

黄东旭解析 TiDB 的核心优势
1840
2023-06-02
本文讲述了常用的分布式事务解决方案有哪些?分布式事务概念与应用场景
关于分布式事务,工程领域主要讨论的是强一致性和最终一致性的解决方案。典型方案包括:
两阶段提交(2PC, Two-phase Commit)方案
eBay 事件队列方案
TCC 补偿模式
缓存数据最终一致性
一、一致性理论
分布式事务的目的是保障分库数据一致性,而跨库事务会遇到各种不可控制的问题,如个别节点永久性宕机,像单机事务一样的ACID是无法奢望的。另外,业界著名的CAP理论也告诉我们,对分布式系统,需要将数据一致性和系统可用性、分区容忍性放在天平上一起考虑。
两阶段提交协议(简称2PC)是实现分布式事务较为经典的方案,但2PC 的可扩展性很差,在分布式架构下应用代价较大,eBay 架构师Dan Pritchett 提出了BASE 理论,用于解决大规模分布式系统下的数据一致性问题。BASE 理论告诉我们:可以通过放弃系统在每个时刻的强一致性来换取系统的可扩展性。
1、CAP理论
在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)3 个要素最多只能同时满足两个,不可兼得。其中,分区容忍性又是不可或缺的。
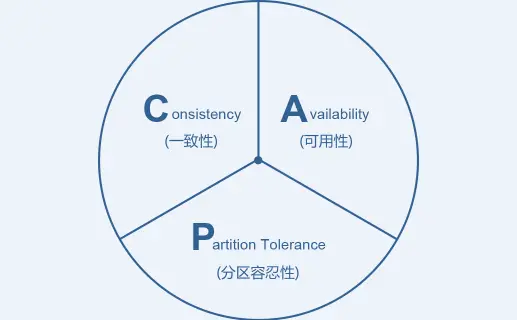
一致性:分布式环境下多个节点的数据是否强一致。
可用性:分布式服务能一直保证可用状态。当用户发出一个请求后,服务能在有限时间内返回结果。
分区容忍性:特指对网络分区的容忍性。
举例:***、Dynamo 等,默认优先选择AP,弱化C;***、*** 等,默认优先选择CP,弱化A。
2、BASE 理论
核心思想:
基本可用(BasicallyAvailable):指分布式系统在出现故障时,允许损失部分的可用性来保证核心可用。
软状态(SoftState):指允许分布式系统存在中间状态,该中间状态不会影响到系统的整体可用性。
最终一致性(EventualConsistency):指分布式系统中的所有副本数据经过一定时间后,最终能够达到一致的状态。
二、一致性模型
数据的一致性模型可以分成以下 3 类:
强一致性:数据更新成功后,任意时刻所有副本中的数据都是一致的,一般采用同步的方式实现。
弱一致性:数据更新成功后,系统不承诺立即可以读到最新写入的值,也不承诺具体多久之后可以读到。
最终一致性:弱一致性的一种形式,数据更新成功后,系统不承诺立即可以返回最新写入的值,但是保证最终会返回上一次更新操作的值。
分布式系统数据一致性模型可以通过Quorum NRW算法分析。
不少朋友向我们反馈处理企业数据一致性时成本过高、事务执行状态不透明。
三、分布式事务解决方案
1、2PC方案——强一致性
