
黄东旭解析 TiDB 的核心优势
851
2023-06-27
本文关于( TiDB 容灾解决方案)
本文将以如下结构系统介绍 TiDB 容灾解决方案:
介绍容灾解决方案涉及的基本概念。
介绍核心组件 TiDB、TiCDC 及 BR 的架构。
介绍各种容灾方案。
对比不同的容灾解决方案。
基本概念
RTO (Recovery Time Objective):是指灾难发生后,系统恢复服务所需的时间。
RPO (Recovery Point Objective):是指灾难发生后,确保对业务不产生损失的前提下,可以丢失的最大数据量。
下面的图形描述了这两个概念:
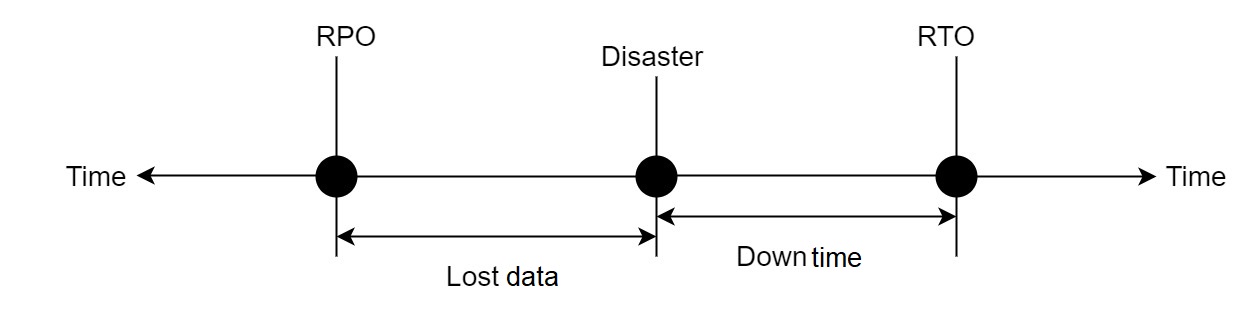
错误容忍目标:由于灾难可能影响的地域范围是不同的,在本文中,使用“错误容忍目标”来描述系统能够容忍的灾难的最大范围。
区域:本文主要讨论区域 (region) 级别的容灾方案,这里的区域通常是指一个物理世界中的地区或者城市。
组件架构
在介绍具体的容灾方案之前,本部分将从容灾角度介绍容灾系统中的组件架构,包括 TiDB、TiCDC 和 BR。
TiDB 架构
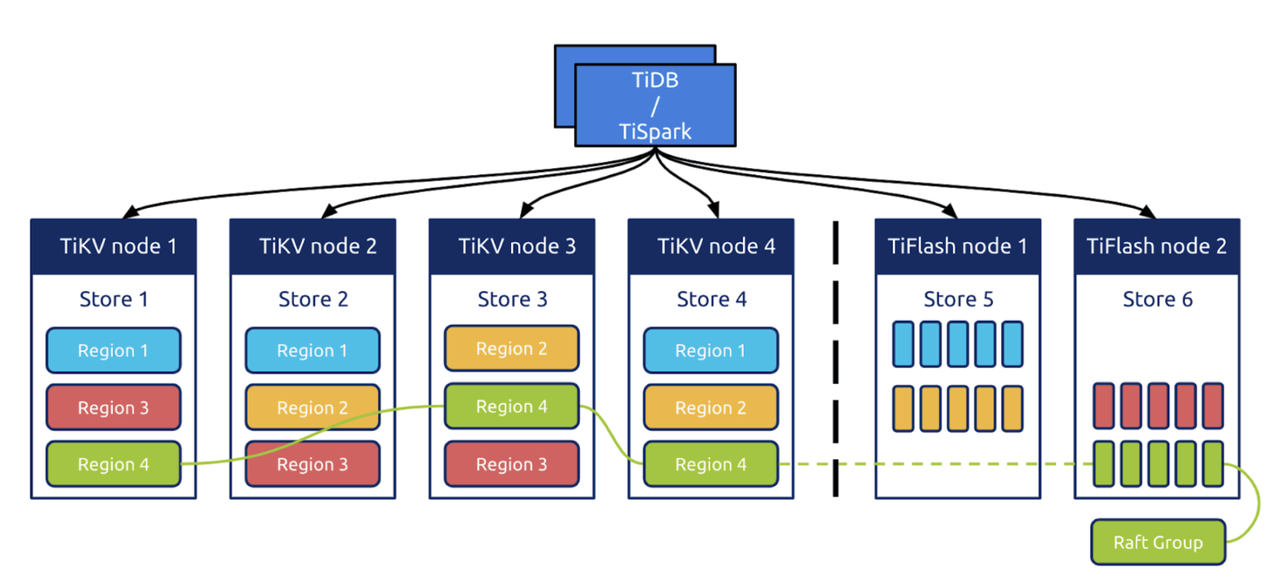
TiDB 的设计采用了计算、存储分离的架构:
TiDB 为系统的计算层。
