

黄东旭解析 TiDB 的核心优势
1380
2023-06-06
本文讲述了TiFlash 架构与原理,TiFlash 计算层概览
TiFlash是pingcap开发的一种分布式列式存储引擎,它主要用于支持OLAP(Online Analytical Processing)场景下的数据查询。相对于TiKV这种基于分布式事务的存储引擎,TiFlash专注于对大规模数据进行快速的复杂查询和分析,能够满足数百亿行的数据查询需求,同时也能够支持实时的数据插入和删除操作。
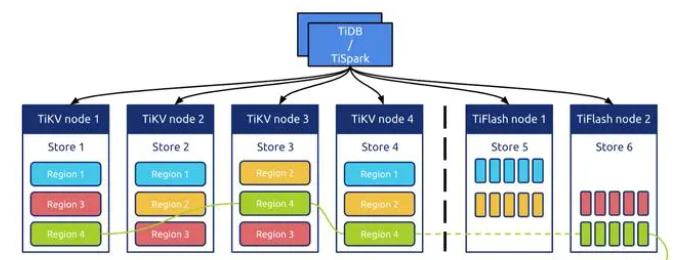
TiFlash的架构和原理如下:
1、列式存储
TiFlash采用列式存储方式,与传统的行式存储方式不同,列式存储将同一列的数据存储在一起,可以提高数据的压缩率,同时也能够减少IO操作,提高查询效率。
2、分布式架构
TiFlash采用分布式架构,数据可以水平扩展,可以支持PB级别的数据存储和查询。TiFlash的每个节点都是独立的,可以独立进行数据的处理和计算,同时也能够相互协作完成复杂的查询任务。
3、列存储索引
TiFlash采用了一种叫作“分区内排序”的方式对数据进行索引。这种方式可以在列存储中快速定位数据,提高查询效率。TiFlash的列存储索引还可以支持多种索引类型,包括Bloom Filter、Bitmap Index、Range Index等。
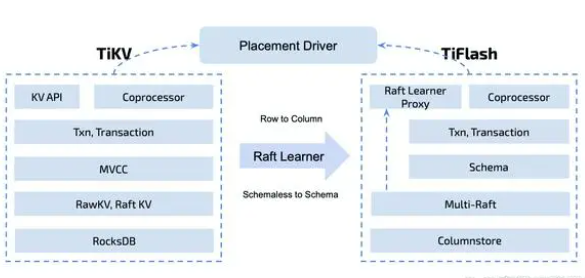
4、查询优化
TiFlash通过多种方式优化查询效率。例如,通过在查询过程中动态生成代码,避免了反复的解析和编译操作;同时还可以在不同节点上执行不同的查询计划,以提高整个系统的并行度。
5、兼容TiDB
TiFlash可以与TiDB进行集成,通过TiDB的TiKV层来实现数据的存储和管理,同时还可以与TiDB的查询优化器配合使用,实现更高效的查询计划生成和执行。
总之,TiFlash的架构和原理设计非常符合OLAP场景下的需求,能够提供高效的列式存储和复杂查询功能,为用户提供高性能、低延迟的数据处理能力。
本文选自《TiDB 6.x in Action》,分为 TiDB 6.x 原理和特性、TiDB Developer 体验指南、TiDB 6.x 可管理性、TiDB 6.x 内核优化与性能提升、TiDB 6.x 测评、TiDB 6.x 最佳实践 6 大内容模块,汇聚了 TiDB 6.x 新特性的原理、测评、试用心得等等干货。不管你是 DBA 运维还是应用开发者,如果你正在或有意向使用 TiDB 6.x,这本书都可以给你提供参考和实践指南。
TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件。TiFlash 源码阅读系列文章将从源码层面介绍 TiFlash 的内部实现。主要包括架构的演进,DAGRequest 协议、dag request 在 TiFlash 侧的处理流程以及 MPP 基本原理。

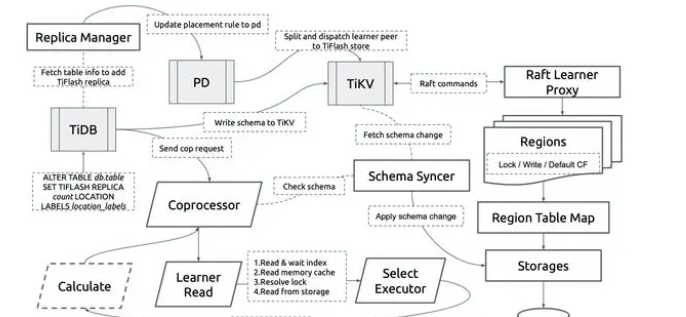
