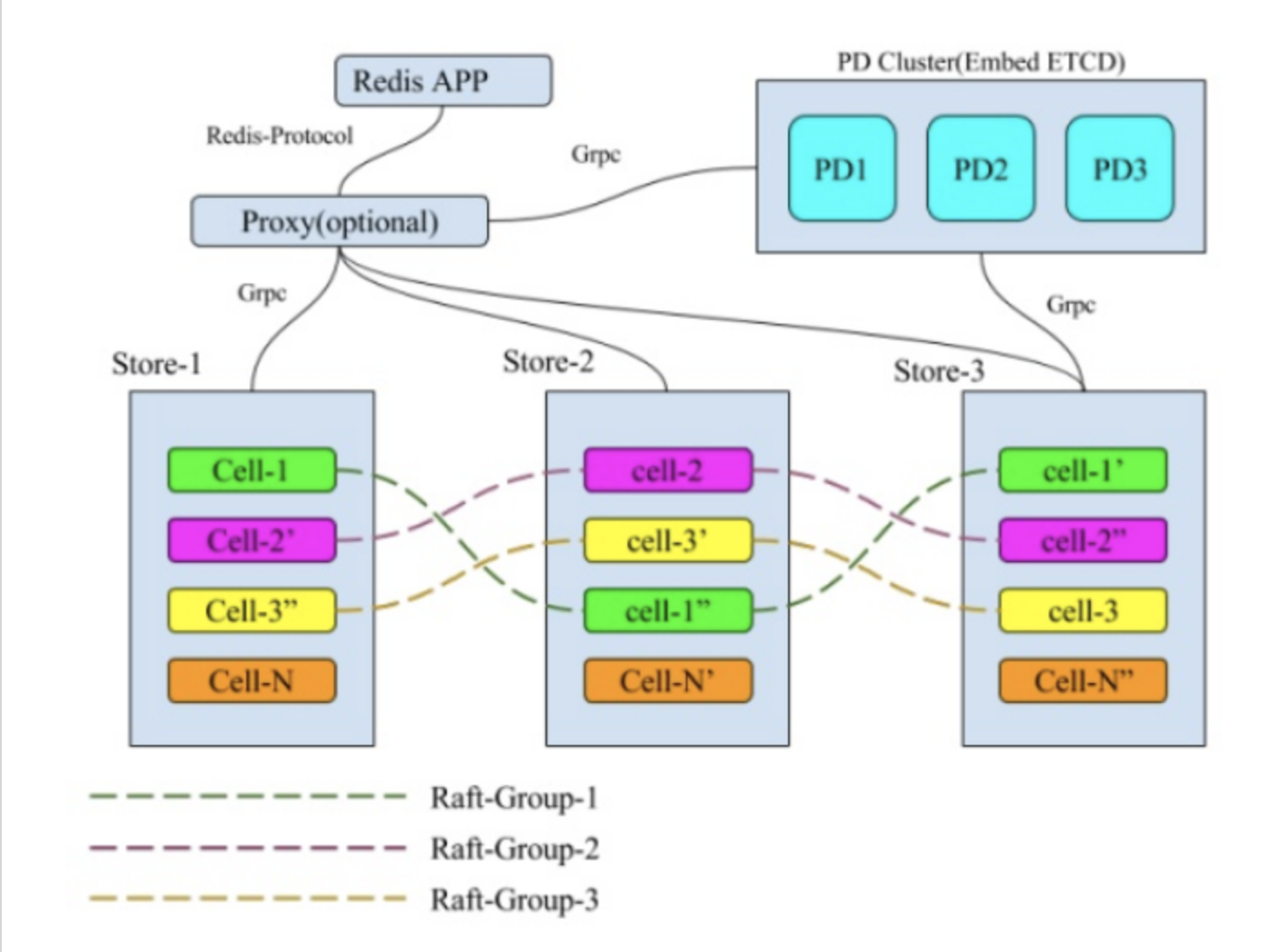
MultiRaft 需要解决的问题
单个 Raft-Group 在 KV 的场景下存在一些弊端:
(1) 系统的存储容量受制于单机的存储容量(使用分布式存储除外)。
(2) 系统的性能受制于单机的性能(读写请求都由Leader节点处理)。
MultiRaft 需要解决的一些核心问题:
(1) 数据何如分片。
(2) 分片中的数据越来越大,需要分裂产生更多的分片,组成更多 Raft-Group。
(3) 分片的调度,让负载在系统中更平均(分片副本的迁移,补全,Leader 切换等等)。
(4) 一个节点上,所有的 Raft-Group 复用链接(否则 Raft 副本之间两两建链,链接爆炸了)。
(5) 如何处理 stale 的请求(例如 Proposal 和 Apply 的时候,当前的副本不是 Leader、分裂了、被销毁了等等)。
(6) Snapshot 如何管理(限制Snapshot,避免带宽、CPU、IO资源被过度占用)。
要实现一个 Multi-Raft 还是很复杂和很有挑战的一件事情。
背景
作为近期Hadoop社区的明星项目,Hadoop Ozone吸引了社区广泛的关注。它脱胎于HDFS,不仅同时支持文件系统和对象语义,能原生对接HDFS和S3两种访问模式,也将集群的读写性能和吞吐量视为重中之重。2019年年中,***大数据团队开始上线Ozone集群承接大数据存储业务,数据湖小组也全力投入了Hadoop Ozone的开源项目中。在与Hadoop Ozone社区和Cloudera深度合作后,数据湖小组凭借在开源界多年的深耕和数据平台的业务对接实战经验,逐渐发现Ozone写入性能显现出了一定的波动和瓶颈,针对性设计了重点的新特性和优化来解决这些问题,同时也将这些特性回馈给了社区。此次介绍的Multi-Raft特性就是其中的重头戏。
Ozone的结构中保留了原先HDFS中的 DataNode数据节点,不过将管理元数据的NameNode分拆成了Ozone Manager(处理用户请求和响应)和Storage Container Manager(管理数据pipeline,container等资源)。数据节点上从原先的Block管理数据转变成了Container管理,同时也采用了更为轻量的Raft协议管理元数据和数据的一致性。Ozone Manager和Storage Container Manager放在了性能更好的RocksDB内管理,大大增加了集群Scale Out的能力,在架构上突破了原先HDFS元数据瓶颈的限制,同时也通过Raft增加了元数据管理节点standBy的个数,增强了集群可用性。
元数据管理的增强也意味着数据节点可以被更好地利用,于是,在HDFS上为人津津乐道的数据节点DataNode的吞吐量优化问题,在Ozone集群上也成了焦点问题。互联网各大厂对于HDFS DataNode数据吞吐量的优化各有十八般武艺:某大厂利用C++重写了一套HDFS,不仅扩展了DataNode吞吐量,也让一个NameNode可以管理超过7万个DataNode;还有大厂选择优化Linux的cache排队机制,优化Linux底层分配内存时page allocation的效率,达到增大写盘带宽的效果,从而增大DataNode的吞吐量。