TiKV 是系统的存储层,采用行存的方式保存数据库的数据记录,其中 Region 是经过排序的若干行数据的集合,也是系统调度数据的单位。同一个 Region 的数据保存至少 3 份,通过 Raft 协议在日志层复制数据改变。
TiFlash 副本是可选的,它是一款列式存储,用于加速分析类查询的速度。数据通过 Raft group 中的 learner 角色与 TiKV 中的数据进行复制。
由于 TiDB 保存了三份完整的数据副本,所以天然就具备了基于多副本数据复制的容灾能力。同时,由于 TiDB 采用了 Raft log 来进行事务日志同步,也在一定程度上具备了基于事务日志同步的容灾能力。TiCDC 架构
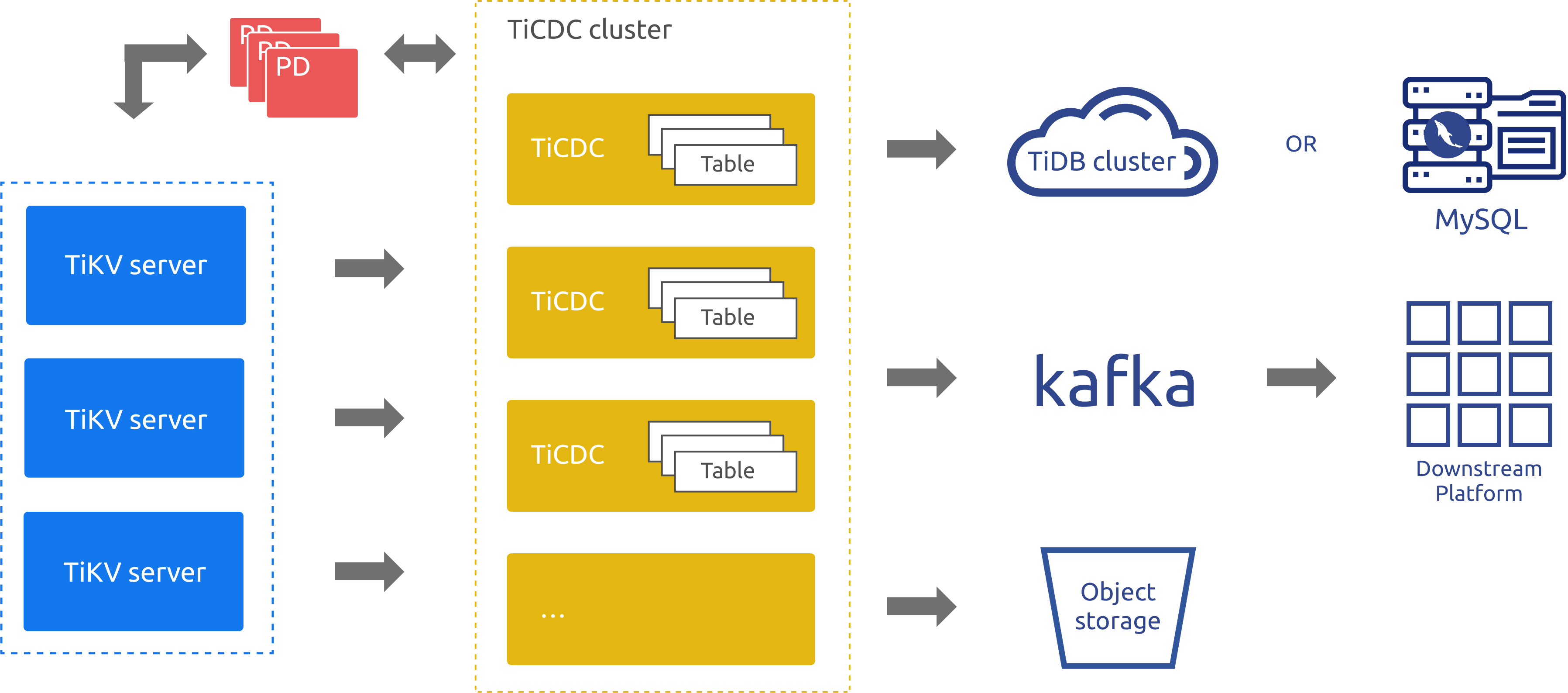
TiCDC 作为 TiDB 的增量数据同步工具,通过 PD 内部的 etcd 实现高可用,通过多个 Capture 进程获取 TiKV 节点上的数据改变,在内部进行排序、合并等处理之后,通过多个同步任务,同时向多个下游系统进行数据同步。在上面的架构中:
TiKV server:负责将对应节点上数据的改变推送到TiCDC 节点。当然,如果 TiCDC 发现收到的数据改变不完整,也会主动联系 TiKV server 获取需要的数据改变。