上图是一个 TiDB 中 query 执行的示意图,可以看到在 TiDB 中一个 query 的执行会被分成两部分,一部分在 TiDB 执行,一部分下推给存储层(TiFlash/TiKV)执行。本文我们主要关注在 TiFlash 执行的部分。
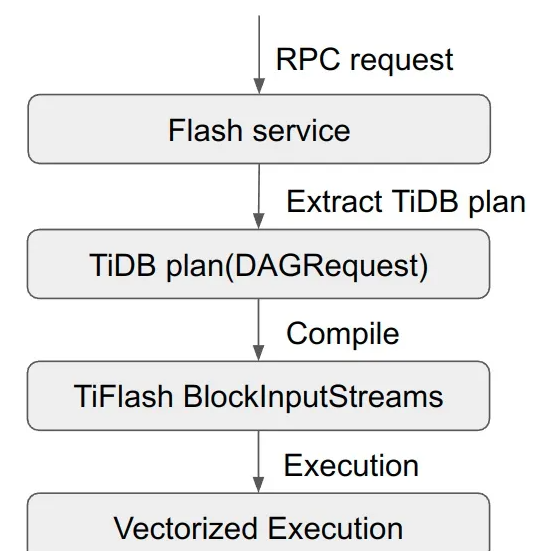
这个是一个 TiDB 的查询 request 在 TiFlash 内部的基本处理流程,首先 Flash service 会接受到来自 TiDB 的 RPC 请求,然后会从请求里拿到 TiDB 的 plan,在 TiFlash 中我们称之为 DAGRequest,拿到 TiDB 的 plan 之后,TiFlash 需要把 TiDB 的 plan 编译成可以在 TiFlash 中执行的 BlockInputStream,最后在得到 BlockInputStream 之后,TiFlash 就会进入向量化执行的阶段。本文要讲的 TiFlash 计算层实际上是包含以上四个阶段的广义上的计算层。
TiDB + TiFlash 计算层的演进
首先,我们从 API 的角度来讲一下 TiDB + TiFlash 计算层的演进过程:
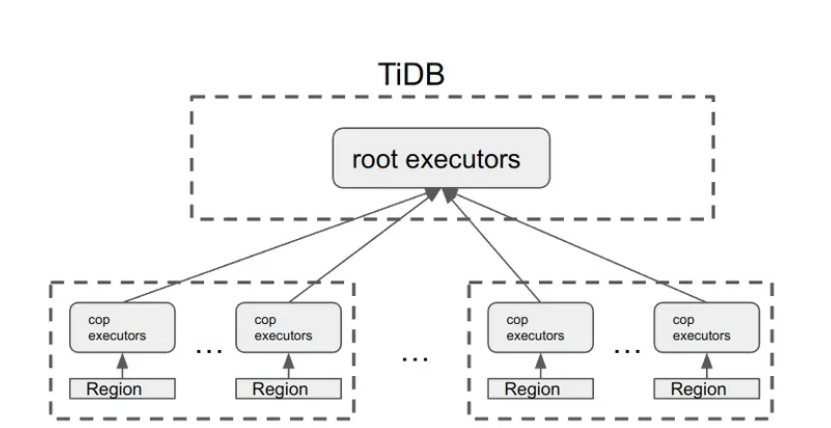
最开始在没有引入 TiFlash 时,TiDB 是用过 Coprocessor 协议来与存储层(TiKV)进行交互的,在上图中,root executors 表示在 TiDB 中单机执行的算子,cop executors 指下推给 TiKV 执行的算子。在 TiDB + TiKV 的计算体系中,有如下几个特点:
TiDB 中的算子是在 TiDB 中单机执行的,计算的扩展性受限;
TiKV 中的算子是在 TiKV 中执行的,而且 TiKV 的计算能力是可以随着 TiKV 节点数的增加而线性扩展的;
因为 TiKV 中并没有 table 的概念,Coprocessor 是以 Region 为单位的,一个 region 一个 coprocessor request;
每个 Coprocessor 都会带有一个用于 MVCC 读的 timestamp,在 TiFlash 中我们称之为 start_ts。在 TiDB 4.0 中,我们首次引入了 TiFlash:

在引入之初,我们基本上就是只对接了现有的 Coprocessor 协议,可以看出上面这个图上之前 TiDB + TiKV 的图其实是一样的,除了存储层从 TiKV 变成了 TiFlash。但是本质上讲引入 TiFlash 之前 TiDB + TiKV 是一个面向 TP 的系统,TiFlash 在简单对接 Coprocessor 协议之后,马上发现了一些对 AP 很不友好的地方,主要有两点:
Coprocessor 是以 region 为单位的,而 TiDB 中默认 region 大小是 96 MB,这样对于一个 AP 的大表,可能会包含成千上万个 region,这导致一个 query 就会有成千上万次 RPC;
每个 Coprocessor 只读一个 region 的数据,这让存储层很多读相关的优化都用不上。
