

黄东旭解析 TiDB 的核心优势
1256
2023-03-30
最近几年来,越来越多的文章介绍了 Raft 或者 Paxos 这样的分布式一致性算法,且主要集中在算法细节和日志同步方面的应用。但是呢,这些算法的潜力并不仅限于此,基于这样的分布式一致性算法构建一个完整的可弹性伸缩的高可用的大规模存储系统,是一个很新的课题,我结合我们这一年多以来在 TiKV 这样一个大规模分布式数据库上的实践,谈谈其中的一些设计和挑战。
本次分享的主要内容是如何使用 Raft 来构建一个可以「弹性伸缩」存储。其实最近这两年也有很多的文章开始关注类似 Paxos 或者 Raft 这类的分布式一致性算法,但是主要内容还是在介绍算法本身和日志复制,但是对于如何基于这样的分布式一致性算法构建一个大规模的存储系统介绍得并不多,我们目前在以 Raft 为基础去构建一个大规模的分布式数据库 TiKV ,在这方面积累了一些第一手的经验,今天和大家聊聊类似系统的设计,本次分享的内容不会涉及很多 Raft 算法的细节,大家有个 Paxos 或者 Raft 的概念,知道它们是干什么的就好。
其实一个分布式存储的核心无非两点,一个是 Sharding 策略,一个是元信息存储,如何在 Sharding 的过程中保持业务的透明及一致性是一个拥有「弹性伸缩」能力的存储系统的关键。如果一个存储系统,只有静态的数据 Sharding 策略是很难进行业务透明的弹性扩展的,比如各种 MySQL 的静态路由中间件(如 Cobar)或者 Twemproxy 这样的 Redis 中间件等,这些系统都很难无缝地进行 Scale。
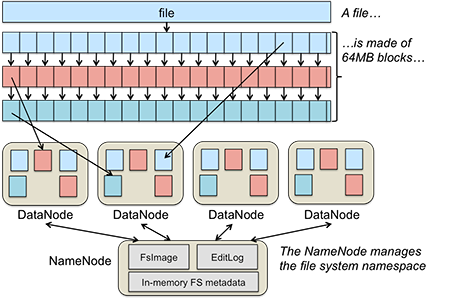
在集群中的每一个物理节点都存储若干个 Sharding 单元,数据移动和均衡的单位都是 Sharding 单元。策略主要分两种,一种是 Range 另外一种是 Hash。针对不同类型的系统可以选择不同的策略,比如 HDFS 的 Datanode 的数据分布就是一个很典型的例子:
Range 的想法比较简单粗暴,首先假设整个数据库系统的 key 都是可排序的,这点其实还是蛮普遍的,比如 *** 中 key 是按照字节序排序,MySQL 可以按照自增 ID 排序,其实对于一些存储引擎来说,排序其实是天然的,比如 LSM-Tree 或者 BTree 都是天然有序的。Range 的策略就是一段连续的 key 作为一个 Sharding 单元:
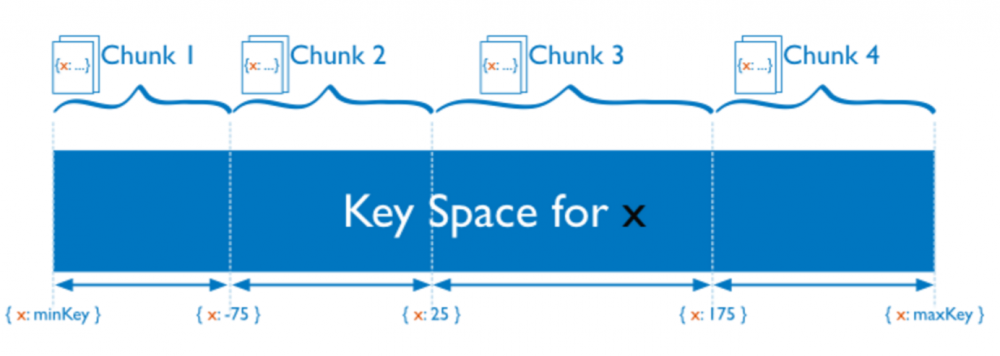
例如上图中,整个 key 的空间被划分成 (minKey, maxKey),每一个 Sharding 单元(Chunk)是一段连续的 key。按照 Range 的 Sharding 策略的好处是临近的数据大概率在一起(例如共同前缀),可以很好的支持 range scan 这样的操作,比如 *** 的 Region 就是典型的 Range 策略。
但是这种策略对于压力比较大的顺序写是不太友好的,比如日志类型的写入 load,写入热点永远在于最后一个 Region,因为一般来说日志的 key 基本都和时间戳有关,而时间显然是单调递增的。但是对于关系型数据库来说,经常性的需要表扫描(或者索引扫描),基本上都会选用 Range 的 Sharding 策略。
