

黄东旭解析 TiDB 的核心优势
1814
2023-03-31
今天主要是想把我们 TiDB 做 SQL 性能优化的一些经验和一些思考,就此跟大家探讨一下。题目写的比较大,但是内容还是比较简单。我们做 TiDB 的 SQL 层时,一开始做的很简单,就是通过最简单的 KV 接口(Get/Set/Seek)去存数据、取数据,做一些非常直白、简单的计算。然而后来我们发现,这个方案在性能上不可接受,可能行不通,我们就重新思考了这个事情。
TiDB 的目标是做一个 NewSQL 的 database ,什么是 NewSQL?从 Wikipedia 上我们看到 NewSQL 的定义『NewSQL is a class of modern relational database management systems that seek to provide the same scalable performance of NoSQL systems for online transaction processing (OLTP) read-write workloads while still maintaining the ACID guarantees of a traditional database system.』。首先NewSQL Database 需要能存储海量数据,这点就像一些 NoSQL 数据库一样。然后,能够提供事务的功能。所以 NewSQL 中的计算,主要有两个特点。第一个,就是数据是海量的,这跟 MySQL 传统数据有可能不一样,他们当然可以通过一些 sharding 的方式来进行处理,但是 sharding 之后会损失,比如说你不能跨节点做 Join,没有跨节点事务等。二是,在海量数据情况下,我们还需要对数据进行随时的取用,因为数据存在那,你算不出来就是对用户没有价值、没有意义的,所以我们需要在海量数据的前提下,能够随时把它计算出来。
计算主要分两种任务,一种是 OLTP 的 query,就是简单的查询,通过一些索引,就能过滤到大部分数据,然后能够做一些简单的处理和计算。还有一种是 OLAP的 query,这个一般来说会涉及到大量的数据及复杂的 query,比如说 Join,SubQuery 以及 Aggregate 这样一些东西。并且在海量数据的情况下,很多传统数据库上的 OLTP 的 query,看起来可能更像一个 OLAP 的 query,因为涉及到的数据量会非常大。那么在这样一些背景下,我们应该怎么考虑 SQL 计算呢?简单来讲,我们需要想办法在海量数据上,对计算进行优化和提速。
传统数据库的提速方法
传统数据库有很多提速的方法,有两种比较有名的,一个是 MPP,它的架构参见下图。计算数据是分在不同的节点上,并且很可能不在一台机器上,它们通过高速的网络连接,让每个节点都自己去处理数据,处理完数据之后再汇总在一起,最后给用户返回结果。
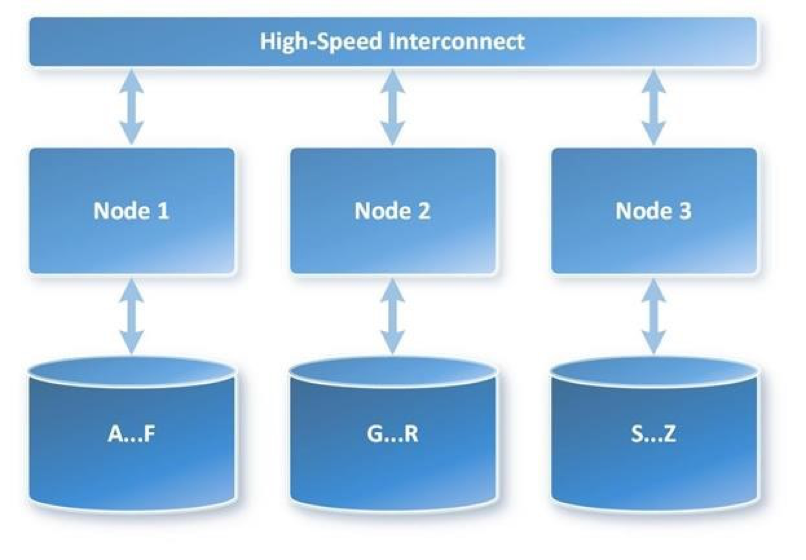
这个架构最大的特点就是它是一种 share nothing 的架构,也就是说节点之间的计算是相互不知道的,然后他们只执行自己的事情,不需要去交换数据,这是一种架构。