2PC的核心原理是通过提交分阶段和记日志的方式,记录下事务提交所处的阶段状态,在组件宕机重启后,可通过日志恢复事务提交的阶段状态,并在这个状态节点重试,如Coordinator重启后,通过日志可以确定提交处于Prepare还是PrepareAll状态,若是前者,说明有节点可能没有Prepare成功,或所有节点Prepare成功但还没有下发Commit,状态恢复后给所有节点下发RollBack;若是PrepareAll状态,需要给所有节点下发Commit,数据库节点需要保证Commit幂等。
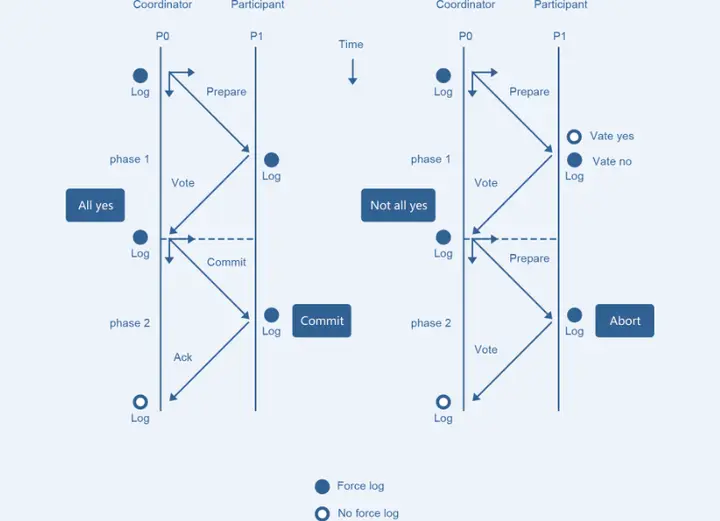
2PC方案的问题:
同步阻塞。
数据不一致。
单点问题。
升级的3PC方案旨在解决这些问题,主要有两个改进:
增加超时机制。
两阶段之间插入准备阶段。
但三阶段提交也存在一些缺陷,要彻底从协议层面避免数据不一致,可以采用Paxos或者Raft 算法。
2、eBay 事件队列方案——最终一致性
eBay 的架构师Dan Pritchett,曾在一篇解释BASE 原理的论文《Base:An Acid Alternative》中提到一个eBay 分布式系统一致性问题的解决方案。它的核心思想是将需要分布式处理的任务通过消息或者日志的方式来异步执行,消息或日志可以存到本地文件、数据库或消息队列,再通过业务规则进行失败重试,它要求各服务的接口是幂等的。
描述的场景为,有用户表user 和交易表transaction,用户表存储用户信息、总销售额和总购买额,交易表存储每一笔交易的流水号、买家信息、卖家信息和交易金额。如果产生了一笔交易,需要在交易表增加记录,同时还要修改用户表的金额。
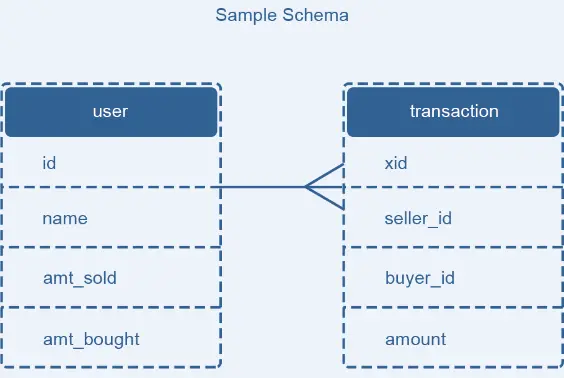
论文中提出的解决方法是将更新交易表记录和用户表更新消息放在一个本地事务来完成,为了避免重复消费用户表更新消息带来的问题,增加一个操作记录表updates_applied来记录已经完成的交易相关的信息。
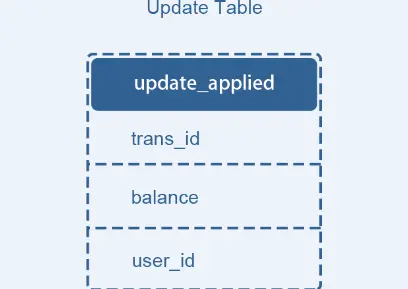
这个方案的核心在于第二阶段的重试和幂等执行。失败后重试,这是一种补偿机制,它是能保证系统最终一致的关键流程。
3、TCC (Try-Confirm-Cancel)补偿模式——最终一致性
某业务模型如图,由服务 A、服务B、服务C、服务D 共同组成的一个微服务架构系统。服务A 需要依次调用服务B、服务C 和服务D 共同完成一个操作。当服务A 调用服务D 失败时,若要保证整个系统数据的一致性,就要对服务B 和服务C 的invoke 操作进行回滚,执行反向的revert 操作。回滚成功后,整个微服务系统是数据一致的。
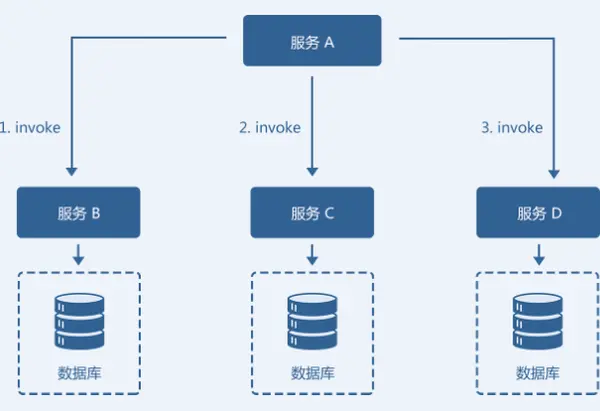
实现关键要素:
服务调用链必须被记录下来。
每个服务提供者都需要提供一组业务逻辑相反的操作,互为补偿,同时回滚操作要保证幂等。
必须按失败原因执行不同的回滚策略。
4、缓存数据最终一致性