在发现问题之后,我们尝试对原始的 Coprocessor 协议进行改进,主要进行了两次尝试:
BatchCommands:这个是 TiDB + TiKV 体系里就有的一个改进,原理就是在发送的时候将发送给同一个存储节点的 request batch 成一个,对于 TiFlash 来说,因为只支持 Coprocessor request,所以就是把一些 Coprocessor request batch 成了一个。因为 batch 操作是发送端最底层做的,所以 batch 在一起的 Coprocessor request 并没有逻辑上的联系,所以 TiFlash 拿到 BatchCoprocessor 之后也就是每个 Coprocessor request 依次处理。所以 BatchCommands 只能解决 RPC 过多的问题。
BatchCoprocessor:这个是 TiDB + TiFlash 特有的 RPC,其想法也很简单,就是对同一个 TiFlash 节点,只发送一个 request,这个 request 里面包含了所有需要读取的 region 信息。显然这个模式不但能减少 RPC,而且存储层能一次性的看到所有需要扫描的数据,也让存储层有了更大的优化空间。
尽管在引入 BatchCoprocessor 之后,Coprocessor 的两个主要缺点都得到了解决,但是因为无论是 BatchCoprocessor 还是 Coprocessor 都只是支持对单表的 query,遇到复杂 sql,其大部分工作还是需要在 root executor 上单机执行,以下面这个两表 join 的 plan 为例:

只有 TableScan 和 Selection 部分可以在 TiFlash 中执行,而之后的 Join 和 Agg 都需要在 TiDB 执行,这显然极大的限制了计算层的扩展性。为了从架构层面解决这个问题,在 TiFlash 5.0 中,我们正式引入了 MPP 的计算架构:
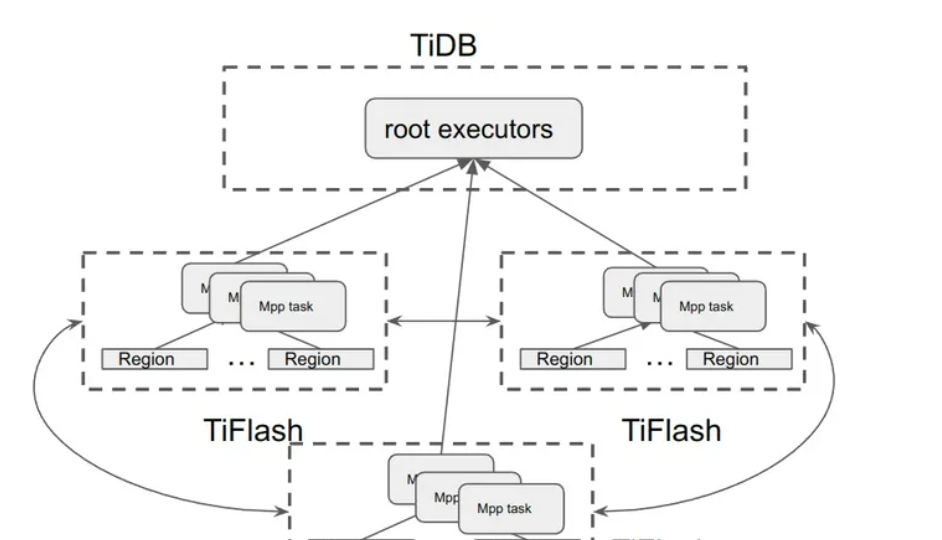
引入 MPP 之后,TiFlash 支持的 query 部分得到了极大的丰富,对于理想情况下,root executor 直接退化为一个收集结果的 TableReader,剩下部分都会下推给 TiFlash,从而从根本上解决了 TiDB 中计算能力无法横向扩展的问题。
DAGRequest 到 BlockInputStream
在 TiFlash 内部,接收到 TiDB 的 request 之后,首先会得到 TiDB 的 plan,在 TiFlash 中,称之为 DAGRequest,它是一个基于 protobuf 协议的一个定义,一些主要的部分如下:

值得一提的就是 DAGRequest 中有两个 executor 相关的 field:
executors:这个是引入 TiFlash 之前的定义,其表示一个 executor 的数组,而且里面的 executor 最多就三个:一个 scan(tablescan 或者 indexscan),一个 selection,最后一个 agg/topN/limit;