与 Range 相对的,Sharding 的策略是将 key 经过一个 Hash 函数,用得到的值来决定 Sharding ID,这样的好处是,每一个 key 的分布几乎是随机的,所以分布是均匀的分布,所以对于写压力比较大、同时读基本上是随机读的系统来说更加友好,因为写的压力可以均匀的分散到集群中,但是显然的,对于 range scan 这样的操作几乎没法做。
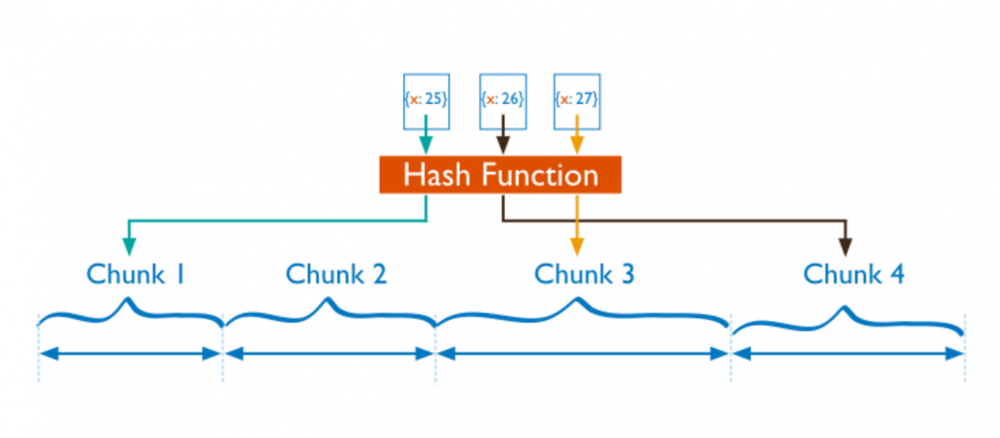
比较典型的 Hash Sharding 策略的系统如:*** 的一致性 Hash,Redis Cluster 和 Codis 的 Pre-sharding 策略,Twemproxy 有采用一致性 Hash 的配置。
当然这两种策略并不是孤立的,可以灵活组合,比如可以建立多级的 Sharding 策略,最上层用 Hash ,每一个 Hash Sharding 中,数据有序的存储。
在做动态扩展的时候,对于 Range 模型的系统会稍微好做一些,简单来说是采用分裂,比如原本我有一个 [1, 100) 的 Range Region,现在我要分裂,逻辑上我只需要简单的将这个 region 选取某个分裂点,如分裂成 [1,50), [50, 100) 即可,然后将这两个 Region 移动到不同的机器上,负载就可以均摊开。
但是对于 Hash 的方案来说,做一次 re-hash 的代价是挺高的,原因也是显而易见,比如现在的系统有三个节点,现在我添加一个新的物理节点,此时我的 hash 模的 n 就会从 3 变成 4,对于已有系统的抖动是很大,尽管可以通过 ketama hash 这样的一致性 hash 算法尽量的降低对已有系统的抖动,但是很难彻底的避免。
选择好了 sharding 的策略,那剩下的就是和高可用方案结合,不同的复制方案达到的可用性及一致性级别是不同的。很多中间件只是简单的做了 sharding 的策略,但是并没有规定每个分片上的数据的复制方案,比如 redis 中间件 twemproxy 和 codis,MySQL 中间件 cobar 等,只是在中间层进行路由,并未假设底层各个存储节点上的复制方案。但是,在一个大规模存储系统上,这是一个很重要的事情,由于支持弹性伸缩的系统一般来说整个系统的分片数量,数据分片的具体分布都是不固定的,系统会根据负载和容量进行自动均衡和扩展,人工手动维护主从关系,数据故障恢复等操作在数据量及分片数量巨大的情况下几乎是不可能完成的任务。选择一个高度自动化的高可用方案是非常重要的。
在 TiKV 中,我们选择了按 range 的 sharding 策略,每一个 range 分片我们称之为 region,因为我们需要对 scan 的支持,而且存储的数据基本是有关系表结构的,我们希望同一个表的数据尽量的在一起。另外在 TiKV 中每一个 region 采用 Raft 算法在多个物理节点上保证数据的一致性和高可用。
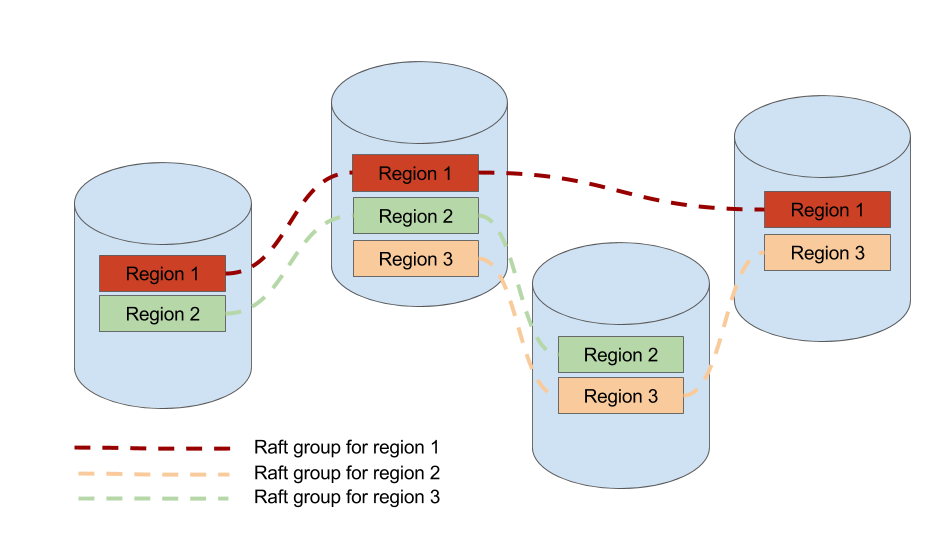