TiCDC:负责启动多个 Capture 进程,每个 Capture 负责拉取一部分的 KV change logs,并对获取到的数据改变进行排序,最后同步到不同的下游当中。
从上面的架构中可以看到,TiCDC 的架构和事务日志复制系统比较类似,但是扩展性更好,同时又兼顾了逻辑数据复制的很多特点。所以,TiCDC 也可以为 TiDB 在容灾场景提供很好的帮助和补充。
BR 架构
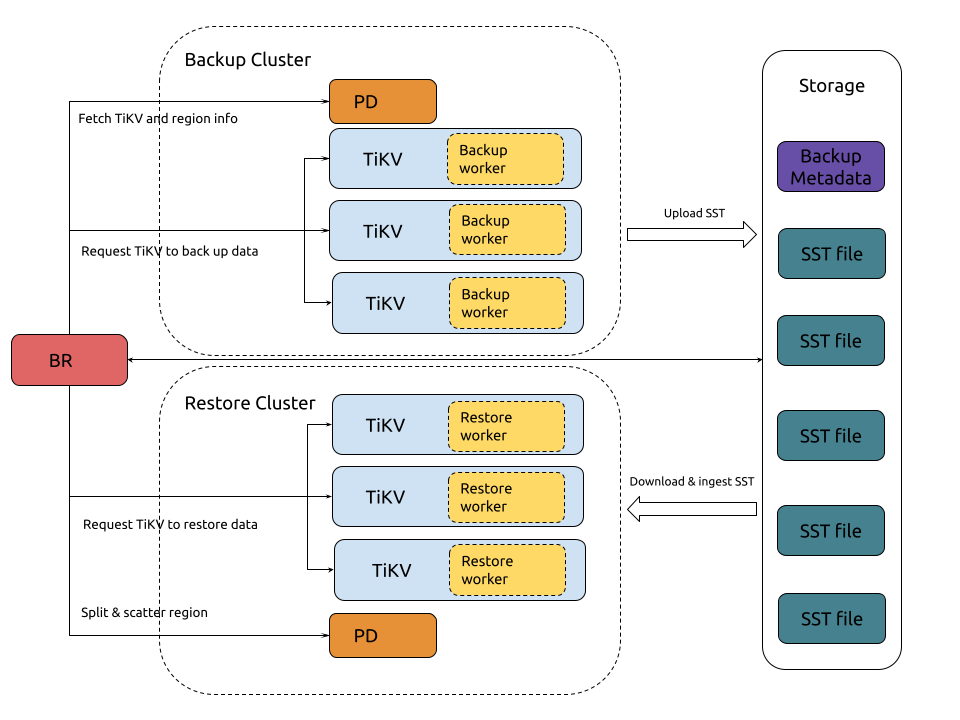
BR 作为 TiDB 的备份恢复工具,可以对 TiDB 集群进行基于时间点的全量快照备份和持续的日志备份,从而保护 TiDB 集群的数据。当 TiDB 集群完全不可用时,可以通过备份文件,在全新的集群中进行恢复。备份恢复通常是数据安全的最后一道防线。
方案介绍
基于 TiCDC 的主备集群容灾方案
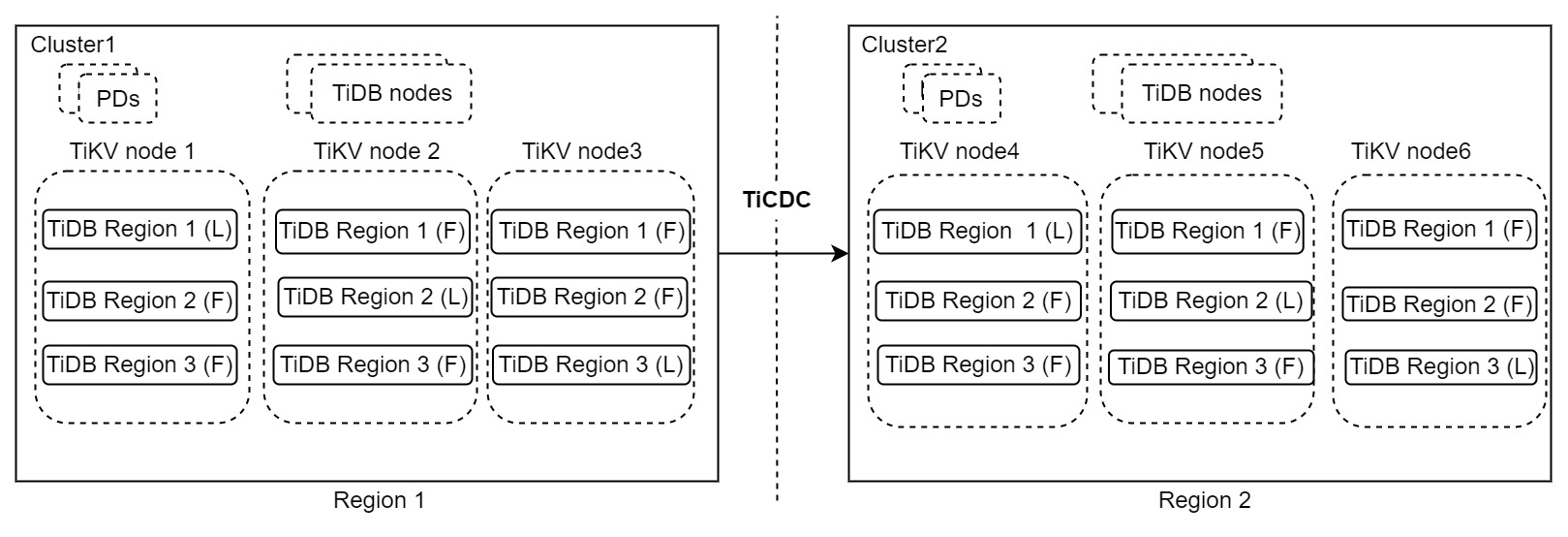
在上面的架构中包含了两个 TiDB 集群,Cluster1 为主用集群,运行在区域 1 (Region 1),包含 3 个副本,承担读写业务。Cluster2 作为灾备集群,运行在区域 2 (Region 2)。当 Cluster1 出现灾难时,Cluster2 继续对外提供服务。两个集群之间通过 TiCDC 进行数据改变的同步。这种架构,简称为“1:1”解决方案。