但这些方案都仅限于公司内部高度定制化的方案,无论是后期维护,还是合入开源社区新的改动升级等方面都造成了新的障碍。***作为大面积使用Hadoop Ozone的第一家大厂,在选择Ozone的优化方案时优先考虑了社区友好的策略。
Ozone利用了Raft协议作为集群一致性协议,写数据时通过DataNode Raft Leader同步到Follower的方式确保多副本写入,读数据时只需要读到任意副本都可以返回结果,从而达到强一致的读写语义。在考虑调优DataNode性能时,我们把目光集中到了Raft Pipeline上,在一系列的测试后,我们发现之前Ozone对数据Pipeline和Raft的使用并没有使得磁盘处于高效运转的状态,于是设计了Multi-Raft的功能,可以让单个数据节点上承载尽量多个Raft Pipeline,达到用带宽换时延的目的。
Raft选举机制
我们先来简单介绍下Raft机制,以及Ozone是如何利用Raft机制来实现多副本写入的数据一致性的。分布式系统的一致性问题是大家津津乐道的话题,分布式系统由于本身分布式处理和计算的特点,需要协调各个服务器节点的服务状态保持一致来保证系统的容错能力,当某些节点出现故障的时候,不至于拖累整个集群。尤其对于Ozone这样的强一致分布式存储系统,需要在节点间有广泛承认的协议来保证状态一致,Ozone采用了Raft协议来维护集群状态和共享数据。
Raft协议中会有3个角色身份:Leader,Follower和Candidate。Split Vote投票过程会在Candidate中选出Leader和Follower的身份,Follower可以变成Candidate竞选Leader。
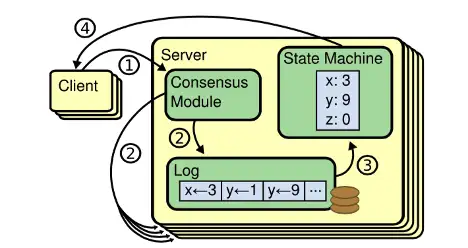
Raft一致性过程
Raft协议本质上是通过本地的RaftLog和在Leader与Follower之间同步状态来保证数据的一致性,同时StateMachine会记录集群的状态。RaftLog使用了write ahead log (WAL) 的理念,Leader将过程记录在Log里面,同时日志的更新内容会同步到Follower上,然后日志会apply log到StateMachine中记录状态,当有足够的Quorum宣布成功,整体操作就成功了。这样能保证集群所有节点的状态机变化是相对同步的,同时RaftLog会在节点重启时做replay回放操作,重新建立起重启前的StateMachine状态,让节点恢复到与重启前相对同步的状态。
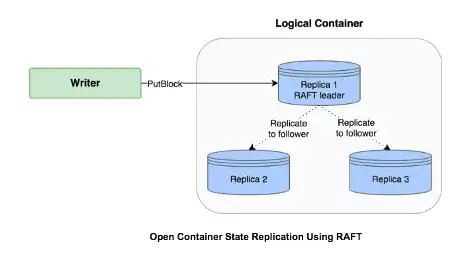