还有一种叫 SMP,这个跟 MPP 对应,它是一种 share everything 的架构。
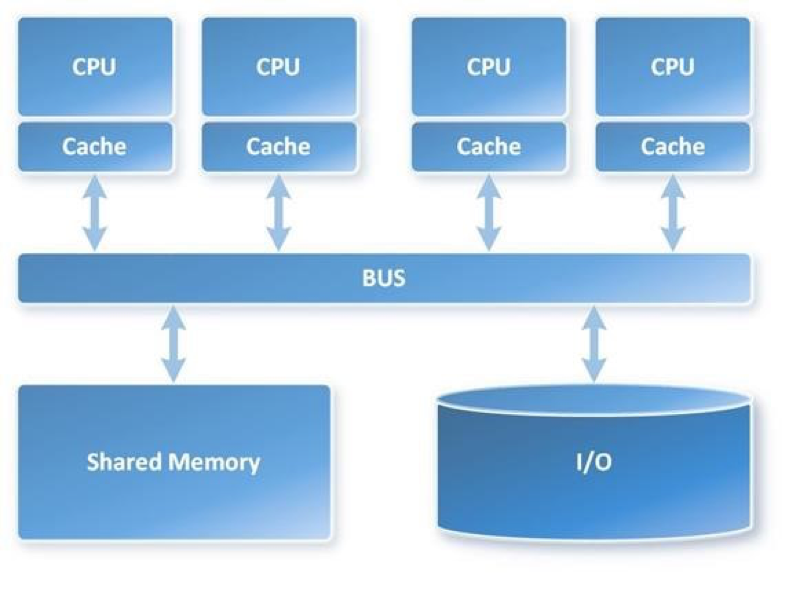
这种架构一般都是在一个 node 上、一个计算节点上进行,然后它们有多个 CPU 同时计算,它们会去通过总线去共享,比如说内存、IO 这样一些东西,这是一种 share everything 的一个架构。可以看到 MPP 和 SMP 这是两种传统数据库中用来提速的一些方案。我看到 PG(***) 最新的代码,他们已经支持了并行的处理,比如他们可以做并行 scan,他们可以去定义并发度,比如说 scan 一个表,他们利用多核这个特性,能够提速很多。当然这个肯定不是线性的,因为你去做并行,做数据交换,是有 overhead 的,这个 overhead 在你并行度太高的时候是挺大的。
TiDB
说完传统数据,我们说一下 TiDB。TiDB 的架构如下图所示。
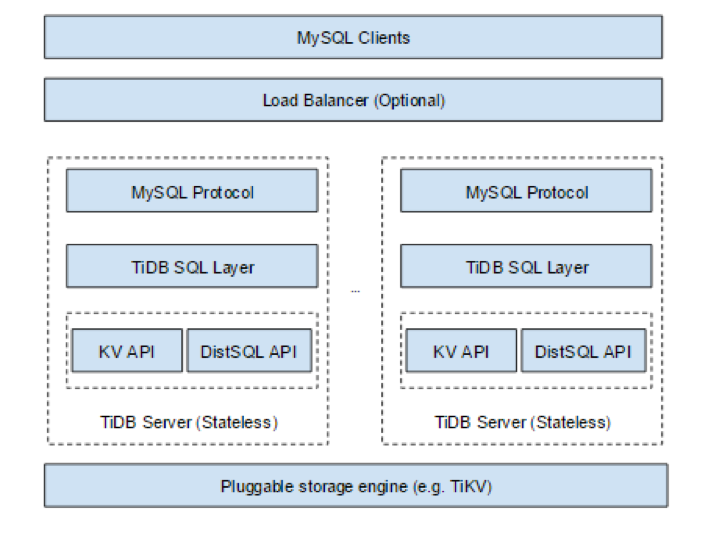
虚框所标的是 TiDB SQL layer,它的最上层是 protocol layer ,就是解析 MySQL 协议。然后是 SQL layer,它主要负责 SQL 的解析、查询,查询计划的制定以及生成执行器。它会调用底下的接口来获取数据,然后进行 SQL 的运算。接下来这一层,可以看到,分两个接口,一个就是 KV 的 API ,就是我们会把数据映射为 KV,因为我们最底下一层是一个 KV 的 storage engine 。比如说一行数据我们会用 Row ID 加上 Table ID 加上 Database ID 这些来做一个 key,然后把这行里面的数据作为 value ,再扔到 KV 中,就转成一种 key-value 的模式。对于 index 来说,我们也是转成了 KV 的模式,因为我们的 KV 有一个特点,就是可以进行有序的 scan。比如说你要在某些 Column 上建了 index,我们就会把这个 Column 编码成一个 key,然后再加上 index ID、Table ID 之类的东西,也 send 到这个 KV 里面去。就是说我们的上层,你可以认为只通过这个 API 也是能够正确的获取到数据、访问数据的,大概就是这样一个架构。然后这里还有一个 DistSQL API,这个是我们分布式计算框架的对上层提供了一个抽象,后面我会详细介绍这个 API 。最下面一层,就是我们的 TiKV 。你可以把 TiKV 考虑成一个纯的分布式的带事务的 key-value engine 。为了支持我们分布式 SQL 的 API ,我们给它上面加了更多功能,在这里我们有参考 *** 的 coprocessor 方案,然后提供一些 EndPoint 的功能,这样对上一层可以提供更丰富的语义。
那么,我们怎么让 SQL 在 TiDB/TiKV 中跑的更快?这半年多我们一直在做这个事情。
