





黄东旭解析 TiDB 的核心优势
1199
2023-06-09
本文讲述了时序引擎架构和实例演练,运维监控利器——时序数据库
一、时序引擎介绍
时序引擎是一款功能丰富、高性能的时序引擎,专为物联网、工业互联网、数字能源、金融等场景设计并优化。它能让大量设备、数据采集器每天产生的高达 TB 甚至 PB 级的数据得到高效实时的处理,对业务的运行状态进行实时的监测、预警,从大数据中挖掘出商业价值。
随着我国工业和信息化的发展,系统所需处理的数据量也越来越大,传统的数据库已经无法满足时序数据的高速写入和高并发的查询分析需求。基于传统关系型数据库或大数据平台发展而来的时序引擎,或性能不佳、或运维管理复杂、或 SQL 支持不足,无法满足我国工业信息化的需求。
时序引擎使用“就地运算”等技术,具备高速、易用及易运维等特性,满足海量、高并发的时序数据写入及快速查询和复杂查询的需求。
二、时序引擎功能
数据查询:数据查询是 时序引擎的基础功能。创建数据库后,用户可以通过 SELECT 执行查询操作,子句支持 LAST/SINCE/BETWEEN/FILTER BY SAMPLE/WHERE/GROUP BY/HAVING/ORDER BY/LIMIT 等常见语法。
交叉链接分析:交叉链接分析在数据分析中非常强大,许多有用的信息是通过查找和构建实体之间的链接或关联来发现的,通常用于分析两个变量之间的关系。
空间索引:提供 Geohash 算法实现空间索引,空间索引的建立可满足依据空间位置来进行查询的需求;工业互联网、车联网等诸多场景均需使用到空间位置分析。
树形分析:支持提供树形;在某些数据分析情况下,它提供了一种比使用分析表对象更有效的计算方式。
集群部署:支持集群部署,适用于大数据分析和边缘计算应用的高性能平台;采用高效的映射/缩减架构来处理分布在不同 上的数据。
支持协议:支持 MySQL 协议,对应用更加友好,充分降低从 数据库迁移成本。
支持多种函数:支持主要函数类型和自定义函数,包括聚合函数、日期函数、数学函数、空间函数、字符串函数等实用函数;也支持在表对象的查询语句中使用用户定义的函数,解决用户在生产中遇到的已有函数或功能无法解决的问题。
外部接口:时序引擎支持 Spark 和 Http 两种外部接口访问数据库,可支持数据库外部集成需求或通过其他方式对外部进行访问。
三、时序引擎优势
支持每秒百万级别的单/多指标写入,可增加随时间变化而产生的数据集。
时序引擎的时间序列查询速度相较于传统关系数据库,提升了 10-500 倍。
为不同用户配置不同权限,对接入时序引擎用户进行身份认证。
数据压缩无需解压缩即可使用,降本增效,数据压缩比为 1:7~1:10。
支持 SQL 语法、类 SQL 语法、SQL 写入、多开发语言、多协议兼容。
集群部署适用于大数据分析和边缘计算应用程序的高性能平台。
四、时序引擎架构
时序引擎能够有效地且主要用于处理庞大且统一的带时间标签实时数据。产品具有实时本地运算、串行流式数据实时运算等核心技术,支持云边端协同架构的超融合时序引擎产品,助力物联网、工业互联网、交通车联网、数字能源等多个领域或行业数字化建设。
五、时序引擎实例演练
1、支持第三方工具进行连接
2、兼容大部分 MySQL 语法
随着IT系统复杂度增加、运维监控数据激增,传统数据库在对这些时序数据进行存储、查询、分析等处理操作时捉襟见肘,迫切需要一种专门针对时序数据来做优化的数据库系统,即时间序列数据库。
一、什么是时序数据库
在介绍时序数据库之前,首先了解一下什么是时序数据。时序数据是指按照时间顺序记录系统、设备状态变化的数据,运维监控系统如APM(应用性能监控)、基础服务监控、大型机监控等监控采集的数据大部分是时序数据。时序数据看起来就是一个时间轴,表明了一些数据维度随着时间的变化,通常这些数据以插入为主,没有什么更新操作。由于这些特点,时序数据库诞生了。时序数据库全称为时间序列数据库 Time Series Database (TSDB),是用于存储和管理时间序列数据的专业化数据库,也是用于优化摄取、处理和存储时间戳数据的数据库。时序数据库的目标是实现高性能的读写,实时分析,其被广泛应用在设备信息采集、金融数据分析及可视化等众多场景当中。与常规的关系数据库SQL相比,最大的区别在于,时序数据库是以时间为索引的规律性时间间隔记录的数据库。
二、时序数据库的特点
1、高吞吐量写入能力
这是针对时序业务持续产生海量数据这么一个特点量身定做的,当前要实现系统高吞吐量写入,必须要满足两个基本技术点要求:系统具有水平扩展性和单机LSM体系结构。系统水平扩展是指能以集群化部署系统、支持动态扩缩容,LSM体系结构是用来保证单台机器的高吞吐量写入,LSM结构下数据写入只需要写入内存以及追加写入日志,这样就不再需要随机将数据写入磁盘,***、Kudu以及Druid等对写入性能有要求的系统目前都采用这种结构。
2、数据分级存储/TTL
这是针对时序数据冷热性质定制的技术特性。数据分级存储要求能将最近小时级别的数据放到内存中,将最近天级别的数据放到***,而更久远的数据会放到更加廉价的HDD或者直接使用TTL过期淘汰掉。
3、高压缩率
提供高压缩率有两个方面的考虑,一方面是节省成本,另一方面是压缩后的数据可以更容易保证存储到内存中。
4、高效时间窗口查询能力
时序业务的查询需求分为两类,一是实时数据查询,反映当前监控对象的状态;二是主要查询某个时间段的历史数据,由于历史数据的数据量非常大,所以需要对时间窗口中的大量数据查询进行优化。
5、多维度查询能力
时序数据通常会有多个维度的标签来刻画一条数据。如何根据随机几个维度进行高效查询是必须要解决的一个问题,这个问题通常需要考虑位图索引或者倒排索引技术。
6、高效聚合能力
时序业务一个通用的需求是聚合统计报表查询,比如哨兵系统中需要查看最近一天某个接口出现异常的总次数,或者某个接口执行的最大耗时时间。这样的聚合实际上就是简单的count以及max,但是如何能高效地在巨量数据的基础上将满足条件的原始数据查询出来并聚合,且统计的原始值可能会因时间久远而不在内存中,这些问题使得这是一个非常耗时的操作。目前业界比较成熟的方案是使用预聚合,即在数据写进的时候就完成基本聚合操作。
7、批量删除能力
时序业务对于过期的数据需要进行批量删除操作。
三、总结
由于运维监控中的数据一般包含以下特性,而这些特性也正是时序数据库所能够覆盖的。
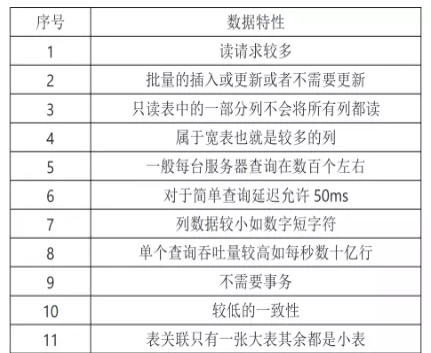
上文就是小编为大家整理的时序引擎架构和实例演练,运维监控利器——时序数据库。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