从Ozone写入过程的container流程中,为了保证当前三副本的冗余机制,container需要在3个数据节点DataNode上分配空间并保证多数节点写成功。Raft协议中的日志机制可以保证在Leader写完成后,Replicate数量到follower上去,三副本中有一个follower写完成后,数据就持久化成功了。这个大多数数据写成功的操作可以直接由Raft协议帮助完成,同时可以保证读写强一致。
Multi-Raft实现写入吞吐量优化
Ozone利用Raft机制管理数据和元数据的写入流程,数据写入DataNode上的磁盘前,Leader节点需要利用RaftLog的复制功能将数据同步到Follower节点上。由于Raft协议依赖RaftLog作为其WAL(写前日志),那么在数据节点上写入数据时也受到了RaftLog持久化时延的影响,随着线上环境支撑的数据量越来越大,Ozone写性能的波动和瓶颈越来越明显。
经过一系列的benchmark测试后,我们将目光投向了如何利用Raft Log增强DataNode上写盘的效率。原先的设计中,每一个Raft Group构成一个SCM中的Pipeline控制一系列的数据Container,经过测试发现,每个DataNode的磁盘使用率不是很充分,之后结合Ozone当前实现,设计并开发了Multi-Raft的功能,让SCM可以在每个DataNode上分配多个Pipeline,更加高效地使用DataNode上的磁盘和分区,同时也利用多Raft Group天然提高了单个DataNode的写并发,演进优化了Ozone的写入吞吐量和性能。
Ozone的数据写入模式
Ozone对于数据的管理主要由Pipeline和Container完成。Ozone的Storage Container Manager (SCM)负责创建数据Pipeline,并且分配Container到不同的Pipeline中,而每个Container负责在不同的数据节点DataNode上分配Block用来存储数据。用户通过客户端写入Ozone,会通过Ozone Manager创建Key,并从SCM拿到数据可以写入的空间,这个空间会由Pipeline和Container分配得来。
Pipeline和Container分配写入数据跟数据的副本数有关,Ozone现在主要支持三副本的方式,数据Pipeline创建时会关联三个数据节点,然后相关的Container会在这三个数据节点上分配Block来完成写入空间分配,三个数据节点会分别记住Pipeline和Container信息,异步发送Report到SCM上报Pipeline和Container的状态。三副本的数据Pipeline是通过Raft协议保证多副本一致性,在Ozone中也叫Ratis Pipeline,相关的三个数据节点会根据Raft协议组成一个Leader和2个Follower的组合,数据写入时会利用RaftLog把数据从leader发到Followers。所以Ozone的数据写入的性能依赖RaftLog的写入吞吐量和传输速度。
关于吞吐量的优化探索
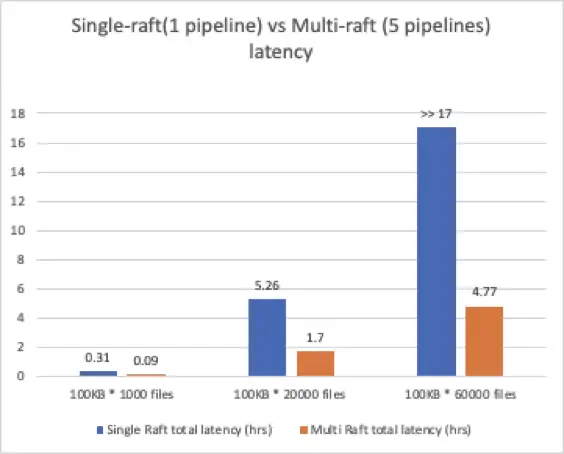