第一就是不管是 NewSQL 数据库还是传统数据库,我们肯定要对 optimizer 进行一些优化,在这方面我们做了特别多特别多的事情,包括常量折叠,后面还会做更多的,比如常量传播这些。然后 Join 怎么去选择,还有就是我们现在有一个 Cost Based Optimize 的一个框架,我们会考虑下层数据的统计信息,然后在统计信息的基础上,再制订查询计划,所以这是一个巨大的坑,我们正在努力的填它。我觉得 Google F1 这部分做的很好,它应该也做了挺多优化,但其它的数据库我觉得倒不一定有我们做的好,比如我看了一下 Spark,它的 Optimizor 比较简单,就是用了大概一部分 Rule 不断地去 Apply。我想主要的原因是 Spark 定位于做一个通用的计算框架,所以对底层的数据信息无法有细致的了解。
除了优化器这块儿,确定一个查询计划之后,怎么去执行它,也是很重要的事情。就是说同样的一个计划,可能用不同的执行器执行起来会有不同的效果。因为我们做的是一个 NewSQL 数据库,数据是分布在很多很多节点上的,我们完全可以利用数据广泛分布的特点,提高整体的并行度。而且我们 TiDB SQL layer 是用 Go 来写的,Go 在多核机器上能够发挥并发优势,它的 Goroutine 调度的开销很小,我们可以建很多 Goroutine,利用现在 CPU 越来越多的这个特性,去提高计算的并行度。还有就是说像传统的,比如 MySQL 、PG 上的东西,它主要还是访问内存、访问硬盘这样的一些开销。但对 TiDB 来说,它很大一部分都耗在网络上了,就是说你发一个请求过去,拿到数据,要走一遍网络,这还是有挺大开销的。所以我们一个很重要的目的就是让整个数据的流程尽可能快起来,尽可能的平滑,把网络这种开销尽可能的搞掉。
先讲一下,本次分享的标题叫 “MPP and SMP in TiDB” 主要是说我们有一个并行的、分布式的计算框架,怎么用这个计算框架来提高我们 SQL 计算的并行度,还有就是我们提供了coprocessor ,刚才介绍了,是从 *** 来的。
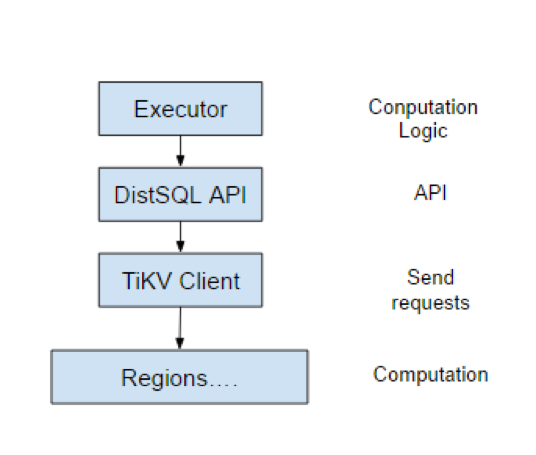
上图中的 Regions 是 TiKV 的一个 region servers ,我们可以在这里面插入一些代码,让它能够执行我们给它定义的一些任务。大家可以先看上图,整个的分层大概就是这样一个流程。它的最上面是执行器,就是我们经过 SQL Optimizer 之后生成执行计划,而后我们会根据执行计划生成这个执行器。接下来是刚才说的 DistSQL API,它会调用我们的 TiClient,就是说是一个 TiKV 的 Client,通过它来访问 TiKV,通过 Rpc 发送请求。它还有一个很重要的功能就是能获取数据分布在哪儿。因为一个表会分成很多 KV,这些 KV 是散列在很多很多 TiKV server 上的,它很重要的功能就是干这个事情,就相当于数据路由,是它一个重要的任务。最下面就是 region server ,这中间可以认为是网络。