这种架构看起来非常简洁,可用性比较高,最大的错误容忍目标可以做到区域级别,写能力也能够得到扩展,RPO 在秒级别,RTO 在分钟级别,甚至更低。如果 RPO 为 0 并不是必须满足的要求,推荐在重要生产系统使用该容灾方案。
基于多副本的单集群容灾方案
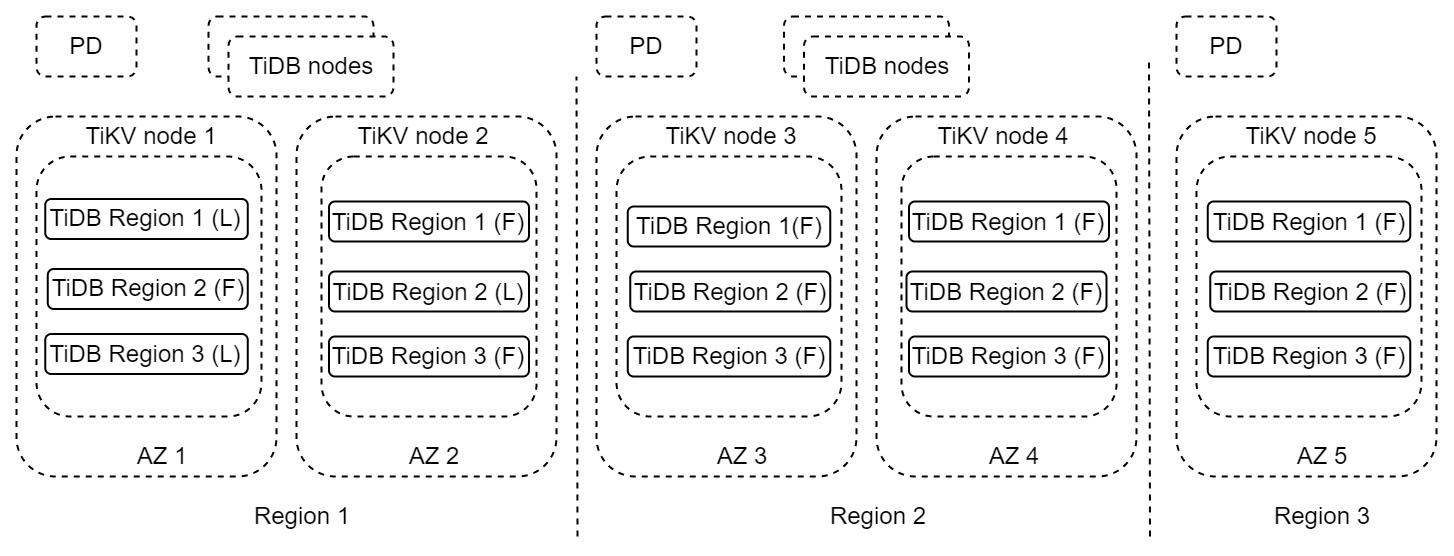
在上面的架构中,每个区域都包含两份完整的数据副本,它们位于不同的可用区 (Available Zone, AZ) 当中(通常情况下,两个可用区之间的网络速度和带宽条件较好,在同一个区域中的不同 AZ 中读写请求的延迟很低),整个集群横跨了三个区域。区域 1 通常是用来处理读写业务请求的主区域,当区域 1 出现灾难后完全不可用时,区域 2 可以作为灾难恢复的区域。而区域 3 (Region 3) 更多的是为了满足多数派协议而存在的一个副本。这种架构,简称为“2-2-1”解决方案。
该方案最大的错误容忍目标可以达到区域级别,写能力也能够得到扩展,并且 RPO 为 0,RTO 也可以达到分钟级别,甚至更低。如果 RPO 为 0 是必须满足的要求,推荐在重要生产系统使用该容灾方案。对于该方案的详细信息。
多副本与 TiCDC 相结合的容灾解决方案