Ozone-0.4.0版本中,Pipeline控制数据写入是基于Single-Raft的实现,即每一个数据节点只能参与一个Pipeline。我们针对这个版本的Ozone进行了写入性能的观察和测试,组件了一个10节点的Ozone集群,每台Ozone数据节点都有12块HDD磁盘,网络选取了10 Gps带宽,作为大数据外部存储的集群配置。访问Ozone的方式我们选择了S3协议写入Ozone,对象大小比较离散,由内部sql query的结果组成,大部分是KB级的小对象,其中掺杂了GB级的大对象。
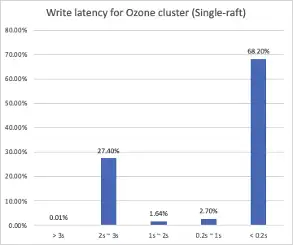
根据图中时延分布,我们可以看到有68%的写入可以在200毫秒内完成,但是依然有超过27%的文件集中于2-3秒内才能完成,同时观察发现时延与文件大小没有非常直接的联系。此外,我们也观察了某个数据节点的磁盘使用率。
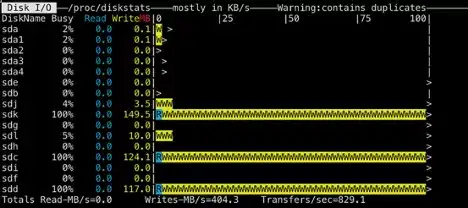
在前台持续并发写入的过程中,在全部12块磁盘中,只有5块数据盘有负载,并且集中于其中的3块磁盘。通过日志挖掘和数据统计也观察到,有IO阻塞的现象,数据节点上RaftLog写入磁盘的时候很有可能有排队的现象。于是我们将思路放在了提高数据节点磁盘使用率和缓解Ratis持久化RaftLog排队现象上。
在社区版本的HDFS上也有DataNode IO吞吐量不高的现象,之前有一些落地的方案会改动Linux操作文件系统的方式,增加一些类似Cache的手段帮助增大DataNode通过操作系统写入磁盘的吞吐量。而Ozone这部分优化的思路放在了通过数据Pipeline的节点复用来加大每个节点上Pipeline的使用量,从而通过增加使用者的方式变相增大磁盘使用率。
Multi-Raft的设计思路
如果每一个DataNode,受到了Single-Raft的制约,只能参加一个数据Pipeline的写入,那么上面的磁盘使用率观察可以看到Ratis实现的RaftLog并不能将写入IO均匀的分配到每一个磁盘路径上。
在与Ratis社区讨论后,我们提出了了Multi-Raft的方案,即允许数据节点参与多个数据Pipeline的工作,同时,Multi-Raft也需要通过新的Pipeline分配算法保证数据隔离,考虑数据locality和节点的rack awareness。
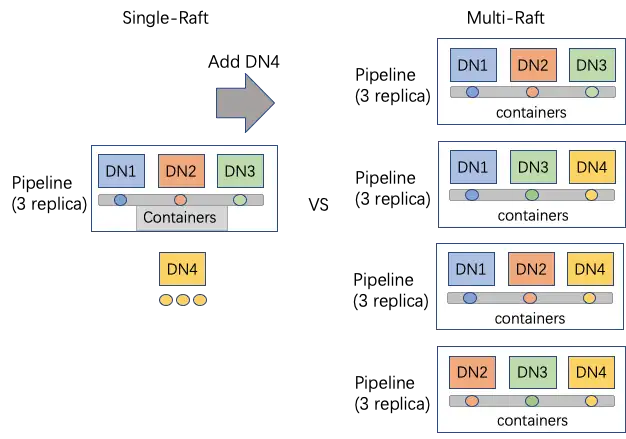
在允许数据节点DataNode参加多个数据Pipeline之后,Pipeline的节点分配就出现了很大的变化:
SCM能在集群不变大的情况下分配出更多的数据Pipeline。假设配置每个节点最多可以承接M个数据Pipeline的写入,在有N个数据节点的情况下,Single-Raft下SCM最多可以分配N/3个Pipeline,而Multi-Raft下就可以配置M(M*N)/3个Pipeline。
由于三副本备份的原因,数据Pipeline必须有刚好3个数据节点加入才能创建成功,Multi-Raft可以合理利用每一个数据节点的能力参与Pipeline。如图示,在有4个数据节点的时候,Single-Raft的集群只能创建出1个数据Pipeline,而剩下的1个数据节点(4-3*1)只能作为StandBy备用,在开启Multi-Raft功能后,4个节点都可以参加数据Pipeline的分配,大大提高了集群配置的灵活度。