这样分了几层之后,每一层都有它自己的任务,就是说我们每一层都抽的很薄。Executor 最重要的工作就是制定执行逻辑。就是说它要告诉下面你需要干什么事情。比如你是需要做 count ,还是需要计算 Where ,它理解的是 SQL 逻辑。DistSQL API 是两层之间的封装,就是说我们下面除了 TiKV 之外,还可以接其它的存储引擎,只要你满足我们这个接口的定义就可以。然后 DistSQL API 把上下隔离了,它提供了一个 API ,这个 API 稍后我会详细介绍一下。然后 TiKV Client 就是数据路由,数据的分发,比如说请求失败了怎么办,它干的就是数据请求发送的。Regions 这一层存储了数据,它需要利用上层传下来这个计算逻辑,在这个数据上进行计算。大概就是这些层,每一层只干了自己的事情,不需要关心下一层的实现。
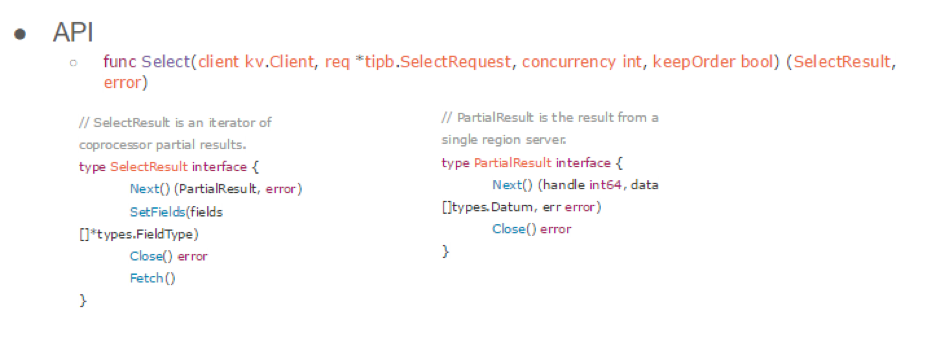
这个 API 就是刚才上面那个 DistSQL 提供的对外最重要的一个接口,叫 Select。
它有几个参数一个是 client。就是说只要你的 KV 引擎满足带事务、满足 KV 接口,并且满足这个 client 的一些接口,就可以接入 TiDB。有一些其他的厂商跟我们合作,在他们的 KV 上也能 run 我们这个分布式的 SQL ,这是相当于是 KV 的 Client。
第二个,就是 SelectRequest。这个东西是由上层执行器构造出来的,它把计算上的逻辑,比如说一些表达式要不要排序、要不要做聚合,所有的信息都放在 req 里边,是一个 Protobuf 结构,然后发给 Select 接口,它会扔到下层,最后扔到那个 region server 上进行计算。
还有 concurrency int。这个其实只是个建议,它的作用是提示下层要不要并发的去请求数据。因为我们数据是分在很多 region server 上的,所以要考虑去以多大并发度去发。然后,KeepOrder 这个参数是这样的,就是说下层是有很多 region server 的,我们要把请求发在很多 region server 上,但先发的结果不一定先返回来,因为有网络延迟、计算的延迟,所以这个顺序是不能预先设定好的。但是并不是所有的计算任务都依赖于数据的顺序,大多数情况下从拿到第一个结果开始就可以计算了,你就需要把结果先返回上来。在另一些情况下,我们需要下面按某一种顺序返回结果的,比如说 SQL 语句中有 OrderBy,并且对应的列上有索引,那么制定出来的查询计划很有可能就是首先扫描索引,然后依赖于索引的顺序对数据进行排序,因为索引是有序的,可以节约掉排序的时间。假设我们按照扫索引的顺序给你返回数据的话,你就可以不用后续自己去排了,这个 sort 已经帮你做好了。这个时候,就需要下层数据,下层的这个接口对你返回的数据是按照某个 key 有序的,所以这里就加了一个 KeepOrder 。当你不需要下层数据有序的时候,你就可以把这个设为 false ,假设这是 TiKV ,然后这是 TiDB,假设这个请求发了好几个 region server,虽然这个 TiKV 你可以认为是一个大的 key 的空间,并且按照 key 有序,假设某个后面的 key range 的请求先返回,如果你不要求下层返回有序,你完全可以把这个请求的结果先返回到上面进行计算,让整个计算过程能够更快。