以上两种容灾解决方案都可以实现区域级别的容灾,但是都无法解决多个区域同时不可用的问题。如果你的系统非常重要,需要“错误容忍目标”达到多个区域,就需要将以上两种容灾解决方案进行结合。
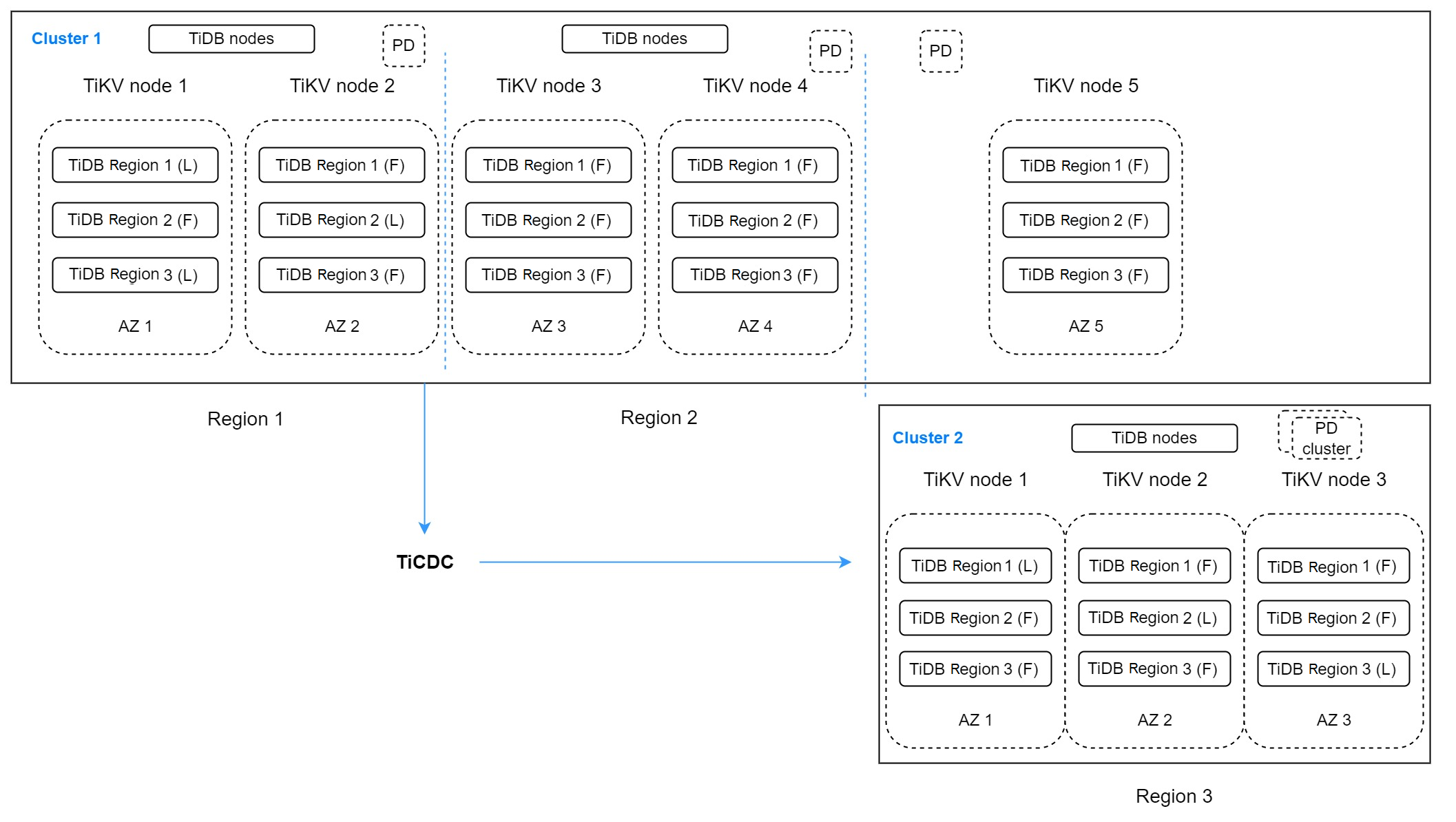
在上面的部署中存在两个 TiDB 集群。Cluster1 有 5 个副本,跨 3 个区域。区域 1 (Region 1) 包含两个副本作为主区域,用于服务写入。区域 2 (Region 2) 有两个副本作为区域 1 的容灾区域,可以提供一些延迟不敏感的读取服务。最后一个副本用于投票,位于区域 3 (Region 3) 中。
作为区域 1 和区域 2 的容灾集群,Cluster2 在区域 3 中运行,并包含 3 个副本。TiCDC 在两个集群之间同步数据更改。这种部署可能看起来比较复杂,但它可以将容错目标提高到多区域。如果多区域故障不要求 RPO 必须为 0,这种架构是一个很好的选择。这种架构,简称为 “2-2-1:1” 解决方案。
当然,如果“错误容忍目标”为多个区域,并且 RPO 为 0 是一个必须满足的要求,你也可以考虑创建一个包含至少 9 个副本,横跨 5 个区域的集群来实现该能力。这种架构,简称为“2-2-2-2-1”解决方案。
基于备份与恢复的容灾解决方案