root_executors:显然上面那个 executors 的定义过于简单,无法描述 MPP 时的 plan,所以在引入 MPP 之后我们加了一个 root_executor 的 field,它是一个 executor 的 tree。
在得到 executor tree 之后,TiFlash 会进行编译,在编译的时候有一个中间数据结构是 DAGQueryBlock,TiDB 会先将 executor tree 转成 DAGQueryBlock 的tree,然后对 DAGQueryBlock 的 tree 进行后序遍历来编译。
DAGQueryBlock 的定义和原始的 executor 数组很类似,一个 DAGQueryBlock 包含的 executor 如下:
SourceExecutor Selection Having
其中 SourceExecutor 包含真正的 source executor 比如 tablescan 或者 exchange receiver,以及其他所有不符合上述 executor 数组 pattern 的 executor,如 join,project 等。
可以看出来 DAGQueryBlock 是从 Coprocessor 时代的 executor 数组发展而来的,这个结构本身并没有太多的意义,而且也会影响很多潜在的优化,在不久的将来,应该会被移除掉。
在编译过程中,有两个 TiDB 体系特有的问题需要解决:
如何保证 TiFlash 的数据与 TiKV 的数据保持强一致性;
如何处理 Region error。
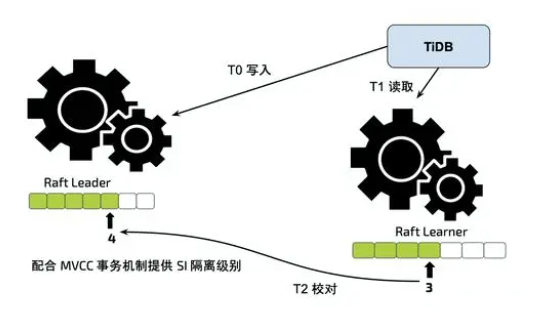
对于第一个问题,我们引入了 Learner read 的过程,即在 TiFlash 编译 tablescan 之前,会用 start_ts 向 raft leader 查询截止到该 start_ts 时,raft 的 index 是多少,在得到该 index 之后,TiFlash 会等自己这个 raft leaner 的 index 追上 leader 的 index。
对于第二个问题,我们引入了 Remote reader 的概念,即如果 TiFlash 遇到了 region error,那么如果是 BatchCoprocessor 和 MPP request,那 TiFlash 会主动向其他 TiFlash 节点发 Coprocessor request 来拿到该 region 的数据。
在把 DAGRequest 编译成 BlockInputStream 之后,就进入了向量化执行的阶段,在向量化执行的时候,有两个基本的概念:
Block:是执行期的最小数据单元,它由一个 column 的数组组成;
BlockInputStream:相当于执行框架,每个 BlockInputStream 都有一个或者多个 child,执行时采用了 pull 的模型。下面是执行时的伪代码:

BlockInputStream 可以分为两类:
用于做计算的,例如:
DMSegmentThreadInputStream:与存储交互的 InpuStream,可以简单理解为是 table scan;