在我们的业务系统中,缓存(Redis 或者Memcached)通常被用在数据库前面,作为数据读取的缓冲,使得I/O 操作不至于直接落在数据库上。以商品详情页为例,假如卖家修改了商品信息,并写回到数据库,但是这时候用户从商品详情页看到的信息还是从缓存中拿到的过时数据,这就出现了缓存系统和数据库系统中的数据不一致的现象。
要解决该场景下缓存和数据库数据不一致的问题我们有以下两种解决方案:
为缓存数据设置过期时间。当缓存中数据过期后,业务系统会从数据库中获取数据,并将新值放入缓存。这个过期时间就是系统可以达到最终一致的容忍时间。
更新数据库数据后同时清除缓存数据。数据库数据更新后,同步删除缓存中数据,使得下次对商品详情的获取直接从数据库中获取,并同步到缓存。
分布式编程开发是目前大多数软件开发程序员都在学习和应用的一个编程开发方法,下面我们就通过案例分析来了解一下,分布式事务概念与应用场景。

1、什么是事务
事务可以看作是一次大的活动,它由不同的小活动组成,这些活动要么全部成功,要么全部失败。
2、本地事务
数据库事务的四大特性ACID:
A(Atomic):原子性,构成事务的所有操作,要么都执行完成,要么全部不执行,不可能出现部分成功部分失败的情况。
C(Consistency):一致性,在事务执行前后,数据库的一致性约束没有被破坏。比如:张三向李四转100元,转账前和转账后的数据是正确状态这叫一致性,如果出现张三转出100元,李四账户没有增加100元这就出现了数据错误,就没有达到一致性。
I(Isolation):隔离性,数据库中的事务一般都是并发的,隔离性是指并发的两个事务的执行互不干扰,一个事务不能看到其他事务运行过程的中间状态。通过配置事务隔离级别可以避脏读、重复读等问题。
D(Durability):持久性,事务完成之后,该事务对数据的更改会被持久化到数据库,且不会被回滚。
数据库事务在实现时会将一次事务涉及的所有操作全部纳入到一个不可分割的执行单元,该执行单元中的所有操作要么都成功,要么都失败,只要其中任一操作执行失败,都将导致整个事务的回滚。
3、分布式事务
分布式系统会把一个应用系统拆分为可独立部署的多个服务,因此需要服务与服务之间远程协作才能完成事务操作,这种分布式系统环境下由不同的服务之间通过网络远程协作完成事务称之为分布式事务,例如用户注册送积分事务、创建订单减库存事务,银行转账事务等都是分布式事务。
4、分布式事务产生的场景
的场景就是微服务架构,微服务之间通过远程调用完成事务操作。比如:订单微服务和库存微服务,下单的同时订单微服务请求库存微服务减库存。简言之:跨JVM进程产生分布式事务。
单体系统访问多个数据库实例,跨数据库实例产生分布式事务。
多服务访问同一个数据库实例,比如:订单微服务和库存微服务即使访问同一个数据库也会产生分布式事务,原因就是跨JVM进程,两个微服务持有了不同的数据库连接进行数据库操作,此时产生分布式事务。
上文就是小编为大家整理的常用的分布式事务解决方案有哪些?分布式事务概念与应用场景。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