从社区的多个 Raft 实现来看,比如 Etcd / LogCabin / Consul 基本都是单一 raft group 的实现,并不能用于存储海量的数据,所以他们主要的应用场景是配置管理,很难直接用来存储大量的数据,毕竟单个 raft group 的参与节点越多,性能越差,但是如果不能横向的添加物理节点的话,整个系统没有办法 scale。
scale 的办法说来也很简单,采用多 raft group,这就很自然的和上面所说的 sharding 策略结合起来了,也就是每一个分片作为一个 raft group,这是 TiKV 能够存储海量数据的基础。但是管理动态分裂的多 raft group 的复杂程度比单 group 要复杂得多,目前 TiKV 是我已知的开源项目中实现 multiple raft group 的仅有的两个项目之一。
正如之前提到过的我们采用的是按照 key range 划分的 region,当某一个 region 变得过大的时候(目前是 64M),这个 region 就会分裂成两个新的 region,这里的分裂会发生在这个 region 所处的所有物理节点上,新产生的 region 会组成新的 raft group。
构建一个健壮的分布式系统是一个很复杂的工程,上面提到了在 TiKV 在实践中的一些关键的设计和思想,希望能抛砖引玉。因为 TiKV 也是一个开源的实现,作为 TiDB 的核心存储组件,最近也刚发布了 Beta 版本,代码面前没有秘密,有兴趣深入了解的同学也可以直接阅读源码和我们的文档,谢谢大家。
Q1:如何在这个 region 的各个副本上保证分裂这个操作安全的被执行?
其实这个问题比较简单,就是将 split region 这个操作作为一个 raft log,走一遍 raft 状态机,当这个 log 成功 apply 的时候,即可以认为这个操作被安全的复制了(因为 raft 算法干得就是这个事情)。确保 split log 操作被 accept 后,对新的 region 在走一次 raft 的选举流程(也可以沿用原来的 leader,新 region 的其他节点直接发心跳)。split 的过程是加上网络隔离,可能会产生很复杂的 case,比如一个复杂的例子:
a, b 两个节点,a 是 leader, 发起一个分裂 region 1 [a, d) -> region 1 [a, b) + region 2 [b, d), region 2的 heartbeart 先发到 b,但这时候 region 2 分裂成了 region 2 [b, c) + region 3 [c, d),给 b 发送的 snapshot 是最新的 region 2 的 snapshot [b, c),region 1的 split log 到了 b,b 的老 region 1 也分裂成了 region 1 [a, b) + region 2 [b,d), 这之后 a 给 b 发送的最新的 region 2 的 snapshot [b, c) 到了,region 2 被 apply 之后,b 节点的 region 2 必须没有 [c, d) 区间的数据。
Q2:如何做到透明?