ExchangeReceiverInputStream:从远端读数据的 InputStream;
ExpressionBlockInputStream:进行 expression 计算的 InputStream;
FilterBlockInputStream:对数据进行过滤的 InputStream;
ParallelAggregatingBlockInputStream:做数据进行聚合的 InputStream。
用于并发控制的,例如:
UnionBlockInputStream:把多个 InputStream 合成一个 InputStream;
ParallelAggregatingBlockInputStream:和 Union 类似,不过还会做一个额外的数据聚合;
SharedQueryBlockInputStream:把一个 InputStream 扩散成多个 InputStream。
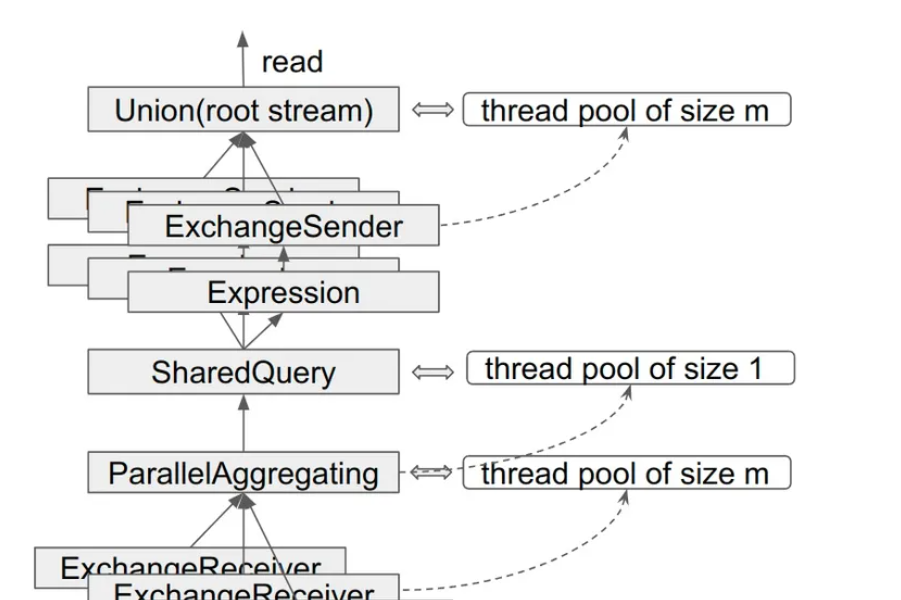
用于计算的 InputStream 与用于并发控制的 InputStream 最大的不同在于用于计算的 InputStream 自己不管理线程,它们只负责在某个线程里跑起来,而用于并发控制的 InputStream 会自己管理线程,如上所示,Union,ParallelAggregating 以及 SharedQuery 都会在自己内部维护一个线程池。当然有些并发控制的 InputStream 自己也会完成一些计算,比如 ParallelAggregatingBlockInputStream。
MPP
在介绍完 TiFlash 计算层中基本的编译以及执行框架之后,我们重点再介绍下 MPP。
MPP 在 API 层共有三个:
DispatchMPPTask:用于 TiDB 向 TiFlash 发送 plan;
EstablishMPPConnectionSyncOrAsync:用于 MPP 中上游 task 向下游 task 发起读数据的请求,因为无论是读的数据量以及读的时间会比较长,所以这个 RPC 是 streaming 的 RPC;
CancelMPPTask:用于 TiDB 端 cancel MPP query。
在运行 MPP query 的时候,首先由 TiDB 生成 MPP task,TiDB 用 DispatchMPPTask 来将 task 分发给各个 TiFlash 节点,然后 TiDB 与 TiFlash 会用 EstablishMPPConnection 来建立起各个 task 之间的连接。
与 BatchCoprocessor 相比,MPP 的核心概念是 Exchange,用于 TiFlash 节点之间的数据交换,在 TiFlash 中有三种 exchange 的类型:
Broadcast:即将一份数据 broadcast 到多个目标 mpp task;
HashPartition:即将一份数据用 hash partition 的方式切分成多个 partition,然后发送给目标 mpp task;