接着这个接口返回了一个数据结构,叫 SelectResult ,这个结构可以认为它是一个迭代器,因为我们下层是有很多 TiKV ,然后每个结果是一个 PartialResult。上层封装了一个 SelectResult ,就是一个 PartialResult 的迭代器。通过这个的 next 方法可以拿到下一个 PartialResult ,但是具体的下一个 PartialResult 是哪个的 region server ,是不一定的,就像我刚才说的,取决于你要不要 KeepOrder 。 SelectResult 的内部实现你可以认为是个 pipeline。我们会并发的去往各个 region server 发数据,但是可能有的先返回给你了,有的后返回给你了。虽然某个 region 存储数据的 key 的范围比另外一个 region 的小,但是要不要先把某个 region 的结果返回给你,是由你这个 KeepOrder 决定的。
然后如果你是不要 KeepOrder ,那我们就是一个 channel,也就是有数据返回了就往里扔,扔完之后就可以对上返回了。然后这个 API 返回的是 SelectResult 。
如果你是要求下面有序,那么这里会对这个 request 建一个slice ,假如前面的没返回来,是不会把后面的 request 返回给你的。主要是定义了这样一个语义,我们就可以很方便的决定下面的这个行为。
这个地方,我们是做了一些优化的。当 KeepOrder 为 false 的时候,如果它先到了一部分,你可以先处理那一部分。就是说这个 KeepOrder 是 true 还是 false,影响了最下面一层的返回逻辑。比如你不要这个 KeepOrder ,那么我给一堆 KV server 发了request 之后,这个 response 是扔到一个统一的 channel 里面的,谁先返回就把谁的扔进来,然后外面调用 next 就已经拿到了。但如果你是 KeepOrder 为 true ,我下面所有的 request 按照这个 key 的顺序建了一个 slice,然后你调这个的 next 的时候,它是遍历这个 slice,就是如果前面那个 result 没拿到,它是不会往后面走的,即使后面 response 已经到了,它也不会给你返回的。
这个接口还是挺重要的。举个例子吧,来看一下我们怎么去做这个分布式的 SQL ,比如 select * from t where age > 20 and age < 30。在这里, t 这个数据可能分布在很多 region 上,我们会把要扫描 t 这个表的信息以及这个 filter,整个推到 region server 上进行计算,然后 Executor 构造的就是比如说我要扫哪个表,它的表的信息是什么。通过这个表的信息,下层就能去构造 KV,Ti-Client 就能通过这些 KV 找到这个表的数据分布在哪些 region 上面,然后它就会把这个请求发在这些 region 上面,同时在 selecter request 信息里面也会带上我要做 filter 的那个 condition,它会把要查询的表的元信息等都发到存储个表数据的 region server 上。然后它再利用表的信息把数据拿出来并过一遍 filter,只有过了这个 filter 的数据,之后才会返回给 TiDB。这样一方面能够增加这个计算并行度,因为我们可能有很多 region server 存储这个数据,当然只有有这个数据的 region server 我们才会发请求过去。
