
麒麟v10 上部署 TiDB v5.1.2 生产环境优化实践
2176
2023-06-27
本文讲述了OLTP数据库,OLTP与OLAP的区别和联系。
OLTP(Online Transaction Pro- cessing)数据库,也称交易型数据库,是能够提供实时在线处理事务时保证强一致性(ACID)的关系型数据库。事务(Transaction)是操作数据库中数据的操作序列,要求保证ACID,即原子性(Atomicity)、 一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
OLTP(Online Transaction Pro- cessing)数据库,也称交易型数据库,是能够提供实时在线处理事务时保证强一致性(ACID)的关系型数据库。事务(Transaction)是操作数据库中数据的操作序列,要求保证ACID,即原子性(Atomicity)、 一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
为了满足事务处理的ACID四个性质,需要用到事务处理技术,主要包括并发控制技术和数 据库恢复技术。 其中,并发控制机制用来控制多个事务的同时运行,避免它们之间的互相干扰,保证每个事务都产生正确的结果。 数据库恢复机制用来进行系统失败后的恢复处理,确保 数据库能够恢复到正确状态。
为了便于添加或者修改数据集中某一条记录,提供OLTP服务 的数据库通常采用按行存储的方式。 在面对海量数据时,为了提高I/O效率,建立相应索引, 便于读取。 然而,在每条记录包含内容过多的情景中,按行访问的方式,会导致大量不必要数 据的读入。 如何减小数据库的相应延迟,增加吞吐量,是核心目标之一。
TPC-C:TPC组织提出并维护模拟仓库订单管理的应用。TPC-C包含9张表,各表所含的记录 条数具有比例关系。设计了5种事务,比较全面的涵盖了仓库订单管理业务。 采用tpmC作为度 量,描述每分钟处理的事务数;鉴于能耗越来越受到重视,也引入瓦特/tmpC(即每个tpm的 能量消耗)。
Sysbench:多线程基准测试工具,常用于数据库基准测试,对数千并发线程按秒测试CPU、 内存占用、文件I/O、延迟百分比等。
多节点写:YCSB是由雅虎研究院设计,频繁更新是它构造5类负载之一(其余四个为频繁 读、只读、读最新和小范围)。对主键的并发更新,可以根据其回复延迟,评测分布式数据管 理系统的性能 。
非索引列查询:TPC-E基准比TPC-C的数据库模式更为复杂,负载中包括了非主键访问等等。TPC-E 涉及 12 种不同类型和复杂性的并发交易,它们要么在线 执行,要么由价格或时间标准触发。 该数据库由 33 个表组成,具有广泛的列、基数和缩放属性。
单机数据库一般指的是运行在一个节点的数据库,然而其高可用受到较大限制(节点宕机 时不能提供服务),因此衍生了一主多备和一写多读的数据库。一主多备(备机不支持读)和 一写多读架构更能在实际应用场景中发挥作用。一主多读相比于一主多备的优势在于主机可以 提供事务的读写服务,其他备节点获得主节点的实时数据备份,并且对只包含读数据需求的用 户提供服务。这种集中式架构,可以很好的保证强一致性,提升度扩展能力。同时,备节点作 为主节点的备份,保障了数据库的可用性。
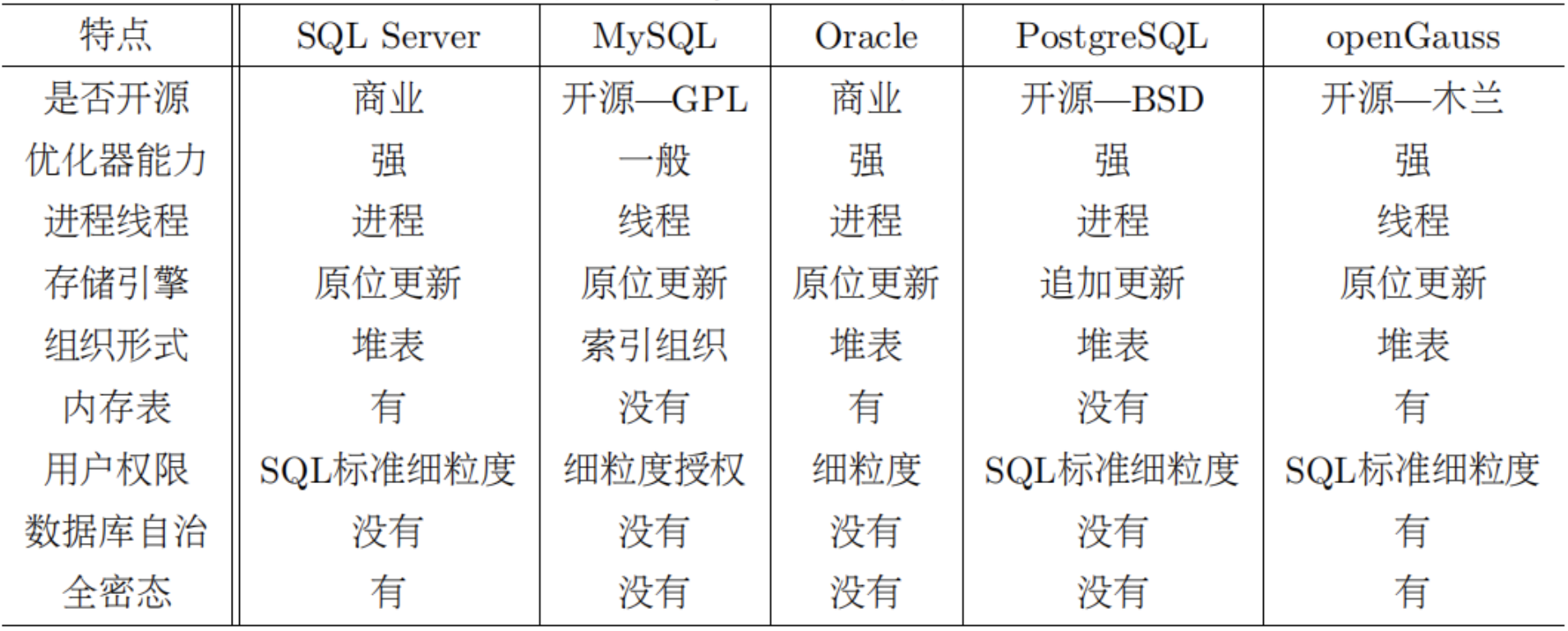
支持单机、一主多备、一写多读的数据库业界代表包括MySQL、***、***、 ***等。传统的***、***、***也支持类似部署。
一写多读OLTP数据库
单机数据库、一主多备数据库、一写多读数据库的写扩展能力受到了限制,当写请求量较 大时单节点写不能满足需求,因此集中式的多写数据库可以解决写扩展问题。多写数据库通 过“双机(active-active)”配置将数据库扩展到一组服务器上,以便交付高水平的可用性和可伸 缩性。