PassThrough:这个与 broadcast 几乎一样,不过 PassThrough 的目标 task 只能有一个,通常用于 MPP task 给 TiDB 返回结果。
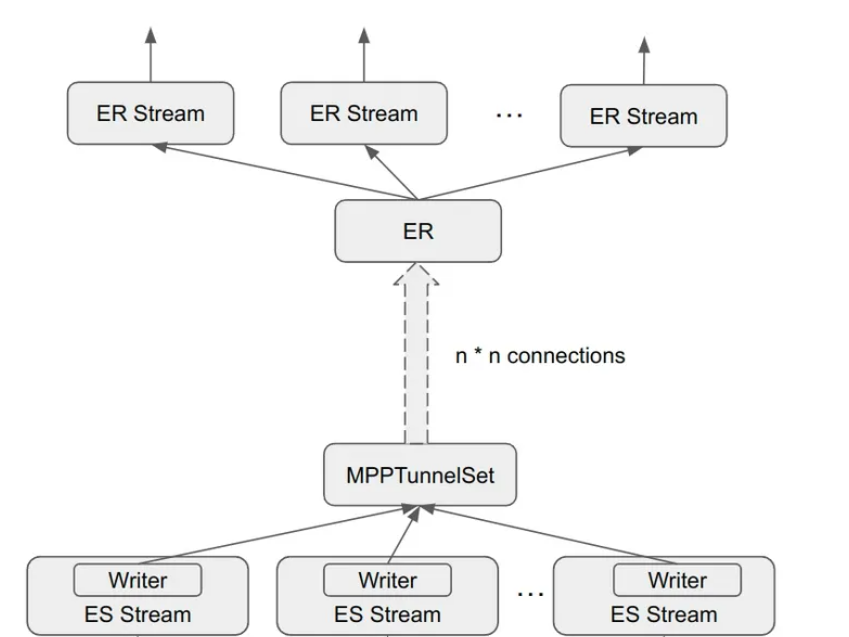
上图是 Exchange 过程中的一些关键数据结构,主要有如下几个:
接收端
ExchangeReceiver:用于向其他 task 建立连接,接收数据并放在 result queue;
ExchangeReceiverInputStream:执行框架中的一个 InputStream,多个 ER Stream 共同持有一个 ExchangeReceiver,并从其 result queue 中读数据。
发送端
MPPTunnel:持有 grpc streaming writer,用于将计算结果发送给其他 task,目前有三种模式:
Sync Tunnel:用 sync grpc 实现的 tunnel;
Async Tunnel:用 async grpc 实现的 tunnel;
Local Tunnel:对于处于同一个节点的不同 task,他们之间的 Tunnel 不走 RPC,在内存里传输数据即可。
MPPTunnelSet:同一个 ExchangeSender 可能需要向多个 mpp task 传输数据,所以会有多个 MPPTunnel,这些 MPPTunnel 在一起组成一个 MPPTunnelSet。
StreamingDAGResponseWriter:持有 MPPTunnelSet,主要做一些发送之前的数据预处理工作:
将数据 encode 成协议规定的格式;
如果 Exchange Type 是 HashPartition 的话,还需要负责把数据进行 Hash partition 的切分。
ExchangeSenderBlockInputStream:执行框架中的一个 InputStream,持有 StreamingDAGResponseWriter,把计算的结果发送给 writer。
除了 Exchange,MPP 还有一个重要部分是 MPP task 的管理,与 BatchCoprocessor/Coprocessor 不同,MPP query 的多个 task 需要有一定的通信协作,所以 TiFlash 中需要有对 MPP task 的管理模块。其主要的数据结构如下:
MPPTaskManager:全局的 instance 用来管理该 TiFlash 节点上所有的 MPP task;
MPPQueryTaskSet:属于同一个 query 的所有 MPP task 集合,在诸如 CancelMPPTask 时用于快速找到所有的目标 task;
MPPTask:一个 MPP query 中的最基本单元,不同 MPP task 之间通过 Exchange 来交换数据。
以上就是 TiFlash 中 MPP 的相关实现,可以看出目前这个实现还是比较朴素的。在随后的测试和使用中,我们很快发现一些问题,主要有两个问题:
第一个问题:对于一些 sql 本身很复杂,但是数据量(计算量)却不大的 query,我们发现,无论怎么增加 query 的并发,TiFlash 的 cpu 利用率始终会在 50% 以下。经过一系列的研究之后我们发现 root cause 是目前 TiFlash 的线程使用是需要时申请,结束之后即释放的模式,而频繁的线程申请与释放效率非常低,直接导致了系统 cpu 使用率无法超过 50%。解决该问题的直接思路即使用线程池,但是由于我们目前 task 使用线程的模式是非抢占的,所以对于固定大小的线程池,因为系统中没有全局的调度器,会有死锁的风险,为此我们引入了 DynamicThreadPool,在该线程池中,线程主要分为两类:
固定线程:长期存在的线程
动态线程:按需申请的线程,不过与之前的线程不同的是,该线程在结束当前任务之后会等一段时间,如果没有新的任务的话,才会退出
第二个问题和第一个问题类似,也是线程相关的,即 TiFlash 在遇到高并发的 query 时,因为线程使用没有很好的控制,会导致 TiFlash server 遇到无法分配出线程的问题,为了解决此问题,我们必须控制 TiFlash 中同时使用的线程,在跑 MPP query 的时候,线程主要可以分为两部分:
完全分布式的调度器,仅依赖 TiFlash 节点自身的信息
基本的原理为 MinTSOScheduer 保证 TiFlash 节点上最小的 start_ts 对应的所有 MPP task 能正常运行。因为全局最小的 start_ts 在各个节点上必然也是最小的 start_ts,所以 MinTSOScheduer 能够保证全局至少有一条 query 能顺利运行从而保证整个系统不会有死锁,而对于非最小 start_ts 的 MPP task,则根据当前系统的线程使用情况来决定是否可以运行,所以也能达到控制系统线程使用量的目的。
IO 线程:主要指用于 grpc 通信的线程,在减小 grpc 线程使用方面,我们基本上是采用了业界的成熟方案,即用 async 的方式,我们实现了 async 的 grpc server 和 async 的 grpc client,大大减小了 IO 线程的使用量
计算线程:为了控制计算线程,我们必须引入调度器,该调度器有两个最低目标:不造成死锁以及最大程度控制系统的线程使用量,最后我们在 TiFlash 里引入了 MinTSOScheduer:
完全分布式的调度器,仅依赖 TiFlash 节点自身的信息
基本的原理为 MinTSOScheduer 保证 TiFlash 节点上最小的 start_ts 对应的所有 MPP task 能正常运行。因为全局最小的 start_ts 在各个节点上必然也是最小的 start_ts,所以 MinTSOScheduer 能够保证全局至少有一条 query 能顺利运行从而保证整个系统不会有死锁,而对于非最小 start_ts 的 MPP task,则根据当前系统的线程使用情况来决定是否可以运行,所以也能达到控制系统线程使用量的目的。
上文就是小编为大家整理的TiFlash 架构与原理,TiFlash 计算层概览。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