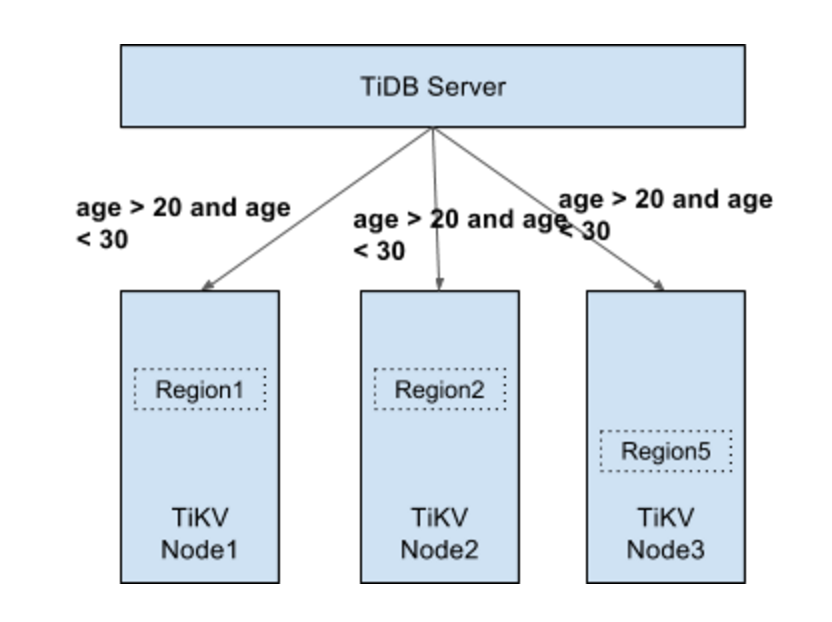
第二,你把 filter 推下去很重要的好处就是,只有过了这个 filter 才能返回,这样返回你的数量是减小了很多,你就能减小无意义的网络传输。据我们在 Google 那边了解的情况是,他们好像不太care这个事儿,因为他们内部网络实在太快了,他们可以直接把所有数据 load 过来,在这边去算,可以认为整个 IPC 就是一台巨大的机器。就像所有的机器都通过总线连起来,有这种感觉,它就不考虑效率问题。所以他们的效率我觉得还是值得考虑。但大部分用户可能是用一些廉价的 PC,我们这个方案其实是更好的一个方案。这是比较简单的一种。我们还有分布式 aggregate,这种是更好搞的,就假设我们把这个 ability 也推下去,比如说 count,然后你在这边过完 filter,你只需要每个 region 计算自己上的结果,给我返回一个这边的计数就可以了,然后我在 TiDB Server 再把这个 partial result 制成一个 final result ,比如说你这边是五个,这边十个,这边二十个,那我加起来直接算个 sum 返回给你就可以了,这是它最大的好处。
刚才是介绍了一下我们 TiDB 的一个分布式的计算框架,然后下面我们介绍一下之前我们做这两项工作,就是把这个 Join 让它变得更快一些。
最开始的时候,TiDB 进行 Join 运算非常慢,其实这也是 MySQL 的缺陷,MySQL 只支持 look up Join ,它是说你先取一个表的数据,然后用每一行数据去另一个表拿数据,这个在数据量大的时候是很慢的。所以我们支持了 Hash Join。
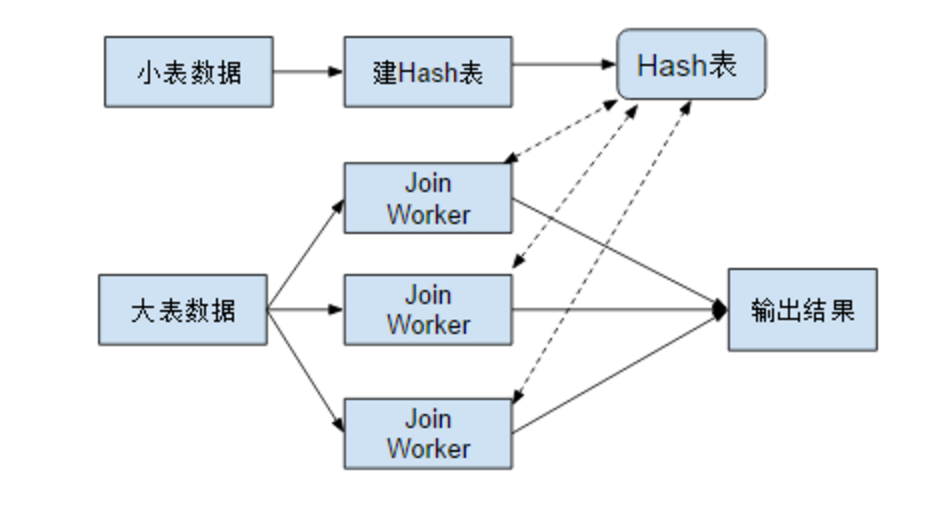
Hash Join 的话比如说你有一个大一个小两个表,大表在千万量级,其实也不是特别大,内存还是能放下的。你可以用一个小表去建一个 Hash 表,然后再从大表去读数据,读数据的时候你可以去 Hash 表中拿数据,待拿到 Join on 那个条件能对应上那个小表的数据,再算,再过一些 filter ,看看要不要输出这一行,然后对外返回结果。
为了让它算的更快,我们最近干了一些工作。第一,我们读小表的数据和读大表的数据,是可以并行来搞的,你可以想象成两条数据流。因为我们网络延迟是比较大的,所以我们想让数据尽可能的平滑、平顺地去流动,对于 Join 读取 DataSource 有两个事情要做,第一个是读小表数据,第二个是读大表数据,我们读小表数据可以用一个单独的线程来做,然后它就会发请求去读小表数据。拿到小表数据之后,拿到一行,然后它就可以对这行扔到一个 Hash 表中,算一个 key 。与此同时,我们可以新建另一个线程,它在这同时去读大表的数据,读完大表的数据之后,它再扔给一堆 worker,这堆 worker 就是做 Join 这个事的。