在这方面,raft 做得比 paxos 好,raft 很清晰的提供了 configuration change 的流程,configuration change 流程用于应对 raft gourp 安全的动态添加节点和移除节点,有了这个算法,在数据库中 rebalance 的流程其实能很好的总结为:
对一个 region: add replica
transfer leadership
remove local replica
这三个流程都是标准的 raft 的 configuration change 的流程,TiKV 的实现和 raft 的 paper 的实现有点不一样的是:
config change 的 log 被 apply 后,才会发起 config change 操作。
一次一个 group 只能处理一个 config change 操作,避免 disjoint majority,不过这点在 diego 的论文里提到过。
主要是出于正确性没问题的情况下,工程实现比较简单的考虑。
另外这几个过程要做到业务层透明,也需要客户端及元信息管理模块的配合。毕竟当一个 region 的 leader 被转移走后,客户端对这个 region 的读写请求要发到新的 leader 节点上。
客户端这里指的是 TiKV 的 client sdk,下面简称 client , client 对数据的读写流程是这样的:首先 client 会本地缓存一份数据的路由表,这个路由表形如:
{startKey1, endKey1} -> {Region1, NodeA}{startKey2, endKey2} -> {Region2, NodeB}{startKey3, endKey3} -> {Region3, NodeC}…client 根据用户访问的 key,查到这个 key 属于哪个区间,这个区间是哪个 region,leader 现在在哪个物理节点上,然后客户端查到后直接将这个请求发到这个具体的 node 上,刚才说过了,此时 leader 可能已经被 transfer 到了其他节点,此时客户端会收到一个 region stale 的错误,客户端会向元信息管理服务请求然后更新自己的路由表缓存。
这里可以看到,路由表是一个很重要的模块,它需要存储所有的 region 分布的信息,同时还必须准确,另外这个模块需要高可用。另一方面,刚才提到的数据 rebalance 工作,需要有一个拥有全局视角的调度器,这个调度器需要知道哪个 node 容量不够了,哪个 node 的压力比较大,哪个 node region leader 比较多?以动态的调整 regions 在各个 node 中的分布,因为每个 node 是几乎无状态的,它们无法自主的完成数据迁移工作,需要依靠这个调度器发起数据迁移的操作(raft config change)。
大家应该也注意到了,这个调度器的角色很自然的能和路由表融合成一个模块,在 Google Spanner 的论文中,这个模块的名字叫 Placement Driver, 我们在 TiKV 中沿用了这个名称,简称 pd,pd 主要的工作就是上面提到的两项:1. 路由表 2. 调度器。
Spanner 的论文中并没有过多的介绍 pd 的设计,但是设计一个大规模的分布式存储系统的一个核心思想是一定要假设任何模块都是会 crash 的,模块之间互相持有状态是一件很危险的事情,因为一旦 crash,standby 要立刻启动起来,但是这个新实例状态不一定和之前 crash 的实例一致,这时候就要小心会不会引发问题.
比如一个简单的 case :因为 pd 的路由表是存储在 etcd 上的,但是 region 的分裂是由 node 自行决定的 ( node 才能第一时间知道自己的某个 region 大小是不是超过阈值),这个 split 事件如果主动的从 node push 到 pd ,如果 pd 接收到这个事件,但是在持久化到 etcd 前宕机,新启动的 pd 并不知道这个 event 的存在,路由表的信息就可能错误。
我们的做法是将 pd 设计成彻底无状态的,只有彻底无状态才能避免各种因为无法持久化状态引发的问题。
每个 node 会定期的将自己机器上的 region 信息通过心跳发送给 pd, pd 通过各个 node 通过心跳传上来的 region 信息建立一个全局的路由表。这样即使 pd 挂掉,新的 pd 启动起来后,只需要等待几个心跳时间,就又可以拥有全局的路由信息,另外 etcd 可以作为缓存加速这一过程,也就是新的 pd 启动后,先从 etcd 上拉取一遍路由信息,然后等待几个心跳,就可以对外提供服务。
但是这里有一个问题,细心的朋友也可能注意到了,如果集群出现局部分区,可能某些 node 的信息是错误的,比如一些 region 在分区之后重新发起了选举和分裂,但是被隔离的另外一批 node 还将老的信息通过心跳传递给 pd,可能对于某个 region 两个 node 都说自己是 leader 到底该信谁的?
在这里,TiKV 使用了一个 epoch 的机制,用两个逻辑时钟来标记,一个是 raft 的 config change version,另一个是 region version,每次 config change 都会自增 config version,每次 region change(比如split、merge)都会更新 region version. pd 比较的 epoch 的策略是取这两个的最大值,先比较 region version, 如果 region version 相等则比较 config version 拥有更大 version 的节点,一定拥有更新的信息。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