按照上面的部署,TiDB Cluster1 部署在区域 1 (Region 1),BR 工具定期将集群的数据备份到区域 2 (Region 2),并且持续将数据改变日志也备份到区域 2。当区域 1 出现灾难导致 Cluster1 无法恢复时,你可以使用备份的数据和数据改变在区域 2 恢复新的集群 Cluster2 对外提供服务。
基于备份恢复的容灾方案,目前,RPO 低于 5 分钟,而 RTO 则取决于需要恢复的集群数据大小,对于 v6.5.0 版本的 BR,其恢复速度可以参考快照恢复的性能与影响和 PITR 的性能与影响。通常来说,大部分客户会把跨区域 的备份作为数据安全的最后一道防线,是大多数系统都需要的。
另外,从 v6.5.0 开始,BR 支持基于 AWS 上的 EBS 快照的快速恢复。如果你在 AWS 上运行 TiDB 集群,要求备份过程对集群没有任何影响,并且要求恢复的时间尽量短,可以考虑使用该特性来降低系统的 RTO。
其他容灾解决方案
除了以上容灾方案,针对同城双中心这种特定的场景,如果 RPO=0 是一个必须的条件,你也可以采用 DR-AUTO sync 解决方案。
方案对比
最后,对本文提到的各种容灾解决方案进行对比,以方便你根据自己的业务需要选择合适的容灾方案。
| 容灾方案 | TCO | 错误容忍目标 | RPO | RTO | 网络延迟要求 | 使用的系统 |