就比如说它把数据虽然发到这些 worker,这些 worker 拿到大表的一行,算出 Join 的 key ,然后它去 Hash 表中去拿到对应的小表的数据,再看能不能过这个 Join 的 filter,最后再输出结果。这个时候,整个数据可以看到,已经尽可能的去并行,不会因为比如说小表数据没读到,就阻碍大表拿数据。当然,这个中间还有个同步的问题,就是这个 Hash 表只有完全建好之后,大表的 Join 的 worker 才会开始工作。
用 Go 写这种计算任务是非常简单的,因为 Go 有 goroutine,它的调度开销非常小,并且 Go 还有 channel,它们之间的通讯也是可以通过 channel 去扔的。但是有一点要注意,就是你这个大表假设比较大,有好几千万,你可以一条一条数据扔到 channel 里面去,它开销很大,我们后来采用的是用 batch 的方式往里扔。比如说读个一千条扔到一个 channel 里面,然后一个 worker 再拿着这个数据来进行计算。等到这些 worker 计算完之后,再把这个结果扔到一个 channel 里面去,这时外面就可以通过这个 channel 拿到计算的结果。这个做完之后,我们 Join 差不多快了十倍。 在这里,读取数据的时候是一个单线程的。因为下面我们没有保障线程安全,这个后面可以再考虑,怎么让下面也去线程安全。但是读数据这个步骤,只要不 block 后面计算流程就可以了。
然后还有一个优化是这样的。我们之前发现了一个问题,就当我们通过索引去读数据,以前的一个串行的模式是比较有问题的。我们索引和数据你可以认为是两个 KV 的 region ,想通过索引 filter 数据,首先你要构造一个索引的范围,在这边读索引表,然后拿到所有的 row ID。拿到 row ID 之后,再用这些 row ID去访问一下数据表,大概是这样一个流程。实际这样对 TiDB 来说,可以看成是两次网络请求,第一次是读,拿到所有的数据,row ID,然后第二次用 row ID 去拿真正的数据,再在 Join 上进行处理。
index data 也分布在很多 region server 里面, row 的数据也分布在很多 region server 里面,当网络开销比较大的时候,如果你先读索引数据,拿到所有的数据再去读数据表,那么读数据表的工作就会等读完所有的索引数据后才开始,这是不合理的。因为上面我们介绍过,我们发很多 region server 之后,你可以让它不 KeepOrder ,就是有数据先返回来了,你就可以去用了。这个时候,我们可以把整个这个改成一个 pipeline 的模式,比如说你拿到一部分 index handle ,然后我们可以拿 row ID 先构造一个 job ,起一个 goroutine 让它去拿这个数据表的内容,这样我们可以把整个数据的流动让它更平滑,让它更快一些。