多写数据库业界代表包括***、IBM PureScale等。
分布式关系数据库,需要对数据库SQL引擎、执行引擎、存储引擎原生技术开 发。通常包含一个调度节点,若干负责计算的节点,若干负责存储的节点,才能同时具有扩展 性和可用性。而整个系统需要时刻保持协调统一,才能保证分布式事务处理的强一致性。 分布 式数据库通过数据分片来解决高可扩展问题,通过计算节点状态解耦、多副本、高精度时钟等 技术解决高可用问题。分布式数据库在分布式事务处理、分布式查询优化、智能化数据管理、 全密态数据管理等方面都有创新。
分布式数据库业界代表包括Spanner、***(***)、***、***-X、 TiDB、CockroachDB、 Yugabyte、***等。
云数据库服务一般将***、MySQL、***等数据库部署到云上部署(容器或 虚机),提供一写多读、运维、升级等能力。 而云原生数据库则指的是基于云架构的云数据库,一般提供计算存储分离和日志即数据能力,前者主要解决云弹性问题,后者解决磁盘和网络IO问题。
其设计原则和对应优势包括如下几方面:
日志即数据,减少了网络和IO代价(适合于云上部署)。
存储和计算相分离,计算节点上的数据来自网络中任意节点,使得资源调度更灵活。
弹性计算,根据使用量,占用计算资源。
支持在线扩容,不需要终止服务,即可扩展存储资源。
读写分离,支持一写多读,读服务可扩展性强。
云原生数据库业界代表包括Aurora、Taurus、***等。目前云原生数据库一般支持一 写多读服务,不支持多写服务。
单机数据库在单机上运行,因此较容易识别。鉴别一写多读、一主多备、多写主要通过备 机是否可读,备机读和主机读的时延,以及备机是否可以写来区别,也可以通过增加写的压力 进行区分。
下面介绍如何鉴别集中式数据库和分布式数据库。分布式数据库需要对数据进行sharding, 一般需要分布式键(或者隐藏的分布式键),可以构造在非分布列的查询来鉴别集中式数据库 和分布式数据库。
鉴别分布式中间件和分布式数据库主要通过分布式查询计划和分布式事务来区别,分布式 中间件不支持实时一致性、查询速度较分布式数据库有明显劣势。
OLTP(on-line transaction processing)翻译为联机事务处理, OLAP(On-Line Analytical Processing)翻译为联机分析处理,从字面上来看OLTP是做事务处理,OLAP是做分析处理。从对数据库操作来看,OLTP主要是对数据的增删改,OLAP是对数据的查询。
OLTP主要用来记录某类业务事件的发生,如购买行为,当行为产生后,系统会记录是谁在何时何地做了何事,这样的一行(或多行)数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功,像公司常见的业务系统如ERP,CRM,OA等系统都属于OLTP。当数据积累到一定的程度,我们需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,这时候就是在做OLAP了。因为OLTP所产生的业务数据分散在不同的业务系统中,而OLAP往往需要将不同的业务数据集中到一起进行统一综合的分析,这时候就需要根据业务分析需求做对应的数据清洗后存储在数据仓库中,然后由数据仓库来统一提供OLAP分析。所以我们常说OLTP是数据库的应用,OLAP是数据仓库的应用。
所以OLAP和OLTP之间的关系可以认为OLAP是依赖于OLTP的,因为OLAP分析的数据都是由OLTP所产生的,也可以看作OLAP是OLTP的一种延展,一个让OLTP产生的数据发现价值的过程。
上文就是小编为大家整理的OLTP数据库,OLTP与OLAP的区别和联系。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