|---|---|---|---|---|---|---|
| 基于多副本的单集群容灾方案 (2-2-1) | 高 | 单个区域 | 0 | 分钟级 | 区域之间的网络延迟要求小于 30 ms。 | 对灾备和响应时间有明确要求 (RPO = 0) 的重要生产系统。 |
| 基于 TiCDC 的主备集群容灾方案 (1:1) | 中等 | 单个区域 | 小于 10 秒 | 小于 5 分钟 | 区域之间的网络延迟要求小于 100 ms。 | 对灾备和响应时间有明确要求 (RPO > 0) 的重要生产系统。 |
| 多副本与 TiCDC 相结合的容灾解决方案 (2-2-1:1) | 高 | 多个区域 | 小于 10 秒 | 小于 5 分钟 | 对于通过多副本进行容灾的区域,网络延迟建议小于 30 ms。对于第三区域与其他区域之间,建议延迟小于 100 ms。 | 对灾难恢复和响应时间有严格要求的关键生产系统。 |
| 基于备份恢复的容灾方案 | 低 | 单个区域 | 小于 5 分钟 | 小时级 | 无特殊要求 | 能够接受 RPO < 5 分钟,RTO 达到小时级别的系统。 |
上述就是小编为大家整理的( TiDB 容灾解决方案)
***
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