一般来说,当你拿到最后一个 index 的 row ID 的这个 respond 之后,你只需要拿那一个 respond 就可以了。而且你拿到最前面这个 row data 之后,已经可以对你的更上一层的 executor 返回数据了。这样将无论是执行的成本,还是启动代价都降的很低。以前的你可以认为启动代价是整个 scan 之后才能返回第一行数据,现在只是一个 scan index 的第一个 reason server 返回结果,然后拿那个结果到第一个 row data 的 response 已经能返回数据了。
这个改造完之后,我们又快了很多,至少有两三倍吧。
刚刚介绍了我们之前已经做的很多事情,那么,我们后面还能做一些什么样的事情,能让整个TiDB跑的更快、SQL 跑的更快呢?
第一个,我们还需要一个更牛逼的执行框架,执行引擎。我们现在是一个很简单的,可以认为是一堆 Map 、一个 reduce 这种模式。但这种已经足够解决所有的 OLTP 请求,以及中小规模 OLAP 请求,但大型的 OLAP 请求我们可能还是有一些风险,我们还要继续去解决这个事。未来,我们可能会像 Spark 一样,有一个 DAG 引擎,它会有一些更丰富的语义能够让你把整个 job 描述出来,分成很多 task 一起帮你来算。当然,这个东西也要考虑它的代价,因为当你的数据量不是特别大的时候,比如千万这种级别,你把这个数据去做 shuffle,它还要去落盘,还要去走网络传输,还是有一些额外的开销,我们试过,在中小规模上 spark 不如我们快。
但如果是更大规模, Spark 能做的更快的。这个是我们后续要做的。当然我们有个考虑,就是 SQL 的优化和执行,还是要看你的场景,你是 TP 的还是 AP 的。比如说你 AP 的可以做你的优化,你的执行器可以做的很重,对吧?当然你数据量很大,你之前的那些代价就可以忽略不计了。比如说你要去生成一个更高效代码,这个都有开销的,但是你在 OLTP 的请求中,这些事情就不太适合。所以 TiDB 完全可以区分这两个请求,比如说通过设置一些标识或者直接打两套引擎,满足不同的需求,更灵活一些。
第二,后面可能还需要把这种并行度搞成可配置,因为这个东西也是跟你的硬件架构有关,比如说你是多少核,你有多少块盘,是不是 *** 的,然后你网络什么情况等等这些。我们需要有些可配置的东西,比如可以通过一些系统变量或者配置文件来进行制定。还有就是我们有很多 executor 都可以搞成并行的,比如说一些排序,包括 where 拿到数据之后,算那个 where 表达式,我们也可以并行来搞,诸如此类。
还有就是,我们现在有一个 cost-based optimizer。它考虑 cost 的时候,还是按照传统数据库那样考虑。当然我们是考虑了网络的,但是如果下面的 executor 可以并行的去做,这个时候它的 cost 可能会变,所以我们后面需要把并行的计算考虑到这个 optimizer 的 cost 计算中去,以更好的适应整个框架。
这两个工作很好搞,DAG 引擎是一个比较大的工作,它有很多坑,其实 Spark 用不好也有很多坑,比如说你有数据倾斜,你内存会爆,对吧?所以这个是很复杂的事情,可能这个事情我们也走在前沿了,但我们会长期的来做,并且肯定会做出来。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