从Single-Raft的磁盘使用率能看到,一个数据Pipeline使用的RaftLog并不能充分将数据写入很好的load balance,在与Ratis社区协作之后,Multi-Raft的方案可以有效利用节点上服务多个数据Pipeline的磁盘,从原来的一个RaftLog使用12个磁盘,变为多个RaftLog使用12个磁盘。对于Ratis的Batch写入和排队机制来说,一次写入可能会Hold某个磁盘一段时间,于是后面排队的写入由于RaftLog个数的限制,会造成一定程度的排队,这也是我们在Single-Raft的集群看到有超过27%的写入需要花费2-3秒,多个RaftLog的存在会很好减少排队的拥挤程度,因为“队伍”变多了。
Multi-Raft优化后的写性能表现
首先来看看同样的大数据数据集写入Multi-Raft集群和Single-Raft集群的时延分布对比:
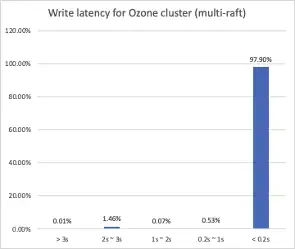
对比Single-Raft的集群:
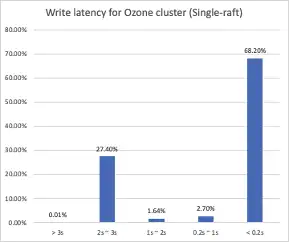
可以看到Multi-Raft优化后的集群,面对同样的数据集写入,接近98%的写入都在200ms内完成,IO排队导致的时延波动已经几乎看不到了。
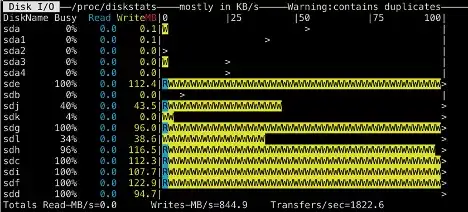
然后再选取一个数据节点根据节点上Pipeline分配个数观察磁盘使用率:
单数据节点参与1条数据Pipeline时:
单数据节点参与12条数据Pipeline时:
单数据节点参与15条数据Pipeline时:
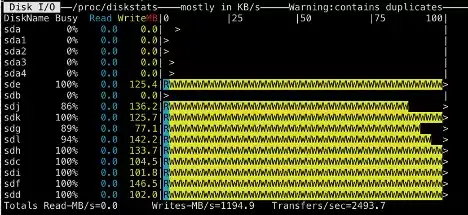
可以很明显地看到当数据节点上的数据Pipeline增多的时候,越来越多的磁盘达到了繁忙的程度,不再出现忙碌和闲置不均匀的情况了。
总结
Ozone的数据节点写入磁盘的部分,一定程度上延续了HDFS单节点写入的方式,同时也保留了一些可待优化的部分。比起单纯在数据节点上做IO栈层面的优化,Multi-Raft的方案利用了数据Pipeline的节点复用和RaftLog的特点,加大了数据节点对于并发写入数据的参与度。这样通过元数据和管理成本的修改增大写入带宽的方式,对于开源社区是更好的选择,后续可以打开更多的优化点,当前的Ozone-0.5.0版本在HDD集群上的写入性能比起0.4版本也有显著的提升。
Multi-Raft的功能已经完全回馈给了Apache Ozone社区,也在社区中取得了不错的评价,在合作的Cloudera技术Blog中也发布了Multi-Raft的技术分享:
上文就是小编为大家整理的什么是 MultiRaft,multiraft 数据摆放。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

